引言:
对于二分类问题,一般会将预测结果经过一个非线性变换缩小到0到1之间,并设置一个阀值,比如0.5,小于0.5便是0,大于0.5便是1。但是这种做法对于多分类是不适用的。
交叉熵:
通过神经网络解决多分类的方法是设置n个输出节点,n代表类别数。对于每一个样例,神经网络会得到一个n维数组做为输出结果。数组中的每一个维度代表对应的类别。理想情况下,如果一个样本属于k,那么这个类别对应的输出节点的输出值应该为1.而其他节点为0.但是实际上不可能,比如我们理想的是[0, 0, 1, 0],而实际上输出的是[0.1,0.2,0.6,0.1],那么我们这时候如何评判呢,此时交叉熵是常用的评判方法之一。交叉熵刻画得是两个概率分布之间的距离。比如上面的0和0.1的距离。1和0.6的距离。它的公式是这样的:

softmax回归:
但是还有一点要指出的是,神经网络预测的应该是一个概率,比如这种形式的[0.1,0.2,0.6,0.1],但是可以想到最后一层的神经网络,对于每一个结点,其实输出的不会就是一个概率,使得所有输出节点的概率之和为1,那么如何得到概率向量呢?我们使用softmax回归函数。它的公式是这样的:
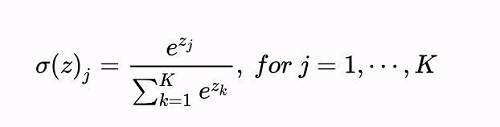
二分类的交叉熵:
当分类结果只有0和1时,交叉熵变成以下形式:
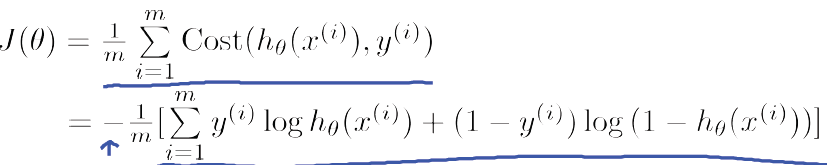
总结:
当交叉熵用于神经网络的损失函数时,p代表的是正确答案,q代表的是预测值,交叉熵刻画得是两个概率分布之间的距离,也就是说交叉熵越小,两个概率分布越近。
tensorflow中的实现:
cross_entropy = -tf.reduce_mean(y_*tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
因为交叉熵一班会与softmax回归一起使用,所以tf有一个封装,比如可以直接通过下面的代码实现使用了softmax回归之后的交叉熵损失函数:
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(y, y_)
回归问题:
与分类问题不同的是,回归问题是对具体数值的预测,要预测的是一个数字,因此解决回归问题的网络一般只有一个输出节点,这个节点的输出值就是预测值。对于回归问题,最常用的损失函数就是均方误差(MSE)函数,其在tf中实现如下:
mse = tf.reduce_mean(tf.square(y_ - y))