来源:阿里云栖社区
https://yq.aliyun.com/articles/74399
更多深度文章,请关注:https://yq.aliyun.com/cloud
作者介绍
Ankit Gupta:数据科学家、IIIT Allahabad研究助理,热爱解决复杂的数据挖掘问题、了解更多关于数据科学和机器学习算法,目前致力于预测软件缺陷的项目。
领英:https://www.linkedin.com/in/ankit-gupta
Github:https://github.com/anki1909
博客:https://www.analyticsvidhya.com/blog/author/facebook_user_4/
注
PCA:主成分分析(Principal Component Analysis)
T-SNE:t-分布随机邻域嵌入(t-Distributed Stochastic Neighbor Embedding)
LDA:线性判别式分析(Linear Discriminant Analysis )
介绍
在处理现实生活中的问题时,数据科学家经常会遇到数百列及以上的数据集,并通过这些大型数据集构建预测模型,这会是一个较复杂的工程。幸运的是有降维技术的存在,降维是数据科学中的一项重要技术,任何数据科学家都必须具备该技能。这项技能测试测试你掌握的降维技术知识,测试问题包括PCA、t-SNE和LDA等主题。在这里还有更具挑战性的比赛。
共有582人参加该测试,以下问题涉及理论到实践的方方面面。

如果错过测试,可以在这里参加测试。
综合成绩
以下是分数的分布,这将有助于评估自己的表现:
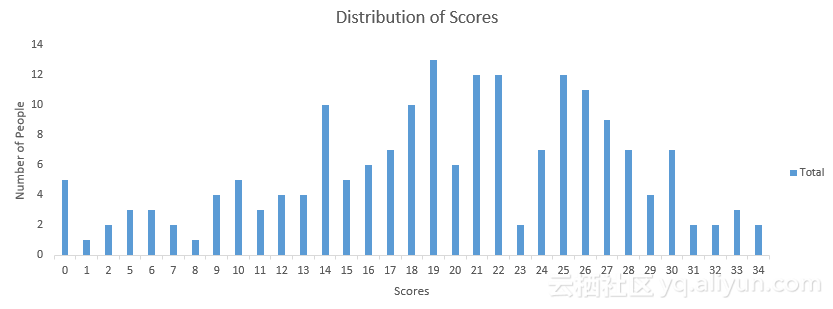
你可以访问并查看自己的分数,以下是关于分配的一些统计数据。
总体分布
平均得分(所有分值的平均值):19.52
得分中位数(按顺序排列的中间值):20
模型得分(最常出现的得分):19

有用资源
问题和答案
1)想象一下,机器学习中有1000个输入特征和1个目标特征,必须根据输入特征和目标特征之间的关系选择100个最重要的特征。你认为这是减少维数的例子吗?
A.是
B.不是
解答:(A)
2)[真或假]没有必要有一个用于应用维数降低算法的目标变量。
A.真
B.假
解答:(A)
LDA是有监督降维算法的一个例子。
3)在数据集中有4个变量,如A,B,C和D.执行了以下操作:
步骤1:使用上述变量创建另外两个变量,即E = A + 3 * B和F = B + 5 * C + D。
步骤2:然后只使用变量E和F建立了一个随机森林模型。
上述步骤可以表示降维方法吗?
A.真
B.假
解答:(A)
因为步骤1可以用于将数据表示为2个较低的维度。
4)以下哪种技术对于减少数据集的维度会更好?
A.删除缺少值太多的列
B.删除数据差异较大的列
C.删除不同数据趋势的列
D.都不是
解答:(A)
如果列的缺失值太多(例如99%),那么可以删除这些列。
5)[真或假]降维算法是减少构建模型所需计算时间的方法之一。
A.真
B.假
解答:(A)
降低数据维数将花费更少的时间来训练模型。
6)以下哪种算法不能用于降低数据的维数?
A. t-SNE
B. PCA
C. LDA
D.都不是
解答:(D)
所有算法都是降维算法的例子。
7)[真或假] PCA可用于在较小维度上投影和可视化数据。
A.真
B.假
解答:(A)
有时绘制较小维数据非常有用,可以使用前两个主要分量,然后使用散点图可视化数据。
8)最常用的降维算法是PCA,以下哪项是关于PCA的?
1.PCA是一种无监督的方法
2.它搜索数据具有最大差异的方向
3.主成分的最大数量<=特征能数量
4.所有主成分彼此正交
A. 1和2
B. 1和3
C. 2和3
D. 1、2和3
E. 1、2和4
F.以上所有
解答:(F)
9)假设使用维数降低作为预处理技术,使用PCA将数据减少到k维度。然后使用这些PCA预测作为特征,以下哪个声明是正确的?
A.更高的“k”意味着更正则化
B.更高的“k”意味着较少的正则化
C.不知道
解答:(B)
较高的k导致较少的平滑,因此能够保留更多的数据特征,从而减少正则化。
10)在相同的机器上运行并设置最小的计算能力,以下哪种情况下t-SNE比PCA降维效果更好?
B.具有100000项310个特征的数据集
C.具有10,000项8个特征的数据集
D.具有10,000项200个特征的数据集
解答:(C)
t-SNE具有二次时空复杂度。
11)对于t-SNE代价函数,以下陈述中的哪一个正确?
A.本质上是不对称的。
B.本质上是对称的。
C.与SNE的代价函数相同。
解答:(B)
SNE代价函数是不对称的,这使得使用梯度下降难以收敛。对称是SNE和t-SNE代价函数之间的主要区别之一。
12)想像正在处理文本数据,使用单词嵌入(Word2vec)表示使用的单词。在单词嵌入中,最终会有1000维。现在想减小这个高维数据的维度,这样相似的词应该在最邻近的空间中具有相似的含义。在这种情况下,您最有可能选择以下哪种算法?
A. t-SNE
B. PCA
C. LDA
D.都不是
解答:(A)
t-SNE代表t分布随机相邻嵌入,它考虑最近的邻居来减少数据。
13)[真或假] t-SNE学习非参数映射。
A.真
B.假
解答:(A)
t-SNE学习非参数映射,这意味着它不会学习将数据从输入空间映射到地图的显式函数。从该网站获取更多信息。
14)以下对于t-SNE和PCA的陈述中哪个是正确的?
A.t-SNE是线性的,而PCA是非线性的
B.t-SNE和PCA都是线性的
C.t-SNE和PCA都是非线性的
D.t-SNE是非线性的,而PCA是线性的
解答:(D)
选项D是正确的。从此处获取说明
15)在t-SNE算法中,可以调整以下哪些超参数?
A.维度数量
B.平稳测量有效数量的邻居
C.最大迭代次数
D.以上所有
解答:(D)
选项中的所有超参数都可以调整。
16)与PCA相比,t-SNE的以下说明哪个正确?
A.数据巨大(大小)时,t-SNE可能无法产生更好的结果。
B.无论数据的大小如何,T-NSE总是产生更好的结果。
C.对于较小尺寸的数据,PCA总是比t-SNE更好。
D.都不是
解答:(A)
17)Xi和Xj是较高维度表示中的两个不同点,其中Yi和Yj是较低维度中的Xi和Xj的表示。
1.数据点Xi与数据点Xj的相似度是条件概率p(j | i)。
2.数据点Yi与数据点Yj的相似度是条件概率q(j | i)。
对于在较低维度空间中的Xi和Xj的完美表示,以下哪一项必须是正确的?
A.p(j | i)= 0,q(j | i)= 1
B.p(j | i)<q(j | i)
C.p(j | i)= q(j | i)
D.P(j | i)> q(j | i)
解答:(C)
两点的相似性的条件概率必须相等,因为点之间的相似性必须在高维和低维中保持不变,以使它们成为完美的表示。
18)LDA的以下哪项是正确的?
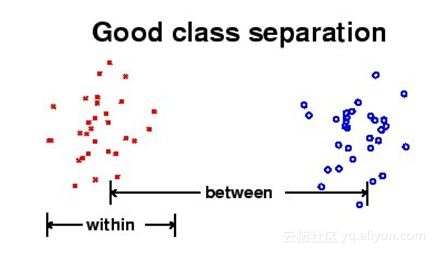
A.LDA旨在最大化之间类别的距离,并最小化类内之间的距离
B. LDA旨在最小化类别和类内之间的距离
C. LDA旨在最大化类内之间的距离,并最小化类别之间的距离
D.LDA旨在最大化类别和类内之间的距离
解答:(A)
19)以下哪种情况LDA会失败?
A.如果有辨识性的信息不是平均值,而是数据的方差
B.如果有辨识性的信息是平均值,而不是数据方差
C.如果有辨识性的信息是数据的均值和方差
D.都不是
解答:(A)
20)PCA和LDA的以下比较哪些是正确的?
1. LDA和PCA都是线性变换技术
2. LDA是有监督的,而PCA是无监督的
3. PCA最大化数据的方差,而LDA最大化不同类之间的分离,
A. 1和2
B. 2和3
C. 1和3
D.只有3
E. 1、2和3
解答:(E)
21)当特征值大致相等时会发生什么?
A. PCA将表现出色
B. PCA将表现不佳
C.不知道
D.以上都没有
解答:(B)
当所有特征向量相同时将无法选择主成分,因为在这种情况下所有主成分相等。
22)以下情况中PCA的效果好吗?
1. 数据中的线性结构
2. 如果数据位于曲面上,而不在平坦的表面上
3. 如果变量以同一单元缩放
A. 1和2
B. 2和3
C. 1和3
D. 1、2和3
解答:(C)
23)当使用PCA获得较低维度的特征时会发生什么?
1. 这些特征仍然具有可解释性
2. 特征将失去可解释性
3. 特征必须携带数据中存在的所有信息
4. 这些特征可能不携带数据中存在的所有信息
A. 1和3
B. 1和4
C. 2和3
D. 2和4
解答:(D)
当获取较低维度的特征时,大部分时间将丢失一些数据信息,您将无法解释较低维的数据。
24)想象一下,在高度和重量之间给出以下散点图 。
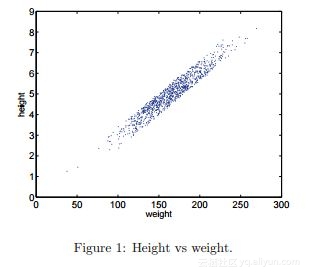
选择沿哪个轴捕获最大变化的角度?
A.〜0度
B.〜45度
C.〜60度
D.〜90度
解答:(B)
选项B的数据的差异可能最大。
25)以下哪个选项是真的?
1.在PCA中需要初始化参数
2.在PCA中不需要初始化参数
3. PCA可以被困在局部最小问题
4. PCA不能被困到局部最小问题
A. 1和3
B. 1和4
C. 2和3
D. 2和4
解答:(D)
PCA是一个确定性算法,它不具有初始化的参数,并且不像大多数机器学习算法那样具有局部最小问题。
问题26背景
以下快照显示了两个特征(X1和X2)与类别信息(红色、蓝色)的散点图,还可以看到PCA和LDA的方向。
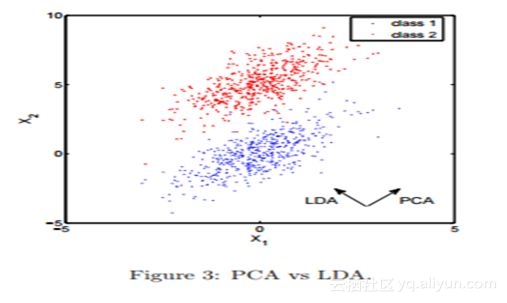
26)以下哪种方法会导致更好的类别预测?
A.建立PCA分类算法(PCA方向的主成分)
B.建立LDA分类算法
C.不知道
D.都不是
解答:(B)
如果目标是对这些点进行分类,PCA投影只会带来更多的危害——大多数蓝色和红色点将重叠在第一个主成分上,这样会混淆分类器。
27)在图像数据集上应用PCA时,以下哪个选项是正确的?
1.它可以用于有效地检测可变形物体。
2.仿射变换是不变的。
3.它可用于有损图像压缩。
4.阴影不是不变的。
A. 1和2
B. 2和3
C. 3和4
D. 1和4
解答:(C)
28)在哪种条件下,SVD和PCA产生相同的投影结果?
A.当数据为零时
B.当数据均值为零时,
C.两者总是相同
D.都不是
解答:(B)
当数据具有零均值向量时二者会相同,否则在进行SVD之前必须首先对数据进行中心处理。
问题背景29
考虑2维空间中的3个数据点:(-1,-1)、(0,0)、(1,1)。
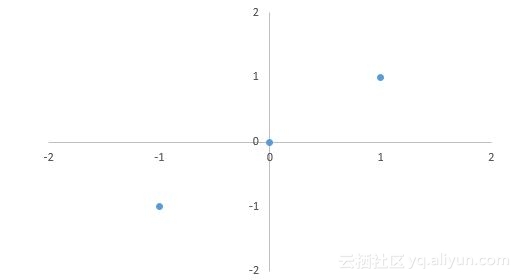
29)这些数据的第一个主成分是什么 ?
1.[√2/2,√2/2]
2.(1 /√3,1 /√3)
3.([-√2/ 2,√2/ 2])
4.(- 1 /√3, - 1 /√3)
A. 1和2
B. 3和4
C. 1和3
D. 2和4
解答:(C)
第一个主要组成部分是v = [√2/ 2,√2/ 2] T,请注意,主成分应该被归一化。
30)如果通过主成分[√2/2,√2/2]T将原始数据点投影到1维子空间中,他们在1维子空间中的坐标是什么?
A.(- √2)、(0)、(√2)
B.(√2)、(0)、(√2)
C.(√2)、(0)、(- 2)
D.(- 2)、(0)、(- 2)
解答:(A)
投影后三点的坐标应为z1 = [-1,-1] [√2/2,√2/2] T = - √2,同理可得z2= 0,z3 = √2。
31)对于投影数据为(( √2),(0),(√2))。现在如果在二维空间中重建,并将它们视为原始数据点的重建,那么重建误差是多少?
A. 0%
B. 10%
C. 30%
D. 40%
解答:(A)
重建误差为0,因为所有三个点完全位于第一个主要分量的方向上或者计算重建;
32)LDA的思想是找到最能区分两类别之间的线,下图中哪个是好的投影?
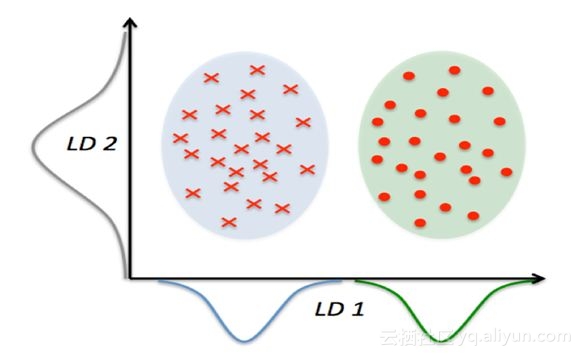
A.LD1
B.LD2
C.两者
D.都不是
解答:(A)
问题33背景
PCA是一种很好的技术,因为它很容易理解并通常用于数据降维。获得特征值λ1≥λ2≥•••≥λN并画图。
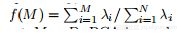
看看f(M)(贡献率)如何随着M而增加,并且在M = D处获得最大值1,给定两图:
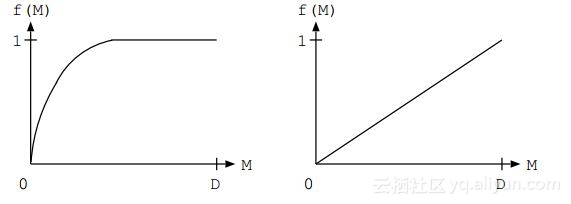
33)上述哪个图表显示PCA的性能更好?其中M是主要分量,D是特征的总数。
A.左
B.右
C.任意A和B
D.都不是
解答:(A)
如果f(M)渐近线快速到达1,则PCA是好的;如果第一个特征值较大且其余较小,则会发生这种情况。如果所有特征值大致相等,PCA是坏的。
34)以下哪个选项是真的?
A. LDA明确地尝试对数据类别之间的差异进行建模,而PCA没有。
B.两者都试图模拟数据类之间的差异。
C.PCA明确地试图对数据类别之间的差异进行建模,而LDA没有。
D.两者都不试图模拟数据类之间的差异。
解答:(A)
35)应用PCA后,以下哪项可以是前两个主成分?
1.(0.5,0.5,0.5,0.5)和(0.71,0.71,0,0)
2. (0.5,0.5,0.5,0.5)和(0,0,-0.71,0.71)
3. (0.5,0.5,0.5,0.5)和(0.5,0.5,-0.5,-0.5)
4. (0.5,0.5,0.5,0.5)和(-0.5,-0.5,0.5,0.5)
A. 1和2
B. 1和3
C. 2和4
D. 3和4
解答:(D)
对于前两个选择,两个向量不是正交的。
36)以下哪一项给出了逻辑回归与LDA之间的差异?
1. 如果类别分离好,逻辑回归的参数估计可能不稳定。
2. 如果样本量小,并且每个类的特征分布是正常的。在这种情况下,线性判别分析比逻辑回归更稳定。
A. 1
B. 2
C. 1和2
D.都不是
解答:(C)
参考该视频 (需翻墙)
37)在PCA中会考虑以下哪个偏差?
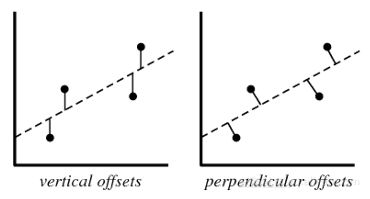
A.垂直偏移
B.正交偏移
C.两者
D.都不是
解答:(B)
总是将残差视为垂直偏移,正交偏移在PCA的情况下是有用的
38)假设正在处理10类分类问题,并且想知道LDA最多可以产生几个判别向量。以下哪个是正确答案?
A. 20
B.9
C. 21
D. 11
E. 10
解答:(B)
LDA最多产生c-1个判别向量,可以参考此链接(需翻墙)获取更多信息。
问题39背景
给定的数据集包括“胡佛塔”和其他一些塔的图像。现在要使用PCA(特征脸)和最近邻方法来构建一个分类器,可以预测新图像是否显示“胡佛塔”。该图给出了输入的训练图像样本

39)为了从“特征脸”算法获得合理的性能,这些图像将需要什么预处理步骤?
1. 将塔对准图像中相同的位置。
2. 将所有图像缩放或裁剪为相同的大小。
A. 1
B. 2
C. 1和2
D.都不是
解答:(C)
40)下图中主成分的最佳数量是多少?
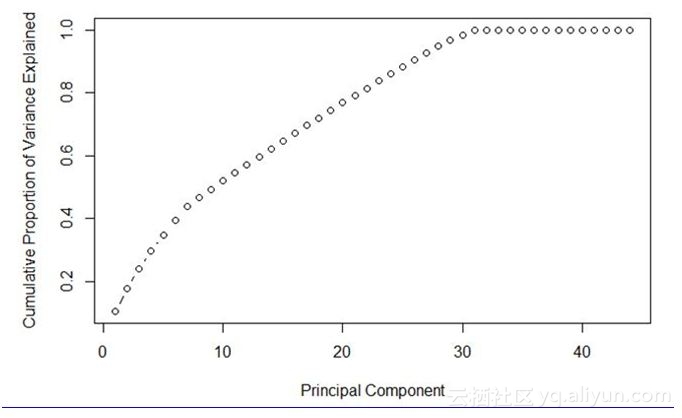
A. 7
B. 30C. 40
D.不知道
解答:(B)
可以在上图中看到,主成分的数量为30时以最小的数量得到最大的方差。
尾注
希望你喜欢参加的这个测试,并参考答案中获取一些帮助。测试侧重于降维的概念和实践知识。如果有任何关于以上测试题的疑问,可以在评论中注明;如果有任何的建议,可以在评论中让我们知道你的反馈。
本文由北邮@爱可可-爱生活老师推荐,阿里云云栖社区组织翻译。