1.堆的概念
大顶堆:每个节点的值都大于或等于其左右孩子节点的值,下图是完全二叉树是大顶堆
小顶堆:每个节点的值都小于或等于其左右孩子节点的值
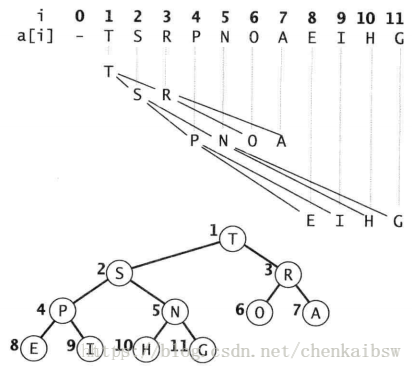
如果我们用指针来表示大顶堆,那么每个结点需要三个指针来找到它的上下结点(父结点和两个子结点各需要一个),但如果使用完全二叉树,表达就会边的特别方便,如下图所示。完全二叉树使用数组而不需要指针就可以表示大顶堆。(注意为了方便,是从下标1开始存放元素的),此时下标i对应的节点的双亲节点如果存在,那么在数组中的下标是[i/2],下标i对应的孩子节点存在,那么对应的下标是2i和2i+1.
2.优先队列
提出的背景:许多应用程序都要处理有序的元素,但不一定要求他们全部有序,或者不一定要一次将他们排序,很多情况下我们会收集一些元素,处理元素的最大值,然后收集更多的元素,再处理当前元素的最大的值。
优先队列的操作(大顶堆):
插入某值:插入的元素放在数组尾部,通过上浮操作,将其上浮到合适的位置,构建大顶堆。
删除最大值:获取下标为1的元素(目前的最大值)存入临时变量,然后将下标为1的元素和最后一个元素交换,将最后一个元素设置为空并对下标为1的元素进行下沉操作,重建大顶堆。
代码示例:
class MaxPQ<Key extends Comparable<Key>> //Comparable后面也要加泛型
{
private Key[] pq;
private int N = 0;
//构造函数
public MaxPQ(int maxN)
{
pq = (Key[])new Comparable[maxN+1]; //注意如果数组0坐标不哟把那个,都会有这个操作
}
public boolean isEmpty()
{
return N == 0;
}
public int size()
{
return N;
}
public void insert(Key v)
{
pq[++N] = v; //将元素插入到队尾//0下标并没有放东西
swim(N); //上浮
}
//这边删除一个元素,其实堆排序就是使用了同样的原理
//每次取出的根结点都大顶堆得最大的值,如此反复就达到了排序的目的.
public Key delMax()
{
Key max = pq[1]; //将队头元素取出
exch(1,N); //交换尾元素和队头元素
pq[N] = null; //防止游离
N--; //数目减去一
sink(1); //将队头元素下沉
return max;
}
//这边的比较和交换都是输入的是下标,而不是数值
private boolean less(int i,int j)
{
return pq[i].compareTo(pq[j])<0; //pq[i]<pq[j]
}
private void exch(int i,int j)
{
Key t = pq[i];
pq[i] = pq[j];
pq[j] = t;
}
//上浮操作
private void swim(int k)
{
while(k>1&&less(k/2,k)) //如果父结点小于子结点//如果k为1了就不用比较了
{
exch(k,k/2);
k/=2;
}
}
//下沉操作
private void sink(int k)
{
while(2*k<=N)
{
int j = 2*k;
if(j<N&&less(j,j+1))
j++;
if(!less(k,j))
break;
exch(k,j);
k = j;
}
}
public void show()
{
for(int i=1;i<=N;i++) //下标为0的值并没有使用,因为用起来不方便
{
System.out.print(pq[i]+" ");
}
}
}
class PaiXu
{
public static void main(String[] args)
{
MaxPQ<String> str = new MaxPQ(11);
str.insert("2"); //插入操作用的上浮
str.insert("1");
str.insert("7");
str.insert("3");
str.insert("5");
str.insert("6");
str.insert("9");
System.out.println("打印当前值:");
str.show();
System.out.println(); //换行
//str.delMax();
System.out.println("\n取出当前的最大值");
System.out.println(str.delMax());
System.out.println("\n取出当前的最大值");
System.out.println(str.delMax());
}
}
3.PriorityQueue优先队列
Java已经封装了PriorityQueue类实现了优先队列的操作。
常用构造函数:
PriorityQueue() //默认是小顶堆
使用默认的初始容量(11)创建一个 PriorityQueue,并根据其自然顺序对元素进行排序。
PriorityQueue(int initialCapacity, Comparator<? super E> comparator) //通过自定义比较器设置为大顶堆或小顶堆
使用指定的初始容量创建一个 PriorityQueue,并根据指定的比较器对元素进行排序。
常用方法:
peek() 获取但不移除此队列的头;如果此队列为空,则返回 null。
poll() 获取并移除此队列的头,如果此队列为空,则返回 null。
剑指offer两道题,第一题利用小顶堆获取一组数据中的最小值,第二题利用大顶堆+小顶堆获取中位数。
1)题目描述(剑指offer面试题40题)
分析:定义一个大小为4的优先队列(设置为大顶堆),先放入4个元素,从中取出最大值和新放入的元素比较,如果新放入的元素小于该最大值,就将新元素放入优先队列,否则不放入。每次获取最大元素和插入新元素的操作的时间复杂度都是O(logk),对于n个输入数字而言,总的时间复杂度是O(nlogk)。
代码实现:
class Solution{
public ArrayList<Integer> GetLeastNumbers_Solution(int[] array,int k){
ArrayList<Integer> list = new ArrayList<>();
if(k<=0||array==null||array.length<k)
return list;
PriorityQueue<Integer> p = new PriorityQueue<>(k,new myCompare());
for(int i=0;i<array.length;i++){
if(p.size()<k){
p.add(array[i]);
}
else{
int temp = p.peek(); //每次取出的数都是最大数
if(array[i]<temp){ //如果数小于最大值
p.poll();
p.add(array[i]);
}
}
}
for(int i=0;i<k;i++){
list.add(p.poll());
}
return list;
}
class myCompare implements Comparator<Integer>{
public int compare(Integer i1,Integer i2){
return i2-i1; //这里从小到大排序
}
}
}
该代码使用与海量数据的处理,从n(很大的数据)中取出k个最小值或最大值,因为n非常大在硬盘中,无法一次读入内存,所以可以先读取部分数据到内存,从中取出最小的k个数,再读入剩下的部分到内存,比较后取出所有数据的最小的k个数。
2)题目描述 数据流中的中位数(剑指offer面试题41题)
分析:
1)使用一个大顶堆和一个小顶堆,如果数据流中的数据array数组数据长度是奇数,将下标为奇数的放入小顶堆,下标为偶数的放入小顶堆,并保证大顶堆的最大值小于小顶堆的最小值,此时大顶堆的最小值就是中位数。如果数据流中的数据array数组数据长度是偶数,将小标为奇数的放入小顶堆,下标为偶数的放入大顶堆,并保证大顶堆的最大值小于小顶堆的最小值,此时取出大顶堆的最大值和小顶堆最小值的和的平均值。
2)如何保证大顶堆的最大值小于最小堆的最小值,放入大顶堆前先放入小顶堆中,然后从小顶堆中取出的值最小值放入大顶堆,这样就保证大顶堆的中最大值小于小顶堆中的最小值。
代码示例:
class PaiXu{
public static void main(String[] args) {
Solution s = new Solution();
s.Insert(5);
System.out.println(s.GetMedian());
s.Insert(2);
System.out.println(s.GetMedian());
s.Insert(3);
System.out.println(s.GetMedian());
s.Insert(4);
System.out.println(s.GetMedian());
}
}
class Solution{
int m = 0;
PriorityQueue<Integer> minQueue = new PriorityQueue<>();
PriorityQueue<Integer> maxQueue = new PriorityQueue<>(new Comparator<Integer>(){
public int compare(Integer i1,Integer i2){
return i2 - i1;
}
});
public void Insert(Integer num){
if((m&1)==0){ //如果是偶数,插入小顶堆
maxQueue.offer(num);
int temp = maxQueue.poll();
minQueue.offer(temp);
}
else{ //如果是奇数,插入大顶堆
minQueue.offer(num);
int temp = minQueue.poll();
maxQueue.offer(temp);
}
m++;
}
public Double GetMedian(){
if(((m-1)&1)==0){
return new Double(minQueue.peek());
}
else{
int temp1 = maxQueue.peek();
int temp2 = maxQueue.peek();
return new Double(temp1+temp2)/2;
}
}
}
总结:
1)一般使用优先队列可以在不排序的情况下获取数组的最大值,最小值,中间值和第k大值。
取最大值通过大顶堆,n个数构建大顶堆的时间复杂度是O(nlogn),取最大值的时间复杂度是O(1)
取最小值通过小顶堆,n个数构造小顶堆的时间复杂度是O(nlogn),取最小值的时间复杂度是O(1)
取中间值通过大顶堆加小顶堆,构建两个堆的时间复杂度O(nlogn),取中间值的时间复杂度O(1)
取第k大元素,可以通过大顶堆,取元素第k次就是第k大的值,总的时间复杂度O(nlogn)
2)对比排序的Partition函数,使用该函数可以通过O(n)的时间复杂度获取未排序的数组第k大的数。
3)n个元素的数组开始构建大顶堆,完全二叉树从最下层最右边的非中断节点开始构建,时间复杂度是O(n),n个数据一个一个插入构建大顶堆时间复杂度O(nlogn),往对里面插入一个数据,删除一个数据的时间复杂度是O(logn),取出最大值时间复杂度O(1)。