

作者 | Someday
导读
本文主要介绍了商业智能(BI)以及Turing Data Analysis(TDA)的概念和应用。BI通过收集、整理、分析和呈现数据,帮助企业做出更好的决策和战略规划。然而,传统的BI建设思路存在问题,如业务变更数据需求时需要重新开发,以及分析底层数据的效率低等。因此,TDA作为一站式自助分析平台应运而生,它基于明细数据,按照分析主题建设公共数据集,用户可以自由拖拽分析并一键保存结果,同时也可以分享给其他人查看。然而,TDA的建设也面临着分析维度指标要全,数据口径要准,以及查询性能等挑战。针对这些挑战,我们提出全、准、效、快的目标,并通过流程机制和功能建设以及MPP数据引擎来实现这些目标。
全文4766字,预计阅读时间15分钟。
01 背景与目标
BI即商业智能(Business Intelligence),通过收集、整理、分析和呈现数据,辅助企业领先于竞争对手,做出更好的业务决策和战略规划。收集和整理的过程就是数仓的建设,而分析和呈现数据就是可视化分析平台建设。
业内比较常见的BI建设思路:业务想看某指标数据变化,向中台提需,数据RD从ODS>DWD>DWS>ADS逐层建模,然后定制化的开发ADS结果表落地到Palo/Mysql,最后配置成多个图表保存到报表中供业务查看。这种建设思路虽然满足了业务的看数需求,但面临两个问题:1、当业务变更数据需求时,需要重新定制化开发ADS结果表,会重复占用研发人力;2、只解决了业务看数的需求,如果想进一步下钻分析波动的原因,就比较困难,因为底层表是仅包含当前图表数据的聚合表,想分析只能下载明细数据,再通过Excel或者其他方式分析,效率比较低。
TDA(Turing Data Analysis ),目标就是为了解决上述BI中分析链路长的问题,而建设的一站式自助分析平台。
TDA的建设思路:基于DWD明细宽表,按照分析主题建设公共数据集(单天数据千万+),用户基于公共数据集自由拖拽分析,可以一键将分析结果保存到个人仪表盘或者发布成公共仪表盘,分享给其他人查看;其他人可以在公共仪表盘查看波动趋势、下钻分析到可视化分析页面继续探索波动原因,一站式完成“看趋势、拆维度、查明细”的分析三板斧。
下图是TDA建设思路的整体流程:
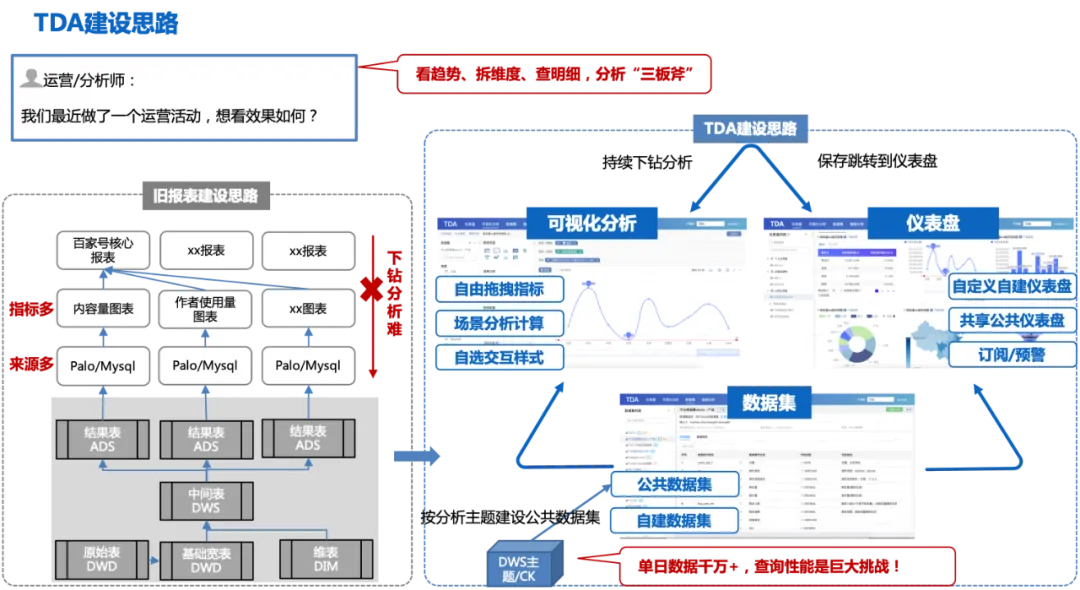
这种建设思路下同样会面临一些挑战:
1、分析维度指标要全,否则就需要建设多个数据集,造成数据集多而散,和之前的报表建设一样的问题;
2、数据口径要准、数据权威;
3、单日数据千万+,查询性能是巨大挑战。
针对以上挑战,我们也制定了相应的目标,来满足业务高效分析诉求:
1、全(分析维度指标要全,覆盖业务80%+的需求);
2、准(口径统一、数据准确);
3、效(数据产出时效T+10h);
4、快(10亿级数据查询10s内)。
TDA平台会从流程机制和功能建设上来保证数据集建设的全、准、效,结合MPP数据引擎来保证查询性能,通过BI的可视化拖拽、场景分析、自助建模等能力提升用户的分析效率。
02 技术方案
基于以上分析,TDA的产品定位是一个可以实现用户一站式自助查询的BI平台,用户可以自由拖拽数据集,进行可视化数据分析,并进行核心仪表盘的搭建。从以下角度帮助用户实现查询分析的一站式体验:
业务看板迭代提效(自助化):数据报表迭代模式发生变化,从PM提需RD排期模式逐步转换为PM/运营自助化操作(做看板/分析数据)。
数据洞察分析提效(极速):单次数据查询从分钟级降低到秒级,指标波动分析效率提升20倍,单次指标波动归因分析端到端从2小时->5分钟内。
业务一站式自助分析(一站式):实现数据趋势观测、维度下钻分析、明细导出等功能,实现了数据监控、数据分析一体化体验。
本产品的功能矩阵如下:
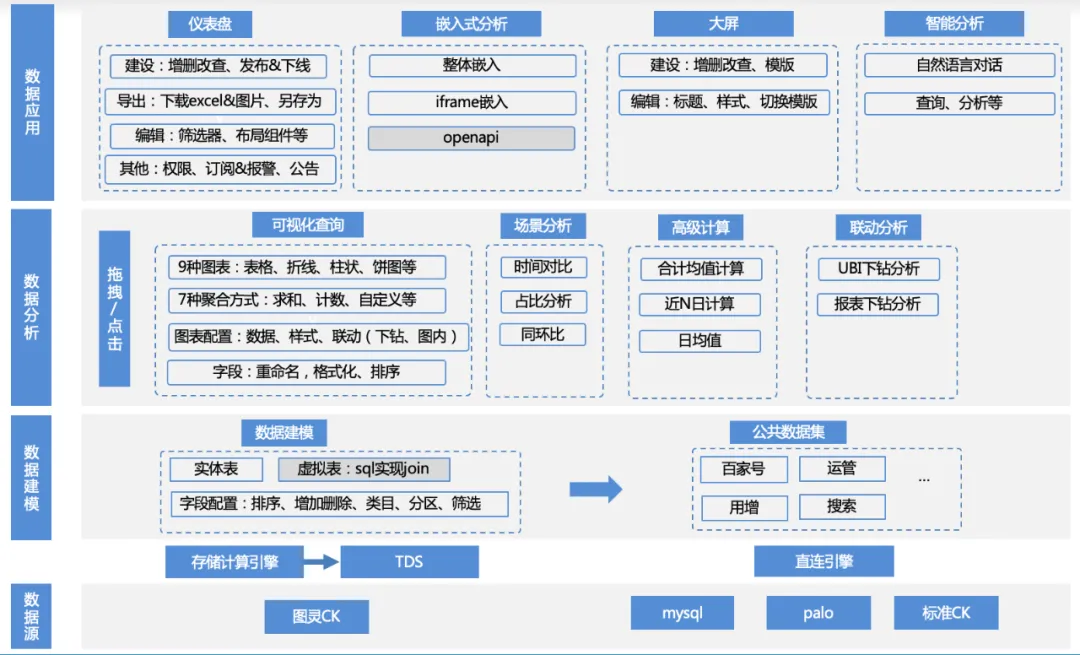
1、数据源接入:业务使用TDS将上游图灵表数据通过计算引擎计算后,将数据写入到clickhouse/mysql/palo等引擎,通过直连的方式接入;或者业务提供自己的palo/mysql数据源接入。
a.数据源管理:数据源增删改查、clickhouse/mysql/palo等引擎驱动适配
2、数据建模:对接完数据源,数据可以通过写SQL、直接原始表的方式加载到产品中。但这些表通常还需要做一些简单的二次处理,变成可以被分析的数据集。
a.数据集的管理:增删改查、数据预览、schema查看、一键可视化分析等功能
b.数据集字段管理:增删改查、字段排序、自定义字段等
c.数据集类目管理:字段所属类目的增删改查、自定义排序等
d.数据集目录管理:数据集目录的增删改查、自定义排序等
3、数据分析:用户基于数据集,自由拖拽指标、维度、筛选,选择合适的图表类型及场景分析方式,进行分析计算。
a.数据配置:切换数据集、添加自定义字段
b.图表配置:表格、折线图、柱状图、饼图等多种图表类型配置、图例颜色设置、数据格式设置等
c.场景分析:日均值、同环比、占比、合计等多种场景分析能力支持
d.归因分析:自助归因分析能力
e.交互分析:下钻分析等
4、数据应用:用户可将分析结果保存至仪表盘、或嵌出到第三方平台、或保存至大屏、或直接用于智能分析等。
a.仪表盘管理:仪表盘增删改查、自定义排序、发布下线、数据导出、订阅预警等
b.嵌出式分析:ifame嵌出、sdk嵌出等多种嵌出模式
c.大屏:实时大屏
d.智能分析:LUI对话式分析
2.1 整体设计
TDA整体架构如下图所示:
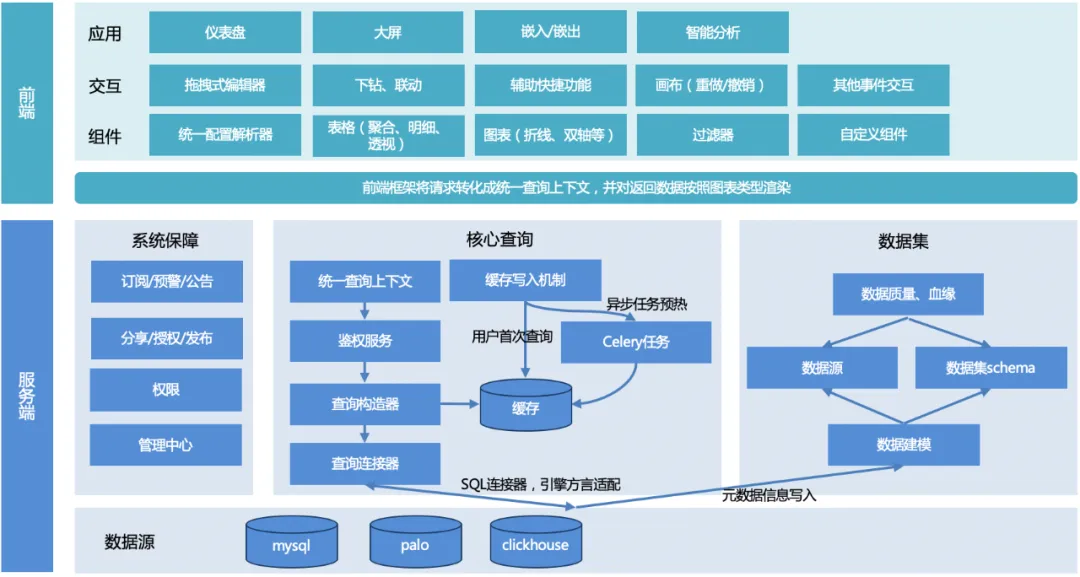
整体流程:用户发起查询,经服务端统一查询上下文,构造查询对象,底层引擎方言适配,返回统一数据格式,再由前端渲染框架根据图表类型适配渲染。
服务端:
1、统一查询上下文:为了后期扩展其他图表功能时,方便通用功能的复用,设计统一的查询上下文。
2、查询构造器:根据前端传过来的请求参数,构造出查询对象(可以是多个,如对表格分页,需要构造两个查询对象,一个是分页查询对象,一个是计数查询对象)。
3、查询连接器:
a.当前只有SQL连接器,用以满足拼SQL查询的引擎(mysql、palo、clickhouse等),不同引擎、语法或一些函数可能会不同,通过不同引擎规则配置去适配;
b. 未来可以扩展其他连接器满足非sql查询。
4、缓存写入:保证查询性能,两种写入方式,用户首次访问时写入,或通过celery定时任务预热缓存。
5、数据集模块:提供数据支持,和底层数据源建立链接,保证数据质量。
6、系统保障模块:订阅、预警、公告实现数据预警能力,分享、发布、授权提升数据的流转效率,管理中心和权限为数据提供底层管理和权限支持。
前端:
1、组件库:提供配置解析、不同图表渲染组件、过滤器组件以及自定义组件能力。
2、交互:封装了页面交互能力,包括拖拽式编辑器、下钻联动、辅助快捷功能、画布能力以及其他事件交互。
3、应用:实现不同的可视化应用,面向不同的用户和使用场景,如仪表盘、大屏等。
2.2 详细设计
2.2.1 核心查询
一站式自助BI,通过公共数据集建模思路,实现“趋势、维度、明细”三板斧的分析思路,会面临诸多挑战,包括:
-
多源数据、多图表呈现、多种场景分析计算:BI系统底层数据源引擎不止一种,为了灵活的扩展数据源,且呈现样式上也需要丰富的图表支撑,同时为了满足不同场景下的分析计算,需要支持如同环比、日均值等常用的分析能力。
-
千万级数据秒级查询:公共数据集的建设思路,便于分析的同时也引入了新的挑战。单日千万数据量,对于查询性能的巨大挑战。
针对以上问题,制定了对应的解决方案:
-
统一查询:统一查询上下文,构造查询对象,底层引擎方言适配,返回统一数据格式,前端渲染框架根据图表类型适配渲染。
-
查询优化:Ⅰ>缓存+自动上卷,覆盖70%公共仪表盘请求;Ⅱ>优化构建SQL查询,充分利用引擎侧聚合能力;III>多域名并发请求,多协程响应处理。
统一查询:
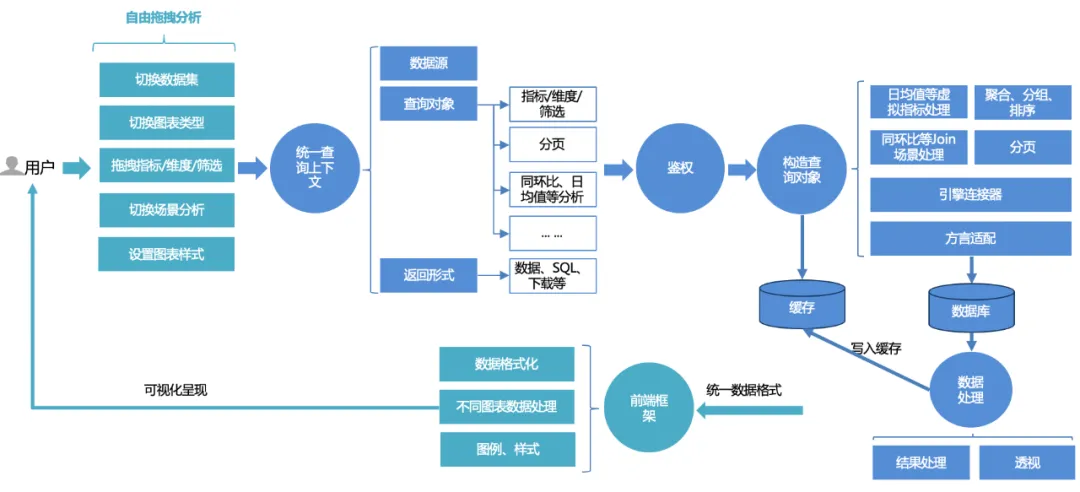
平台用户统一查询流程如下:
1、用户在页面上自由拖拽分析:切换数据集,切换不同图表类型,拖拽指标、维度、筛选,查询即可;或想使用一些高级的场景分析能力,一键切换配置。
2、前端请求会处理成统一的查询上下文:包含数据源、查询对象、返回形式,其中查询对象封装了基础的指标、维度、筛选信息,以及高级的同环比、日均值等分析配置。
3、统一的鉴权服务:基于仪表盘和数据集双重鉴权的内核,同时支持行列权限更细粒度的权限控制。
4、构造查询对象:先根据指标、维度、筛选三元组完成基础SQL构造(聚合、分组、过滤),然后根据排序规则,组装排序逻辑,有些高级分析选项(如同环比、日均值等)添加额外的组装逻辑,然后处理分页,整个过程中需要结合方言适配,查询数据时根据不同的引擎链接器查询不同的数据库(如mysql、palo、clickhouse等)。
5、查询&处理数据:通过链接器查询数据后,对数据进行处理(日期格式处理、折线图的透视等)。
6、缓存:处理后的数据写入缓存;或查询时如果直接命中缓存则直接读取缓存数据并返回。
7、前端渲染框架统一渲染:返回统一的数据格式,前端完成图表、样式等适配渲染。
查询优化:Ⅰ>缓存+自动上卷,覆盖70%公共仪表盘请求。
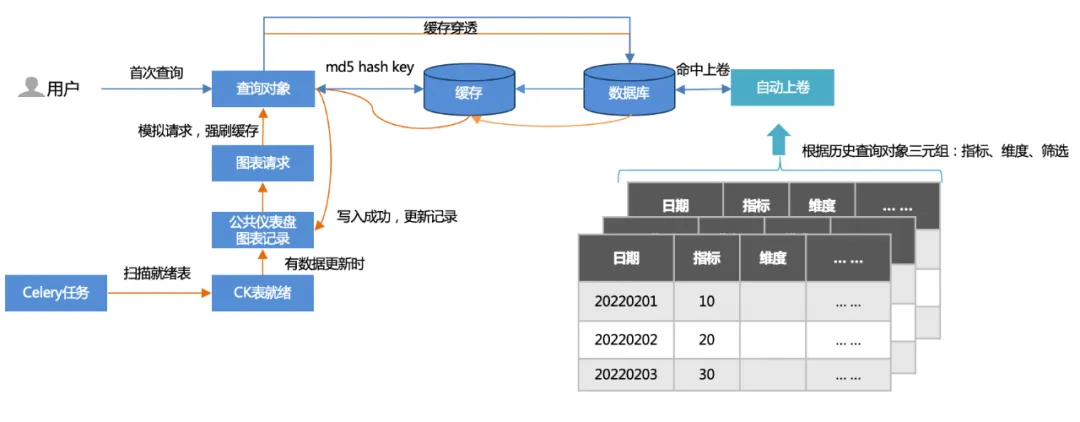
1、两种缓存方式:
首次查询:用户首次访问(缓存穿透),查询数据库,然后写入缓存。
离线任务预热:扫描公共仪表盘图表记录,模拟图表请求(每次更新500+)强刷缓存。
2、自动上卷:
根据历史查询的三元组(指标、维度、筛选),建立上卷表,查询命中上卷表,查询的数据量级大幅减少,性能加快。
查询优化:Ⅱ>优化构建SQL查询,充分利用MPP架构引擎(如clickhouse/palo等)的聚合能力。

公共数据集分析场景下,查询出数据后,再在内存中聚合计算,几乎不太可能(如(a + b) / c需要基于明细数据a、b、c聚合计算),需要借助引擎侧MPP架构的查询能力,将聚合计算提炼到引擎侧执行,如同环比按月聚合,数据量涉及百亿,引擎侧聚合计算后的数据量减少几十倍,性能也随之提升几倍。
查询优化:III>多域名并发请求,多协程响应处理。
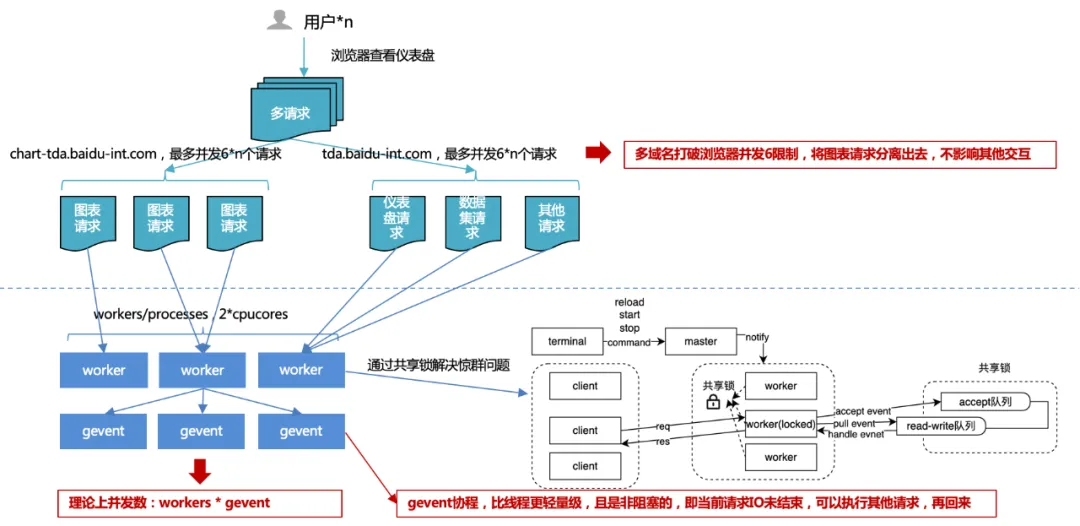
1、浏览器并发6限制:通过多域名方式,将图表请求与其他请求分流,保证平台交互流畅,图表请求并发度提升,从而提升总体性能。
对操作系统端口资源考虑:PC总端口数为65536,那么一个TCP(http也是tcp)链接就占用一个端口。操作系统通常会对总端口一半开放对外请求,以防端口数量不被迅速消耗殆尽。
过多并发导致频繁切换产生性能问题:一个线程对应处理一个http请求,那么如果并发数量巨大的话会导致线程频繁切换。而线程的上下文切换有时候并不是轻量级的资源。这导致得不偿失,所以请求控制器里面会产生一个链接池,以复用之前的链接。所以我们可以看作同域名下链接池最大为4~8个,如果链接池全部被使用会阻塞后面请求任务,等待有空闲链接时执行后续任务。
避免同一客服端并发大量请求超过服务端的并发阈值:在服务端通常都对同一个客户端来源设置并发阀值避免恶意攻击,如果浏览器不对同一域名做并发限制可能会导致超过服务端的并发阀值被BAN掉。
客户端良知机制:为了防止两个应用抢占资源时候导致强势一方无限制的获取资源,导致弱势一方永远阻塞状态。
2、服务端多进程+多协程并发:
使用多进程开发时,可能会遇到“惊群问题”,即多个进程等待同一个事件。当事件发生时,所有的进程都会被内核唤醒,但唤醒后只有一个进程获得了该事件并进行处理,其他进程发现获取时间失败后又继续进入了等待状态,监听同一个事件的进程数越多,争用CPU的情况越严重,造成了严重的上下文谢欢成本。
故针对这种情况,uwsgi服务设计并实现了共享锁机制,保证同一时刻只有一个进程在监听事件,解决了惊群问题。
但即使如此,进程数也不能无限制扩增,一般建议等于2倍的cpu内核数。
那既然进程数有限制,如何提高吞吐呢?一般情况下IO是阻塞的,你在读数据库或者读文件时,当前的进程、线程会一直等待,直到 IO 操作返回结果才能继续执行后续的代码。如果我们通过多线程的方式增大吞吐,遇到IO阻塞,线程会卡住,其他并发请求就没线程处理了,通过协程实现异步的 IO,即对于每一个线程来说,在自己 IO 时不再等待 IO 结果,而是先去处理新来的请求,等 IO 完成了再跳回到需要等待 IO 的这段代码。通过这种方式,我们充分利用了程序中的每一个线程,让它们永远有事可做。这种方式提高了整体的吞吐量,降低了整体耗时,对单个耗时没有影响。
2.2.2 系统保障
订阅预警:
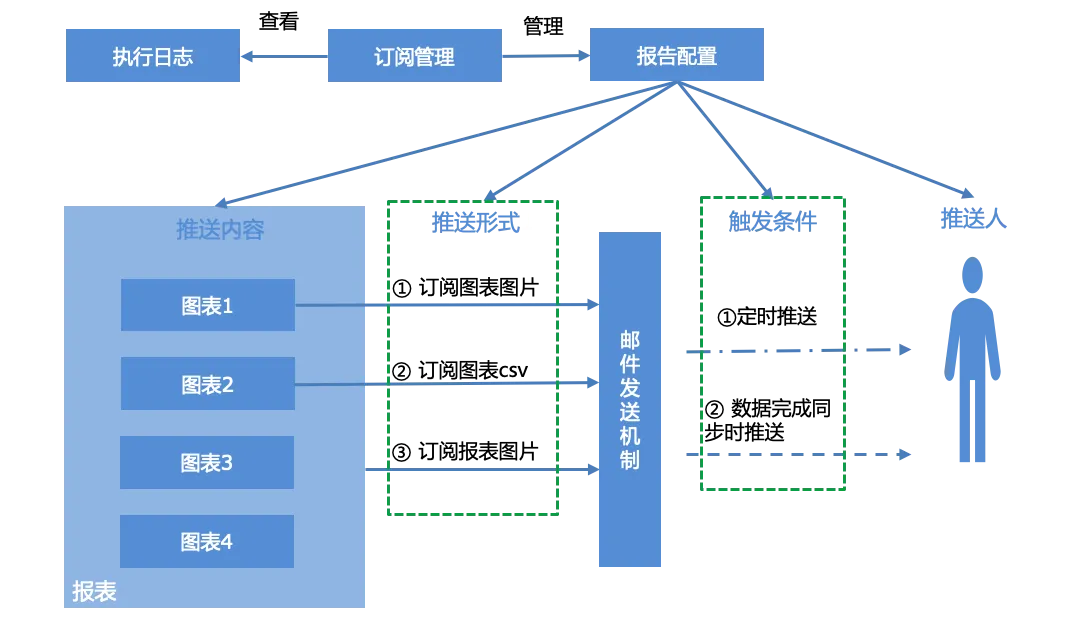
用户可针对报表进行报告配置,可根据订阅管理界面,对生成的订阅报告进行管理,并可查看系统的执行日志即报告的推送情况。
报告配置主要包括四部分,推送内容、推送形式、触发条件和推送人:
推送内容:单个图表、整张报表
推送形式:三种形式推送
图表截图
图表的csv数据邮件附件
报表截图
触发条件:
定时推送,根据cron表达式定时推送。
在数据完成同步时推送,在该报表所有图表关联的数据集完成数据同步时,触发推送条件,完成邮件通知。
推送人:邮箱账号,多个时以“,”分割。
权限:

数据权限分级管控:基于数据集&仪表盘双层鉴权内核,支持行列权限按规则粒度申请授权,灵活控制用户权限。
高效协同:打通MPS(统一权限管理系统)统一权限服务,实现权限的审批、到期回收、离职冻结等能力,打通如流办公,加速权限审批的高速流转。
03 总结和规划
3.1 总结
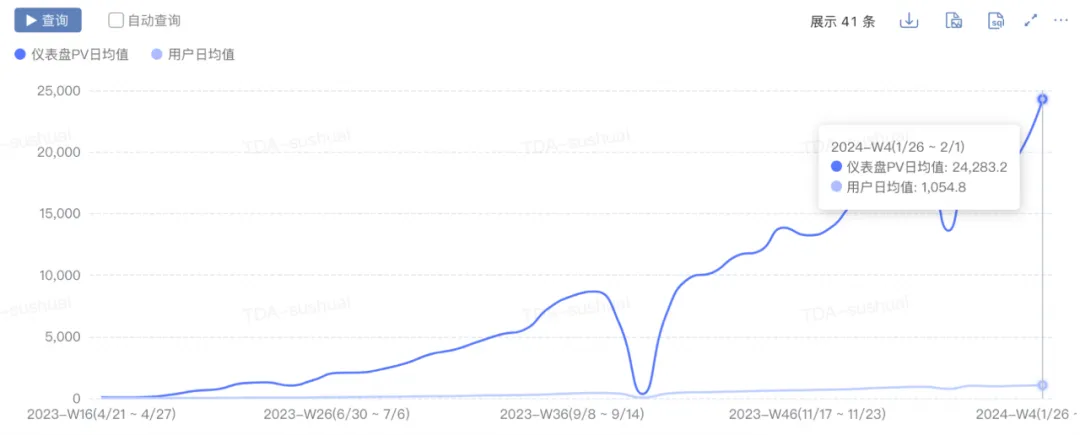
经过不断迭代,TDA已基本具备一站式自助分析能力,实现了以下几个指标:
- 规模增长:pv由0增长到2w+,uv由0增长到1000+,每日新增图表由0增长到300+。
-
性能提升:仪表盘首屏90分位耗时从10s+下降到5s。
-
业务提效:促成核心业务80%+自助化率,波动分析效率提升20倍,单次指标波动归因分析端到端从2小时->5分钟内。
3.2 规划
随着AI原生技术在各个领域的渗透,未来TDA也会结合AI技术,提升平台的智能分析体验,主要有如下几点:
-
数据自助接入:会放开数据接入,扩充数据源类型等。
-
AI+BI:归因分析、嵌出式分析、分析报告等BI能力,结合大模型AI,完善智能分析产品。
-
管理驾驶舱(探索):OKR目标仪表盘。
——————END——————
推荐阅读
JetBrains 全家桶 2024 首个大版本更新 (2024.1) 老乡鸡“开源”了 微软都打算付钱了,为何还是被骂“白嫖”开源? 【已恢复】腾讯云后台崩了:大量服务报错、控制台登入后无数据 德国也要“自主可控”,州政府将 3 万台 PC 从 Windows 迁移到 Linux deepin-IDE 终于实现了自举! Visual Studio Code 1.88 发布 好家伙,腾讯真把 Switch 变成了「思维驰学习机」 RustDesk 远程桌面启动重构 Web 客户端 微信基于 SQLite 的开源终端数据库 WCDB 迎来重大升级