随着社交网络等新型网络的迅猛发展,文本大数据呈几何级数增长,语料库的 加工处理一般都是由文科背景的研究人员完成,因此,急需快速简便的大数据内容批处理平台。

NLPIR大数据语义智能分析平台是一个全链条的分析工具,完全本地化部署, 不上传用户数据,安全可靠。融合了网络精准采集、自然语言理解、文本挖掘和 网络搜索的技术,提供客户端工具、云服务以及二次开发接口,包含了大数据背 景下有关语义分析的各个环节的工具。语义智能分析的全链条指的是从语料数据的采集预处理,经过自然语言处理 到文本挖掘,信息检索再到可视化呈现和导出以便适合于不同人员的使用需求的 全部处理过程。
数据收集和预处理部分
数据收集和预处理中包括了通过主题采集和站点采集从互联网上 爬取信息和处理本地上传或录入的信息,同时还提供了不同文档格式转换和编码 转换的工具。
自然语言处理部分
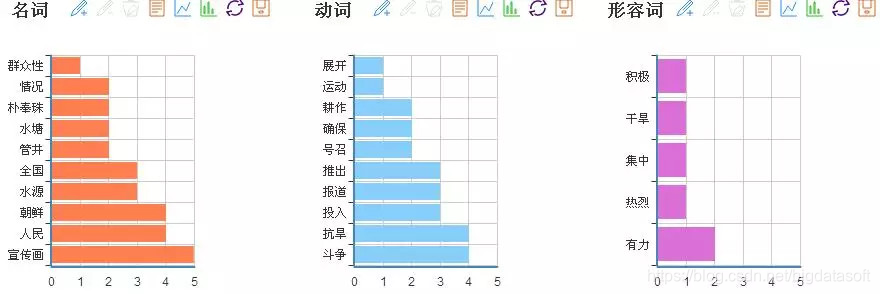
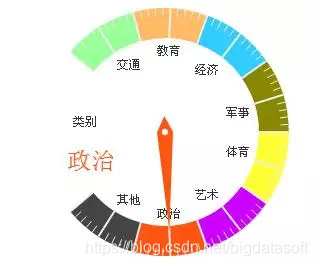
自然语言处理部分可以进行批量分词、新词发现和主题抽取和语言 统计;文本挖掘部分可以进行文本分类、文本聚类、摘要实体生成、智能过滤、情感分析、文档去重;
 *
*
信息检索部分*
信息检索部分可以进行模糊查询快速全文检索,附带还有 文档去重的工具。
可视化呈现部分
可视化呈现部分可以画出各种用户喜欢的信息表示图案,如词 云图等。
导出部分
导出部分贯穿在各个功能当中,将输出结果导出,用户可以采用导出的内容写入分析报告当中。对于有开发背景的还可以通过API进行二次开发满足特定需要,自动生成分析报告。
在使用层面,NLPIR大数据语义智能分析开发平台先后历时20年,融入了20年的科研成果。平台由多个中间件组成,各个中间件API可以无缝地融合到客户的各类 复杂应用系统之中,可兼容Windows、Linux、Android、Maemo5、FreeBSD等不 同操作系统平台,可以供Java、C、C#等各类开发语言使用。无论对没有任何编程背景但要大量处理语 言、媒体信息的文科生辅助处理分析,还是对需要二次开发才能完成特定领域的 信息服务都可以满足要求。现在已经服务了 全球40万家机构用户和100余家高校用户,免费给研究人员从事研究工作。
NLPIR平台实现中文语义分析的一站式应用
猜你喜欢
转载自blog.csdn.net/bigdatasoft/article/details/102957623
今日推荐
周排行