近日,智源视觉团队成功训练并发布世界最大最强的 CLIP 模型 EVA-CLIP-18B,拥有 180 亿参数。EVA-CLIP-18B 大幅突破了图像、视频和 3D 上的零样本识别能力,在 27 个图像分类基准测试上取得了80.7%的零样本准确率,这一成绩显著优于其前代模型 EVA-CLIP-5B 和 Google, Apple 等公司取得 SOTA 的其他开源 CLIP 模型。
EVA-CLIP-18B 的成功训练进一步验证了 EVA 系列 weak-to-strong 规模扩增策略的潜力和有效性。团队将公开 EVA-CLIP 18B 模型的权重和训练代码,为未来的计算机视觉和视觉-语言多模态研究提供强大的视觉基础模型。
技术亮点
Weak-to-strong 策略:以小教大,以弱引强
EVA-CLIP-18B沿用了 EVA 系列 weak-to-strong 的视觉模型scale up 策略,实现了视觉模型规模的渐进式扩增。该策略遵循“以小教大,以弱引强”的规模扩增思想。
具体而言,团队首先使用一个较小的 EVA-CLIP-5B 模型作为教师,以掩码图像建模为训练目标,蒸馏出一个较大的 EVA-18B 纯视觉模型。随后,EVA-18B 作为 EVA-CLIP-18B 视觉-语言对比训练中视觉编码器的初始化,帮助 EVA-CLIP 模型进一步 scale up。
研究结果表明,使用较弱的 EVA-CLIP 模型引导更大的 EVA 模型完成视觉训练,再使用得到的 EVA 模型作为更大 EVA-CLIP 训练的初始化,这种渐进式地用弱模型引导大模型的scale up方式,可以有效解决大型视觉模型训练中的不稳定问题,并加速模型训练收敛。
Scaling Behaviour
除了最大规模的 EVA- CLIP-18B 模型,团队还训练了中等规模的 EVA-CLIP-8B 模型,并在实验中设置不同规模的模型使用近乎相同规模的训练数据,考察 EVA weak-to-strong vision scaling 在扩大模型规模方面的有效性。
实验结果表明,在保持数据量几乎不变的条件下,按照 EVA weak-to-strong 方法仅对模型规模进行扩增,模型性能实现了持续、稳定地提升,验证了 EVA weak-to-strong 方法在扩大视觉模型规模方面的有效性。同时,模型性能并未呈现饱和趋势,体现了 EVA weak-to-strong 方法的潜力。

EVA-CLIP系列模型随着模型规模扩大性能变化曲线,和现存最大(InternVL-C)和最强(DFN5B)的CLIP模型对比
更高的训练效率
受益于 weak-to-strong 算法在 scale up 模型方面的高效性,相比于其他 CLIP 模型,EVA-CLIP-18B 具有更高的训练效率,在 360 块 40G A100上600小时完成训练。
值得注意的是,EVA-CLIP-18B 在仅仅使用 6B 训练样本的情况下,就取得了最先进的性能,而其他先进的CLIP模型通常需要在 10B+ 的样本上进行训练。
有限数据规模下的无限潜力
数据集方面,EVA-CLIP-18B 模型的训练仅使用了可公开获取的 LAION-2B,COYO-700M 和少量的 LAION-COCO(仅20M)数据集,相比于前代模型并没有对数据规模进行扩大。
值得注意的是,此前最强的CLIP模型——Apple 公司的 DFN-5B 是在公司私有数据集上训练的,比我们使用的公开数据集规模更大、质量更好。这进一步证明了EVA weak-to-strong vision scaling 方法的优越性,以及EVA-CLIP模型在有限数据规模下的出色泛化能力。
在模型训练的最后阶段,团队引入少量视频数据(23M),显著增强了模型零样本视频分类的性能。未来通过扩大数据集规模可以进一步提升模型性能,推动 EVA-CLIP-18B 模型的性能边界。
全方位最强性能的 CLIP 模型
相比于世界其他先进 CLIP 模型,EVA-CLIP-18B 取得了全方位的最强性能。我们的评估基准涵盖了图像分类、视频分类、图文检索领域的33个常用评估数据集。EVA-CLIP-18B在27个图像分类的基准测试上取得了80.7%的零样本分类准确率,相比于此前最强的CLIP模型(Apple公司DFN-5B)取得了1.5%的领先。

EVA-CLIP零样本图片分类性能
在视频分类任务上,EVA-CLIP-18B 在 UCF-101、K-400/600/700 四个常用视频理解基准上进行测试。相比于最先进的 CLIP 模型,上海人工智能实验室的同期工作 InternVL,取得了平均1.8%的分类准确率提升。
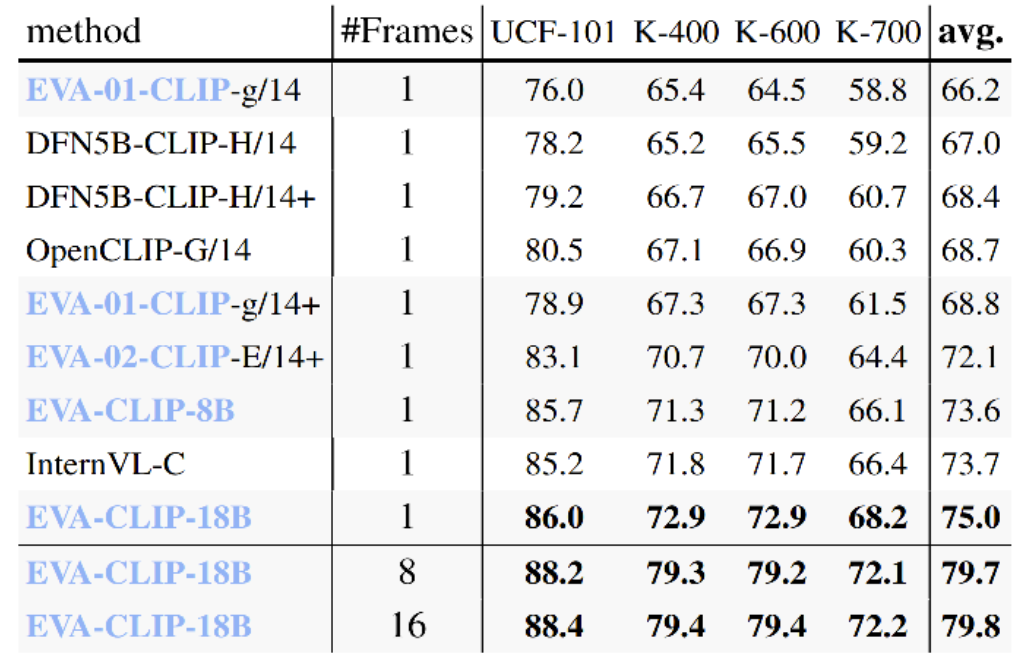
EVA-CLIP零样本视频分类性能
在另一项常用于 CLIP 模型评估的图文检索任务上,EVA-CLIP-18B 同样取得了世界领先的最强性能。
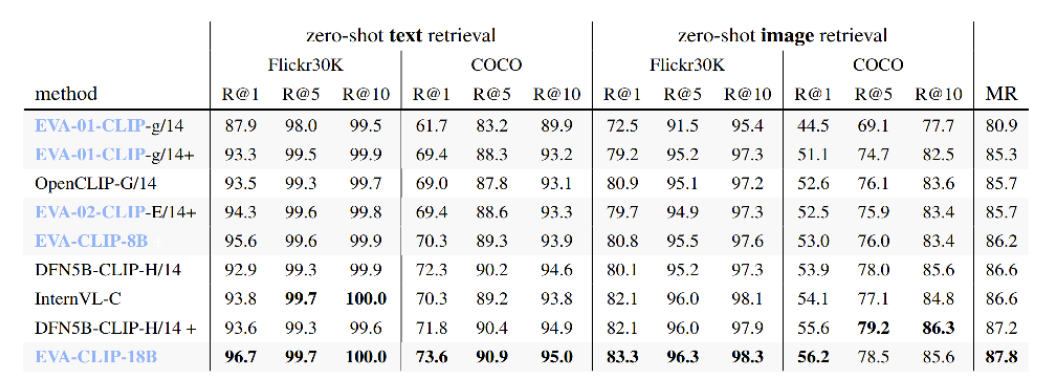
EVA-CLIP零样本图文检索性能
在3D表示学习领域,使用和Uni3D一样的训练设置,我们使用更大的EVA-CLIP模型作为教师。实验结果表明,CLIP教师模型的scale up能够对3D表示学习有恒定的提升作用,稳定增强模型3D零样本分类的性能。
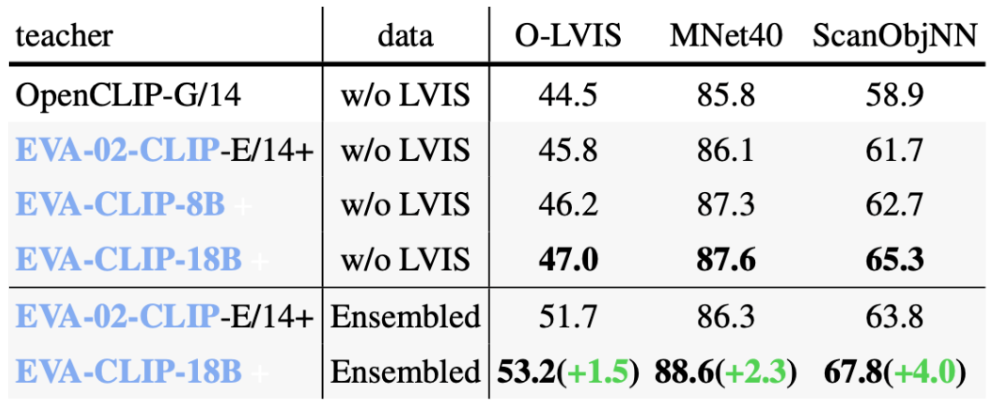
EVA-CLIP模型增强零样本3D分类的性能