文章目录
一、前言
我们推出了一个名为CLIP的神经网络,它可以有效地从自然语言监督中学习视觉概念。CLIP可以应用于任何视觉分类基准,只需提供要识别的视觉类别名称,类似于GPT-2和GPT-3的“零样本”功能。
尽管深度学习彻底改变了计算机视觉,但当前的方法存在几个主要问题:
- 典型的视觉数据集是劳动密集型的,创建成本高昂,同时只教授一小部分视觉概念;
- 标准视觉模型擅长一项任务且仅擅长一项任务,并且需要付出大量努力才能适应新任务;
在基准测试中表现良好的模型在压力测试中的表现令人失望,这让人们对计算机视觉的整个深度学习方法产生了怀疑。
我们提出了一个旨在解决这些问题的神经网络:
它在各种图像上进行训练,并接受互联网上大量提供的各种自然语言监督。 通过设计,可以用自然语言指示网络执行各种分类基准测试,而无需直接针对基准性能进行优化,类似于 GPT-2 和 GPT-3 的“零样本”功能。
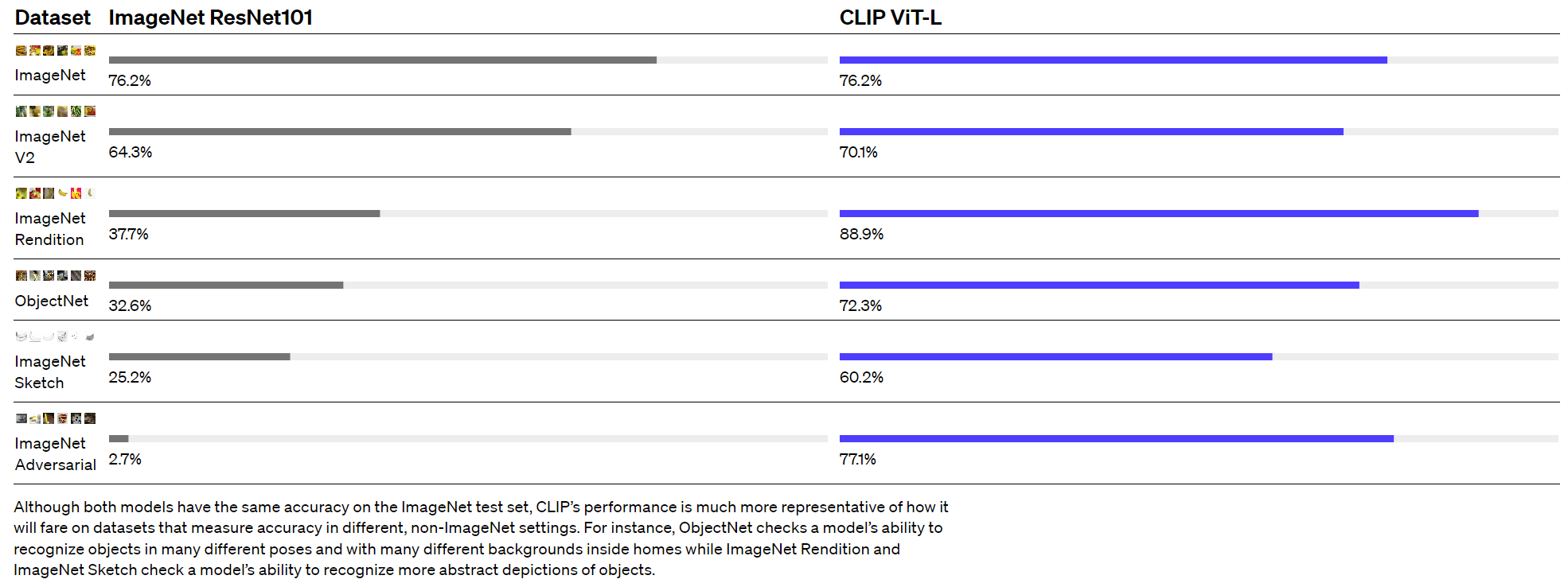
这是一个关键的变化 :通过不直接针对基准进行优化,我们表明它变得更具代表性:我们的系统将这种“稳健性差距”缩小了高达 75%,同时在 ImageNet 零镜头上匹配原始 ResNet-50 的性能,而无需使用任何原始的 1.28M 标记示例。
二、背景及相关工作
CLIP(对比语言-图像预训练)建立在大量关于零镜头迁移、自然语言监督和多模式学习的工作之上。
零数据学习的想法可以追溯到十多年前,但直到最近才主要在计算机视觉中作为一种泛化到看不见的对象类别的方式进行研究。
一个关键的见解是利用自然语言作为灵活的预测空间来实现泛化和转移。 2013 年,Richer Socher 和斯坦福大学的合著者通过在 CIFAR-10 上训练模型在词向量嵌入空间中进行预测来开发概念证明,并证明该模型可以预测两个不可见的类。
同年,DeVISE 扩展了这种方法,并证明可以微调 ImageNet 模型,使其可以泛化以正确预测原始 1000 个训练集之外的对象。
对 CLIP 最有启发性的是 Ang Li 和他的合著者在 FAIR 上的工作,他们在 2016 年演示了使用自然语言监督来实现零镜头迁移到几个现有的计算机视觉分类数据集,例如规范的 ImageNet 数据集。 他们通过微调 ImageNet CNN 从 3000 万张 Flickr 照片的标题、描述和标签文本中预测更广泛的视觉概念(视觉 n-gram),并在 ImageNet 上达到 11.5% 的准确率,从而实现了这一目标 零射击。
最后,CLIP 是一组论文的一部分,这些论文重新审视了过去一年中从自然语言监督中学习视觉表示。
这一系列工作使用更现代的架构,如 Transformer,包括探索自回归语言建模的 VirTex,研究屏蔽语言建模的 ICMLM,以及研究我们用于 CLIP 的相同对比目标的 ConVIRT,医学影像。
三、方法
我们表明,扩展一个简单的预训练任务足以在各种图像分类数据集上实现有竞争力的零样本性能。
我们的方法使用大量可用的监督来源:文本与在互联网上找到的图像配对。
此数据用于为 CLIP 创建以下代理训练任务:给定一张图像,预测一组 32,768 个随机抽样的文本片段中的哪一个在我们的数据集中与它实际配对。
为了解决这个任务,我们的直觉是 CLIP 模型需要学习识别图像中的各种视觉概念并将它们与它们的名称相关联。 因此,CLIP 模型可以应用于几乎任意的视觉分类任务。
例如,如果数据集的任务是对狗和猫的照片进行分类,我们会检查每张图像,CLIP 模型是否预测文本描述 “a photo of a dog” 或 “a photo of a cat” 更有可能配对 用它。

CLIP 旨在缓解计算机视觉标准深度学习方法中的一些主要问题:
3.1 Costly datasets
深度学习需要大量数据,而视觉模型传统上是在人工标记的数据集上训练的,这些数据集的构建成本很高,而且只对有限数量的预定视觉概念提供监督。
ImageNet 数据集是该领域最大的成果之一,需要超过 25,000 名工作人员为 22,000 个对象类别标注 1400 万张图像。 相比之下,CLIP 从互联网上公开的文本图像对中学习。 先前的工作已经广泛研究了减少对昂贵的大型标记数据集的需求,特别是自我监督学习对比方法、自我训练方法和生成建模。
3.2 Narrow
ImageNet 模型擅长预测 1000 个 ImageNet 类别,但这就是它“开箱即用”的全部功能。
如果我们希望执行任何其他任务,机器学习从业者需要构建一个新的数据集,添加一个输出头,并对模型进行微调。
相比之下,CLIP 可以适应执行各种视觉分类任务,而无需额外的训练示例。
要将 CLIP 应用于新任务,我们需要做的就是“告诉”CLIP 的文本编码器任务视觉概念的名称,它将输出 CLIP 视觉表示的线性分类器。
这种分类器的准确性通常可以与完全监督的模型相媲美。
3.3 Poor real-world performance
深度学习系统经常被报道可以达到人类甚至超人的表现。在视觉基准上,但在野外部署时,它们的性能可能远低于基准设定的预期。 换句话说,“基准性能”和“实际性能”之间存在差距。
我们推测,之所以会出现这种差距,是因为模型仅通过优化基准性能来“作弊”,就像一名学生通过仅研究过去几年考试中的问题来通过考试一样。
相比之下,CLIP 模型可以在基准上进行评估,而无需对其数据进行训练,因此它不能以这种方式“作弊”。 这导致其基准性能更能代表其在野外的性能。
为了验证“作弊假设”,我们还测量了 CLIP 在能够“学习”ImageNet 时的性能变化。
当线性分类器安装在 CLIP 的特征之上时,它将 CLIP 在 ImageNet 测试集上的准确率提高了近 10%。
然而,这个分类器在 7 个其他数据集的评估套件中的平均表现并没有更好,这些数据集测量了“稳健”的性能。
四、要点
4.1 CLIP is highly efficient
CLIP 从未经过滤的、高度多样化和高度嘈杂的数据中学习,旨在以零样本的方式使用。
我们从 GPT-2 和 3 中了解到,在此类数据上训练的模型可以实现令人信服的零样本性能; 然而,此类模型需要大量的训练计算。 为了减少所需的计算,我们专注于算法方法来提高我们方法的训练效率。
我们报告了导致显着计算节省的两种算法选择。
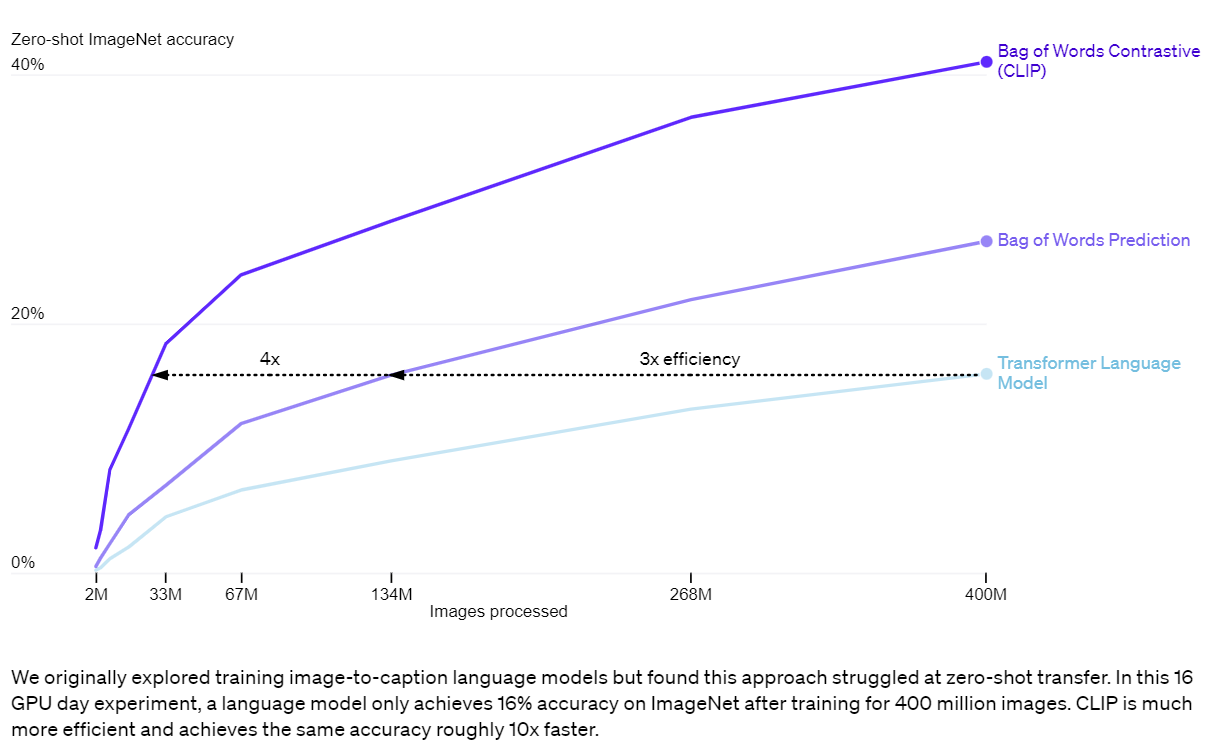
第一个选择是采用对比目标来连接文本和图像。我们最初探索了一种图像到文本的方法,类似于 VirTex,但遇到了缩放它以实现状态的困难- 艺术表演。 在中小型实验中,我们发现 CLIP 使用的对比目标在零样本 ImageNet 分类方面的效率提高了 4 到 10 倍。
第二个选择是采用 Vision Transformer,与标准 ResNet 相比,它使我们的计算效率进一步提高了 3 倍。 最后,我们性能最好的 CLIP 模型在 256 个 GPU 上训练了 2 周,这与现有的大规模图像模型相似。
4.2 CLIP is flexible and general
因为它们直接从自然语言中学习了广泛的视觉概念,所以 CLIP 模型比现有的 ImageNet 模型更加灵活和通用。 我们发现他们能够零射击执行许多不同的任务。
为了验证这一点,我们测量了 CLIP 在 30 多个不同数据集上的零样本性能,包括细粒度对象分类、地理定位、视频中的动作识别和 OCR 等任务。
特别是,学习 OCR 是标准 ImageNet 模型中不会发生的令人兴奋的行为的一个例子。 上面,我们从每个零样本分类器中可视化了一个随机的非 cherry picked 预测。
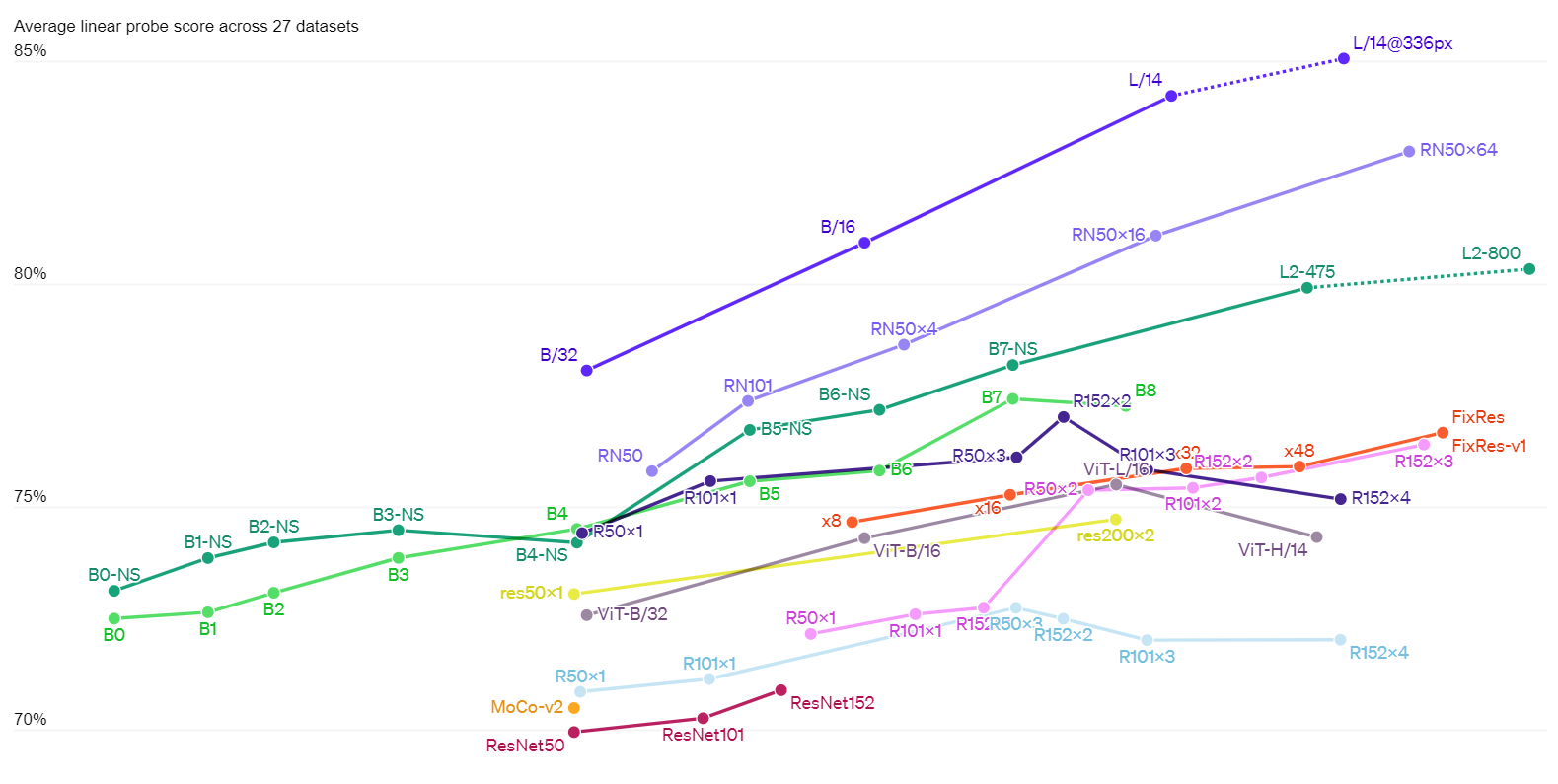
这一发现也反映在使用线性探针的标准表示学习评估中。 在我们测试的 26 个不同传输数据集中的 20 个上,最佳 CLIP 模型优于公开可用的最佳 ImageNet 模型 Noisy Student EfficientNet-L2。

五、限制
虽然 CLIP 通常在识别常见物体方面表现良好,但它在更抽象或系统的任务(例如计算图像中的物体数量)和更复杂的任务(例如预测照片中最近的汽车的距离)方面表现不佳。
在这两个数据集上,零样本 CLIP 仅略优于随机猜测。 与任务特定模型相比,零样本 CLIP 在非常细粒度的分类上也表现不佳,例如区分汽车模型、飞机变体或花卉种类。
CLIP 对其预训练数据集中未涵盖的图像的泛化能力仍然很差。
例如,尽管 CLIP 学习了一个功能强大的 OCR 系统,但在对来自 MNIST 数据集的手写数字进行评估时,零样本 CLIP 仅达到 88% 的准确率,远低于数据集上人类的 99.75%。
最后,我们观察到 CLIP 的零样本分类器可能对措辞或措辞敏感,有时需要反复试验“提示工程”才能表现良好。
六、更广泛的影响
CLIP 允许人们设计自己的分类器并消除了对特定任务训练数据的需求。 这些类的设计方式会严重影响模型性能和模型偏差。 例如,我们发现当给定一组标签时,包括 Fairface 种族标签 C 。
以及一些令人震惊的术语,如“犯罪”、“动物”等,该模型倾向于将 0-20 岁的人的图像分类为令人震惊的类别,比率约为 32.3%。 然而,当我们将类“child”添加到可能的类列表中时,这种行为下降到约 8.7%。
此外,鉴于 CLIP 不需要特定任务的训练数据,它可以更轻松地解锁某些特定任务。 其中一些任务可能会引发与隐私或监视相关的风险,我们通过研究 CLIP 在名人识别方面的表现来探讨这一问题。
当从 100 个候选对象中进行选择时,CLIP 在“野外”名人图像分类中的 top-1 准确率为 59.2%,而当从 1000 个可能的选项中进行选择时,CLIP 的 top-1 准确度为 43.3%。
尽管通过与任务无关的预训练实现这些结果值得注意,但与广泛使用的生产级模型相比,这种性能并不具有竞争力。
我们进一步探讨了 CLIP 在我们的论文中提出的挑战,我们希望这项工作能够激发未来对此类模型的能力、缺点和偏差的表征的研究。
七、结论
借助 CLIP,我们测试了是否也可以利用互联网规模自然语言的任务不可知预训练(它推动了 NLP 的最新突破)来提高其他领域深度学习的性能。
到目前为止,我们对将这种方法应用于计算机视觉所取得的成果感到非常兴奋。
与 GPT 系列一样,CLIP 在预训练期间学习了各种各样的任务,我们通过零镜头迁移展示了这些任务。 我们对 ImageNet 的发现也感到鼓舞,这些发现表明零样本评估是衡量模型能力的更具代表性的指标。