1.简介
学习深度学习必看CLIP!论文链接arxiv.org/pdf/2103.00020v1.pdf。
简单来说就是传统的分类任务被用来预测指定的类别,有监督训练限制了模型的通用性和可用性,并且需要带有标签的数据来训练,该篇论文就想直接从原始文本中学习图像特征,具体就是从网络上采集大量的带有文字描述的图片,同时向网络输入原始文字和图像,网络来学习他们之间的关系。预测时通过输入一句话就能判断图像是否与其匹配了,具有很强的泛化性能。这就是zero shot,不用数据集中任何一张图片,就能够达到ResNet-50的精度。
2.方法
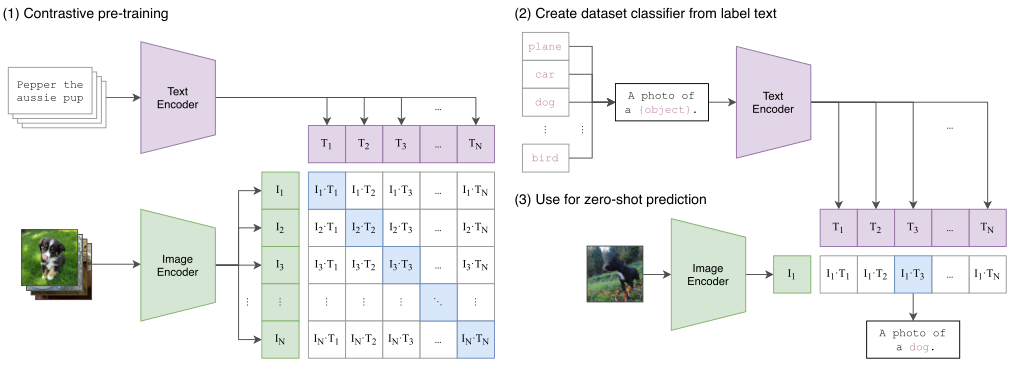
方法的核心思想是从自然语言的监督中学习感知。这种方法其实一点都不新,之前也有人做过,只不过之前的方法描述的很混淆,并且数据规模不大。那么为什么非要用自然语言监督的方法来训练一个视觉模型呢?第一个就是说你不需要再去标注数据了,直接从网上下载图像和文字的配对就行了,减少了很多的工作量。第二个就是将图片和文字绑定到了一起,模型学习的就是一个多模态的特征了。这样就很容易去做zero-shot的迁移任务了。
该方法不需要之前的那种黄金标签,而是从互联网上的大量文本中学习。与大多数无监督或自监督学习方法相比,从自然语言中学习也有重要的优势,因为它不仅“只是”学习表征,而且还将该表征与语言联系起来,从而实现灵活的零迁移。
2.1构建数据集
构建了一个新的数据集,其中包含4亿对(图像,文本)对,这些数据来自互联网上各种公开可用的资源。
2.2选择有效的预训练方法
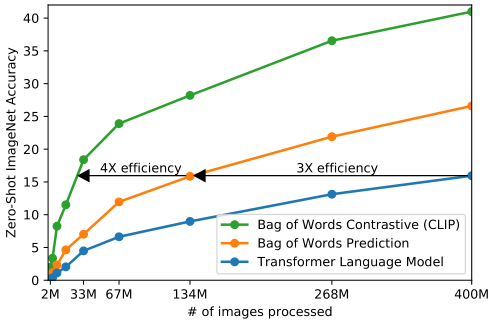
一开始作者选用了VirTex的方法,图像用CNN,文本用transformer来进行,CNN用来预测图像对应的文本,但是由于一个图像对应的描述实在是太多了,所以这样预训练的效果很差,于是作者决定用对比学习的方法来进行预训练。
从上图我们可以发现,蓝色的线是类似gpt的方法,基于transformer去做预测性的任务,逐字逐句的去预测文本。橘黄色的线是去预测已经全局化抽象成特征的文本(bag of words prediction)。可以发现训练效率提高了三倍。绿色的线是用对比学习的方法来判断图像和文本是否配对,这样效率是最高的。

上图是CLIP训练的一个伪代码。首先是两个编码器,用来对图像和文本进行编码。图像的编码器可以用ResNet或者ViT,文本的编码器可以用CBOW和Text Transformer。然后对提取的两个特征归一化并求一个余弦相似度,然后计算的结果和groundtruth做一个交叉熵损失函数计算loss,一个是image的loss,一个是text的loss,最后把两个loss求和求平均来训练网络。

2.3训练
作者训练了5个resnet和3个ViT来进行对比,因为数据集实在太大,所以不需要预训练和别的数据增强,只用了随即裁剪。而且这篇论文用了惊人的32768的batchsize,离谱。作者还用了混合精度等一系列策略来加速训练节省内存。最后效果最好的网络是ViT-L/14,作者还用336*336的高像素图像fine-tune了一个epoch,进一步提升了网络性能。最后这个网络也就是ViT-L/14@336px,这也就是CLIP用的模型了。
3.实验
3.1prompt engineering and ensembling
提示工程和集成,那么为什么要做提示工程呢?
首先是在用一个单词提示图片时,一个单词往往有多个含义,这样的提示可能会产生歧义,让图片生成不好的效果。第二是由于CLIP在做预训练是往往用的都是一个句子,如果在推理时用的是一个单词的话,由于文本的特征分布可能不一样,导致预测出来的效果可能就不好了。
![]()
所以为了避免这些问题,作者做了一个prompt template,这样就能在输入一个单词的情况下形成一句话。
prompt engineering还可以根据不同的数据集来变化,比如你想要在Oxford-IIIT Pets数据集上跑一下,那么你就可以将模板改为
![]()
如果你想要在OCR数据集上跑一下,那么你可以在你想要寻找的内容上打上双引号,这样模型能更加的理解你的意思。
ensembling的意思是在多个zero-shot分类器上进行集成,每个分类器通过不同的上下文提示,比如

集成发生在文本嵌入空间而不是概率空间。 这允许缓存一组平均文本嵌入,这样当在许多预测上平摊时,集成的计算成本与使用单个分类器相同。
4.限制
CLIP还是有不足之处。首先,作者在文中提到在分割等任务中,CLIP仅仅和基于ResNet50的网络差不多,和当前SOTA的模型还是有很多差距。如果要达到SOTA的性能,CLIP还需要1000倍的计算能力,这在当前来说显然是不可能的。
其次,CLIP在细分类任务和抽象概念的任务中的效果也不好。
第三是,如果数据集中的数据分布与4亿个图像的数据集相差非常大的话,那么CLIP的效果也是不好的。比如MNIST数据集,作者去重后发现,MNIST数据集真的没有在4亿张图片中。
第四是,作者还是希望完成一个能够输入图片输出图片标题的模型。
第五是CLIP还是需要用到大量的数据来训练,希望后面能够减少数据用量,比如用自监督或者伪标签的方法来训练。
第六是,CLIP是为了zero-shot来创建的,但是当在CLIP上进行one-shot、two-shot时,效果反而会下降,这是非常难以理解的,后续还需要很多的工作去进行优化。