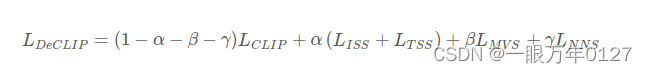本文是CLIP算法的学习笔记,从CLIP算法介绍到具体实现原理,再到应用方法和后续一些优化策略来学习CLIP系列算法。
CLIP是什么:
CLIP全称是Contrastive Language–Image Pre-training,一种基于对比文本-图像对的预训练方法。
CLIP怎么做的
主要包含Text Encoder和Image Encoder两个模块,分别提取文本和图像特征,然后基于比对学习让模型学习到文本-图像的匹配关系。原文使用大规模数据(4亿文本-图像对)进行训练,基于海量数据,CLIP模型可以学习到更多通用的视觉语义信息,给下游任务提高帮助。
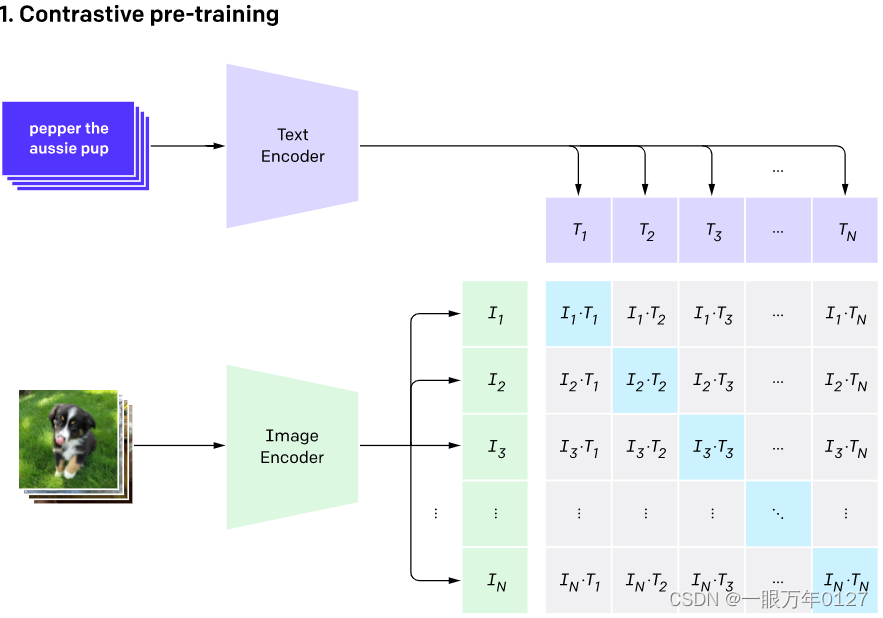
CLIP怎么用
CLIP可以应用与众多的下游任务。例如图文检索,文本视频检索,图文问答,图文生成等。
CLIP系列优化方法:
主要学习基于CLIP的后续一系列工作,包括多篇论文方法。
FLIP:Scaling Language-Image Pre-trainingvia Masking
一种简单高效的CLIP加速训练方法,只需mask掉部分图像,就可以将CLIP的训练过程加速2~3倍,而且能实现更好的性能。
我们知道输入到image encoder(transformer)的图像先要处理成多个patch,每个patch相当于sequence中的一个词。我们对这个sequence做随机mask,按比例随机掩盖掉一些词,然后将剩下的词(image patch)输入到encoder中。
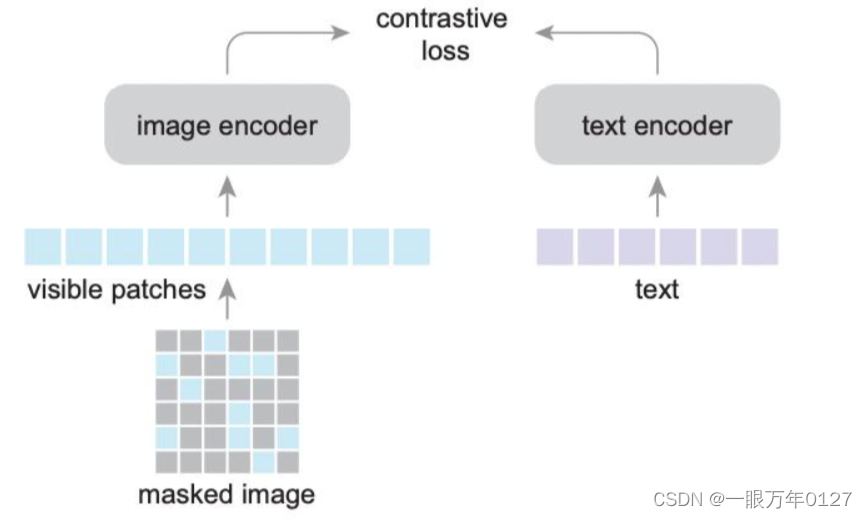
这样做的好处是减小了sequence的长度,也就减少了计算量,训练速度更快;同时减小显存占用,可以增大batch size,有利于对比学习。另一方面,这种操作有点类似dropout,相当于正则化。
最后,为了减少分布上的gap(训练mask测试一版不mask),FLIP会在最后增加少量的unmasking训练,可以进一步提升模型的性能。
FILIP:Fine-grained Interactive Language-Image Pre-Training
CLIP的双塔结构分别提取图像和文本的全局特征做对比学习,缺少局部信息的交互,FILIP增加了image tokens和text tokens的细粒度交互。
DeCLIP:Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm
参考博客 DeCLIP一种数据高效的CLIP训练方法 | 一起打怪升级呀
在CLIP的基础上,采用了多种监督形式,包括:
- 单模态自监督学习
- 图像自监督(ISS):同一张图片进过数据增强获得俩个view:(xI,x~I)(xI,x~I),将经过数据增强后的结果经过相同的encoder得到俩个embedding向量(zI,z~I)(zI,z~I),之后将其中一个embedding向量xIxI再经过一个perd层得到向量pIpI,训练时让pIpI和x~Ix~I 尽量接近;
-
文本自监督(TSS):文本自监督使用的是MLM方法,即随机mask掉文本中15%的token,然后利用前后token预测被mask掉的token;
- 跨模态多视角监督学习(MVS)
- CLIP只使用的原始图像-文本对(zI,zT)(zI,zT),计算infoNCE损失,而DeCLIP中使用的是增强后的文本和图像计算infoNCE损失:(zI,zT),(z~I,zT),(zI,z~T),(z~I,z~T)(zI,zT),(z~I,zT),(zI,z~T),(z~I,z~T) ,相比CLIP多了3个监督信息;
- 最近邻监督学习(NNS)
- 考虑到相同的图像可能会有类似的语言描述,因此选择语言描述相似的图文进行对比学习,通过维护一个先入先出的队列来模拟整个数据的分布,从队列中选择最相似的句子作为正样本zT′zT′,之后使用InfoNCE计算最近邻损失:(zI,zT′),(z~I,zT′)(zI,zT′),(z~I,zT′);
训练loss为以上几部分的加权和: