1、C++中的OMP显示构造
OpenMP在C/C++中通常以编译指令的方式进行使用,一个指令和一个结构化块组成构造。
#pragma omp parallel [clause[[,]clause]... ]
#pragma omp parallel private(x)
{
//并行代码
}示例代码:
#include <iostream>
#include <omp.h> // openmp头文件
#include <mutex> // 互斥锁
int main() {
std::mutex outstream_mutex; //创建输出互斥锁
//openmp构造指令,如下结构块中创建多个子线程并行执行
// default(shared)用于在每个独立线程中共享outstream_mutex锁
#pragma omp parallel default(shared)
{
//获取当前线程ID
int id = omp_get_thread_num();
// 每个时刻只允许一个线程进行输出
outstream_mutex.lock();
std::cout << " thread id " << id << std::endl;
outstream_mutex.unlock();
}
return 0;
}
CmakeList:
cmake_minimum_required(VERSION 3.0)
project(TestOpenMP)
set(CMAKE_BUILD_TYPE "Release")
FIND_PACKAGE(OpenMP REQUIRED)
if (OPENMP_FOUND)
message("OPENMP FOUND")
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} ${OpenMP_C_FLAGS} -Wall -O3")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${OpenMP_CXX_FLAGS} -Wall -O3")
set(CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS} ${OpenMP_EXE_LINKER_FLAGS}")
endif ()
add_executable(simple_example your_source_code.cc)
输出结果如下所示:
thread id 10
thread id 3
thread id 9
thread id 11
thread id 6
thread id 7
thread id 1
thread id 4
thread id 8
thread id 5
thread id 2
thread id 0
Process finished with exit code 0如果去掉输出锁的情况如下:
#include <iostream>
#include <omp.h> // openmp头文件
int main() {
//openmp构造指令,如下结构块中创建多个子线程并行执行
// default(shared)用于在每个独立线程中共享outstream_mutex锁
#pragma omp parallel
{
//获取当前线程ID
int id = omp_get_thread_num();
// 每个时刻只允许一个线程进行输出
std::cout << " thread id " << id << std::endl;
}
return 0;
}
输入如下, 可以看到输出为乱序的:
thread id thread id 26 thread id
thread id 4
thread id 8
thread id 9
10
thread id 7
thread id 5
thread id 3
thread id 1
thread id 11
thread id 0
Process finished with exit code 0上述的代码中,默认的创建了12个线程,因为演示的计算机为12个线程,因此omp会默认讲线程组的线程数设置为当前操作系统可见的核心数;但提供了多种方式用于设置构造执行的线程数。
上述示例中可以看到,程序创建处多个线程来同时执行{}大括号内的代码块。
#pragma omp parallel构造会创建(fork)出一组线程来执行构造内的代码,完成之后会将线程合并(join)在一起并将刚刚新创建的线程组销毁,保留其中的主线程,然后主线程继续执行。
如下图所示:
如右边所示需要注意子线程中也是可以嵌套并行区域,需要注意避免引起数据数据竞争与内存带宽上限问题。
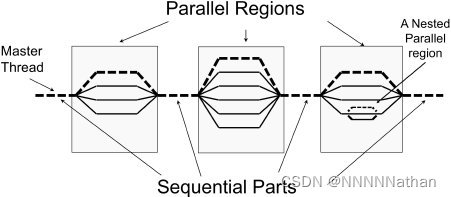
在实际的线程创建与销毁的过程中,omp会使用线程池这种结构来移动线程已减少线程创建与销毁带来的开销;也就是说只是表面上你所创建的线程都被销毁了,但是在后台他并没有被销毁,其他的程序需要时,这些线程又可以快速的填上,缩短创建它的时间。底层由OMP运行时系统来决定。另外OMP的线程在底层中通过线程池的方式来实现的,这种结构可以减少移动线程的方式替换创建与销毁线程的开销。
2、设定默认线程数
omp的程序开始时,在创建线程组时默认为系统可见的线程数,因此可以根据使用场景合理的设置该数值;这里有多种方法可以更改默认线程数,此处使用omp_set_num_threads来实现。
注意:一个线程组一旦创建,其规模是固定的,OpenMP Runtime不会减少线程组的规模
另外一种设置线程数的方法为通过环境变量的方式,如果是在Linux系统中,可以通过如下命令设置:
export OMP_NUM_THREADS=线程数
#include <omp.h>
#include <iostream>
#include <vector>
#include <mutex> // 互斥锁
void pooh(int ID, std::vector<double> Array) {
Array[ID] = ID;
}
int main() {
int num_threads = 4;
//所有线程都可以访问Array
std::vector<double> Array(num_threads);
//通过omp_set_num_threads设置可见的线程为4
omp_set_num_threads(num_threads);
std::mutex outstream_mutex; //创建输出互斥锁
#pragma omp parallel default(shared)
{
int ID = omp_get_thread_num(); // 获取当前线程的ID
pooh(ID, Array);
outstream_mutex.lock();
std::cout << "A of ID(" << ID << ") = " << Array[ID] << std::endl;
outstream_mutex.unlock();
} // end of parallel region
}
A of ID(0) = 0
A of ID(3) = 0
A of ID(1) = 0
A of ID(2) = 0
Process finished with exit code 03、获取线程组中的线程数
#include <omp.h>
#include <iostream>
int main() {
omp_set_num_threads(4);
int size_of_team;
#pragma omp parallel shared(size_of_team)//此处将size_of_team设置为共享变量,使得子线程都可以访问
{
int ID = omp_get_thread_num(); // 获取当前线程的ID
int NThrds = omp_get_num_threads(); // 获取当前并行区域中一共有多少个线程
//只允许第0个线程可以进行如下的赋值操作,否则,
// 需要使用mutex来进行赋值,不然会引发数据冲突,虽然此处的数据冲突不影响最终的结果,但需要注意
// 某些其他平台的处理器会因为数据冲突导致未定义数值的出现
if (ID == 0) {
size_of_team = NThrds;
}
} // end of parallel region
std::cout << "线程组中一共有" << size_of_team << "个线程" << std::endl;
}
线程组中一共有4个线程4、简单示例
4.1 并行计算定积分
下面是一个定积分计算的例子,该程序通过将曲线下的面积近似为矩形面积的和来估计一个定积分的结果;选择积分和积分范围,使得这个积分的结果等于。将通过SPMD(单程序多数据|Single Program/Multiple Data)的设计模式来实现:
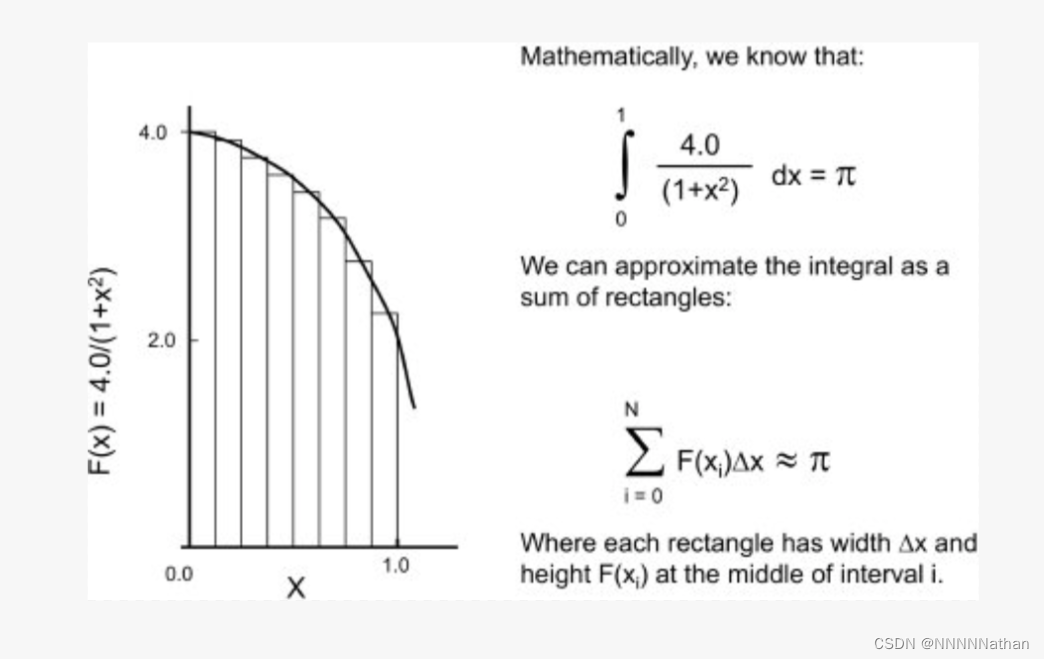
代码中包含两种实现:一种为multi_stride:
另一种为:
#include <omp.h>
#include <iostream>
#include <vector>
#include <chrono> // std::chrono::seconds
#include <thread> // std::this_thread::sleep_fo
static long num_steps = 1e9;
double step;
#define NTHREADS 4 //定义线程数
void plain() {
int i;
double x, pi, sum = 0.0;
double start_time, run_time;
step = 1.0 / (double) num_steps;
// openmp内部实现的时钟定时器
start_time = omp_get_wtime();
for (i = 0; i < num_steps; i++) {
x = (i + 0.5) * step; //计算每个δ矩形x的数值,中值积分
sum += 4.0 / (1.0 + x * x);
}
pi = step * sum;
run_time = omp_get_wtime() - start_time;
std::cout << "单线程: " << "pi = " << pi << ", " << num_steps << " steps "
<< run_time << " secs" << std::endl;
}
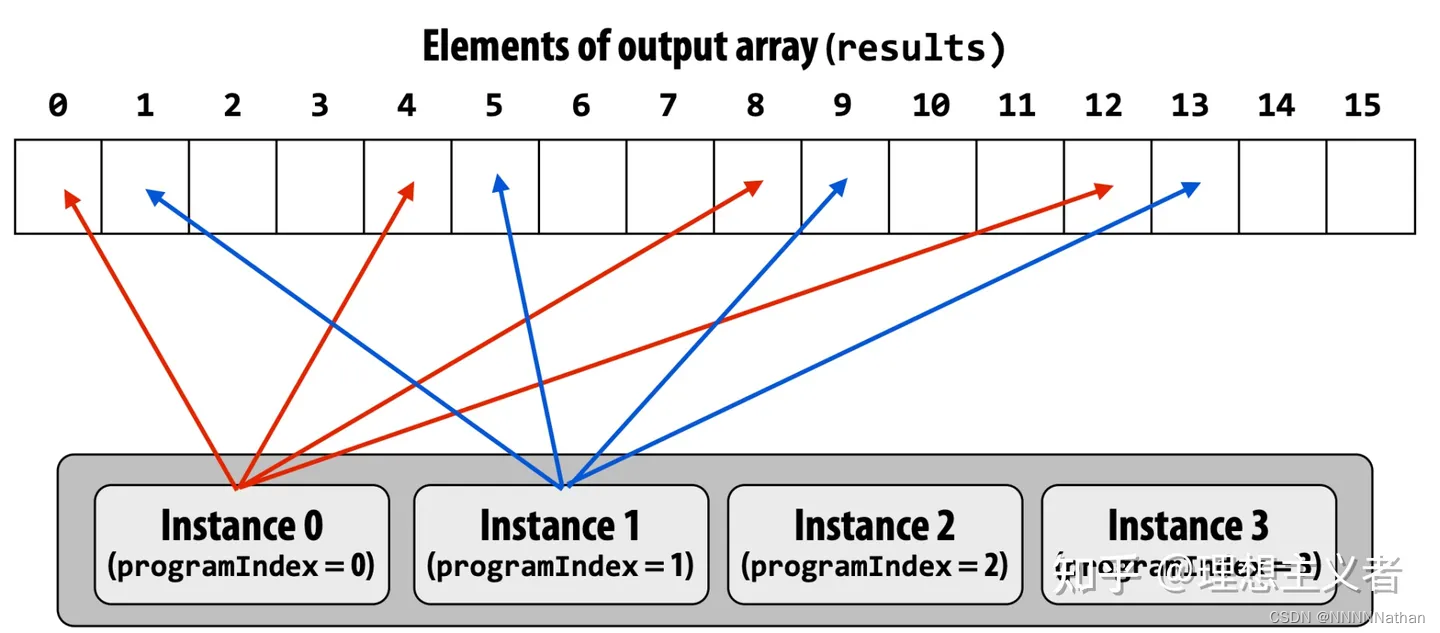
void multi_stride() {
int i, j, actual_nthreads;
double pi, start_time, run_time;
double sum[NTHREADS] = {0.0};
step = 1.0 / (double) num_steps;
start_time = omp_get_wtime();
#pragma omp parallel shared(step)
{
int i;
int id = omp_get_thread_num();
int numthreads = omp_get_num_threads();
double x;
if (id == 0) {
actual_nthreads = numthreads;
}
/*
每个线程独立执行
第0个线程执行0,0+numthreads,0+numthreads+numthreads的数据
第1个线程执行1,1+numthreads,1+numthreads+numthreads的数据
以此类推,并将结果分别累加在各自的sum中
*/
for (i = id; i < num_steps; i += numthreads) {
x = (i + 0.5) * step;
sum[id] += 4.0 / (1.0 + x * x);
}
} // end of parallel region
pi = 0.0;
for (i = 0; i < actual_nthreads; i++)
pi += sum[i];
pi = step * pi;
run_time = omp_get_wtime() - start_time;
std::cout << "多线程 stride: " << "pi = " << pi << ", " << num_steps << " steps "
<< run_time << " secs" << std::endl;
}
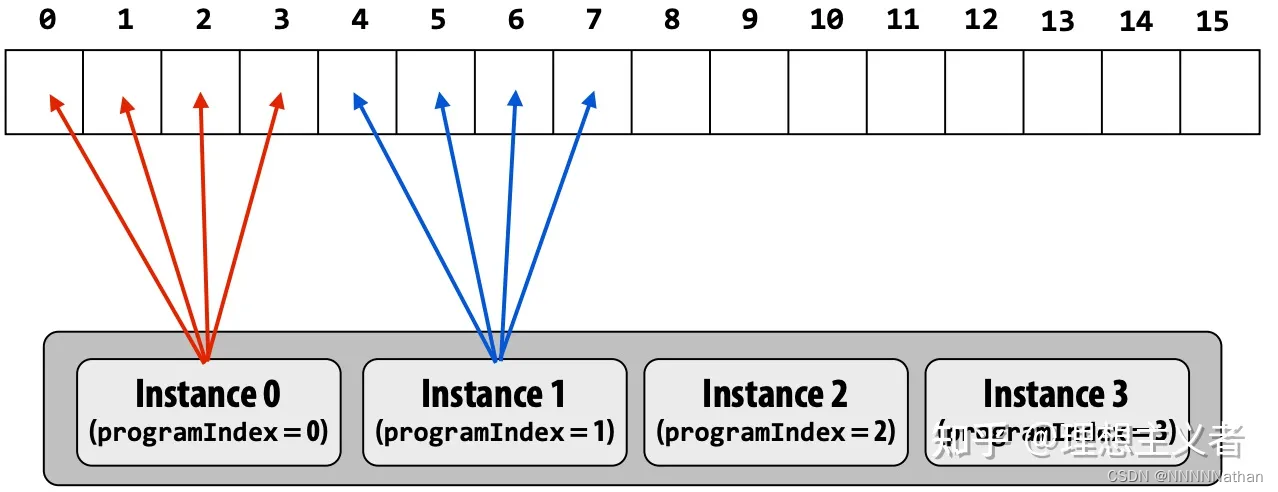
void multi_block() {
int i;
double pi, start_time, run_time;
std::vector<double> sum;
sum.resize(num_steps, 0);
step = 1.0 / (double) num_steps;
start_time = omp_get_wtime();
#pragma omp parallel shared(step)
{
int i, istart, iend;
int id = omp_get_thread_num();
int numthreads = omp_get_num_threads();
double x;
istart = id * num_steps / numthreads;
iend = (id + 1) * num_steps / numthreads;
if (id == (numthreads - 1)) iend = num_steps;
/*
每个线程计算指定的一块区域,
第0个线程计算0 - 1e9/NTHREADS,
第1个线程计算1e9/NTHREADS - 1e9/NTHREADS * 2,
第2个线程计算1e9/NTHREADS *2 - 1e9/NTHREADS * 3,
依次类推
*/
for (i = istart; i <= iend; i++) {
x = (i + 0.5) * step;
sum[i] = 4.0 / (1.0 + x * x);
}
} // end of parallel region
pi = 0.0;
//通过规约对数组进行求和
#pragma omp parallel for reduction(+:pi)
for (i = 0; i < sum.size(); i++)
pi += sum[i];
pi = step * pi;
run_time = omp_get_wtime() - start_time;
std::cout << "多线程 block: " << "pi = " << pi << ", " << num_steps << " steps "
<< run_time << " secs" << std::endl;
};
int main() {
omp_set_num_threads(NTHREADS);
plain();
multi_stride();
std::this_thread::sleep_for(std::chrono::seconds(1));
multi_block();
}
结果如下,可以看到多线程的结果
单线程: pi = 3.14159, 1000000000 steps 2.43653 secs
多线程 stride: pi = 3.14159, 1000000000 steps 0.711552 secs
多线程 block: pi = 3.14159, 1000000000 steps 1.18776 secs
Process finished with exit code 0
4.2 内存伪共享问题
上述的代码会场生一个内存同步问题,每个线程处理数据时,都会读取对应的一组数据到核心的L1缓存行中,如果多个核心同时读取了同一段内存中的数据作为缓存行,则会在核心改写局部数据后出现内存同步的问题,内存同步会导致高速缓存行需要在各核心之间来回移动,降低程序运行的效率。
下图中,两个核心都读取了存放数组Sum的缓存行,数组的相邻元素被映射常常被映射到同一个缓存行上,如果硬件线程0修改了Sum[0]元素,这个修改会导致即将需要更新Sum[2]的第二个硬件线程中的缓存行需要等待同步操作;也就是说每个核心更新一次缓存行会导致数据在多个核心之间来回同步。

下面的代码将通过使用二位数组填充脏数据的方式使得,每个线程的缓存行数据是独立的。
#include <omp.h>
#include <iostream>
#define NTHREADS 4
#define CBLK 8 // 每个double类型占8个字节,N100CPU的L1缓存行大小为64字节,因此8个double类型可以占满
static long num_steps = 1e9;
double step;
int main() {
std::cout<< sizeof(double )<<std::endl;
int i, j, actual_nthreads;
double pi, start_time, run_time;
//将sum设置为一个二维数组,并使用脏数据将其填满
double sum[NTHREADS][CBLK] = {0.0};
step = 1.0 / (double) num_steps;
omp_set_num_threads(NTHREADS);
start_time = omp_get_wtime();
#pragma omp parallel default(shared)
{
int i;
int id = omp_get_thread_num();
int numthreads = omp_get_num_threads();
double x;
if (id == 0) actual_nthreads = numthreads;
for (i = id; i < num_steps; i += numthreads) {
x = (i + 0.5) * step;
//每个线程只会操作各自行的第0个数据
sum[id][0] += 4.0 / (1.0 + x * x);
}
} // end of parallel region
pi = 0.0;
for (i = 0; i < actual_nthreads; i++)
pi += sum[i][0];
pi = step * pi;
run_time = omp_get_wtime() - start_time;
std::cout << "多线程 block: " << "pi = " << pi << ", " << num_steps << " steps "
<< run_time << " secs" << std::endl;
}
8
多线程 block: pi = 3.14159, 1000000000 steps 0.782837 secs
Process finished with exit code 0