文章目录
来源:ICASSP 2020
从L2说话人的句子中分别提取语言学信息和说话人表征,然后驱动语音合成模型,从而产生没有口音的说话人特征不变的句子。
1. INTRODUCTION
传统的AC方法是将native说话人转换成non-native target说话人,但是内容和发音不变。因此在推理过程中需要native speaker的句子,也就只能转换有native speaker的句子。本文提出了一种端到端的方法,在转换过程中不需要native- accented utterances,理论上也可以转换任意内容的non-native utterances。本文的方法由4个部分组成:一个speaker encoder,一个seq2seq 多说话人的TTS,一个seq2seq 有口音的ASR,以及一个vocoder。speaker encoder是在说话人识别任务上训练的,得到固定维度的speaker embedding。多说话人TTS基于tacotron架构,将phoneme序列转成mel谱,以speaker embedding为条件。在native数据上训练。有口音的ASR则是在native 和 accent数据上训练的。在转换期间,应用non-native音频经过ASR产生的语言学信息和说话人表示,语言学信息和说话人表示喂给TTS的decoder,从而产生native的音频。声码器最终将mel转成音频。主要的贡献:
- 在转换过程中不需要ref
- 基于seq2seq框架,有能力建模韵律特性,听起来更native
- 不需要平行语料
2. PROPOSED APPROACH
2.1 训练阶段
训练阶段,应用speaker encoder提取speaker信息,实现speaker信息的解耦。根据文本信息和speaker的embedding生成native的音频。 H l H^l Hl这里表示的是linguistic information,因为是平行语料,所以上下图中linguistic information是一致的, L T T S E L_{TTSE} LTTSE用于计算两个linguistic information之间的loss。
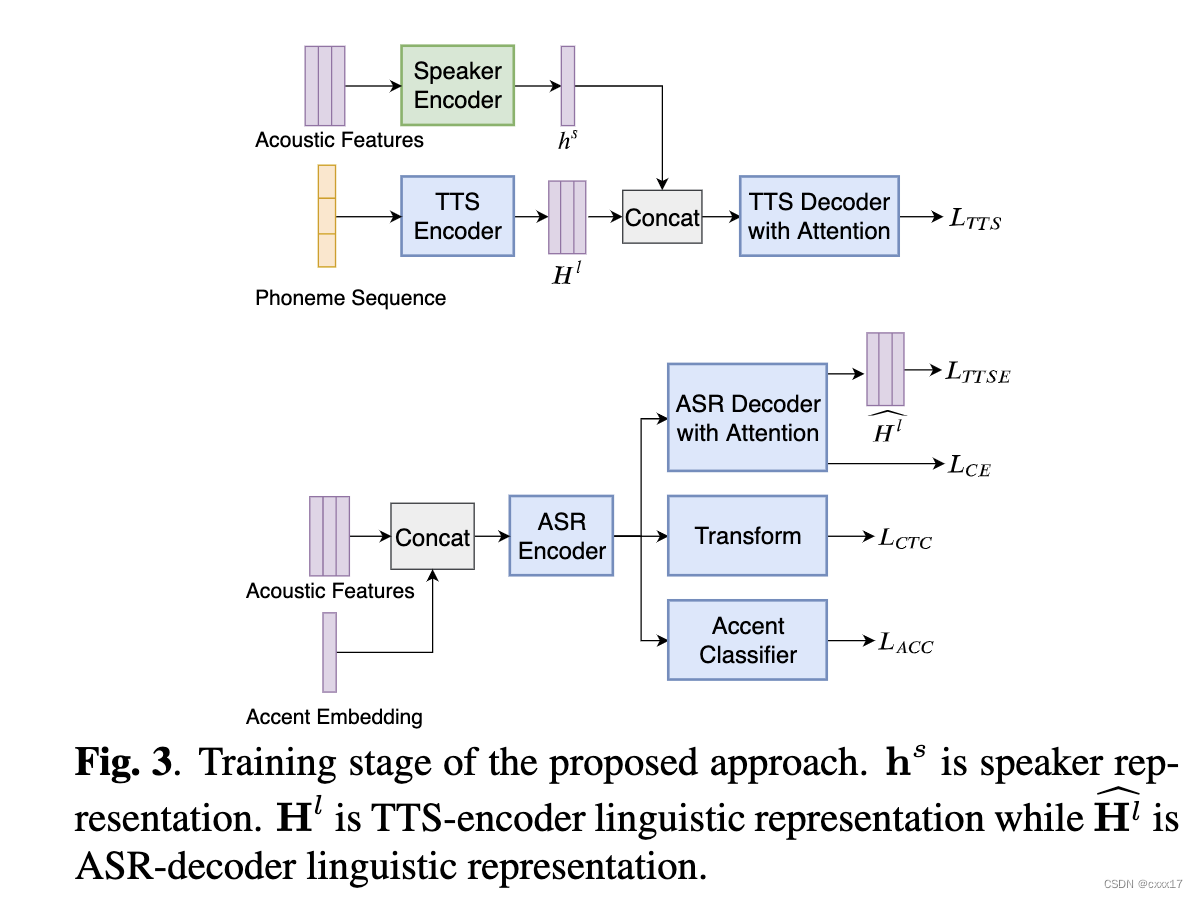
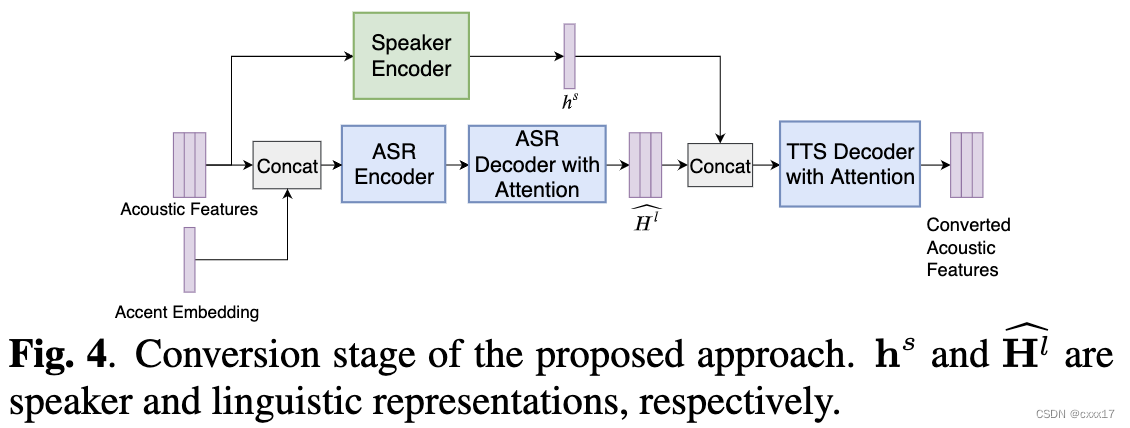
2.2 转换阶段
3. Experimental results
3.1 Audio naturalness
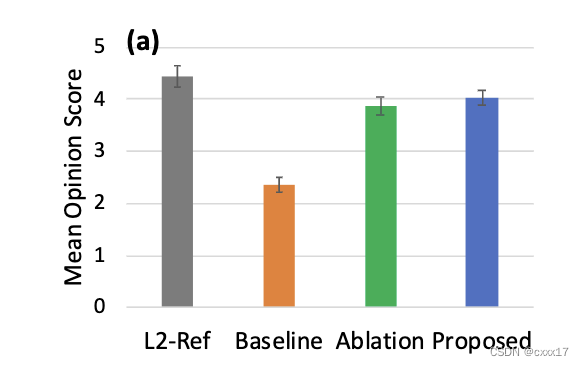
Ablation是去掉Accent embedding和Accent classifier的model。
3.2 Speaker similarity
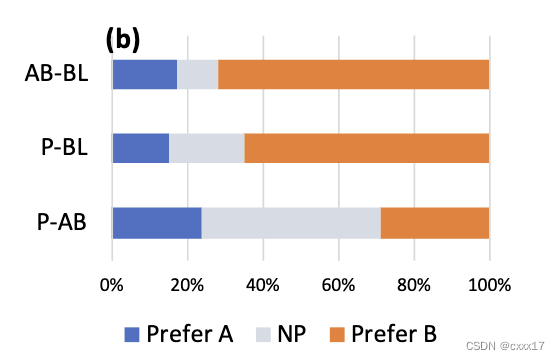
三组分别是: “AB-BL”, “PB-L” and “P-AB”
3.3 Accentedness
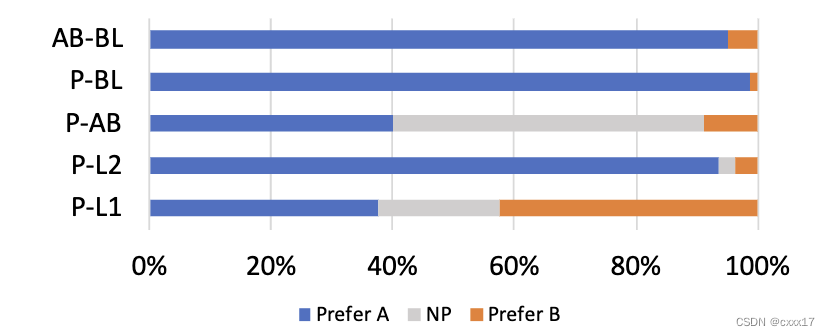
口音测试,可以看到提出的方法明显好于baseline,ablation,和L2原音频,但稍差于L1原音频。