文章目录
-
- 1. Audio Style Transfer for Accents
- 2. END-TO-END ACCENT CONVERSION WITHOUT USING NATIVE UTTERANCES
- 3. Accent and Speaker Disentanglement in Many-to-many Voice Conversion
- 4. Improving Accent Conversion with Reference Encoder and End-To-End Text-To-Speech
- 5. Converting Foreign Accent Speech Without a Reference
1. Audio Style Transfer for Accents
来源:NeurIPS 2019
生成了30000句平行语料库,实现了英音美音英语的转换。采用GAN架构,如下图:
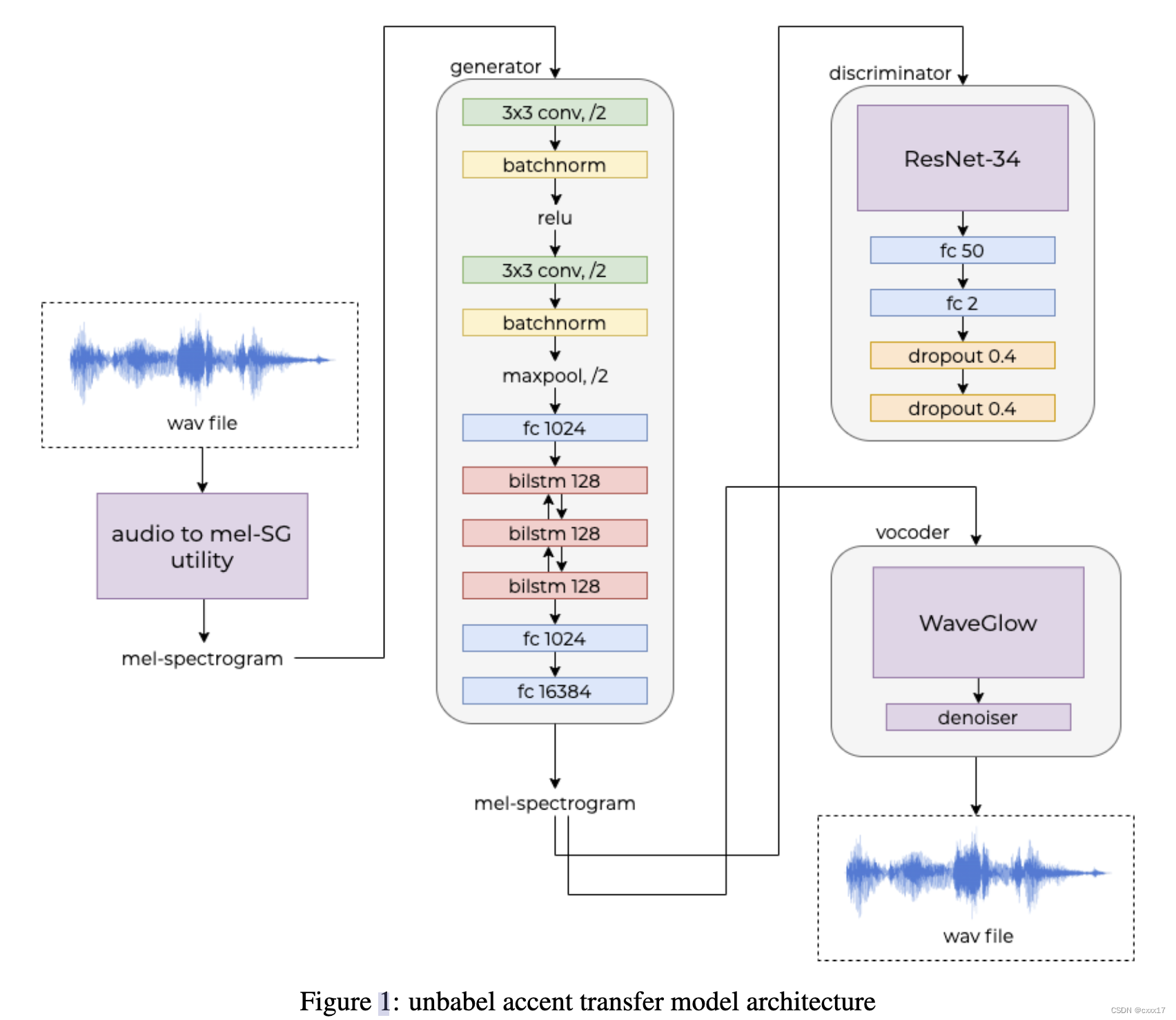
音频samples界面失效了,根据文中给出的信息推测,英音美音分别分别是两个male说话人,因此在转换过程中,音色和口音一起被转换了;且只能转换单词,不能整句整句转。
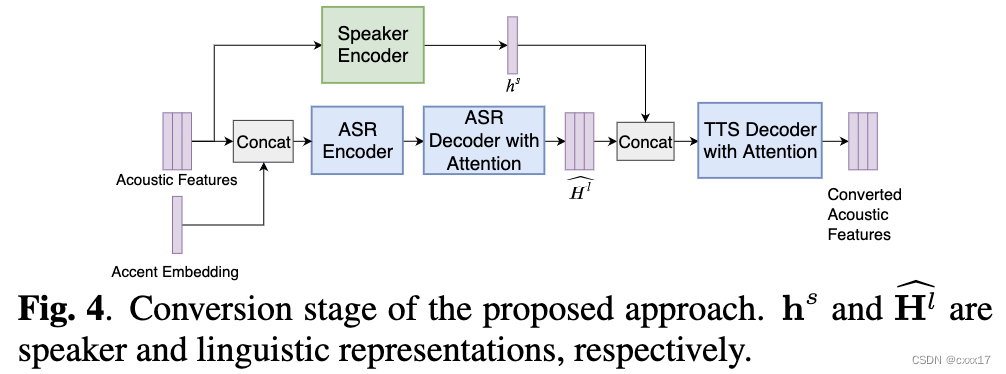
2. END-TO-END ACCENT CONVERSION WITHOUT USING NATIVE UTTERANCES
来源:ICASSP 2020
demo:https://liusongxiang.github.io/end2endAC/
在转换的时候,无需提供native speaker的音频,即可以实现non-native accent 到native accent的转换,应用平行语料。
训练阶段如图所示:

训练阶段,应用speaker encoder提取speaker信息,实现speaker信息的解耦。根据文本信息和speaker的embedding生成native的音频。 H l H^l Hl这里表示的是linguistic information,因为是平行语料,所以上下图中linguistic information是一致的, L T T S E L_{TTSE} LTTSE用于计算两个linguistic information之间的loss。
转换阶段如下图所示,
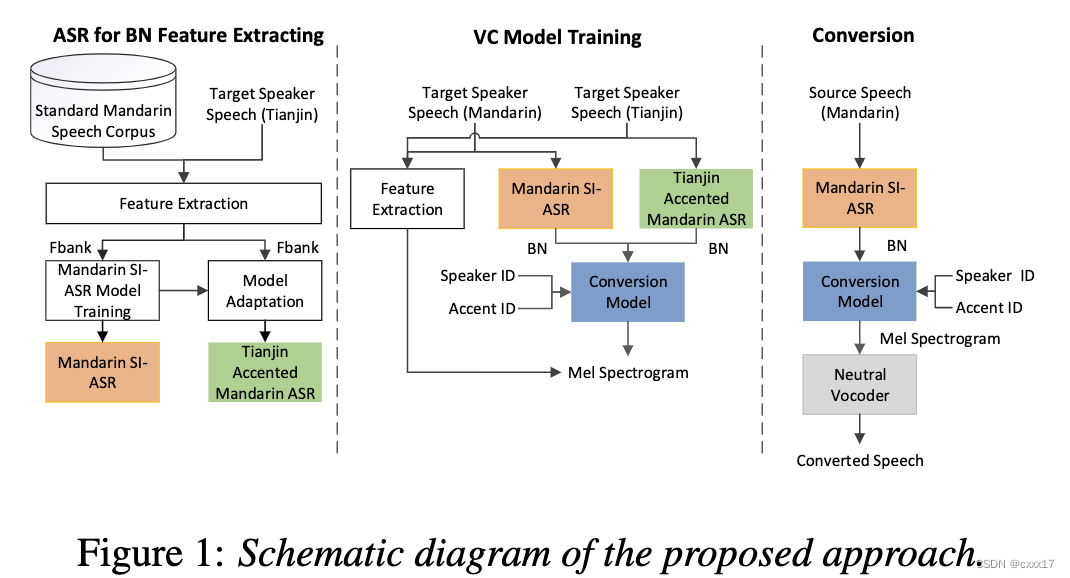
3. Accent and Speaker Disentanglement in Many-to-many Voice Conversion
来源:ISCSLP 2021
demo:https://kerwinchao.github.io/AccentVoicejointConversion.github.io/
口音和说话人耦合比较严重,一般一个说话人只会用一种口音说话。口音转换任务是想要target speaker的音色,但是用source speaker的accent,因此需要对口音和说话人信息进行解耦;本文用了两个trick实行解耦,首先是训练了一个包括了不同口音,不同说话人的ASR(说明ASR提取的feature与speaker和accent无关),为conversion模型的训练提供 BN feature; 其次用了一个 adversarial speaker loss,确保转换模型的encoder的输出不含有说话人相关的信息。
4. Improving Accent Conversion with Reference Encoder and End-To-End Text-To-Speech
来源:arxiv
demo: https://kal009l.github.io/ac-demo/
引入reference encoder引入更多信息,想通过reference encoder 对重音和语调进行控制,这里应该是把音色和口音一起转换了。
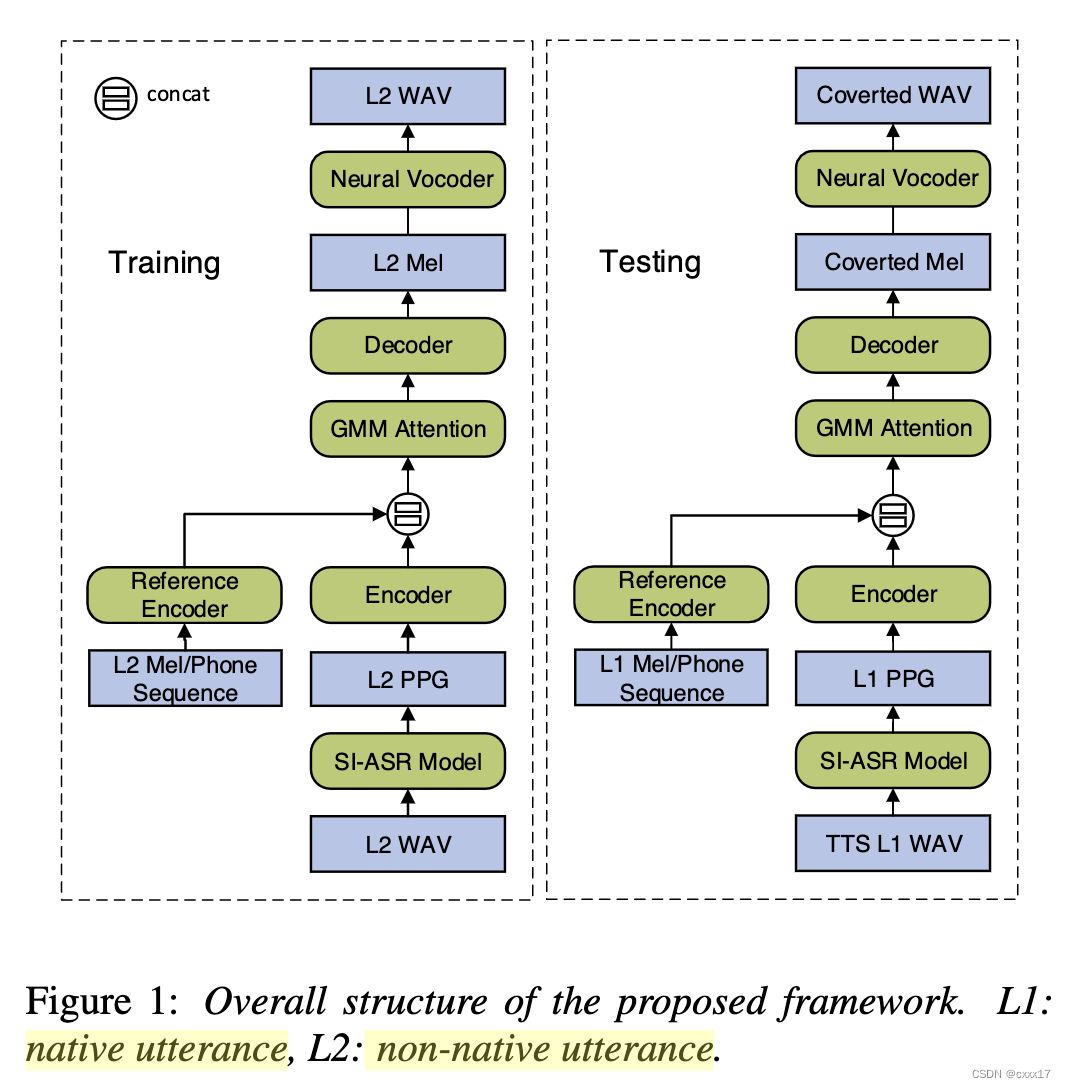
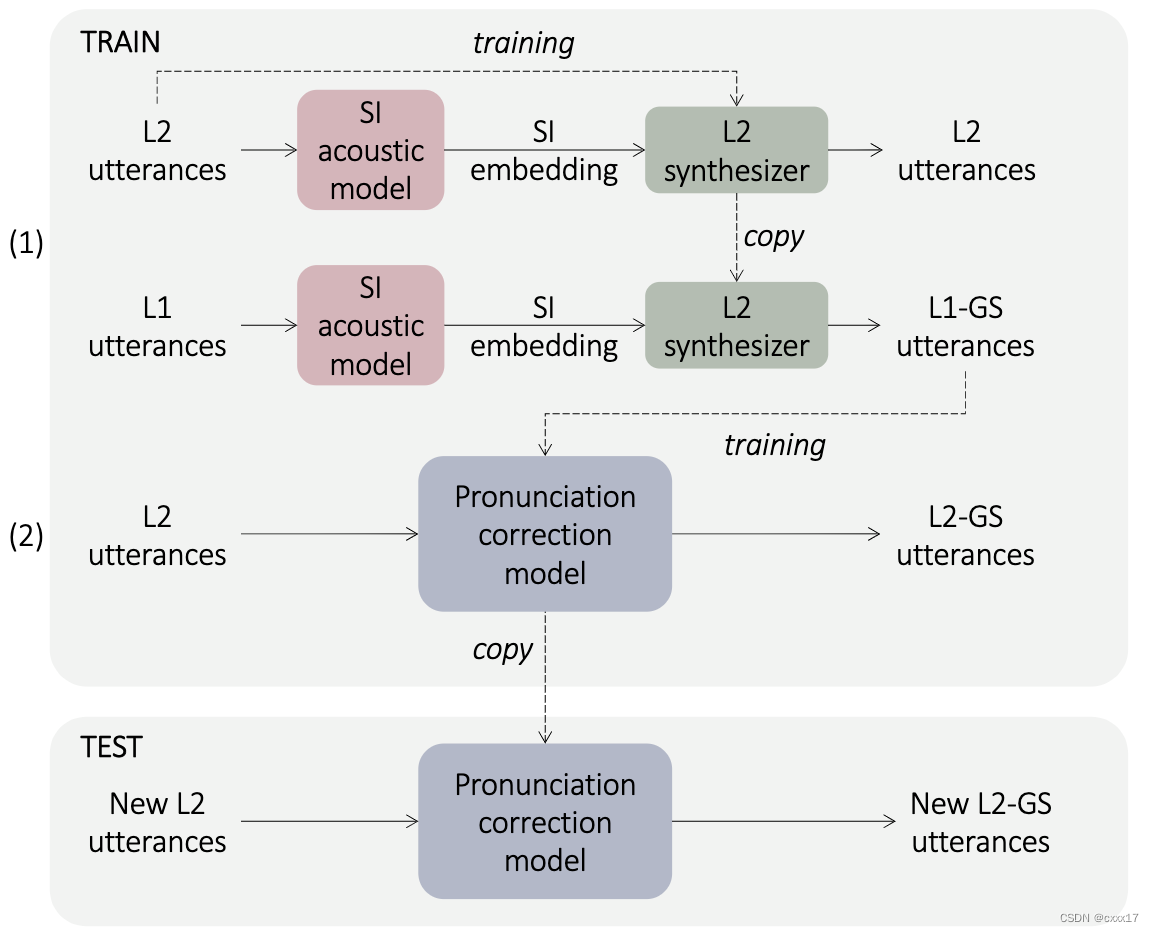
5. Converting Foreign Accent Speech Without a Reference
来源:TASLP 2021
demo:https://guanlongzhao.github.io/demo/reference-free-ac/
L2表示non-native speaker,L1表示native speaker。 首先需要一个SI acoustic model生成语言特征,用于训练L2的合成模型,然后讲L1句子的语言特征输入L2合成模型,就能生成L2说话人特征的和L1内容相同的句子,称作L1-GS,认为语言特征里就包含了accent,L1-GS口音是native,说话人是L2,因此L1-GS+L2可以用于 pronunciation correction model的训练,因为二者只是口音不同,说话人相同。这里用的也是平行语料。