本文使用KNN和SVM实现对LFW人像图像数据集的分类应用,并尝试使用PCA和LDA这两种数据降维方法对原始特征进行处理再分类,并试评估比较这些分类结果。
参考链接: http://vis-www.cs.umass.edu/lfw/#explore
KNN和SVM介绍
KNN
K最近邻(K-Nearest Neighbors,简称KNN)是一种常见的监督学习算法,用于分类和回归问题。它基于一个简单的思想:如果一个样本在特征空间中的k个最相似(即距离最近)的样本中的大多数属于某一个类别,那么该样本也属于这个类别。
以下是KNN算法的基本步骤:
- 确定邻居的数量(k值): 选择一个合适的k值,即要考虑的最近邻居的数量。
- 计算距离: 使用适当的距离度量(如欧氏距离、曼哈顿距离、闵可夫斯基距离等),计算待分类样本与训练集中每个样本的距离。
- 找到最近的邻居: 根据计算的距离找到离待分类样本最近的k个训练样本。
- 投票决策: 对于分类问题,采用多数投票原则,即将待分类样本归类为k个最近邻居中出现次数最多的类别。对于回归问题,可以计算k个最近邻居的平均值作为预测结果。
SVM
支持向量机(Support Vector Machine,SVM)是一种用于分类和回归的监督学习算法。下面是SVM的算法步骤:
算法步骤:
-
数据准备: 收集并准备带有标签的训练数据,其中每个样本包括一组特征和对应的类别标签。
-
选择核函数: 选择适当的核函数,用于将数据映射到高维空间。常见的核函数有线性核、多项式核、径向基函数(RBF)核等。选择核函数的目标是在高维空间中更容易找到一个线性可分的超平面。
-
特征缩放: 对特征进行缩放,以确保不同特征的数值范围相近。这有助于避免某些特征对模型的影响过大。
-
构建并训练模型: 使用训练数据来构建SVM模型。算法的目标是找到一个能够将不同类别分开的超平面,并使得间隔最大化。
a. 对于线性SVM,目标是找到最大间隔超平面,可以通过求解优化问题实现。
b. 对于非线性SVM,采用核函数将数据映射到高维空间,然后在该空间中寻找最大间隔超平面。
-
决策函数: 根据训练好的模型,对新的未标记样本进行分类。通过计算新样本到超平面的距离,决定样本属于哪个类别。
降维方法
PCA降维
主成分分析(Principal Component Analysis,PCA)是一种常用的降维技术,用于减少数据集中的维度。PCA通过找到数据中最重要的方向(主成分),将数据投影到这些方向上,从而减少数据的维度。这样可以保留大部分原始数据的信息,同时减少数据的冗余和噪声。
LDA降维
线性判别分析(Linear Discriminant Analysis,LDA)是一种用于数据降维和分类的监督学习方法。LDA的主要目标是找到一个投影方向,使得在这个方向上类别之间的差异最大化,同时类别内的差异最小化。
数据集介绍
LFW (Labeled Faces in the Wild) 人脸数据库是由美国马萨诸塞州立大学阿默斯特分校计算机视觉实验室整理完成的数据库,主要用来研究非受限情况下的人脸识别问题。LFW 数据库主要是从互联网上搜集图像,而不是实验室,一共含有13000 多张人脸图像,每张图像都被标识出对应的人的名字,其中有1680 人对应不只一张图像,即大约1680个人包含两个以上的人脸。
LFW数据集主要测试人脸识别的准确率,该数据库从中随机选择了6000对人脸组成了人脸辨识图片对,其中3000对属于同一个人2张人脸照片,3000对属于不同的人每人1张人脸照片。测试过程LFW给出一对照片,询问测试中的系统两张照片是不是同一个人,系统给出“是”或“否”的答案。通过6000对人脸测试结果的系统答案与真实答案的比值可以得到人脸识别准确率。
案例代码
加载数据,分别使用knn和svm进行分类,输出他们的准确率
再分别使用两种降维方法,对比knn和svm在降维之后的准确率
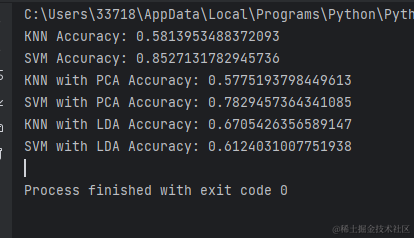
最后发现knn在LAD降维后准确率上升,在pca降维后准确率下降,svm在LAD降维后准确率下降,在pca降维后准确率上升
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.datasets import fetch_lfw_people
# 加载LFW人像数据集
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
X, y = lfw_people.data, lfw_people.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 使用KNN分类器
knn_classifier = KNeighborsClassifier(n_neighbors=5)
knn_classifier.fit(X_train, y_train)
y_pred_knn = knn_classifier.predict(X_test)
accuracy_knn = accuracy_score(y_test, y_pred_knn)
print(f'KNN Accuracy: {
accuracy_knn}')
# 使用SVM分类器
svm_classifier = SVC(kernel='linear')
svm_classifier.fit(X_train, y_train)
y_pred_svm = svm_classifier.predict(X_test)
accuracy_svm = accuracy_score(y_test, y_pred_svm)
print(f'SVM Accuracy: {
accuracy_svm}')
# 使用PCA进行数据降维
pca = PCA(n_components=100) # 选择降维后的维度
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
# 使用LDA进行数据降维
lda = LinearDiscriminantAnalysis(n_components=min(X_train.shape[1], len(np.unique(y_train)) - 1))
X_train_lda = lda.fit_transform(X_train, y_train)
X_test_lda = lda.transform(X_test)
# 使用KNN分类器(PCA降维)
knn_classifier_pca = KNeighborsClassifier(n_neighbors=5)
knn_classifier_pca.fit(X_train_pca, y_train)
y_pred_knn_pca = knn_classifier_pca.predict(X_test_pca)
accuracy_knn_pca = accuracy_score(y_test, y_pred_knn_pca)
print(f'KNN with PCA Accuracy: {
accuracy_knn_pca}')
# 使用SVM分类器(PCA降维)
svm_classifier_pca = SVC(kernel='linear')
svm_classifier_pca.fit(X_train_pca, y_train)
y_pred_svm_pca = svm_classifier_pca.predict(X_test_pca)
accuracy_svm_pca = accuracy_score(y_test, y_pred_svm_pca)
print(f'SVM with PCA Accuracy: {
accuracy_svm_pca}')
# 使用KNN分类器(LDA降维)
knn_classifier_lda = KNeighborsClassifier(n_neighbors=5)
knn_classifier_lda.fit(X_train_lda, y_train)
y_pred_knn_lda = knn_classifier_lda.predict(X_test_lda)
accuracy_knn_lda = accuracy_score(y_test, y_pred_knn_lda)
print(f'KNN with LDA Accuracy: {
accuracy_knn_lda}')
# 使用SVM分类器(LDA降维)
svm_classifier_lda = SVC(kernel='linear')
svm_classifier_lda.fit(X_train_lda, y_train)
y_pred_svm_lda = svm_classifier_lda.predict(X_test_lda)
accuracy_svm_lda = accuracy_score(y_test, y_pred_svm_lda)
print(f'SVM with LDA Accuracy: {
accuracy_svm_lda}')
结果