1 图像分类问题
1.1 什么是图像分类
所谓图像分类问题,就是已有固定的分类标签集合,然后对于输入的图像,从分类标签集合中找出一个分类标签,最后把分类标签分配给该输入图像。虽然看起来挺简单的,但这可是计算机视觉领域的核心问题之一,并且有着各种各样的实际应用。计算机视觉领域中很多看似不同的问题(比如物体检测和分割),都可以被归结为图像分类问题。
举个例子体会一下:
以下图为例,图像分类模型读取该图片,并生成该图片属于集合 {cat, dog, hat, mug}中各个标签的概率。需要注意的是,对于计算机来说,图像是一个由数字组成的巨大的3维数组。在这个例子中,猫的图像大小是宽248像素,高400像素,有3个颜色通道,分别是红、绿和蓝(简称RGB)。如此,该图像就包含了248X400X3=297600个数字,每个数字都是在范围0-255之间的整型,其中0表示全黑,255表示全白。我们的任务就是把这些上百万的数字变成一个简单的标签,比如“猫”。
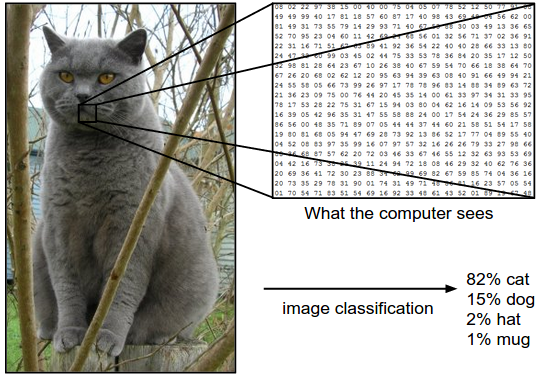
图像分类的任务,就是对于一个给定的图像,预测它属于的那个分类标签(或者给出属于一系列不同标签的可能性)。图像是3维数组,数组元素是取值范围从0到255的整数。数组的尺寸是宽度x高度x3,其中这个3代表的是红、绿和蓝3个颜色通道。
1.2 图像分类任务的难点
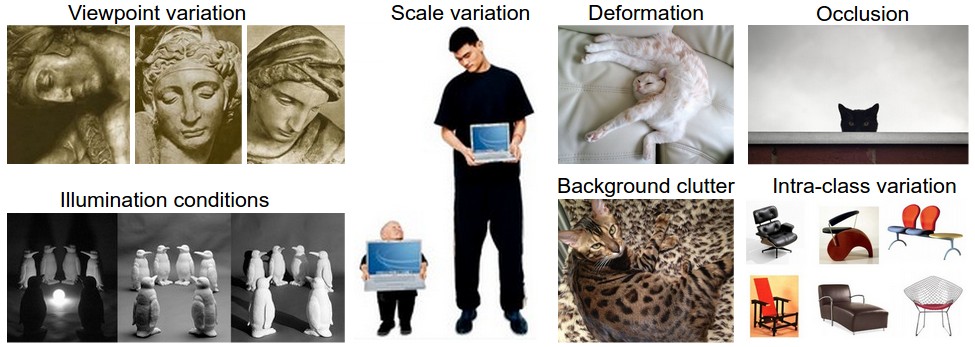
对于人来说,识别出一个像“猫”一样视觉概念是简单至极的,然而从计算机视觉算法的角度来看就值得深思了。我们在下面列举了计算机视觉算法在图像识别方面遇到的一些困难,要记住图像是以3维数组来表示的,数组中的元素是亮度值。
视角变化(Viewpoint variation):同一个物体,摄像机可以从多个角度来展现。
大小变化(Scale variation):物体可视的大小通常是会变化的(不仅是在图片中,在真实世界中大小也是变化的)。
形变(Deformation):很多东西的形状并非一成不变,会有很大变化。
遮挡(Occlusion):目标物体可能被挡住。有时候只有物体的一小部分(可以小到几个像素)是可见的。
光照条件(Illumination conditions):在像素层面上,光照的影响非常大。
背景干扰(Background clutter):物体可能混入背景之中,使之难以被辨认。
类内差异(Intra-class variation):一类物体的个体之间的外形差异很大,比如椅子。这一类物体有许多不同的对象,每个都有自己的外形。
1.3 图像分类的方法及流程
1.3.1 方法
如何写一个图像分类的算法呢?这和写个排序算法可是大不一样。怎么写一个从图像中认出猫的算法?好像不太可行。因此,与其在代码中直接写明各类物体到底看起来是什么样的,倒不如说我们采取和教小孩儿看图识物类似的方法:给计算机很多数据,然后实现学习算法,让计算机学习到每个类的外形。这种方法,就是数据驱动方法。
1.3.2 流程
图像分类就是输入一个元素为像素值的数组,然后给它分配一个分类标签。完整流程如下:
输入:输入是包含N个图像的集合,每个图像的标签是K种分类标签中的一种。这个集合称为训练集。
学习:这一步的任务是使用训练集来学习每个类到底长什么样。一般该步骤叫做训练分类器或者学习一个模型。
评价:让分类器来预测它未曾见过的图像的分类标签,并以此来评价分类器的质量。我们会把分类器预测的标签和图像真正的分类标签对比。毫无疑问,分类器预测的分类标签和图像真正的分类标签如果一致,那就是好事,这样的情况越多越好。
2 最近邻分类器
我们来实现一个Nearest Neighbor分类器。虽然这个分类器和卷积神经网络没有任何关系,实际中也极少使用,但通过实现它,可以让读者对于解决图像分类问题的方法有个基本的认识。
2.1 CIFAR10
一个非常流行的图像分类数据集是CIFAR-10。这个数据集包含了60000张32X32的小图像。每张图像都有10种分类标签中的一种。这60000张图像被分为包含50000张图像的训练集和包含10000张图像的测试集。在下图中你可以看见10个类的10张随机图片。

左边:从CIFAR-10数据库来的样本图像。右边:第一列是测试图像,然后第一列的每个测试图像右边是使用Nearest Neighbor算法,根据像素差异,从训练集中选出的10张最类似的图片。
2.2 基于最近邻的简单图像类别判决
假设现在我们有CIFAR-10的50000张图片(每种分类5000张)作为训练集,我们希望将余下的10000作为测试集并给他们打上标签。Nearest Neighbor算法将会拿着测试图片和训练集中每一张图片去比较,然后将它认为最相似的那个训练集图片的标签赋给这张测试图片。上面右边的图片就展示了这样的结果。请注意上面10个分类中,只有3个是准确的。比如第8行中,马头被分类为一个红色的跑车,原因在于红色跑车的黑色背景非常强烈,所以这匹马就被错误分类为跑车了。
那么具体如何比较两张图片呢?在本例中,就是比较32x32x3的像素块。最简单的方法就是逐个像素比较,最后将差异值全部加起来。换句话说,就是将两张图片先转化为两个向量\(I_{1}\)和\(I_{2}\),然后计算他们的L1距离:
这里的求和是针对所有的像素。下面是整个比较流程的图例:
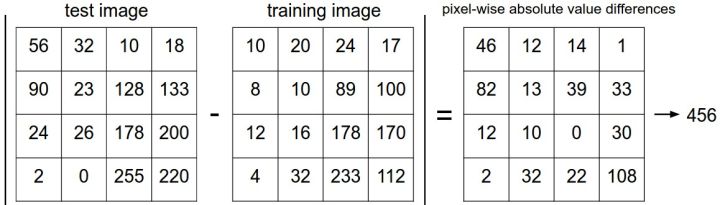
以图片中的一个颜色通道为例来进行说明。两张图片使用L1距离来进行比较。逐个像素求差值,然后将所有差值加起来得到一个数值。如果两张图片一模一样,那么L1距离为0,但是如果两张图片很是不同,那L1值将会非常大。
计算向量间的距离有很多种方法,另一个常用的方法是L2距离,从几何学的角度,可以理解为它在计算两个向量间的欧式距离。L2距离的公式如下:
比较这两个度量方式是挺有意思的。在面对两个向量之间的差异时,L2比L1更加不能容忍这些差异。也就是说,相对于1个巨大的差异,L2距离更倾向于接受多个中等程度的差异。
在cifar10数据集上实现最近邻算法:
# -*- coding: utf-8 -*-
#! /usr/bin/env python
#coding=utf-8
import os
import pickle
import numpy as np
def load_CIFAR_batch(filename):
"""
cifar-10数据集是分batch存储的,这是载入单个batch
@参数 filename: cifar文件名
@r返回值: X, Y: cifar batch中的 data 和 labels
"""
with open(filename,'rb') as f:
datadict=pickle.load(f,encoding='bytes')
X=datadict[b'data']
Y=datadict[b'labels']
X=X.reshape(10000, 3, 32, 32).transpose(0,2,3,1).astype("float")
Y=np.array(Y)
return X, Y
def load_CIFAR10(ROOT):
"""
读取载入整个 CIFAR-10 数据集
@参数 ROOT: 根目录名
@return: X_train, Y_train: 训练集 data 和 labels
X_test, Y_test: 测试集 data 和 labels
"""
xs=[]
ys=[]
for b in range(1,6):
f=os.path.join(ROOT, "data_batch_%d" % (b, ))
X, Y=load_CIFAR_batch(f)
xs.append(X)
ys.append(Y)
X_train=np.concatenate(xs)
Y_train=np.concatenate(ys)
del X, Y
X_test, Y_test=load_CIFAR_batch(os.path.join(ROOT, "test_batch"))
return X_train, Y_train, X_test, Y_test
# 载入训练和测试数据集
X_train, Y_train, X_test, Y_test = load_CIFAR10('data/cifar10/')
# 把32*32*3的多维数组展平
Xtr_rows = X_train.reshape(X_train.shape[0], 32 * 32 * 3) # Xtr_rows : 50000 x 3072
Xte_rows = X_test.reshape(X_test.shape[0], 32 * 32 * 3) # Xte_rows : 10000 x 3072
class NearestNeighbor:
def __init__(self):
pass
def train(self, X, y):
"""
这个地方的训练其实就是把所有的已有图片读取进来 -_-||
"""
# the nearest neighbor classifier simply remembers all the training data
self.Xtr = X
self.ytr = y
def predict(self, X):
"""
所谓的预测过程其实就是扫描所有训练集中的图片,计算距离,取最小的距离对应图片的类目
"""
num_test = X.shape[0]
# 要保证维度一致哦
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
# 把训练集扫一遍 -_-||
for i in range(num_test):
# 计算l1距离,并找到最近的图片
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances) # 取最近图片的下标
Ypred[i] = self.ytr[min_index] # 记录下label
return Ypred
nn = NearestNeighbor() # 初始化一个最近邻对象
nn.train(Xtr_rows, Y_train) # 训练...其实就是读取训练集
Yte_predict = nn.predict(Xte_rows) # 预测
# 比对标准答案,计算准确率
print ('accuracy: %f' % ( np.mean(Yte_predict == Y_test) ))
如果你用这段代码跑CIFAR-10,你会发现准确率能达到38.6%。这比随机猜测的10%要好,但是比人类识别的水平(据研究推测是94%)和卷积神经网络能达到的95%还是差多了。
注:python3实现的
3 K最近邻分类器
你可能注意到了,为什么只用最相似的1张图片的标签来作为测试图像的标签呢?这不是很奇怪吗!是的,使用k-Nearest Neighbor分类器就能做得更好。它的思想很简单:与其只找最相近的那1个图片的标签,我们找最相似的k个图片的标签,然后让他们针对测试图片进行投票,最后把票数最高的标签作为对测试图片的预测。所以当k=1的时候,k-Nearest Neighbor分类器就是Nearest Neighbor分类器。从直观感受上就可以看到,更高的k值可以让分类的效果更平滑,使得分类器对于异常值更有抵抗力。
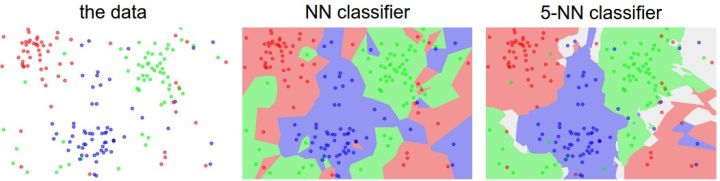
上面示例展示了Nearest Neighbor分类器和5-Nearest Neighbor分类器的区别。例子使用了2维的点来表示,分成3类(红、蓝和绿)。不同颜色区域代表的是使用L2距离的分类器的决策边界。白色的区域是分类模糊的例子(即图像与两个以上的分类标签绑定)。需要注意的是,在NN分类器中,异常的数据点(比如:在蓝色区域中的绿点)制造出一个不正确预测的孤岛。5-NN分类器将这些不规则都平滑了,使得它针对测试数据的泛化(generalization)能力更好(例子中未展示)。注意,5-NN中也存在一些灰色区域,这些区域是因为近邻标签的最高票数相同导致的(比如:2个邻居是红色,2个邻居是蓝色,还有1个是绿色)。
k-NN分类器需要设定k值,那么选择哪个k值最合适的呢?我们可以选择不同的距离函数,比如L1范数和L2范数等,那么选哪个好?还有不少选择我们甚至连考虑都没有考虑到(比如:点积)。所有这些选择,被称为超参数(hyperparameter)。在基于数据进行学习的机器学习算法设计中,超参数是很常见的。一般说来,这些超参数具体怎么设置或取值并不是显而易见的。
你可能会建议尝试不同的值,看哪个值表现最好就选哪个。好主意!我们就是这么做的,但这样做的时候要非常细心。特别注意:决不能使用测试集来进行调优。当你在设计机器学习算法的时候,应该把测试集看做非常珍贵的资源,不到最后一步,绝不使用它。如果你使用测试集来调优,而且算法看起来效果不错,那么真正的危险在于:算法实际部署后,性能可能会远低于预期。这种情况,称之为算法对测试集过拟合。从另一个角度来说,如果使用测试集来调优,实际上就是把测试集当做训练集,由测试集训练出来的算法再跑测试集,自然性能看起来会很好。这其实是过于乐观了,实际部署起来效果就会差很多。所以,最终测试的时候再使用测试集,可以很好地近似度量你所设计的分类器的泛化性能。
好在我们有不用测试集调优的方法。其思路是:从训练集中取出一部分数据用来调优,我们称之为验证集(validation set)。以CIFAR-10为例,我们可以用49000个图像作为训练集,用1000个图像作为验证集。验证集其实就是作为假的测试集来调优。下面就是代码:
# 假定已经有Xtr_rows, Ytr, Xte_rows, Yte了,其中Xtr_rows为50000*3072 矩阵
Xval_rows = Xtr_rows[:1000, :] # 构建1000的交叉验证集
Yval = Y_train[:1000]
Xtr_rows = Xtr_rows[1000:, :] # 保留49000的训练集
Ytr = Y_train[1000:]
# 设置一些k值,用于试验
validation_accuracies = []
for k in [1, 3, 5, 7, 10, 20, 50, 100]:
nn = NearestNeighbor() # 初始化一个最近邻对象
nn.train(Xtr_rows, Ytr) # 训练...其实就是读取训练集
Yval_predict = nn.predict(Xval_rows,k=k) # 预测
# 比对标准答案,计算准确率
acc = np.mean(Yval_predict == Yval)
print ('accuracy: %f' % (acc,))
# 输出结果
validation_accuracies.append((k, acc))关于上述的代码,预测阶段加入了新参数k,所以,修改predict函数如下:
def predict(self, X, k=1):
"""
所谓的预测过程其实就是扫描所有训练集中的图片,计算距离,取最小的距离对应图片的类目
"""
num_test = X.shape[0]
# 要保证维度一致哦
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
# 把训练集扫一遍 -_-||
for i in range(num_test):
closest_y = []
# 计算l1距离,并找到最近的图片
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
a = np.argsort(distances)[:k]#从小到大按照索引排序
closest_y = self.ytr[a]
np.sort(closest_y)#从小到大排序,改变原列表的值的顺序
y = np.bincount(closest_y)#统计各个元素出现的次数
z = np.argmax(y)#结合上一步,得出出现最多的数值(整数时成立)
Ypred[i] = z # 记录下label
return Ypred程序结束后,我们会作图分析出哪个k值表现最好,然后用这个k值来跑真正的测试集,并作出对算法的评价。
4 最近邻分类器的优劣
首先,Nearest Neighbor分类器易于理解,实现简单。其次,算法的训练不需要花时间,因为其训练过程只是将训练集数据存储起来。然而测试要花费大量时间计算,因为每个测试图像需要和所有存储的训练图像进行比较,这显然是一个缺点。在实际应用中,我们关注测试效率远远高于训练效率。其实,我们后续要学习的卷积神经网络在这个权衡上走到了另一个极端:虽然训练花费很多时间,但是一旦训练完成,对新的测试数据进行分类非常快。这样的模式就符合实际使用需求。
Nearest Neighbor分类器在某些特定情况(比如数据维度较低)下,可能是不错的选择。但是在实际的图像分类工作中,很少使用。因为图像都是高维度数据(他们通常包含很多像素),而高维度向量之间的距离通常是反直觉的。
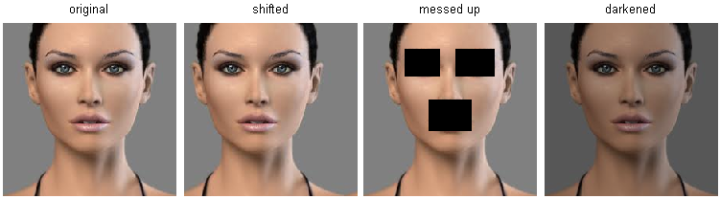
上图中,右边3张图片和左边第1张原始图片的L2距离是一样的。很显然,基于像素比较的相似和感官上以及语义上的相似是不同的。