六、模型效果评估
前面讲过,最初我们建模的目的就是预测,最早人们使用的是传统的数理统计分析建模,这是一套完整的理论,是建立在基本假设、总体、样本、抽样、估计、检验等概念框架之上,有一系列完整的数学方法和和数理统计工具去计算统计量,进而得到总体规律而形成的统计模型,然后用模型来进行预测。
但是,机器学习和深度学习是没有这一套系统的理论框架的,机器学习和深度学习更像是一个实证类方法,评估一个模型的好坏看预测效果即可,预测效果好就是好模型,没人再追究你模型建立的前提假设是否合理、你总体服从什么分布等问题。也所以机器学习和深度学习在调优上,都是根据前人不断实验的基础上总结出来的一些经验和心得。也所以这个领域充斥着大量的"经验之谈"的、"约定成俗"的、没有任何严谨的理论基础的做法。所以也有“炼丹”一说的戏称。当前就是这么一个状况。
即使这样,但也不是完全无迹可寻,我们一般都是先把数据集分成训练集和测试集。在训练模型的时候,只给模型学习训练集的数据,模型训练完毕,让模型预测测试集的数据,检测模型的预测效果。
如果一个模型在训练集的表现和预测集的表现差不多一样好的时候,我们就说这个模型拟合比较好,这是我们追求的最佳状态,也是我们模型调优的目标。
如果一个模型在训练集上的表现非常好,在测试集的表现很一般,我们就说这个模型过拟合了,就是学习过头了。
如果一个模型在训练集上的表现就很一般,那它在测试集的表现几乎100%的概率也是一般了,很少有训练集一般,测试集很好的情况。此时我们就说这个模型欠拟合,就是这个模型根本就没有捕捉到训练集上的数据规律。
下面我们用代码展示一下拟合、欠拟合、过拟合的直观图:
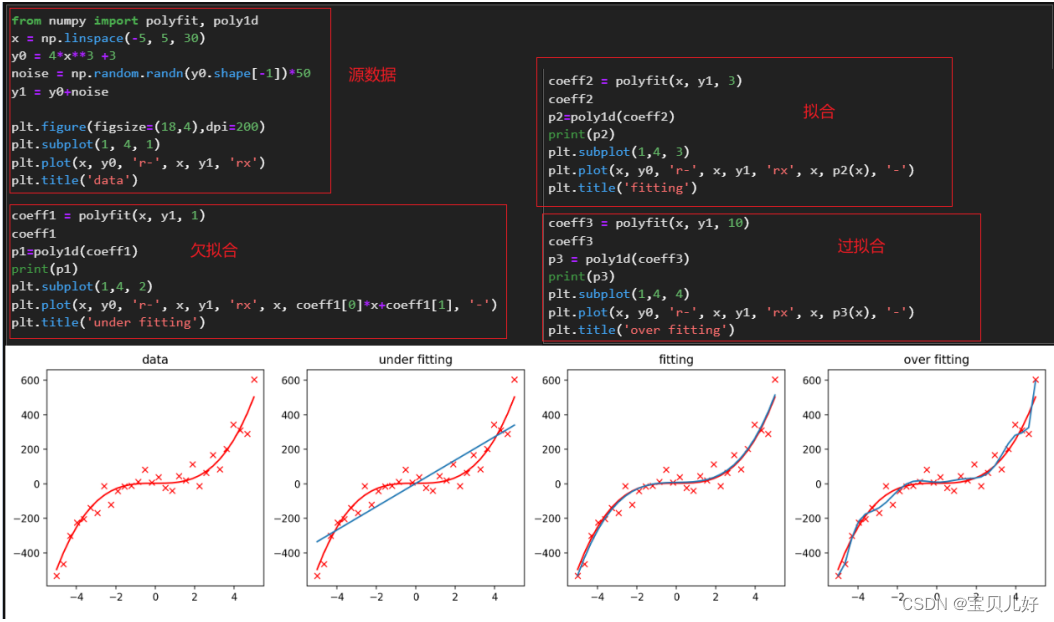
y1是在y0的基础上添加了一些没有规律的噪音noise,所以当我们探索x和y1之间的规律的时候,我们就认为x和y1之间的规律的本质就是x和y0之间的关系:4x**3+3
所以我们在拟合x和y1之间的多项式关系时,图3就是完全拟合,就是找到了x和y1之间的规律;图2就是欠拟合,就是绝大多数点都没有预测对;图4就是学过头了,把一些噪音都学进来了,所以图4是过拟合,虽然图4的拟合曲线穿过了最多的y1,也就是预测到了最多的y1,但是它一定在未知的数据集上表现不会很好,这种情况就是过拟合。
大家都认为:模型出现的过拟合和欠拟合,是和模型复杂度有很大关系的。当模型越复杂,就越能捕捉训练集上的数据的规律,模型就越能很好的拟合训练集。但是当模型复杂到一定程度,就会过度捕捉训练集规律,就会出现训练集效果很好,但测试集效果很差,就是出现了过拟合。 而模型的复杂度指的就是神经网络的层数和层上的神经元个数,以及每层上的激活函数。就是神经网络的层数更多,就更复杂;而相同层数的网络,层上的神经元个数越多,模型就越复杂。并且带激活函数的网络比不带激活函数的网络更复杂。
七、模型调优
1、增加模型复杂度一定是线性层和激活层的同时增加
前面说了,线性层负责的是线性变换,激活层负责的是非线性变换,所以当你要增加模型复杂度的时候,一定不仅仅是线性层的堆叠,一定要同时加激活层。
2、在模型训练时,一定要有适度的随机性
如果完全没有随机性,模型就无法学习,因为模型只能学2遍训练集,所以模型肯定是捕捉不到总体规律的,所以模型一般都是欠拟合。如果随机性设置过大,比如你的小批次设置的太小,第一次循环的时候模型捕捉的就是一个非常小的几个样本的特殊规律,而不是总体规律,甚至有可能和总体规律是相反的,此时当第二批样本带入的时候,就会出现极大的损失值,因为第一轮迭代的参数就不是总体的规律嘛,并且第二轮迭代的梯度也是第二个小批次的特殊规律,所以同理第三轮小批数据带入的时候也会出现极大的损失值,如此反复,模型就很难收敛,而且出现大起大落的波动。
下面举个完全没有随机性的例子:
A:这里的随机性我们想要的随机性!就是这里必须要随机,不能不随机!就是不能每个epoch循环的时候,每次喂入的小批次都是一样的数据、一样的喂入顺序。必须每次喂入不一样的小批次! 为什么?你想啊,每次喂入10条样本,我们就开始正向传播进行预测->通过损失函数求损失->反向传播求梯度->更 新模型参数这些步骤。意思就是我们每次更新模型参数的时候都是使用的是不同的损失函数!论文里的专业表述就是损失函数的随机创建现象。
我们之前讲梯度下降的时候,市面上几乎所有的资料就用盲人下山来类比,就是盲人先随机站在了一点上,然后他左探探右探探,哪边的坡度最陡,他的步子就超哪个方向迈出来下山。但是这里要强调的是,这个盲人下山是把所有样本喂入模型,正向传播,求的损失函数,而我们这里是小批次样本喂入模型的,所以盲人的每走一步,它面临的山就不是同一座山,就是走一步换一座山。虽然每步的山都不一样,但是他依旧要按照当时的最陡的方向下山。
那自然就会有人问,为啥要小批次,我们全部样本,这样山就不变了,这样不香嘛?是滴,不能这样!因为我们神经网络是训练大数据的好吧,如果100万条样本带入模型,那损失函数要逆天啦,哪有那么多的算力求梯度啊?!所以我们要用小批次,而且小批次效率高啊,最极端的就是一条一条的样本带入,每条 样本都求损失。但这样也是效率又太低!所以我们选择合适个数的小批次。
那自然就产生另外一个疑问,那小批次的梯度怎么能代表所有样本的梯度呢?是的,小批次数据的规律确实是不能代替总体数据的规律,但是,小批次也是从总体中的抽样,所以它会在大方向上代替,当这10条样本太逆天,把梯度方向拉到了反方向,那正是由于分批次的随机性,那下一个小批次就可能是一个代 表总体规律的典型呢,所以下一步的迭代方向是不是又拉了回来。所以在下降过程中可能偶然帮助整体损失函数跨越最小值点,这也是借助随机性解决问题的典型例子。
B:这里是每次示例化一次,就随机生成一组模型参数。意思就是每次模型的初始参数都是不一样的。或者说盲人下山时,每次的出发点都是不一样的。所以后面模型效果展示的时候,我会多截几张不同的结果。 这里我们展示一下,如果数据分小批次的时候没有随机性,其效果是这样的: 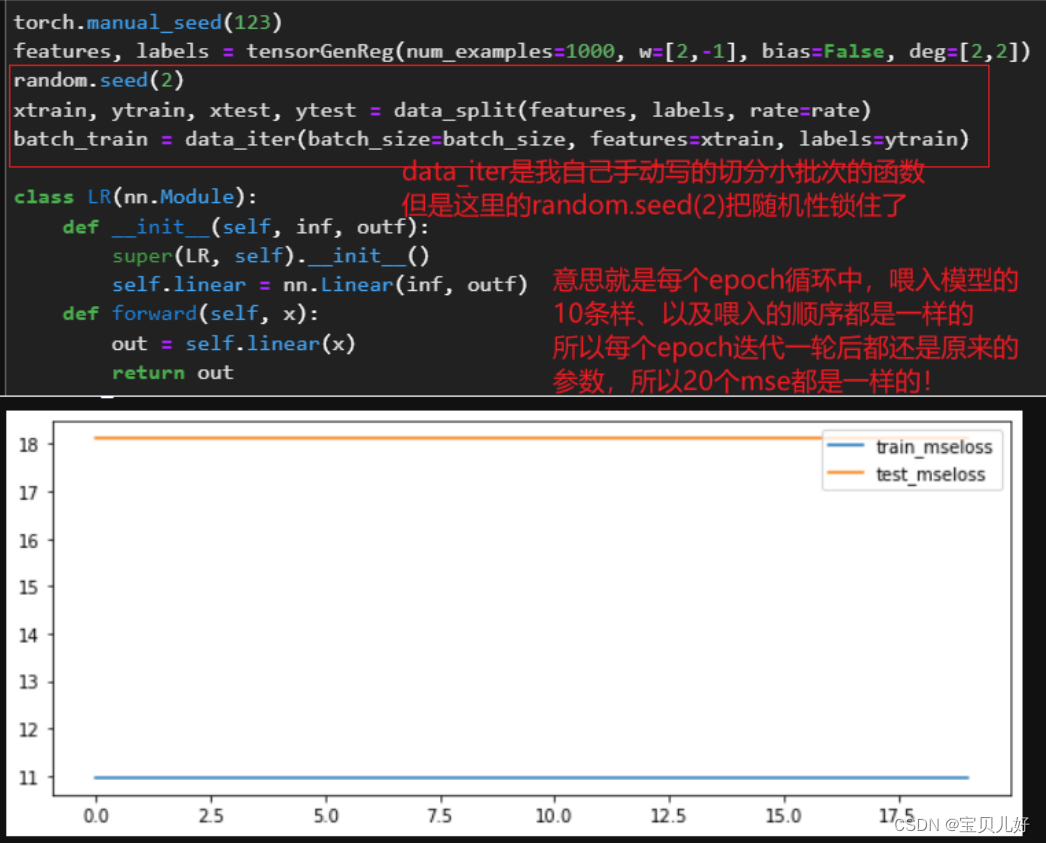
为什么会是这样的?我把迭代的过程给大家看看:
从上图的分步结果查看,如果我们喂入模型迭代参数的batch是一样的话:第一轮迭代,参数从模型生成的随机参数迭代到([00.9559, 0.6846]),第二轮迭代时,第一个batch虽然和它上一轮迭代时的初始参数不一样,但是经过相同的batch数据,迭代70次(我们的训练集是700条数据,batchsize设置的是10,所以要迭代70次)后又把参数迭代到([00.9559, 0.6846])!那第三轮迭代时,初始参数就是([00.9559, 0.6846]),此时每个小批次的迭代过程都是和第二轮迭代过程一模一样。同理第三轮epoch,直到第20轮epoch都时一模一样!所以我们每次把700条训练样本带入模型求损失,那当然一直求的是10.96182。 这也说明其实从第3轮到第20轮的训练,都是无效的训练,就是只训练了2个epoch。后面的学习都啥也没学到。
所以,我们分小批次带入模型训练学习的时候,一定一定要是随机的小批次!
3、出现现梯度不平稳的原因
其实在模型优化过程中,增加模型复杂度和增加随机性都是非常好调整的,最大的难点是模型训练过程中经常出现的梯度不平稳现象。什么是梯度不平稳?为什么会不平稳?是本部分重点要阐明的。

如果我们在模型训练中经常画出上面的训练集和测试集损失时,就是典型的梯度不平稳。梯度不平稳意味着模型不稳定,或者说上图的模型都是不可用模型,就是这样的模型根本就不能用于生产,或者说就是建模失败了。
那出现上面的损失曲线,是出了什么问题?问题在哪个环节?以及后续的优化措施?如何优化?或者说如何让模型按照我们的预想训练?要知道这些问题的答案,我们就要非常熟悉数据是如何在神经网络中正向流动的、反向是怎么求梯度的、求得梯度又是怎么迭代的。
(1)形象化理解数据的流动过程
下面是我自己总结的一个数据流动全过程。是用一个3层回归类模型做例子描述的。中间是模型的图像化展示,四周的文字是描述数据是如何流动的。
上面也是一个数据正向传播的过程。
(2)从数学角度理解梯度的计算过程
现在,我们假如喂入的batchdata是x,标签是y;第一个隐藏层的参数是w1,梯度是grad1;第二个隐藏层的参数是w2,梯度是grad2;输出层的参数是w3,梯度是grad3;假设激活函数是F,激活函数的导函数是f。那么,我们用数学符号描述上面的过程就是:
yhat = w3*F(W2*F(w1*x))
说明:我们从上面图示模型上看,以及我们的输入数据结构[10,2],我们很容易认为是x*w,但pytorch是用的w*x,所以我们这里也用w*x。其实没啥区别,都是算矩阵的乘,而且结果都一样。就是为了和pytorch的展示尽量一致,我们就尽量按照pytorch的的计算过程展示。
小结:正向传播完毕,也就是求出了yhat,也就是求出了预测值。有了预测值,就可以求损失了。求出损失,就可以得到数据传播计算图了。有了计算图,就可以反向链式求导法求梯度了。有了梯度就可以迭代参数了。由于我们迭代的目标是让损失往小的方向走,所以我们这一轮参数迭代就意味着模型就学习了一个batch的数据规律。当我们把所有的batch都学一遍后,就是学了一个epoch。当我们循环下一个epoch的时候,由于前面数据处理的时候我们故意制造了随机性,这个epoch中的batchs就和上个epoch的batchs不同,然后再学习这些batchs,就是学了第二个epoch。如此循环多次(一般200次都是正常的),就是模型重复学习了样本数据。
至此,我们就也非常明白了:loss就是一个关于yhat和y的函数,而y是标签,就是y是个常量,所以loss是一个关于yhat的函数:loss(yhat)
那现在我们就可以根据 yhat = w3*F(W2*F(w1*x))和loss(yhat),手推一下,展示如何通过链式求导计算梯度:
由于数学符号实在太难敲,我就在纸上写了,写得有点歪,凑合看吧。
至此,我们就得到了各层梯度的数学表达了,那我们就继续分析:
先看grad1,也就是第一层隐藏层上的参数w1的梯度值:
w1x就是数据流入第一个隐藏层的线性变换结果,这个值是不是正向传播的时候都有计算过呀。
F(w1x)就是数据经过第一个隐藏层上的激活函数的非线性变换结果,这个值是不是也是正向传播时有计算过呀。
w2*F(w1x)就是数据经过第二个隐藏层的线性变换结果,这个值正向传播时也已经算出来了。
f(w1x)是第一层隐藏层线性变换后的结果再求导,这个值需要再计算的。
f(w2*F(w1x))是第二层隐藏层线性变换后的结果再求导,这个值也需要再计算。
可见,grad1的大小和传入它的数据x有关、和它后面层的参数有关(w2,w3)、和激活函数的导函数有关。
同理grad2,就是第二层隐藏层上的参数w2的梯度。它的构成比grad1少了一点。它和它上层对它的输入有关(F(W1X))、和它后面层的参数有关(w3)、和激活函数的导函数有关。
grand3是输出层上的参数w3的梯度。grand3的梯度就只和它前面的一层对它的输入有关了。F(w2*F(w1x))就是第二层隐藏层的输出。
小结:可见,神经网络每层的参数梯度大小和传入该层的数据有关、和后面层的参数有关、和后面层的激活函数导函数有关。所以,在神经网络中,越靠前的层的参数梯度受影响的因素越多,越靠后的层的参数梯度影响因素越少。并且越靠前的层就有越多的激活函数导函数的连乘。
所以,如果影响梯度大小的因素都是大于1,那梯度值就是大于1的连乘效果,梯度值就迅速被放大,出现梯度爆炸。如果影响梯度大小的因素都是小于1的值,那连乘后梯度就急剧缩小,接近0,出现梯度消失。
梯度消失和梯度爆炸是梯度不平稳的两个极端现象,但实际上梯度消失和梯度爆炸是我们训练模型过程中经常遇到的现象,比如不同层的梯度大小可能都有指数级的差别,但是这种现象是我们不愿意看到的,因为这意味着模型无法训练或者模型不可用。
(3)从模型代码角度理解数据流及梯度问题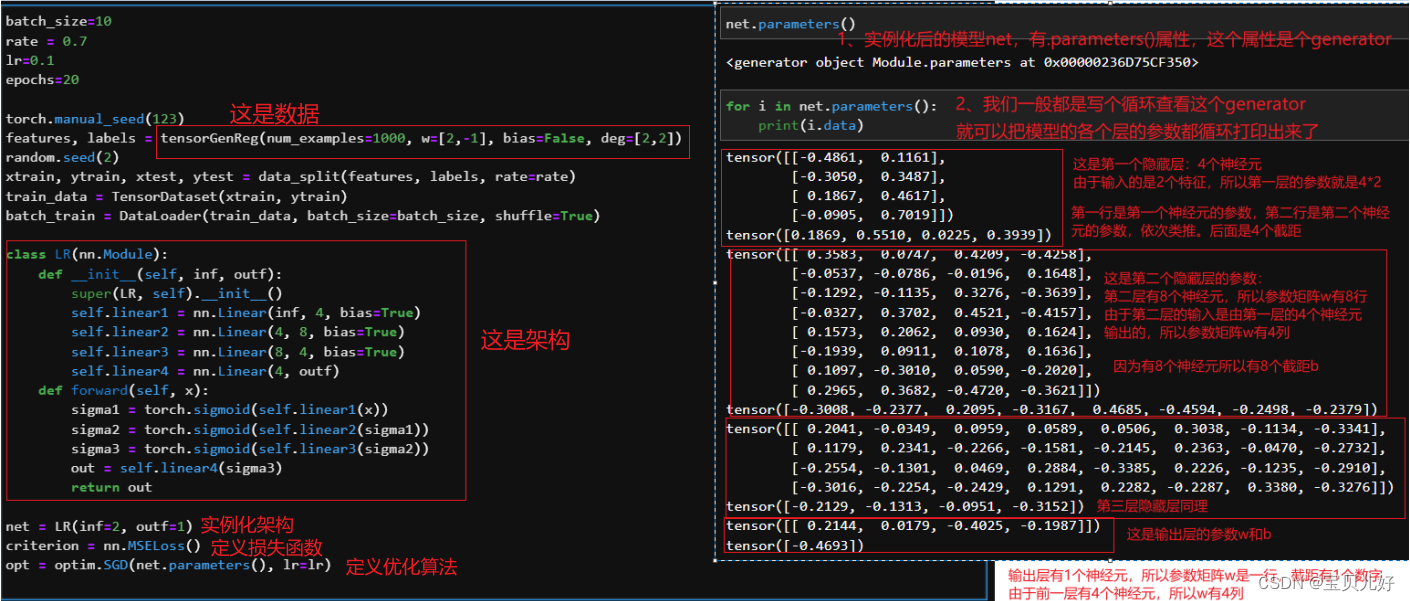
那我们现在用上面的数据和上面的模型,手动训练三轮,看看参数和梯度:

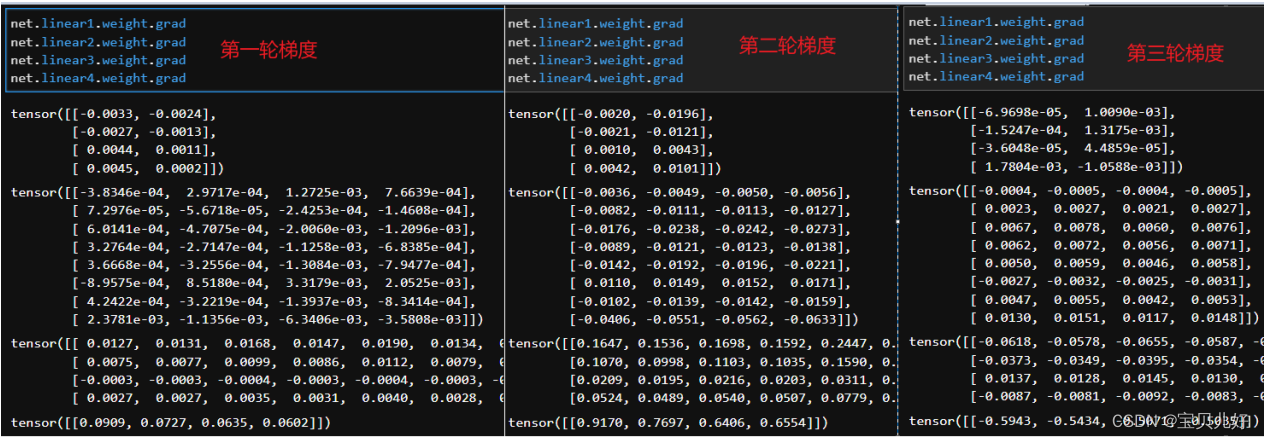
我们用眼睛还是能看到一些趋势的:后层梯度大,前层梯度小。后层参数变化大,前层参数变化小。
我们前面分析的结论是:
梯度消失的表现是:越靠前面的层梯度变化越小,几乎为0,就是参数不迭代了;越靠后面的层梯度变化正常,就是参数正常平稳迭代。而梯度消失会造成模型参数得不到更新,使得复杂模型的效果和简单模型的效果基本一样。就是模型没有学习到数据规律、模型欠拟合、模型不可用。
梯度爆炸的表现是:越靠前面的层梯度变化越大,几乎为是后面层的指数倍,导致前层参数巨大变动;越靠后面的层梯度变化正常,就是参数正常平稳迭代。而梯度爆炸就造成模型训练的损失函数波动极大,就是模型不平稳,模型的可信度就不高。就是模型根本没法收敛,等于训练失败,模型自然也不可用。
而且不管是梯度消失还是梯度爆炸,都不会随着迭代次数增加而消失。
补充:从上图的手动推导梯度的过程,我们可以非常清晰的看到神经网络是怎么进行链式求梯度值的;我们也更加深刻体会到pytorch为什么建立回溯机制以及数据计算图(前面讲得内容);我们也体会到什么是反向传播求梯度。也正是有了这样的一套求梯度方法,才使得神经网络得到了极大的发展。大大节省了算力。不然你用矩阵求导试试,在大模型上用矩阵求导求梯度是根本不现实的。
至此,我们从模型可视化图、数学梯度推导、模型代码,三大维度梳理了一下深度神经网络模型出现梯度不平稳现象的成因,从根本上讲就是:数据流和激活函数!所以,我们的优化方向也是从数据流和激活函数两方面入手。
4、从激活函数入手调优
我们之前展示过sigmoid,tanh,relu三种激活函数,但是当时是为了讲一个完整的建模流程而讲的。现在我们从梯度的角度再来看看这三个激活函数:
sigmoid函数是把数据从-∞到+∞映射到0-1
所以有2个结论:一是,sigmoid函数的输出均大于0。假如数据是0均值输入的,那经过sigmoid函数就变成非0均值了,出现偏移现象,这会导致后一层的神经元将得到上一层输出的非0均值的数据作为输入。
二是,sigmoid函数的两头(-∞,-6)和(∞,6),我们称为饱和区间,就是不管你的输入有多大,都给映射成1了,不管你的输入有多小,都给映射成0了。所以数据一旦在某层落入饱和区间,就是某层的输入超出[-6,6]的范围后,输出值就非常接近,基本上就没有变化了,导致后面的层的输出也非常接近,最后就无法训练了。
sigmoid导函数是把数据从-∞到+∞映射到0-0.2
我们看上面手推的grad1,里面有2次导函数连乘,所以就会有2次最大是0.2*0.2。假如我们的模型层数更多一点,是不是第一层梯度就是多个小于0.2的数连乘,那第一层的梯度是不是就趋近0了,这种现象就是梯度消失。grad2情况会好一点,grad3就只和传入它的数据有关,不受导函数影响。也就是前面的层就越容易出现梯度消失现象,就是前面的层的参数几乎停止迭代,因为梯度为0嘛,所以每次迭代参数都不变,梯度消失了。 一般来说,sigmoid网络在5层之内就会产生梯度消失现象。
tanh激活函数:
tanh激活函数似乎规避了sigmoid激活函数的所有缺点:规避了数据的非0均值输出、导数取值范围在0到1之间优于sigmoid导函数的0到0.25。同时发扬了sigmoid激活函数的优点:在0附近梯度较大,易于训练。但是其实tanh激活函数也是有很多问题,它是既容易出现梯度消失也容易出现梯度爆炸。从数学推导结果看,如果所有的分量都大于1,那累乘后梯度值就大大放大了;如果所有分量都小于1,那累乘后梯度值就大大缩小了。所以它既容易梯度消失也容易梯度爆炸。
relu激活函数:
和sigmoid、tanh激活函数不同,relu激活函数最大的问题不是梯度问题,而是由于其使得部分神经元线性变换后的数值归零的特性,会导致神经元失效问题,就是dead relu problem。这个问题前面已经给大家从直观上描述过。一方面由于relu的问题和sigmoid、ganh的问题压根就不是一类问题,所以得分开讲。另一方面由于relu的问题比较好解决,所以这里我们先把这个问题的解决方案讲了。
我们先来看一下dead relu problem的成因:
relu激活函数是把所有传入它的小于等于0的数据流都统统转化为0流出。上图中的F都看成relu函数。所以:
(1)从梯度角度看,relu激活函数的导函数取值要么是1要么是0。当取值为1的时候,就能保证各层参数的梯度在计算的时候,就不会被累乘中的导数部分而影响梯度的不平稳,因为导数是1嘛,梯度就不受激活函数导函数的取值范围和累乘效应而产生梯度消失或者梯度爆炸。这是relu激活函数优点。就是在relu的导函数不取0的情况下,relu激活函数相对于sigmoid和tanh激活函数,它是可以保证梯度的平稳性的激活函数。但如果导函数取值为0,那就是另外一番景色了。下面(2)(3)是分析导函数为0的情景。
(2)带relu激活函数的模型,不管是模型的哪个线性层,只要它不小心出现了一组参数w,并且正好w*上层的数据流入<=0,那么这层线性层就会全部输出0。并且,一旦某层输出全部为0,后面层就毫无疑问就都输出的是0,进而yhat就是0。就是说:只要某层输出全是0,某层的后面层输出都是0,最后的预测结果yhat也是0。
loss是yhat的函数,此时yhat是恒0,那偏yhat/偏w == 0, 此时的各层梯度就都是0了。那就等于学完这条样本,参数没有发生变化。等于说模型就没有学这条数据。如果一个batch的数据都出现0输出,那就意味着这批数据没有被模型学习。如果全部数据都出现0输出,那这轮epoch参数就都没有迭代。如果多轮epoch都是这样,那loss曲线就会出现平直线。就是参数没有更新、模型无法训练。
(3)此时,自然会有人开始想象,如果不是某一整个线性层都出现0输出,某个线性层只有几个神经元出现0输出呢。是的,这种是最常见的情况,因为relu函数是把传入它的小于等于0的数据都转化为0。而上一层的传出和本次的w相乘很容易出现负数,就被输出0了。当某层的部分神经元输出0,那数据传入下层的时候,下层处理的数据就是不带有上层的0输出神经元的数据的。所以我们称0输出的神经元在反向传播时梯度都是0,都不更新参数,那我们就说这些输出是0的神经元都是失效的神经元,这些神经元dead了。下面有代码展示。
(4)输出为0,也就是神经元失效现象,它是一个概率问题,当模型层数越多,每层上的神经元越多,就越有可能遇到这种现象。而且只要有一层出现0输出,所有层的参数梯度就都是0,模型的所有参数就不迭代。只要一个神经元出现0输出,这个神经元的梯度就是0,这个神经元的参数就不迭代。
上面是理论上的推导,下面我们通过模型证实一下: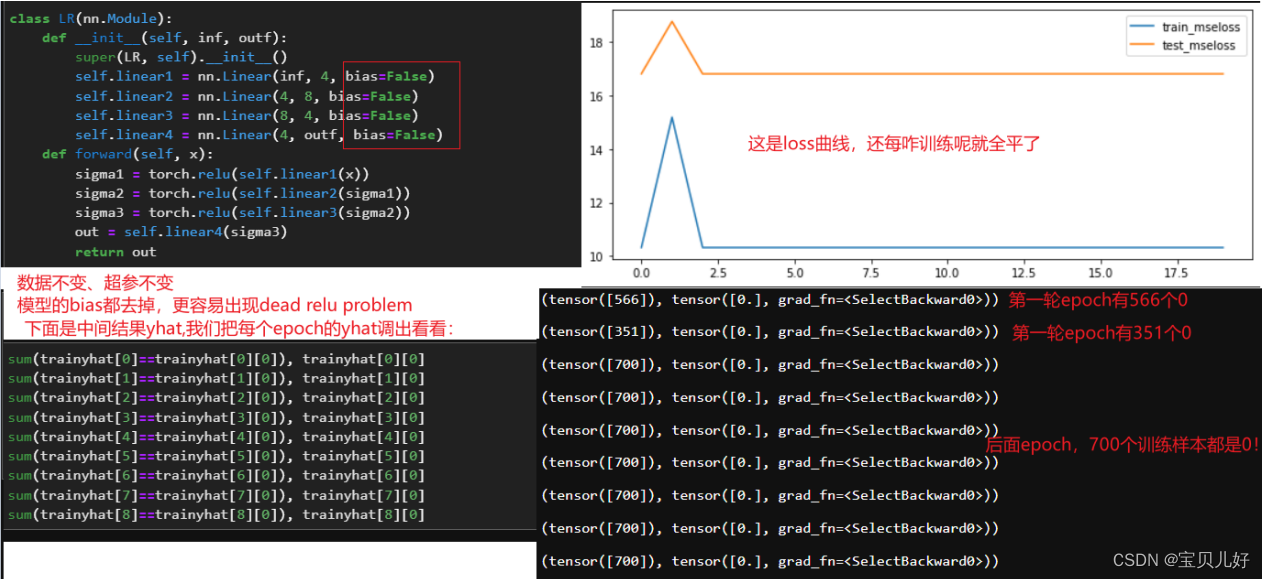
要说明的是:我们上面的大量实验中,relu激活函数的loss曲线虽然也比较平,但不是这个实验中的这么平,那是因为我们的模型是带截距的,所以每个epoch输出的都是bias的结果,就是每个epoch的yhat都是一个非零常数,当然也有可能是0常数,所以loss看着没有这么平,还有点点波动。但无论如何都是典型的dead relu problem。
在所有解决dead relu problem的方法中,最简单的、效率最高的一种方法就是通过调整学习率lr来缓解dead relu problem。我们知道学习率是一个超参数,对模型的影响是各方面的。如果lr越小,收敛速度就越慢;如果lr越大,又容易跳过最小值点造成模型结果震荡。但是对于relu激活函数来说,参数是稍有不慎,就非常容易落入输出值全是0的陷阱,因此我们训练过程中谨慎一点,就是学习率调小一点就可以有效避免了。而且由于relu激活函数的计算过程相对简单,多迭代一些次数不会显著增加计算量的。我们现在把lr从0.1改到0.01,看一下效果:
从上图可以看出学习率调小后,同样是上上图的数据和模型架构,训练后出现上上图的结果的概率确实小了很多,而出现上图左边的效果的概率也不大,最经常出现的是上图右边的效果。
我们把每轮的预测值全部调出来:
上上图从第三轮训练开始后,每个epoch、每个batch、每条数据都输出0。
上图左侧,每个epoch、每个batch、每条数据输出都不为0。
上图右侧,每个epoch、每个batch、都有部分数据输出为0。
这就说明:
(1)relu激活函数是选择样本的! 就是当一个batch喂入模型后,这个batch中哪条样本输出是0,就说明这条样本根本就没有参与本batch的参数迭代。就是本轮batch的参数迭代,这条样本就根本没有贡献任何力量。或者说带relu激活函数的模型是选择数据进行参数更新的,就是只选择那些输出结果不为0的样本进行训练学习。
(2)当某一条样本在这轮epoch中没有被选择训练学习,不代表下个epoch也没被选中,因为参数是变化的,每个epoch中的batch我们都提前设置的不一样了。
(3)我们给这种每次都有选择性的忽视部分数据的现象,看作是线性层进行了“非线性”变换
下面我们再从更微观的层面看看理论推导部分的(3)
当某条样本喂入模型后,虽然是非0输出,就是模型学习了这条样本。但也不一定是所有的神经元都学习了这条数据,而是部分神经元学习了,另一部分神经元就没学,就是失去了活性。当出现上上图就是所有神经元都失去了活性,当出现上图左侧的情况,就是所有神经元都学习了,当出现上图右侧的情况,就是 部分神经元学了。现在我们看看部分神经元失去活性的结果:

小结:
relu激活函数相对不容易出现梯度消失和梯度爆炸,更多的是出现神经元失效问题。所以只要采取措施规避大量神经元失效问题后,relu激活函数就比sigmoid、tanh更适合深度网络模型。
rele激活函数的非线性变换的本质是:选择数据进行训练。
当relu激活函数的某线性层输出全部为0时,本条样本的训练就是无效的,本条样本就等于没有被学习。但是,本轮没学习不代表下轮也不被学习。 当relu激活函数的线性层某个神经元输出0时,这个神经元就失去了活性。但是不代表下一条样本这个神经元也会失去活性。
总结:在深度学习领域,最开始我们都用的是sigmoid函数,后来发现sigmoid函数的输出结果不是0均值,才推出tanh函数,双曲正切函数,2000年后大家又开始偏爱relu函数,目前relu函数是使用最广、效果最好的一种激活函数,但是在RNN和LSTM等这两个经典的神经网络模型中仍然偏爱tanh和sigmoid,而不是relu函数。relu激活函数是在2015年才盛行的,之后针对relu激活函数的很多优化方法也都是根据上述的特性展开的。目前relu激活函数的应用最广泛,所以它有很多变种的relu和相应的优化方法,效果都非常好。这也都是经验之谈,具体还是得适合你的数据。
5、从数据流入手调优
从数据流入手调优的理论基础是由xavier glorot在2010年提出的Glorot条件,此后衍生出来的各种调优手段,基本都可以从这个角度来理解。
2010年,Xavier Glorot在其发表的论文《Understanding the difficulty of training deep feedforward neural networks》中指出,应该保持各层的激活值和梯度的方差在传播过程中保持一致。 也被称为glorot条件。或者说,Glorot条件的核心要求是:要求正向传播的时候,数据每流经一层神经网络前后的方差一致;在反向传播时,数据每流经一层神经网络的时候,该层梯度前后方差一致。这个条件我们称为向前传播条件和反向传播条件。
这个条件也是后面很多各种优化算法的基本准绳。各种优化算法的目的都是要达到glorot条件,因为只有达到glorot条件,模型都可以有效平稳的训练。
(1)xavier方法初始化模型参数
xavier方法自然是Xavier Glorot提出的,虽然xavier方法是针对数据流提出的,但它在带sigmoid和tanh激活函数的模型上效果非常好,所以当我们使用这两种激活函数时,在模型优化时,可以试一试xavier方法的效果。
首先我们先看看模型的初始参数能不能都初始化为0?看下面的实验:
上面实验如果把激活函数从sigmoid改成tanh,那就grad永远是0,w也永远是0。就是没法训练了。
上面的三个batch训练就意味着每层就只有一个神经元在学习,而不是不同的神经元学习数据的不同角度的特征。至于数学上为什么是这个结果参考深度学习 | (6) 关于神经网络参数初始化为全0的思考_神经网络如果权重全部初始化为0会存在什么问题-CSDN博客 文章写的非常详细。
所以结论就是:
模型的初始参数不能全部为0或者全部为某一个数。这样会导致无法训练、网络就学习不到数据的不同特征,进而模型失效。
同时模型的初始参数也不是随便随机生成的,最好是生成的这组随机参数能满足glorot条件,那模型至少不会一开始训练就出现梯度不平稳现象了。
此外,你还要知道相同模型,不同的初始化参数,会极大的影响模型的迭代、收敛的速度,还会影响模型的最终表现。这也是为什么我们前面的各种实验结果产生的各异的loss曲线。这种现象的根本原因还是在于神经网络模型在进行训练时,不确定性过多。在一个有诸多不确定性的系统中,再加上不确定的初始参数,初始参数的不确定性会被这个系统放大,并且在采用小批量梯度下降算法时,数据在随机变化,损失函数也会跟着随机随机变化。
那如何生成一组满足glorot条件的随机参数?
xavier方法的核心理念就是去创建一组满足glorot条件的初始参数值。而Glorot条件要求正向传播的时候,数据每流经一层神经网络前后的方差一致;在反向传播时,数据每流经一层神经网络的时候,该层梯度前后方差一致。
假设数据流x流入到网络的某一线性层时,那该层神经元接收到的数据是: x ;该层神经元处理完数据,传出的数据流就是z, 并且z=∑w*x
根据glorot条件, 则var(z)=∑(E(w)^2*var(x) + E(x)^2*var(w) + var(w)*var(x))
又因为我们假设x,w是独立同分布(一个是采集处理后的数据,一个是随机生成的参数)都是0均值,所以:D(x)=0,E(w)=0, 上面的var(z)=∑(var(w)*var(x))=n*var(w)*var(x)
而根据glorot条件,我们希望线性变换后不影响数据方差,也就是要求var(z)=var(x),那么就推出:var(w)=1/n, n就是上一层神经元的个数。
上面是正向传播的情况,反向传播计算公式不变,但含义正好相反,x代表当前层传出的数据,z代表上一层神经元接收到的数据。所以反向传播时,n就代表当前层神经元的个数,所以为了区别我们分布命名为n-in, n-out,所以为了兼顾正向传播和反向传播两种情况,Xavier Glorot将w的取值定为: var(w)=2/(n-in+n-out),即取均值这个折中方案。
上面就推导出每层神经网络参数的方差。
如果我们设置w服从在[-a,a]区间的均匀分布,根据公式:在[a,b]区间上服从均匀分布的随机变量方差为(b-a)^2/12,那么, var(w)=2a^2/12=a^2/3=2/(n-in+n-out), 就得出a=根号(6/n-in + n-out)
如果我们设置w服从正态分布,则w服从(0, 根号(2/n-in + n-out))的随机变量。
至此,我们就可以设置每一层的初始参数了。
说明:上面我们用的n-in, n-out不是很严谨,其实如果指代某一次传播过程中,上一层神经元数量和下一层神经元数量的叫法是扇入fan in和扇出fan out, 那么:
正向传播时:var(w)=1/fan_in, fan_in表示上一层神经元的个数。
反向传播时:var(w)=1/fan_out, fan_out表示下一层神经元的个数。
取折中方案,就是取均值:var(w)=2/(fan_in + fan_out)
也就是xivar方法中初始参数的方差可以写为:var(w)=2/(fan_in + fan_out)。
如果我们设置w服从在区间[-bound, bound]内的均匀分布,bound=根号3var(w)来确定
如果我们设置w服从正态分布,则w服从(0, 根号war(w))的随机变量。
这就是Xavier方法的数学推导部分。原论文的推导过程比我写得复杂得多,尤其是反向传播时方差的推导,我这里只是直接用了结果。下面我们看pytorch如何实现xavier方法:
使用torch.nn.init.xavier_uniform_进行均匀分布的初始化参数设置:
A:你本来的计算结果就是让它符合,数据正向反向流入流出某线性层,的方差一致,你才计算出的参数取值区间,那你现在自己调整了区间,自然就不能保证方差一致,进而不能保证训练平稳了。所以我们要谨慎调整gain。 B:2行4列的参数矩阵,就是本层有2个神经元,上层有4个神经元。如果均匀分布fanin+fanout=6, 就是根号里是1,所以边界就是-1到1直接的均匀分布。 同理,我们可以使用torch.nn.init.xavier_normal_进行高斯分布的初始化参数设置。这里就不代码演示了。
(2)Kaiming方法(HE初始化)
如果说Xavier参数初始化优化方法,是针对tanh和Sigmoid激活函数的优化方法,那Kaiming方法就是针对ReLU激活函数的初始化方法。当然前面还展示了调整学习率也可以优化带relu激活函数的网络。
HE初始化的参数方差是:var(w) = 2/fan_in或var(w) = 2/fan_out
就是分子和xavier方法的分子一样,都是2,但分母变成了某层扇入或者扇出的神经元数量。虽然用fanin和fanout最后计算得到的var值不一样,但是作者的论文也论证了,说对模型训练过程是没有影响的,建模过程中任选其一即可。
方差确定了,均值是0,那就可以生成均匀分布或者高斯分布的一组随机参数了: 如果设置w服从在区间[-bound, bound]内的均匀分布,bound=根号3var(w)来确定,就是[-根号6/fan_in, +根号f/fan_in]
如果设置w服从正态分布,则w是服从N(0, 根号war(w))的随机变量。
说明:HE初始化不仅针对relu激活函数,还可以对其变种激活函数使用。
下面看看HE方法在pytorch中的实现: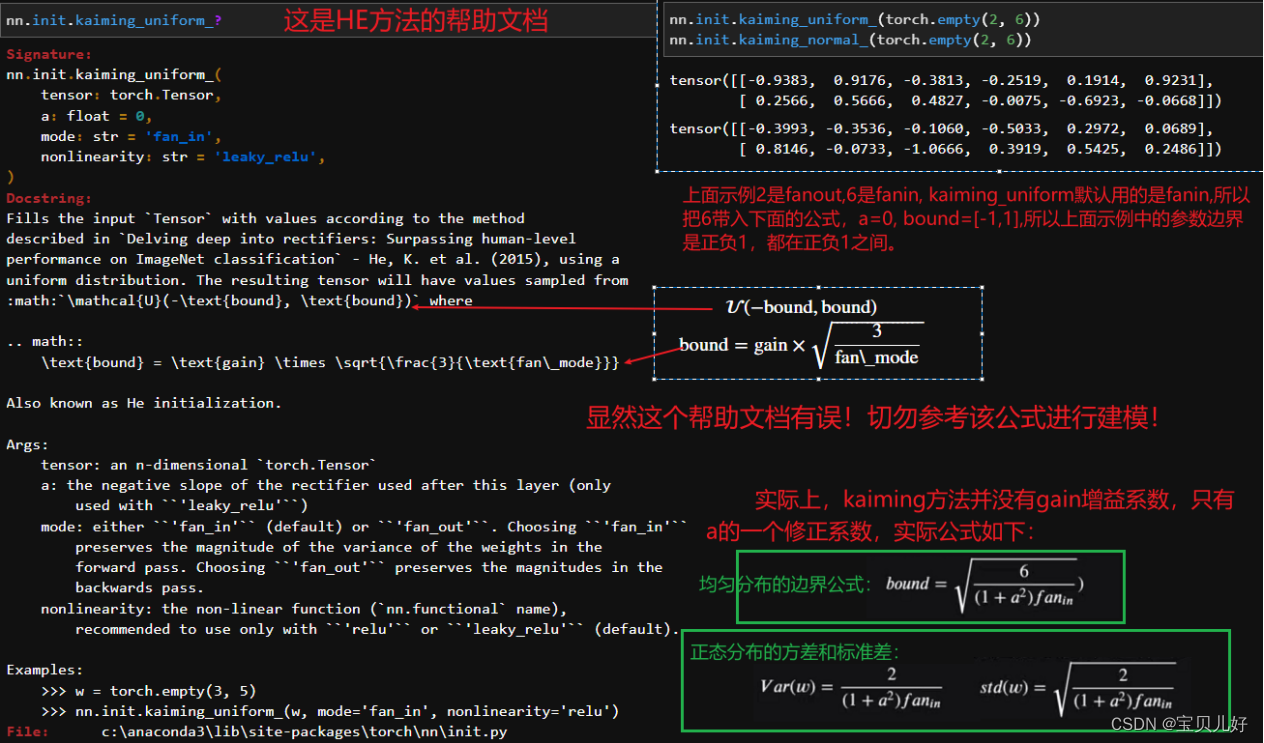
(3)添加BN层(Batch Normalization)
参数初始化一定程度上可以使得模型各层都得到有效学习,模型训练过程更加平稳、收敛速度也更快。但是伴随着模型不断训练,此后的参数就不受我们控制了,所以还是会有梯度不均衡的问题。然而模型一旦开始训练,我们是不能手动参与修改模型参数的。此时如何处理梯度不平稳问题呢?调整每层的输入数据——Batch Normalization方法。
目前来看,应用最为广泛、并且被验证的实践效果最好的数据归一化方法,是由Sergey loffe和Christian Szegedy在2015年发表的《Batch Normalization:Accelaerating Deep Network Training by Reducing Internal Covariate Shift》中提出的方法。该方法通过修改每一次带入训练的数据分布(每一batch)的数据分布,来提升模型各层梯度的平稳性,从而提升模型学习效率、提高模型训练结果。由于修改的是每一个batch的数据分布,因此该方法也被称为batch normalization(BN),小批量数据归一化。
BN层的内容实在是太多太多了,这里暂时不展开写了,还有最后一个优化方法:学习率优化,也不写了。因为我已经写过两遍了,这是第三遍,所以真是有点厌倦了,我想赶紧开始写RNN,深度视觉的部分,那部分比较有意思。
至此,全连接神经网络的模型调优我们就基本结束了,至于其他的调优方法会在卷积网络中,也就是计算机视觉中再陆续讲解。