深度前馈网络又称多层感知机、前馈神经网络。即只有从x向y方向的传播,最终输出y。
主要包括输入层、隐藏层和输出层。神经网络的模型可以解决非线性问题。
计算网络的参数通过反向传播;如果每一层隐藏层都只有wx+b的运算,则多层累加变为w1*(w2*(w3*x))+a = W*x +a,失去了非线性能力。故每一层后面会加上一个激活层。
实例:学习XOR
单个线性函数无法解决XOR的问题,但是多个线性函数的组合,每个线性函数理解为一个神经元,就可以表示XOR运算。
这里提到了RELU激活函数g(x) = max{0,x},也叫整流线性单元,是大多前馈神经网络的默认激活函数。主要优势运算简单。后面有专门章节介绍和比较各个激活函数。
基于梯度的学习:
代价函数:和其他机器学习使用方式类似。
使用最大似然学习条件分布:
学习条件统计量:
输出单元:
主要就是sigmoid 和softmax两种,都存在饱和的问题,前者在输入过大和过小时,后者在有某个预测特别大时。
sigmoid:主要用于二分类,或输出概率。 这边提到softplus:ζ(x)=ln(1+exp(x))
softmax:

输出每个类可能的概率。多分类以及预测自然语言处理中预测下一句话之类时可以用到。但是如果可能性太多的话,运算过大,可以通过树状结构减少运算。
隐藏单元:
隐藏单元主要包括仿射变换 wx+b 和激活函数g(x),重点研究激活函数:
下面介绍几种常见激活函数:
ReLU族
ReLU:整流线性单元 g(z0) = max(0,z),最常用。
优势:计算方便,大于0部分不存在梯度饱和。
计算时通常将仿射变换的b初始设置一个较小的正数,如0.1,这样开始时大多数样本都可以通过。
缺点:无法学习小于0的样本。
针对上述缺点出现了很多变种:
LeakReLU:
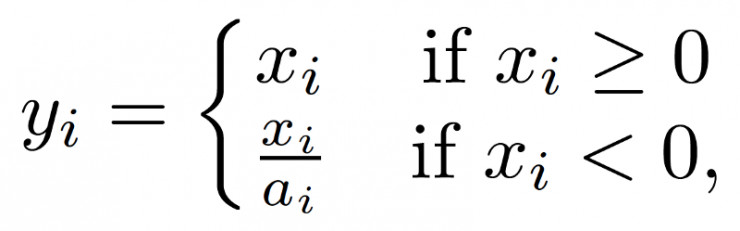
这样可以学习小于0的部分。
PReLU:同LeakReLU,但是a参数是根据数据确定的,而非事先指定
学习方式如下:

RReLU:
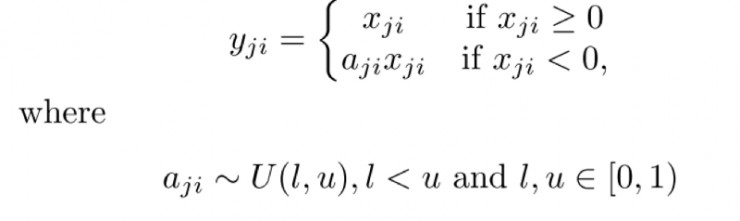
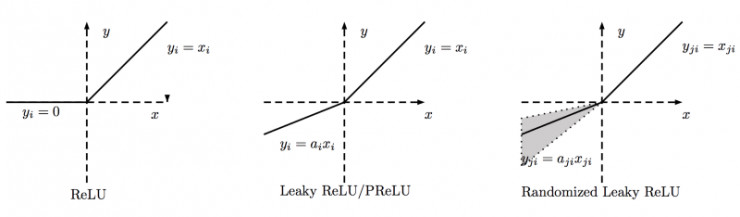
RReLU:训练时是波动的,测试时就固定下来了。
ELU:
SReLU:
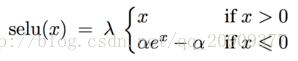
激活后样本均值为0,方差为1,相当于自归一化,效果比batchnormlize好。
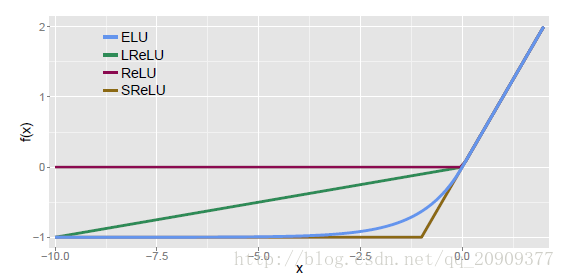
参考别人的一幅图再。
补充一个softplus:
ζ(x)=ln(1+exp(x)):

softplus相当于平滑版的ReLU。
再回忆一下这些激活函数的性质:

Sigmoid族
在整流线性单元之前,主要使用Sigmoid激活函数和tanh激活函数
Sigmoid:
将实数压缩到0到1,适用于输出概率
导数
tanh:g(z) = tanh(z) = 2(2z)-1
将实数压缩到-1到1
导数
sigmoid函数容易饱和,不适合前馈神经网络中隐藏层的激活。但是在诸如LSTM的网络中有用。
二分类问题,一般隐藏层用tanh。因为其均值为0,保持整个网络始终输入0均值的数据,较易优化。
其他都不常用了。也没有什么优势就不介绍了。
架构设计:
理论上深度学习网络可以近似实数空间中的所有函数,只要神经元足够多。
深度学习之所以优越,就是因为同等的表达能力,深层网络需要的神经元小于浅层网络且相对不容易过拟合。
深度网络不单单是一层层的依次链接,后面章节会有介绍多种变种的深度学习网络。
反向传播和其他的微分算法:
从x到y时前向传播,产生一个标量代价函数:
反过来从y计算梯度调整参数称为反向传播。
通过计算图来看数据流向:

主要通过链式法则计算。
这里花书的略深奥了,看了bilibili的一篇视频很不错,链接如下:
https://www.bilibili.com/video/av16577449?from=search&seid=6361052292273718140
大概的意思如下:
反向传播是一层层传播的,比如最后一层往倒数第二层传播,而后第二层继续往第三层传播。不是像我之前一个同事理解的,先计算最后一层相对倒数第二层的偏导,然后计算最后一层相对倒数第三层的偏导,即每次都是最后一层往上传播,这个是不对的。
我们可以理解最后一层的输出为,这个是经过神经网络后最后得到的输出。而实际的输出为y。那么这里的误差就是
,我们设他为Z。这里的Z是输出层所有输出和预期的均方差之和。即:
这个是怎么来的呢,就是经过前面一层所有的权重相乘后相加再加上偏移获得:
这里a1表示前一层和w1对应的那个权重在上一层得到的激活值。
得到前面的Z,而后即可针对w,a,以及b分别求他们的偏导,更新他们的新的值。w和b更新为新的值,a的值可以认为是上一层的预期输出,其差值正好可以作为再上一层的均方误差进行训练。
这里每一次更新不是一个样本,而是一个打乱的小批次,这就是随机梯度下降。
这就是根据自己理解的反向传播算法了。