目录
五、联合采样(top-k & top-p & Temperature)
一、案例分析
在自然语言任务中,我们通常使用一个预训练的大模型(比如GPT)来根据给定的输入文本(比如一个开头或一个问题)生成输出文本(比如一个答案或一个结尾)。为了生成输出文本,我们需要让模型逐个预测每个 token ,直到达到一个终止条件(如一个标点符号或一个最大长度)。在每一步,模型会给出一个概率分布,表示它对下一个单词的预测。
假设我们训练了一个描述个人生活喜好的模型,我们想让它来补全“我最喜欢漂亮的___”这个句子。模型可能会给出下面的概率分布:
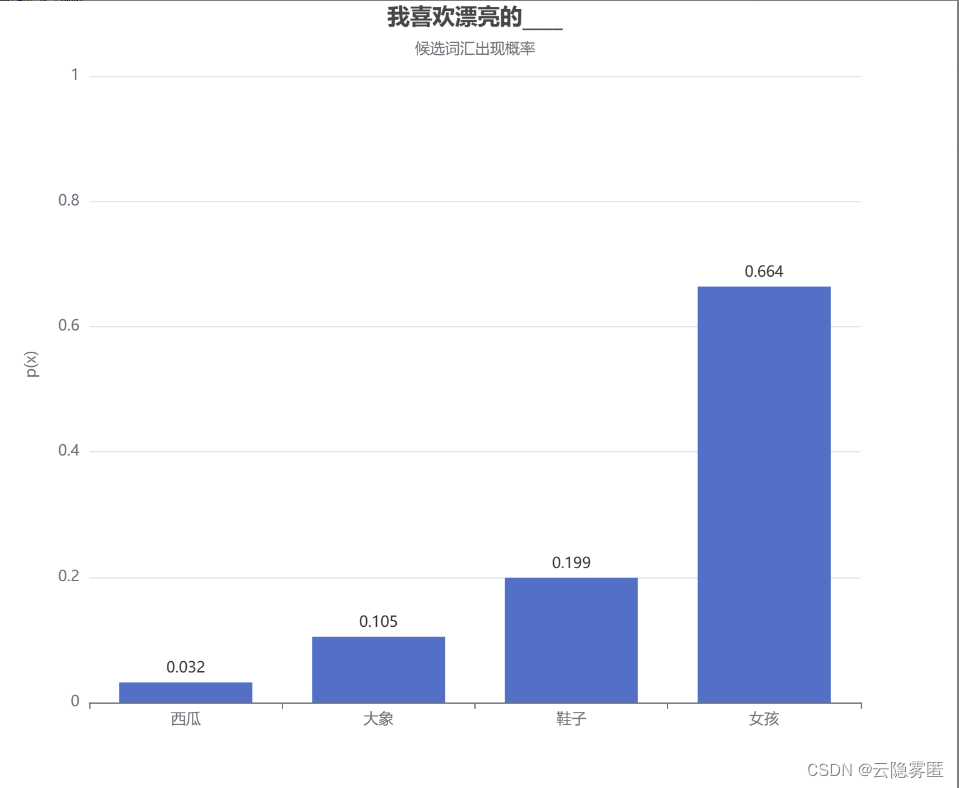
那么,我们应该如何从这个概率分布中选择下一个单词呢?以下是几种常用的方法:
- 贪心解码(Greedy Decoding):直接选择概率最高的单词。这种方法简单高效,但是可能会导致生成的文本过于单调和重复。
- 随机采样(Random Sampling):按照概率分布随机选择一个单词。这种方法可以增加生成的多样性,但是可能会导致生成的文本不连贯和无意义。
- 集束搜索(Beam Search):在每一个时间步,不再只保留当前概率最高的一个单词,而是按照概率从高到低排序,保留前num_beams个单词。这种方法可以平衡生成的质量和多样性,但也难以避免单词重复的问题。我们将在后续章节详细介绍集束搜索。
针对上述方法各自的问题,我们需要思考如何让模型生成的回复用词更加活跃呢?为此,研究人员引入了 top-k 采样、 top-p 采样和temperature采样。
二、top-k采样
在上面的例子中,如果使用贪心策略,那么选择的单词必然就是“女孩”。top-k 采样是对前面“贪心策略”的优化,它从排名前 k 的单词中进行随机抽样,允许其他概率的单词也有机会被选中。在很多情况下,这种抽样带来的随机性有助于提高生成质量。
下面是 top-k 采样的例子:
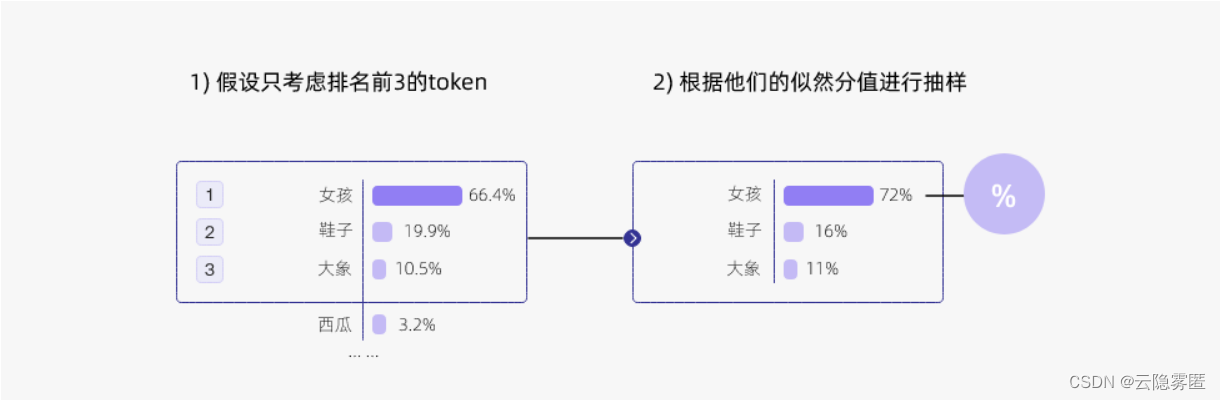
上图示例中,我们将k设置为3,那么模型将只从女孩、鞋子、大象中选择一个单词,而不考虑西瓜这个单词。具体来说,模型首先筛选似然值前三的单词,然后根据这三个单词的似然值重新计算采样概率,最后根据概率进行抽样。
通过调整 k 的大小,即可控制采样列表的大小。“贪心策略”其实就是 k = 1的 top-k 采样。
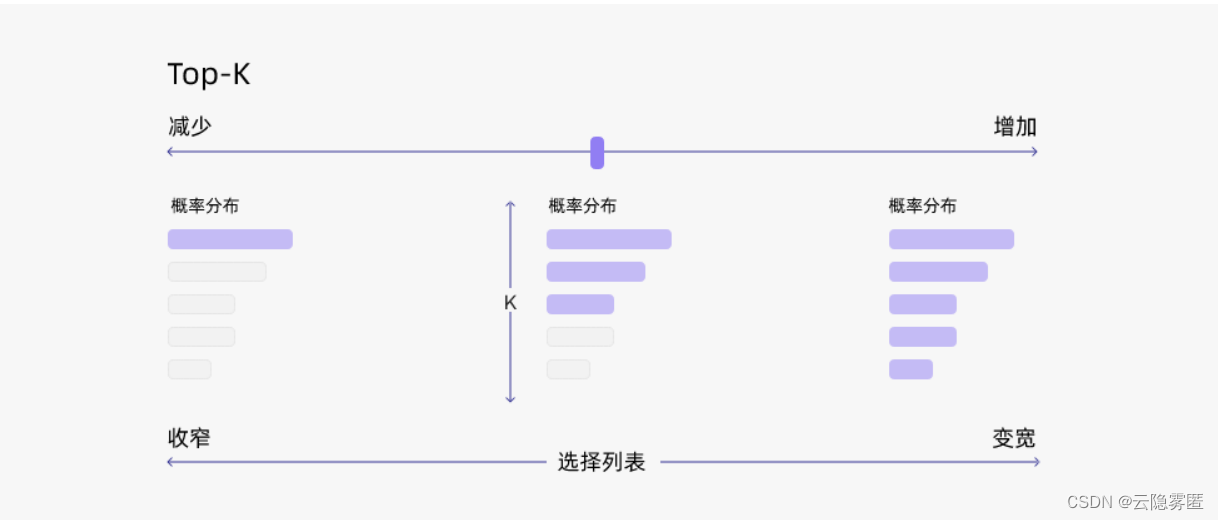
总结一下,top-k 采样有以下优点:
- 它可以通过调整 k 的大小来控制生成的多样性和质量。一般来说,k 越大,生成的多样性越高,但是生成的质量越低;k 越小,生成的质量越高,但是生成的多样性越低。因此,我们可以根据不同的任务和场景来选择合适的k 值。
- 它可以与其他解码策略结合使用,例如温度调节(Temperature Scaling)、重复惩罚(Repetition Penalty)、长度惩罚(Length Penalty)等,来进一步优化生成的效果。
但是 top-k采样也有一些缺点,比如:
- 它可能会导致生成的文本不符合常识或逻辑。这是因为 top-k 采样只考虑了单词的概率,而没有考虑单词之间的语义和语法关系。
- 它可能会导致生成的文本过于简单或无聊。这是因为 top-k 采样只考虑了概率最高的 k 个单词,而没有考虑其他低概率但有意义或有创意的单词。例如,如果输入文本是“我喜欢吃”,那么即使苹果、饺子和火锅都是合理的选择,也不一定是最有趣或最惊喜的选择,因为可能用户更喜欢吃一些特别或新奇的食物。
因此,我们通常会考虑 top-k采样和其它策略结合,比如 top-p采样。
三、top-p采样
top-k 采样有一个缺陷,那就是“k 值取多少是最优的?”这是非常难以确定。于是出现了动态设置单词候选列表大小策略,即top-p采样,又名核采样(Nucleus Sampling)。这也是chatGPT所使用的采样方法。
top-p 采样的思路是:预先设置一个概率界限 p 值,在每一步,将候选单词按照概率从高到低排序,然后依次选择单词构造集合。集合的构造原则是:如果加上当前单词,总概率小于或等于p,那么将当前单词放入集合;如果加上当前单词,总概率大于p,那么丢弃当前单词,集合构造到此结束。模型将从集合中随机选择一个单词,而不考虑集合之外的单词。
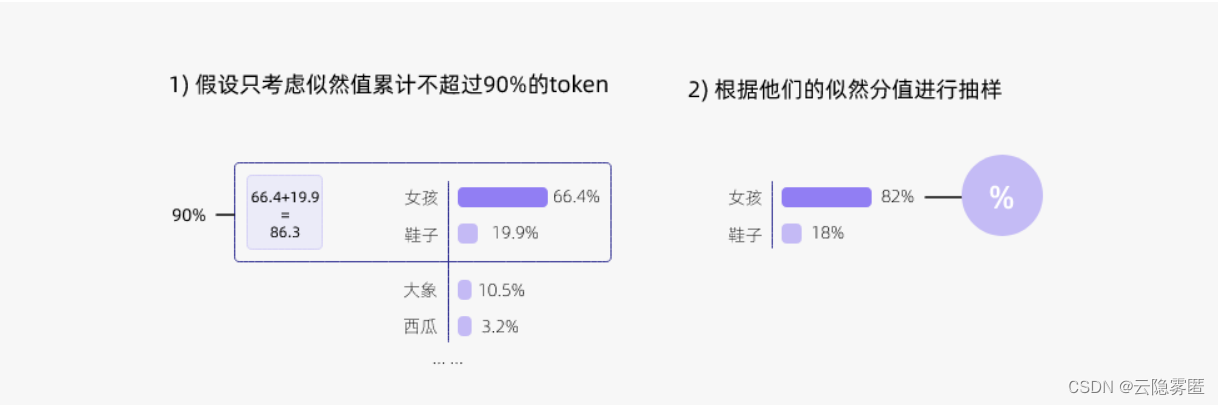
上图展示了 p 值为 0.9 的 Top-p 采样的效果。值得注意的是,我们可以同时使用 top-k采样 和 top-p采样,top-p 将在 top-k 之后起作用。
四、Temperature采样
Temperature 采样受统计热力学的启发,高温意味着更可能遇到低能态。在概率模型中,logits 扮演着能量的角色,我们可以通过将 logits 除以温度来实现Temperature 采样,然后将其输入 Softmax 函数进一步获得采样概率。
Temperature 采样中的温度与玻尔兹曼分布有关,其公式如下所示:
其中 是状态 i 的概率,
是状态 i 的能量, k 是波兹曼常数, T 是系统的温度,M 是系统所能到达的所有量子态的数目。
有机器学习背景的朋友第一眼看到上面的公式会觉得似曾相识。没错,上面的公式跟 Softmax 函数 相似:
本质上就是在 Softmax 函数上添加了温度(T)这个参数。Logits 根据我们的温度值进行缩放,然后传递到 Softmax 函数以计算新的概率分布。
上面“我喜欢漂亮的___”这个例子中,初始温度 T=1 ,我们直观看一下 T 取不同值的情况下,概率会发生什么变化:
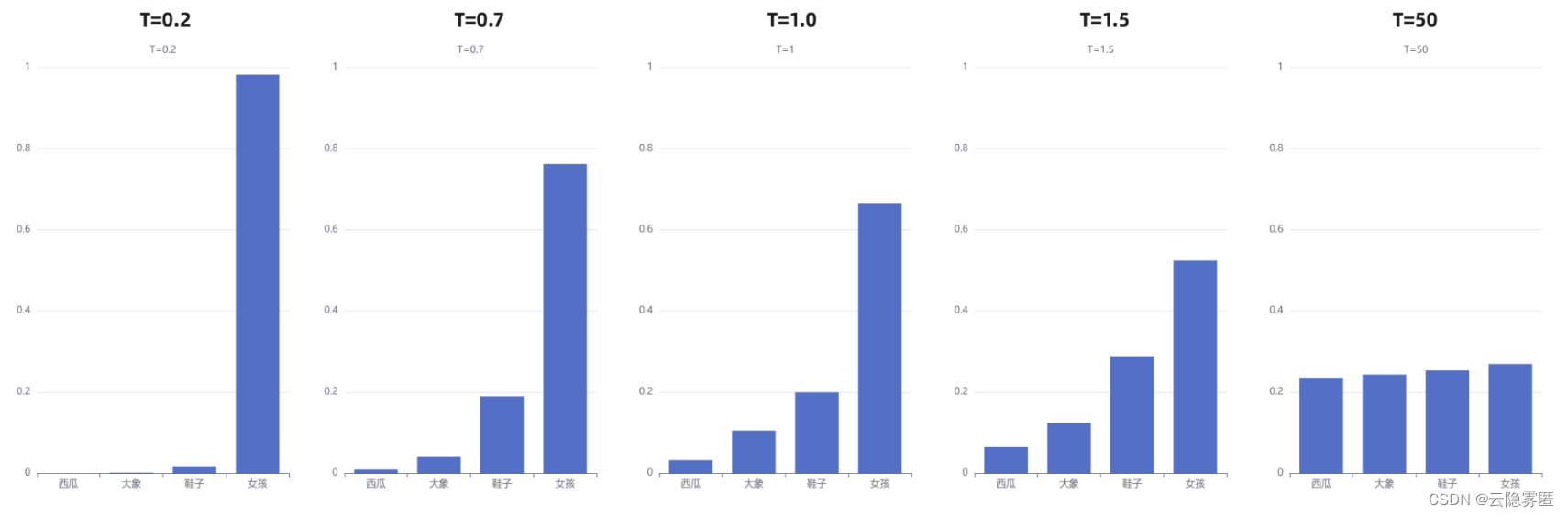
通过上图我们可以清晰地看到,随着温度的降低,模型愈来愈越倾向选择”女孩“;另一方面,随着温度的升高,分布变得越来越均匀。当T=50时,选择”西瓜“的概率已经与选择”女孩“的概率相差无几了。
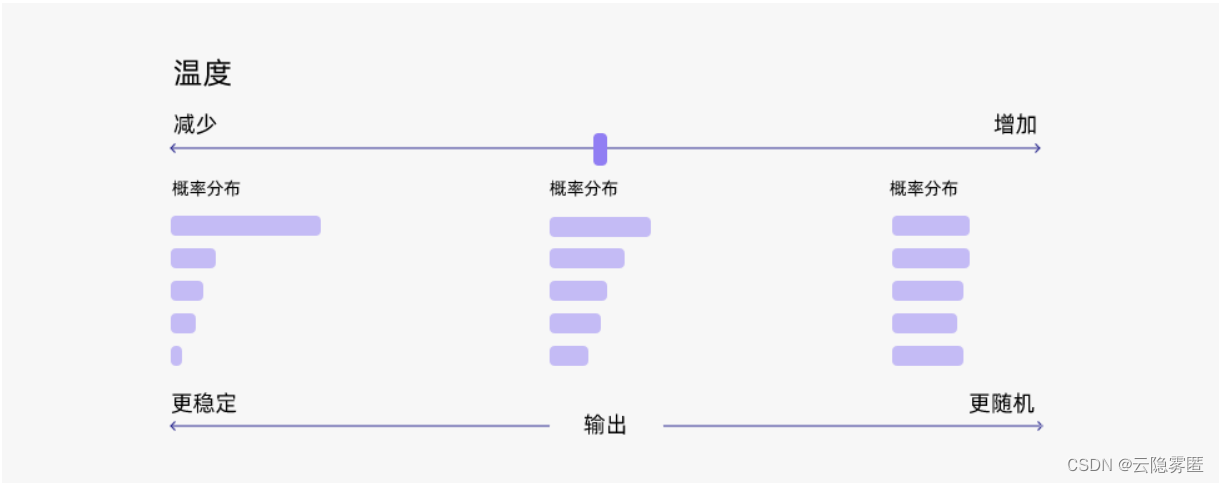
通常来说,温度与模型的“创造力”有关。但事实并非如此。温度只是调整单词的概率分布。其最终的宏观效果是,在较低的温度下,我们的模型更具确定性,而在较高的温度下,则不那么确定。
五、联合采样(top-k & top-p & Temperature)
通常我们是将 top-k、top-p、Temperature 联合起来使用。使用的先后顺序是 top-k->top-p->Temperature。
我们还是以前面的例子为例。
首先我们设置 top-k = 3,表示保留概率最高的3个 单词。这样就会保留女孩、鞋子、大象这3个 单词:
- 女孩:0.664
- 鞋子:0.199
- 大象:0.105
接下来,我们可以使用 top-p 的方法,构造集合,也就是选取女孩和鞋子这两个单词。接着我们使用 Temperature = 0.7 进行归一化,将这两个单词的似然值变为:
- 女孩:0.660
- 鞋子:0.340
接着,我们可以从上述分布中进行随机采样,选取一个单词作为最终的生成结果。
六、补充
6.1 Beam Search
本部分作为补充内容,供感兴趣的读者阅读。
Beam Search是对贪心策略一个改进。思路也很简单,就是稍微放宽一些考察的范围。在每一个时间步,不再只保留当前概率最高的1个单词,而是保留num_beams个。当num_beams=1时集束搜索就退化成了贪心搜索。
下图是一个实际的例子,每个时间步有ABCDE共5种可能的输出,图中的num_beams=2,也就是说每个时间步都会保留到当前步为止条件概率最优的2个序列。
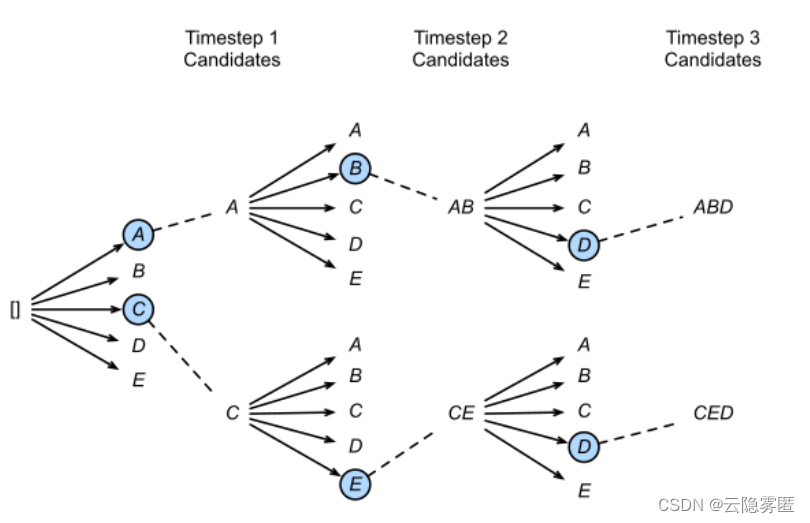
- 在第一个时间步,A和C是最优的两个,因此得到了两个结果
[A],[C],其他三个就被抛弃了; - 第二步会基于这两个结果继续进行生成,在A这个分支可以得到5个候选单词,
[AA],[AB],[AC],[AD],[AE],C也同理得到5个,此时会对这10个进行统一排名,再保留最优的两个,即图中的[AB]和[CE]; - 第三步同理,也会从新的10个候选人里再保留最好的两个,最后得到了
[ABD],[CED]两个结果。
可以发现,beam search在每一步需要考察的候选人数量是贪心搜索的num_beams倍,因此是一种牺牲时间换性能的方法。
6.2 温度(Temperature)参数介绍
温度(Temperature)是一个用于控制人工智能生成文本的创造力水平的参数。通过调整“温度”,您可以影响AI模型的概率分布,使文本更加集中或更多样化。
考虑以下示例:AI 模型必须完成句子“一只猫正在____”。下一个字具有以下标记概率:
玩:0.5
睡:0.25
吃:0.15
驾:0.05
飞:0.05
- 低温(例如0.2):AI模型变得更加专注和确定性,选择概率最高的标记,例如“玩”。
- 中温(例如1.0):AI模型在创造力和专注度之间保持平衡,根据概率选择标记,没有明显的偏见,例如“玩”、“睡”或“吃”。
- 高温(例如2.0):AI模型变得更加冒险,增加了选择不太可能的标记的机会,例如“驾”和“飞”。
如果温度较低,则对除对数概率最高的类之外的其他类进行采样的概率会很小,并且模型可能会输出最正确的文本,但相当无聊,变化较小。
如果温度高,模型可以以相当高的概率输出,或者说不是概率最高的。生成的文本会更加多样化,但出现语法错误和生成废话的可能性更高。
References: