这个算法第一次我是在sift源码里面看见的,之前一直不知道叫什么名字,知道无意间看到一篇博客,才发现了BFPRT的大名。这个名字就挺奇怪的,那是因为该算法由Blum、Floyd、Pratt、Rivest、Tarjan提出,所以就叫BFPRT。。。
此算法可以用来求元素中第k大(或小)的值或是前k大(或小)的值。个人感觉它是对快速选择算法的一种改进,快速选择算法又是基于快速排序的思想。因此本文从快速排序——快速选择算法——BFPRT算法依次讲解。
1.快速排序
一般情况下,快速排序应该是比较排序中效果最好的一种排序算法,虽然它最坏的时间复杂度可能达到O(n2)。
快速排序步骤(从小到大):
(1)首先设定一个分界值,通过该分界值将数组分成左右两部分。
(2)将大于或等于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边。
(3)重复(1)(2)步骤直至数据不能再划分为止。
具体实现如下:
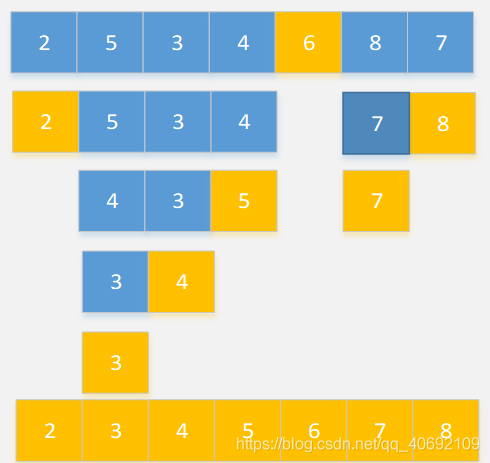
第一次排序:
以第一个数为分界值,从左往右找一个比分界值大的数(7),从右往左找一个比分界值小的数(3),如果比分界值大的在小的左边,则交换两个数位置。再记录下比分界值小的数的个数,最后将分界值放入对应位置,完成第一次排序。接着对分界值左边和右边的数分别进行递归操作直到完成排序。

然后递归进行上面操作,前一个分界值(6)左边的数和右边的数分别重复第一步操作,左右之间不再比较,因为分界值右边的数都比左边的数大。
代码如下:
template<typename T>
static void Qsort(T arr[], int low, int high) {
//c++;
if (high <= low) return;
int i = low;
int j = high + 1;
int key = arr[low];
while (true)
{
/*从左向右找比key大的值*/
while (arr[++i] < key)
{
if (i == high) {
break;
}
}
/*从右向左找比key小的值*/
while (arr[--j] > key)
{
if (j == low) {
break;
}
}
if (i >= j) break;
/*交换i,j对应的值*/
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
/*中枢值与j对应值交换*/
int temp = arr[low];
arr[low] = arr[j];
arr[j] = temp;
Qsort(arr, low, j - 1);
Qsort(arr, j + 1, high);
}
2.快速选择算法
在我们选择元素中第K大的元素时,可能最容易想到的就是对元素进行排序之后选择相应位置的元素,比如我们上面讲的快速排序。但是在我们上面的排序中:

第一轮排序完得到了比6大的元素在6右边,比6小的元素在6左边,如果我们想找中位数,还需要对6右边的87排序吗,当然是不需要。所以快速选择算法的思想就是每一轮排序后,只对我们需要的元素存在的那一边递归排序,不需要对另一边进行排序,这样的平均时间复杂度就将为了O(n)。具体实现如下:
template<typename T>
T Select(T arr[], int low, int high, int m) {
//c++;
if (high <= low)
{
return -1;
}
int i = low;
int j = high + 1;
int key = arr[low];
while (true)
{
/*从左向右找比key大的值*/
while (arr[++i] < key)
{
if (i == high) {
break;
}
}
/*从右向左找比key小的值*/
while (arr[--j] > key)
{
if (j == low) {
break;
}
}
if (i >= j) break;
/*交换i,j对应的值*/
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
/*中枢值与j对应值交换*/
int temp = arr[low];
arr[low] = arr[j];
arr[j] = temp;
if (j > m) {
mQsort(arr, low, j - 1, m);
}
if (j < m) {
mQsort(arr, j + 1, high, m));
}
if (j = m) {
return arr[j];
}
}
这里求到第K大的元素也就求到了前K大的数,因为第K大元素右边的数都比它大。
3.BFPRT算法
前面的快速排序算法和快速选择算法存在这最坏时间复杂度位O(n2)的情况,如果遇到逆序数组将会对排序速度产生较大的影响。在快速选择算法中,每一次的分割值是随便选择的(我们上面选择的是每组元素的第一个数作为分割值),如果分隔值选择较差,会大大增加递归次数,BFPRT算法在快速选择算法的分隔值选择上做了改进,使其尽量接近元素的中位数。
我们不再随机选择一个数据进行划分,而是先寻找一个接近中位数的数据进行划分。这里将输入数组的n个元素划分为n/5组,每组5个元素。首先对每组元素进行插入排序,然后找每组中位数(n/5组有n/5个中位数)的中位数m,以m对数据进行划分。这样可是划分值k更接近中位数,防止最坏情况发生。
找每组中位数(n/5组有n/5个中位数)的中位数m的过程可以通过递归调用BFPRT算法来实现。代码如下:
template<typename T>
static void insertion_sort(T* array, int n)
{
T k;
int i, j;
for (i = 1; i < n; i++)
{
k = array[i];
j = i - 1;
while (j >= 0 && array[j] > k)
{
array[j + 1] = array[j];
j -= 1;
}
array[j + 1] = k;
}
}
//计算分割值在元素中实际的位置(计算有多少元素比它小)
template<typename T>
static int partition_array(T* array, int n, T pivot)
{
T tmp;
int p, i, j;
i = -1;
for (j = 0; j < n; j++)
if (array[j] <= pivot)
{
tmp = array[++i];
array[i] = array[j];
array[j] = tmp;
if (array[i] == pivot)
{
p = i;
}
}
array[p] = array[i];
array[i] = pivot;
return i;
}
template<typename T>
T rank_select(T* array, int n, int r)
{
// c++;
T* tmp, med;
int gr_5, gr_tot, rem_elts, i, j;
/* base case */
if (n == 1)
return array[0];
/* divide array into groups of 5 and sort them */
gr_5 = n / 5;
gr_tot = cvCeil(n / 5.0);
rem_elts = n % 5;
tmp = array;
for (i = 0; i < gr_5; i++)
{
insertion_sort(tmp, 5);
tmp += 5;
}
insertion_sort(tmp, rem_elts);
/* recursively find the median of the medians of the groups of 5 */
tmp = (T*)calloc(gr_tot, sizeof(T));
for (i = 0, j = 2; i < gr_5; i++, j += 5)
tmp[i] = array[j];
if (rem_elts)
tmp[i++] = array[n - 1 - rem_elts / 2];
med = rank_select(tmp, i, (i - 1) / 2);
free(tmp);
/* partition around median of medians and recursively select if necessary */
int i2 = 0;
j = partition_array(array, n, med);
if (r == j)
return med;
else if (r < j)
return rank_select(array, j, r);
else
{
array += j + 1;
return rank_select(array, (n - j - 1), (r - j - 1));
}
}算法比较:
横坐标为数据量,这里去了对数并减了log100,比如横坐标8表示100×2^8个数
纵坐标为计算时间,同样取了对数
通过斜率可以清楚看到这些算法的时间复杂度,因为取了对数,斜率为2表示时间复杂度为O(n2)。
粉色-冒泡排序 O(N2)
红色-快速排序 O(NlogN)
绿色-BFPRT O(N)
蓝色-快速选择算法 O(N)

从图中可以看出BFPRT平均情况下没有快速选择算法快,但是它比较稳定,比如在逆序输入的情况下:

快速排序和快速选择算法时间复杂度都会退化到O(n2),但BFPTR还是能保持O(n)的时间复杂度。(其实不仅不受影响,速度反而更快,这里就不多说了)
