文章:Vision meets mmWave Radar: 3D Object Perception Benchmark for Autonomous Driving
作者: Yizhou Wang, Jen-Hao Cheng, Jui-Te Huang , Sheng-Yao Kuan , Qiqian Fu , Chiming Ni
编辑:点云PCL
欢迎各位加入知识星球,获取PDF论文,欢迎转发朋友圈。文章仅做学术分享,如有侵权联系删文。
公众号致力于点云处理,SLAM,三维视觉,高精地图等领域相关内容的干货分享,欢迎各位加入,有兴趣的可联系[email protected]。侵权或转载联系微信cloudpoint9527。
摘要
传感器融合对于自动驾驶车辆上的准确和鲁棒的感知系统至关重要。大多数现有的数据集和感知解决方案侧重于将摄像机和激光雷达进行融合。然而,摄像机和毫米波雷达之间的融合未被显著的充分利用。从摄像机获取丰富的语义信息,以及从雷达获取可靠的三维信息,潜在地可以实现对于3D目标感知任务的高效、廉价和便携的解决方案。由于毫米波雷达具有适应不同光照或全天候驾驶场景的能力,这种解决方案还可以具有健壮性。在本文中,我们介绍了CRUW3D数据集,包括在各种驾驶场景中同步和校准的66,000帧摄像机、毫米波雷达和激光雷达数据。与其他大规模自动驾驶数据集不同,我们的雷达数据采用射频(RF)张量的格式,其中包含了不仅有3D位置信息还有时空语义信息。这种毫米波雷达格式使得机器学习模型能够在摄像机和雷达之间相互交互和融合信息或特征后生成更可靠的目标感知结果。
主要贡献
有关雷达RF张量的标注的公共数据集有限,如表1所示。
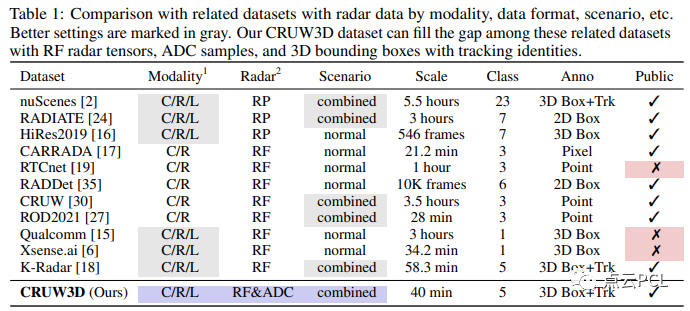
为了填补这方面的不足,我们引入了一个新的数据集名为CRUW3D,其中包含66,000帧同步的摄像机、毫米波雷达和激光雷达数据,涵盖了各种驾驶场景,并带有对象3D边界框和轨迹标注。图1显示了我们在CRUW3D中的数据和注释的一些示例。

图1:CRUW3D数据集中的示例,每个示例包含摄像机RGB图像和一个雷达RF张量对。为了更好地可视化,RF张量被转换为笛卡尔坐标。我们提供了不同驾驶场景和照明条件下的数据示例,相应的3D边界框注释分别投影到RGB和RF张量上。
为了提高数据标注的精度,我们在数据收集系统中包含了一个激光雷达。基于激光雷达点云,我们在每个时间帧内仔细标注了对象的3D边界框,并在整个时间序列中标注了对象的轨迹。我们还提供了传感器之间的校准参数,以允许在不同模态之间进行数据/信息转换或进行传感器融合设置。我们希望CRUW3D数据集能够促进更多关于可靠和健壮协同感知的研究。CRUW3D数据集将很快公开提供。总体而言,我们的CRUW3D数据集具有以下主要贡献:
-
据我们所知,这是第一个具有同步摄像机RGB图像、原始雷达模数转换器(ADC)数据、带有相位的雷达RF张量和激光雷达点云的公共数据集。
-
它包括3D边界框和3D对象轨迹的对象标注,对于各种对象感知任务,例如3D目标检测和3D多目标跟踪具有一定价值。
-
它包含不同的光照条件,对于基于视觉的对象感知方法具有挑战性,因此为基于传感器融合的对象感知算法提供了一个很好的基准。
内容概述
数据收集
我们提出了一个使用双目摄像机、毫米波雷达和激光雷达的数据集收集流程,包括一个传感器平台、一个数据收集软件和一个传感器校准方法。通过我们提出的流程,从三个传感器模态收集的数据可以在时间上同步和在空间上进行精确校准。
传感器平台
我们的数据集收集传感器系统如图2所示,有两个FLIR BFS-U3-16S2C-CS摄像机,一个TI AWR1843雷达板和一个Livox Horizon激光雷达。详细规格列在表2中。
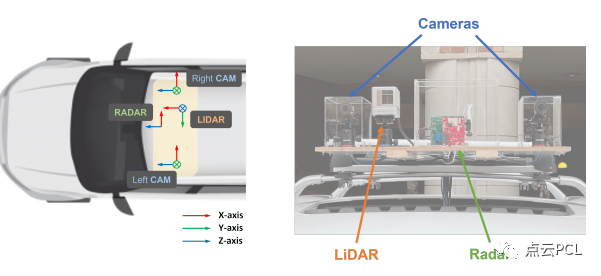
图2:我们CRUW3D数据集的传感器坐标和传感器平台,包括两个摄像机、一个毫米波雷达和一个激光雷达。请注意,我们的雷达没有俯仰角分辨率(即y轴),因此在两个传感器之间应用平移向量之后,它等效于摄像机的鸟瞰图。

传感器同步
我们的数据集收集软件基于Ubuntu下的机器人操作系统(ROS)。对于摄像机和激光雷达,由于它们提供开源API,我们直接将它们集成到ROS系统中。然而TI只提供基于Windows和MATLAB的软件。因此我们在Ubuntu系统中创建了一个Windows虚拟机,并通过ROS进行进程间通信。我们使用由右侧摄像机生成的Transistor-Transistor Logic(TTL)信号进行摄像机和激光雷达之间的硬件时间同步。摄像机和激光雷达传感器都通过它们的API支持TTL信号时间同步。在软件层面上,我们使用ROS库提供的ApproximateTime同步策略将三个传感器的数据对齐到30 FPS的时间槽中。为了在雷达和其他传感器之间同步,我们使用软件触发器启动数据序列收集。服务客户端在收到响应后触发雷达数据的收集过程,并在开始其他传感器数据的收集过程时启动另一个过程。根据我们的实验证明,软件触发器的延迟在几毫秒以下,是可以忽略的。
传感器校准
首先使用Zhang的方法校准了双目摄像机,该方法给出了两个摄像机的内参、畸变系数和外参,这些结果将用于立体矫正。对于摄像机和激光雷达之间的传感器校准,我们采用了Dhall等人提出的校准算法。这将给我们两个变换矩阵,分别表示左摄像机和激光雷达之间的变换,以及右摄像机和激光雷达之间的变换。至于雷达,它根据其俯仰角度仔细安装和与摄像机和激光雷达对齐,其坐标平行于摄像机的鸟瞰图(BEV)。还测量了传感器之间的平移向量,以形成摄像机和雷达之间的完整变换矩阵。
数据处理
摄像头数据处理:首先,由双目摄像头捕捉的图像序列根据摄像头校准进行去畸变和矫正。然后针对由于不良光照条件导致的低质量图像,我们进行图像增强,以提高收集到的视频的质量和光照稳定性。在这里实现了一种基于深度学习的方法,名为RRDNet,使用三分支CNN在零镜头拍摄中恢复曝光不足的图像。为了实现对视频序列的稳定增强结果,我们仅使用每个序列的第一帧对网络进行训练,并对其余帧进行推理。
雷达数据处理:我们的雷达数据处理类似于[28]中提到的预处理,其中雷达范围-方位坐标中的RF张量被描述为俯视图(BEV)表示,其中x轴表示方位(角度),y轴表示距离(距离)。从原始雷达数据中,我们首先对接收到的样本进行范围快速傅里叶变换(FFT)以估算反射的范围。然后我们对不同接收天线上的样本进行第二次角度FFT,以估算反射的方位角。此外,我们还将RF张量转换为笛卡尔坐标,以更好地与摄像机对齐并进行更清晰的可视化。我们的雷达数据处理的更详细描述在补充文件中提到。
激光雷达数据处理:Livox激光雷达采用了一种称为非重复水平扫描的特殊激光扫描技术,与大多数传统激光雷达传感器提供的重复线性扫描显著不同。它积累了在FOV内捕获的点,以在集成时间窗口内获得更密集的点云。然而,基于这项技术,激光雷达的点云无法在相机帧(即1/30秒)内覆盖整个FOV。为确保每个相机/雷达帧都有一个相应的激光雷达帧进行注释,我们将连续三帧(即1/10秒时间窗口)内捕获的点云累积为一个完整的帧,这意味着我们的激光雷达的帧率为10 FPS,如表2中所述。
数据标注
在CRUW3D数据集中,我们在LiDAR点云上标注3D边界框。与KITTI数据集中的3D边界框标签不同,我们使用三个欧拉角来表示每个边界框的方向,因为CRUW3D数据集中的街道不像KITTI数据集中的街道那样平坦。在此,我们在标注过程中考虑以下5个对象类别:行人、汽车、货车、卡车和公共汽车。除了3D边界框之外,我们还为后续的多目标跟踪(MOT)任务标注了对象跟踪ID。然而,由于不同的传感器具有不同的视场(FOV),而且远处物体的点云通常是稀疏的,我们只在重叠区域内标注了对象,如图3所示。在LiDAR点云上标记了3D边界框之后,我们通过来自传感器校准的转换矩阵将所有边界框投影到摄像机和雷达坐标系中。然后,可以使用这些注释分别训练摄像机和雷达的网络。

数据统计
我们的CRUW3D数据集包含约66,000帧各种驾驶场景下的同步摄像机、雷达和激光雷达数据,具有不同的光照条件。大约70%的数据是在正常的驾驶场景中捕获的,具有良好的光照条件。其余30%是在不利的光照条件下捕获的,例如夜间或强光照。表3中显示了一些数据统计信息。在所有数据帧中,我们在训练集中标注了19,000帧,在测试集中标注了10,000帧。
CRUW3D数据集的标注
至于CRUW3D数据集的标注,我们在图4中分析了我们标记的对象的不同分布,包括3D边界框的数量、3D对象轨迹的数量、对象深度、对象方位角和对象尺寸。

图4:CRUW3D数据集中的对象标注分布,包括(a)对象3D边界框分布,(b)对象轨迹分布,(c)对象深度分布,(d)对象方位角分布和(e)对象长度分布。
实验
在CRUW3D数据集上进行了一系列基线实验,包括基于相机的3D目标检测、基于相机的3D目标跟踪、基于雷达的目标检测以及相机-雷达融合的基线。在接下来的实验中,我们只考虑行人和汽车作为我们感知的目标类别。
基于相机的3D目标检测
对于自动驾驶应用来说,单目3D目标检测是至关重要的。用于3D目标检测的神经网络提取图像特征,并在透视图或鸟瞰图中检测对象。我们在我们的基准测试中实现了SMOKE和 DD3D作为基线。
SMOKE 是基于 CenterNet的单级3D目标检测方法。给定输入图像,它检测目标对象在图像平面上投影的3D中心。然而,该算法最初是为KITTI数据集设计的,其3D边界框方向仅包括偏航角。我们通过忽略俯仰和横滚将每个边界框的四元数方向标签转换为偏航角,假设其他旋转角度可以忽略。在此,我们在实现过程中使用DLA-34作为SMOKE的骨干网络。
DD3D 建立在另一个2D目标检测器 FCOS 之上。它使用大规模深度数据集 DDAD15M 对网络进行预训练,以从图像中获得更好的深度感知特征,从而在单目3D目标检测方法中取得了最先进的效果。在实现过程中,我们尝试了两个不同的骨干网络,即 DLA-34和 V2-99 。
与KITTI类似,评估指标包括3D边界框的平均精度(AP)和在IOU阈值为0.5或0.7(对于汽车)以及0.3或0.5(对于行人)时的BEV 2D边界框的平均精度。定量结果如表4所示。从实验结果可以看出,与SMOKE相比,DD3D在各个方面都表现更好。使用更大的骨干V2-99,DD3D在汽车和行人方面均取得了最佳性能。

基于相机的3D目标跟踪
在预测对象3D检测结果之后,我们进一步实现了一个3D多目标跟踪(MOT)算法,称为AB3DMOT,以获得对象3D边界框轨迹。我们根据表4中的3D目标检测结果,即 SMOKE 和 DD3D,进行了基于AB3DMOT框架的实验。AB3DMOT单独跟踪不同的对象类别,并在最后阶段将它们合并,因此我们也分别评估汽车和行人的3D MOT性能,如表5所示。
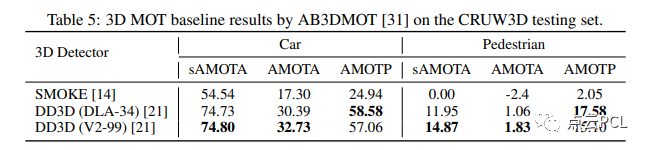
对于3D MOT的评估指标,我们采用了[31]中提出的指标,包括缩放平均多目标跟踪准确度(sAMOTA)、平均多目标跟踪准确度(AMOTA)和平均多目标跟踪精度(AMOTP)。从表5可以看出,“DD3D+AB3DMOT”的组合在3D MOT性能方面表现最佳。由于前一阶段3D检测质量较差,“SMOKE+AB3DMOT”在行人跟踪方面的性能非常差。
毫米波雷达目标检测
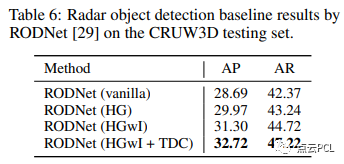
对于基于毫米波雷达的目标检测,它将每个对象检测为RF张量中的一个点,我们使用RODNet作为基线方法。评估指标包括使用不同对象位置相似度(OLS)阈值的平均精度(AP)和平均召回率(AR),这与我们先前的CRUW数据集相同。定量结果如表6所示。整体性能低于CRUW数据集,显示出我们的CRUW3D数据集要更具挑战性,使用HGwI骨干和时间变形卷积的RODNet取得了最佳性能。
总结
本文介绍了一个名为CRUW3D的新基准数据集,其中包含了同步且校准良好的相机、雷达和激光雷达数据,并附有目标3D边界框和轨迹标注。据我们所知,这是第一个具有雷达RF张量、包含幅度和相位信息的公开数据集,可用于3D目标检测和多目标跟踪任务。通过CRUW3D数据集,相机和毫米波雷达之间的传感器融合可以进一步利用,以提高自动驾驶的可靠性和鲁棒性。
以上内容如有错误请留言评论,欢迎指正交流。如有侵权,请联系删除
让我们一起分享一起学习吧!期待有想法,乐于分享的小伙伴加入知识星球注入爱分享的新鲜活力。分享的主题包含但不限于三维视觉,点云,高精地图,自动驾驶,以及机器人等相关的领域。
分享与合作:微信“cloudpoint9527”(备注:姓名+学校/公司+研究方向) 联系邮箱:[email protected]。
为分享的伙伴们点赞吧!