
⭐️ 教程: 手把手打一场AI for Science赛事实践
⭐️ 项目来源: 首届世界科学智能大赛:量子化学赛道——分子属性预测B赛道
量子化学赛道——分子属性预测B赛道
主办方:复旦大学
赛事平台:阿里云天池
⭐️ 9.8入群参赛,第一步做的是配置环境(用云服务器,本地资源无法支撑),然后是跑通 baseline,接着分析 baseline 代码并尝试优化。
1. 赛题
1.1 赛事背景
宏观世界是由大量的微观粒子组成,了解微观粒子的运动和性质,才能更好的认识宏观世界。借助计算机模拟技术和量子力学的基本原理,量子化学计算应运而生,从电子层面阐明分子的能量、性质以及分子间相互作用的本质。量子化学计算在生物、化学、医药和材料科学等领域中具有广泛应用,例如:预测化学反应的热化学性质、分析分子的光谱学特性、优化材料的物理性质等。然而,量子化学计算存在计算量大、成本昂贵、耗时长等缺点,这限制了其在科学研究和技术创新领域的进一步发展。
为了推动量子化学与基础科学研究的深度融合,我们需要积极探索计算成本更低、更高效的求解方法,为此发起了本届 《量子化学分子属性预测大赛》。本次大赛中,我们开源了国内首个采用高精度QM方法计算的分子构象数据集,其中包含了12万个分子和1000多万个构象。这些分子的构象包括了旋转、振动、弯曲等不同形式的构象,覆盖了多种不同的单分子性质,具有高精度、高可靠性和高实用性等特点,能够为参赛者提供准确、丰富和具有代表性的数据资源。
此外,我们还会提供详细的数据集说明和相关文献,帮助参赛者更好地理解和使用这个数据集,从而更好地完成赛题任务。我们相信这个数据集的开源将促进量子化学计算领域的进一步发展和应用,也将为更广泛的科学研究和工程实践提供更多的可能性和机会。
1.2 赛事任务
本届赛题为 图属性回归 问题,目标是预测不同构象下分子的 总能量和力 两种性质。数据集将包含一系列分子的构象和量子化学计算得到的能量、力等属性信息,参赛者需要从中选择合适的特征,并使用适当的算法来建立预测模型,快速准确的预测分子的属性。
1.3 赛题数据集
初赛提供训练集数据文件 ,其中包含约500w训练样本。
单个分子中各字段说明如下:

1.4 评价指标
初赛阶段,选手仅需要提交结果文件,只采用准确率进行评分。
复赛阶段,选手的评分将在准确率的基础上考虑同时计算效率。

2. 环境配置
在阿里云平台选择机器学习平台PAI(新用户可免费试用3个月),GPU选择30G的A10.
创建并打开实例后的页面:
然后用 Ossutil命令 完成赛题数据下载。
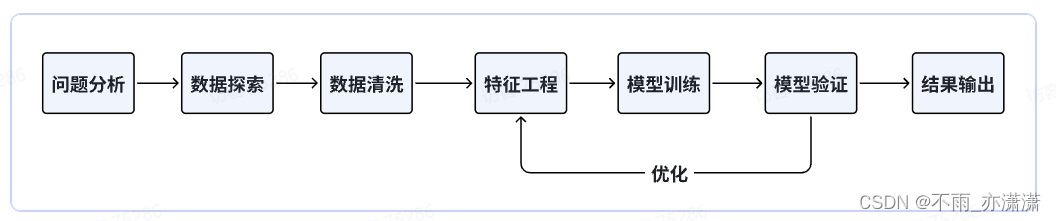
3. baseline
本题初赛任务是预测能量和力,属于回归问题,不过输入数据比较复杂,给出了原子之间的关系和坐标位置,可以构建空间结构。
模型方面可以选择机器学习模型或图神经网络模型,如果使用类似xgboost这类机器学习模型,无法深入挖掘图结构信息,仅能提取简单的图信息,如出度入读、边数量等。如果选择图神经网络模型,则能够有效挖掘图结构信息。
鉴于上面的对比,baseline选择使用机器学习方法。
3.1 导入模块
导入我们本次Baseline代码所需的模块
# 导入numpy库,用于进行数值计算
import numpy as np
# 导入pandas库,用于数据处理和分析
import pandas as pd
# 导入polars库,用于处理大规模数据集
import polars as pl
# 导入collections库中的defaultdict和Counter,用于统计
from collections import defaultdict, Counter
# 导入CatBoostRegressor库,用于梯度提升树模型
from catboost import CatBoostRegressor
# 导入StratifiedKFold、KFold和GroupKFold,用于交叉验证
from sklearn.model_selection import StratifiedKFold, KFold, GroupKFold
# 使用Joblib中的Parallel和delayed实现并行化处理
from joblib import Parallel, delayed
# 导入sys、os、gc、argparse和warnings库,用于处理命令行参数和警告信息
import sys, os, gc, argparse, warnings, tqdm
# 均绝对误差)是一个用于回归问题评估模型性能的指标之一,它衡量了预测值与实际观测值之间的平均绝对差异。
from sklearn.metrics import mean_absolute_error
# 忽略警告信息
warnings.filterwarnings('ignore')
3.2 加载数据
path = '..'
test0 = np.load(f'{
path}/QMB_round1_test_230725_0.npy', allow_pickle=True).tolist()
test1 = np.load(f'{
path}/QMB_round1_test_230725_1.npy', allow_pickle=True).tolist()
test = test0 + test1
del test0, test1
#一个训练集加载后大概20G,根据自己的算力情况选择性加载,baseline采用A10,30G内存的环境,只加载一个训练集
train0 = np.load(f'{
path}/QMB_round1_train_230725_0.npy', allow_pickle=True).tolist()
# train1 = np.load(f'{path}/QMB_round1_train_230725_1.npy', allow_pickle=True).tolist()
# train2 = np.load(f'{path}/QMB_round1_train_230725_2.npy', allow_pickle=True).tolist()
# train3 = np.load(f'{path}/QMB_round1_train_230725_3.npy', allow_pickle=True).tolist()
# train4 = np.load(f'{path}/QMB_round1_train_230725_4.npy', allow_pickle=True).tolist()
# train = train0 + train1 + train2 + train3 + train4
# del train0, train1, train2, train3, train4
train = train0
del train0
✏️ 赛题数据解压之后是 npy文件,是 numpy 专用的二进制文件,加载方式:
import numpy as np
data = np.load('data\\x.npy')
3.3 特征工程
特征工程指的是把原始数据转变为模型训练数据的过程,目的是获取更好的训练数据特征。特征工程能使得模型的性能得到提升,有时甚至在简单的模型上也能取得不错的效果。
对逐个样本进行特征提取,connectivity提取相连原子组成的列表的最长和最大统计、edge_list提取最大出度和入度、coordinates坐标位置的均值、最大值、最小值、elements的不同元素数、formal_charge最大值和最小值、edge_attr键类型占比数等。

为了加快运行速度,这里使用Joblib中的Parallel和delayed实现并行化处理,执行get_parallel_feature函数,代码如下:
注:n_jobs为开启的进程数,即是用n_jobs个CPU来计算。
import stats
def get_parallel_feature(data, IS_TRAIN=False):
# 相连原子组成的列表的最长和最大统计
max_len = len(max(data['connectivity'], key=len))
min_len = len(min(data['connectivity'], key=len))
# 提取最大出度和入度,以及边的数量
# max_out_degree = stats.mode(data['edge_list'][:,0])[1][0]
# max_in_degree = stats.mode(data['edge_list'][:,1])[1][0]
edge_list_len = len(data['edge_list'])
# 坐标位置的均值、最大值、最小值
coordinates = data['coordinates'].mean(axis=0).tolist() + \
data['coordinates'].max(axis=0).tolist() + \
data['coordinates'].min(axis=0).tolist()
# elements的不同元素数
elements_nunique = len(set(data['elements']))
elements = ' '.join([str(i) for i in data['elements']])
# formal_charge最大值和均值
formal_charge = [data['formal_charge'].max(), data['formal_charge'].mean()]
# edge_attr键类型占比数
edge_attr_1_ratio = len(np.where(np.array(data['edge_attr'])=='1')[0]) / edge_list_len
edge_attr_2_ratio = len(np.where(np.array(data['edge_attr'])=='2')[0]) / edge_list_len
edge_attr_3_ratio = len(np.where(np.array(data['edge_attr'])=='3')[0]) / edge_list_len
edge_attr_nunique = len(set(data['edge_attr']))
# 合并到一个list中
res = [data['mol_name'], data['atom_count'], data['bond_count'], max_len, min_len, edge_list_len] + \
coordinates + [elements_nunique, elements] + formal_charge + \
[edge_attr_1_ratio, edge_attr_2_ratio, edge_attr_3_ratio, edge_attr_nunique]
# 返回结果
if IS_TRAIN:
return res + [data['energy']]
else:
return res
### 测试数据
test_samples = Parallel(n_jobs=40)(
delayed(get_parallel_feature)(data, False)
for data in tqdm.tqdm(test)
)
test_df = pd.DataFrame(test_samples, columns=['mol_name','atom_count','bond_count','maxlen','maxin','edgelen',\
'mean1','mean2','mean3','max1','max2','max3','min1','min2','min3','elements_nunique','elements',\
'formal_charge_max','formal_charge_min','edge_attr_1_ratio','edge_attr_2_ratio','edge_attr_3_ratio',\
'edge_attr_nunique'])
### 训练数据
train_samples = Parallel(n_jobs=40)(
delayed(get_parallel_feature)(data, True)
for data in tqdm.tqdm(train)
)
train_df = pd.DataFrame(train_samples, columns=['mol_name','atom_count','bond_count','maxlen','minlen','edgelen',\
'mean1','mean2','mean3','max1','max2','max3','min1','min2','min3','elements_nunique','elements',\
'formal_charge_max','formal_charge_min','edge_attr_1_ratio','edge_attr_2_ratio','edge_attr_3_ratio',\
'edge_attr_nunique','energy'])
构建TfidfVectorizer和CountVectorizer特征,提取elements中的相关信息,代码如下:
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
def tfidf(data, seqs):
tfidf = TfidfVectorizer(max_df = 0.95, min_df = 3)
res = tfidf.fit_transform(data[seqs])
res = res.toarray()
for i in range(len(res[0])):
data['{}_tfidf_{}'.format(seqs,str(i))] = res[:,i]
gc.collect()
return data
def CVec(data, seqs):
tfidf = CountVectorizer(max_df = 0.95, min_df = 3)
res = tfidf.fit_transform(data[seqs])
res = res.toarray()
for i in range(len(res[0])):
data['{}_cv_{}'.format(seqs,str(i))] = res[:,i]
gc.collect()
return data
### 合并训练数据和测试数据
test_df['istest'] = 1
train_df['istest'] = 0
df = pd.concat([test_df, train_df], axis=0, ignore_index=True)
### 进行Tfidf 和 Count
df = tfidf(df, 'elements')
df = CVec(df, 'elements')
### 切分训练数据和测试数据
test_df = df[df.istest==1].reset_index(drop=True)
train_df = df[df.istest==0].reset_index(drop=True)
✏️ CountVectorizer类:
将文本中的词语转换为词频矩阵。也就是通过分词后将所有的文档中的全部词作为一个字典(就是类似于新华字典这种)。然后将每一行的词用0,1矩阵来表示。并且每一行的长度相同,长度为字典的长度,在词典中存在,置为1,否则,为0。
参数:
input: 一般使用默认即可,可以设置为"filename’或’file’;
encodeing: 使用默认的utf-8即可,分析器将会以utf-8解码raw document;
decode_error: 默认为strict,遇到不能解码的字符将报UnicodeDecodeError错误,设为ignore将会忽略解码错误,还可以设为replace,作用尚不明确;
strip_accents: 默认为None,可设为ascii或unicode,将使用ascii或unicode编码在预处理步骤去除raw document中的重音符号;
analyzer: 一般使用默认,可设置为string类型,如’word’, ‘char’, ‘char_wb’,还可设置为callable类型,比如函数是一个callable类型;
preprocessor: 设为None或callable类型;
tokenizer: 设为None或callable类型;
ngram_range: 词组切分的长度范围;
stop_words: 设置停用词,设为english将使用内置的英语停用词,设为一个list可自定义停用词,设为None不使用停用词,设为None且max_df∈[0.7, 1.0)将自动根据当前的语料库建立停用词表;
lowercase: 将所有字符变成小写;
token_pattern: 表示token的正则表达式,需要设置analyzer == ‘word’,默认的正则表达式选择2个及以上的字母或数字作为token,标点符号默认当作token分隔符,而不会被当作token;
max_df: 可以设置为范围在[0.0 1.0]的float,也可以设置为没有范围限制的int,默认为1.0。这个参数的作用是作为一个阈值,当构造语料库的关键词集的时候,如果某个词的document frequence大于max_df,这个词不会被当作关键词。如果这个参数是float,则表示词出现的次数与语料库文档数的百分比,如果是int,则表示词出现的次数。如果参数中已经给定了vocabulary,则这个参数无效;
min_df: 类似于max_df,不同之处在于如果某个词的document frequence小于min_df,则这个词不会被当作关键词;
max_features: 默认为None,可设为int,对所有关键词的term frequency进行降序排序,只取前max_features个作为关键词集;
vocabulary: 默认为None,自动从输入文档中构建关键词集,也可以是一个字典或可迭代对象;
binary: 默认为False,一个关键词在一篇文档中可能出现n次,如果binary=True,非零的n将全部置为1,这对需要布尔值输入的离散概率模型的有用的;
dtype: 使用CountVectorizer类的fit_transform()或transform()将得到一个文档词频矩阵,dtype可以设置这个矩阵的数值类型。
TfidfVectorizer类:
与CountVectorizer有很多相同的参数,下面只解释不同的参数:
binary: 默认为False,tf-idf中每个词的权值是tfidf,如果binary设为True,所有出现的词的tf将置为1,TfidfVectorizer计算得到的tf与CountVectorizer得到的tf是一样的,就是词频,不是词频/该词所在文档的总词数;
norm: 默认为’l2’,可设为’l1’或None,计算得到tf-idf值后,如果norm=‘l2’,则整行权值将归一化,即整行权值向量为单位向量,如果norm=None,则不会进行归一化。大多数情况下,使用归一化是有必要的;
use_idf: 默认为True,权值是tfidf,如果设为False,将不使用idf,就是只使用tf,相当于CountVectorizer了;
smooth_idf: idf平滑参数,默认为True,idf=ln((文档总数+1)/(包含该词的文档数+1))+1,如果设为False,idf=ln(文档总数/包含该词的文档数)+1;
sublinear_tf: 默认为False,如果设为True,则替换tf为1 + log(tf)。
CountVectorizer类和TfidfVectorizer类
3.4 模型训练与验证
特征工程也好,数据清洗也罢,都是为最终的模型来服务的,模型的建立和调参决定了最终的结果。模型的选择决定结果的上限, 如何更好的去达到模型上限取决于模型的调参。
建模的过程需要我们对常见的线性模型、非线性模型有基础的了解。模型构建完成后,需要掌握一定的模型性能验证的方法和技巧。
作为baseline方案使用 catboost 模型,并选择经典的K折交叉验证方法进行离线评估,大体流程如下:
1、K折交叉验证会把样本数据随机的分成K份;
2、每次随机的选择K-1份作为训练集,剩下的1份做验证集;
3、当这一轮完成后,重新随机选择K-1份来训练数据;
4、最后将K折预测结果取平均作为最终提交结果。

具体代码如下:
def catboost_model(train_x, train_y, test_x, seed = 2023):
folds = 5
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
oof = np.zeros(train_x.shape[0])
test_predict = np.zeros(test_x.shape[0])
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ {} ************************************'.format(str(i+1)))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
params = {
'learning_rate': 0.1,
'depth': 6,
'bootstrap_type':'Bernoulli',
'random_seed':2023,
'od_type': 'Iter',
'od_wait': 200,
'random_seed': 11,
'allow_writing_files': False,
'task_type':"GPU", # 任务类型,表示模型运行在GPU还是CPU上。设置为"GPU"表示模型运行在GPU上,如果计算机没有GPU,可以设置为"CPU"。
'devices':'0:1'}
#iterations是迭代次数,可以根据自己的算力配置与精力调整
model = CatBoostRegressor(iterations=10000, **params)
model.fit(trn_x, trn_y, eval_set=(val_x, val_y),
metric_period=500,
use_best_model=True,
cat_features=[],
verbose=1)
val_pred = model.predict(val_x)
test_pred = model.predict(test_x)
oof[valid_index] = val_pred
test_predict += test_pred / kf.n_splits
score = mean_absolute_error(val_y, val_pred)
cv_scores.append(score)
print(cv_scores)
# 获取特征重要性打分,便于评估特征
if i == 0:
fea_ = model.feature_importances_
fea_name = model.feature_names_
fea_score = pd.DataFrame({
'fea_name':fea_name, 'score':fea_})
fea_score = fea_score.sort_values('score', ascending=False)
fea_score.to_csv('feature_importances.csv', index=False)
return oof, test_predict
cols = [f for f in test_df.columns if f not in ['elements','energy','mol_name','elements','istest']]
cat_oof, cat_test = catboost_model(train_df[cols], train_df['energy'], test_df[cols])
生成 feature_importances.csv 文件
特征重要性结果展示:
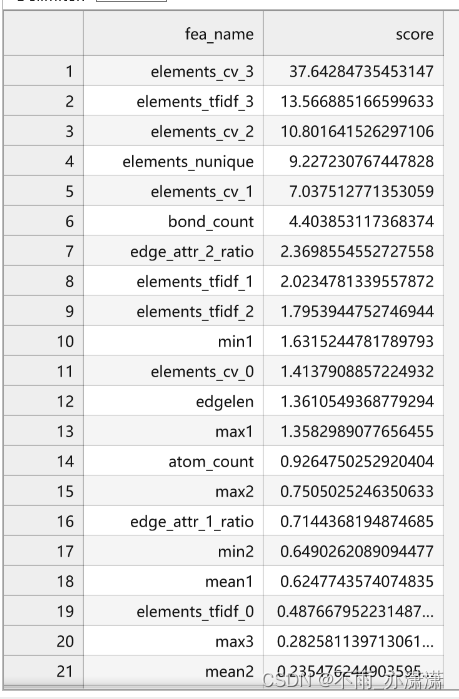
观察特征重要性排序,我们手动构建的elements相关特征重要性排在前面,这也大概率说明这类特征可能有比较大的作用。
3.5 结果输出
提交需要符合提交样例结果,线上提交分数20000+,能优化的空间还是非常大的。特别注意因为force的真实结果非常低,所影响的误差也比较少,所以统一用0作为预测结果。
# 输出赛题提交格式的结果
test_df['energy'] = cat_test
test_df['force'] = test_df['atom_count'].apply(lambda x: ','.join(['0.0' for _ in range(x*3)]))
test_df[['energy','force']].to_csv("submission.csv", index=True)
4. 我的代码
把 CatBoost 模型换成 LightGBM 模型
LightGBM 模型用法参考:
LightGBM回归预测模型构建 - 含GBM调参方法
lightgbm回归模型使用方法(lgbm.LGBMRegressor)
机器学习:lightgbm(实战:分类&&回归)
LightGBM 简单实现
4.1 安装 lightgbm
# !pip install lightgbm
import lightgbm as lgb
4.2 导入模块
# 导入numpy库,用于进行数值计算
import numpy as np
# 导入pandas库,用于数据处理和分析
import pandas as pd
# 导入polars库,用于处理大规模数据集
import polars as pl
# 导入collections库中的defaultdict和Counter,用于统计
from collections import defaultdict, Counter
# 导入LGBMRegressor
from lightgbm import LGBMRegressor
# 导入StratifiedKFold、KFold和GroupKFold,用于交叉验证
from sklearn.model_selection import StratifiedKFold, KFold, GroupKFold
# 使用Joblib中的Parallel和delayed实现并行化处理
from joblib import Parallel, delayed
# 导入sys、os、gc、argparse和warnings库,用于处理命令行参数和警告信息
import sys, os, gc, argparse, warnings, tqdm
# 均绝对误差)是一个用于回归问题评估模型性能的指标之一,它衡量了预测值与实际观测值之间的平均绝对差异。
from sklearn.metrics import mean_absolute_error
# 忽略警告信息
warnings.filterwarnings('ignore')
4.3 加载数据
path = 'data'
test0 = np.load(f'{
path}/QMB_round1_test_230725_0.npy', allow_pickle=True).tolist()
test1 = np.load(f'{
path}/QMB_round1_test_230725_1.npy', allow_pickle=True).tolist()
test = test0 + test1
del test0, test1
#一个训练集加载后大概20G,根据自己的算力情况选择性加载,baseline采用A10,30G内存的环境,只加载一个训练集
train0 = np.load(f'{
path}/QMB_round1_train_230725_0.npy', allow_pickle=True).tolist()
# train1 = np.load(f'{path}/QMB_round1_train_230725_1.npy', allow_pickle=True).tolist()
# train2 = np.load(f'{path}/QMB_round1_train_230725_2.npy', allow_pickle=True).tolist()
# train3 = np.load(f'{path}/QMB_round1_train_230725_3.npy', allow_pickle=True).tolist()
# train4 = np.load(f'{path}/QMB_round1_train_230725_4.npy', allow_pickle=True).tolist()
# train = train0 + train1 + train2 + train3 + train4
# del train0, train1, train2, train3, train4
train = train0
del train0
4.4 特征工程
import stats
def get_parallel_feature(data, IS_TRAIN=False):
# 相连原子组成的列表的最长和最大统计
max_len = len(max(data['connectivity'], key=len))
min_len = len(min(data['connectivity'], key=len))
# 提取最大出度和入度,以及边的数量
# max_out_degree = stats.mode(data['edge_list'][:,0])[1][0]
# max_in_degree = stats.mode(data['edge_list'][:,1])[1][0]
edge_list_len = len(data['edge_list'])
# 坐标位置的均值、最大值、最小值
coordinates = data['coordinates'].mean(axis=0).tolist() + \
data['coordinates'].max(axis=0).tolist() + \
data['coordinates'].min(axis=0).tolist()
# elements的不同元素数
elements_nunique = len(set(data['elements']))
elements = ' '.join([str(i) for i in data['elements']])
# formal_charge最大值和最小值
formal_charge = [data['formal_charge'].max(), data['formal_charge'].mean()]
# edge_attr键类型占比数
edge_attr_1_ratio = len(np.where(np.array(data['edge_attr'])=='1')[0]) / edge_list_len
edge_attr_2_ratio = len(np.where(np.array(data['edge_attr'])=='2')[0]) / edge_list_len
edge_attr_3_ratio = len(np.where(np.array(data['edge_attr'])=='3')[0]) / edge_list_len
edge_attr_nunique = len(set(data['edge_attr']))
# 合并到一个list中
res = [data['mol_name'], data['atom_count'], data['bond_count'], max_len, min_len, edge_list_len] + \
coordinates + [elements_nunique, elements] + formal_charge + \
[edge_attr_1_ratio, edge_attr_2_ratio, edge_attr_3_ratio, edge_attr_nunique]
# 返回结果
if IS_TRAIN:
return res + [data['energy']]
else:
return res
### 测试数据
test_samples = Parallel(n_jobs=40)(
delayed(get_parallel_feature)(data, False)
for data in tqdm.tqdm(test)
)
test_df = pd.DataFrame(test_samples, columns=['mol_name','atom_count','bond_count','maxlen','maxin','edgelen',\
'mean1','mean2','mean3','max1','max2','max3','min1','min2','min3','elements_nunique','elements',\
'formal_charge_max','formal_charge_min','edge_attr_1_ratio','edge_attr_2_ratio','edge_attr_3_ratio',\
'edge_attr_nunique'])
### 训练数据
train_samples = Parallel(n_jobs=40)(
delayed(get_parallel_feature)(data, True)
for data in tqdm.tqdm(train)
)
train_df = pd.DataFrame(train_samples, columns=['mol_name','atom_count','bond_count','maxlen','minlen','edgelen',\
'mean1','mean2','mean3','max1','max2','max3','min1','min2','min3','elements_nunique','elements',\
'formal_charge_max','formal_charge_min','edge_attr_1_ratio','edge_attr_2_ratio','edge_attr_3_ratio',\
'edge_attr_nunique','energy'])
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
def tfidf(data, seqs):
tfidf = TfidfVectorizer(max_df = 0.95, min_df = 4)
res = tfidf.fit_transform(data[seqs])
res = res.toarray()
for i in range(len(res[0])):
data['{}_tfidf_{}'.format(seqs,str(i))] = res[:,i]
gc.collect()
return data
def CVec(data, seqs):
tfidf = CountVectorizer(max_df = 0.95, min_df = 4)
res = tfidf.fit_transform(data[seqs])
res = res.toarray()
for i in range(len(res[0])):
data['{}_cv_{}'.format(seqs,str(i))] = res[:,i]
gc.collect()
return data
### 合并训练数据和测试数据
test_df['istest'] = 1
train_df['istest'] = 0
df = pd.concat([test_df, train_df], axis=0, ignore_index=True)
### 进行Tfidf 和 Count
df = tfidf(df, 'elements')
df = CVec(df, 'elements')
### 切分训练数据和测试数据
test_df = df[df.istest==1].reset_index(drop=True)
train_df = df[df.istest==0].reset_index(drop=True)
4.5 模型训练与验证
# LGBMRegressor: 调用Scikit-learn接口的回归
def lgb_model(train_x, train_y, test_x, seed = 2023):
folds = 5
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
oof = np.zeros(train_x.shape[0])
test_predict = np.zeros(test_x.shape[0])
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ {} ************************************'.format(str(i+1)))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
model = lgb.LGBMRegressor(objective='regression',
num_leaves=500,
learning_rate=0.01,
n_estimators=600)
model.fit(trn_x, trn_y, eval_set=(val_x, val_y))
val_pred = model.predict(val_x)
test_pred = model.predict(test_x)
oof[valid_index] = val_pred
test_predict += test_pred / kf.n_splits
score = mean_absolute_error(val_y, val_pred)
cv_scores.append(score)
print(cv_scores)
return oof, test_predict
cols = [f for f in test_df.columns if f not in ['elements','energy','mol_name','elements','istest']]
cat_oof, cat_test = lgb_model(train_df[cols], train_df['energy'], test_df[cols])
4.6 结果输出
# 输出赛题提交格式的结果
test_df['energy'] = cat_test
test_df['force'] = test_df['atom_count'].apply(lambda x: ','.join(['0.0' for _ in range(x*3)]))
test_df[['energy','force']].to_csv("submission4.csv", index=True)
5. 运行结果

照着 baseline 跑一遍,分数:20773.6846
微调了一下参数(learning_rate调小,depth调大),把 train0 换成 train1 ,之后分数:21879.9301
后面把 CatBoost 模型换成 LightGBM 模型,分数:21249.8966
迭代次数加大之后,分数:21745.3668
还有很大的优化空间。