首先,这是对上一篇文章(pytorch:一维线性回归(一))的改进。
其次,为什么想要改进上一篇文章嘞?
答案:我使用这个写好的模型后,想着既然参数已经训练出来了,那么预测的时候,就只需要直接根据参数和输入数据就可以计算出预测值,速度应该很快。
然而,按照上一篇文章这样的写法,仔细的人会发现,每次预测的时候都又进行了训练,那么之前我的训练就等于白费了。
于是,我得找原因在哪里,不难发现,我虽然训练了模型,但是没有对参数进行保存。
于是我查询了pytorch是如何保存模型参数的,一共有两种方式:保存整个模型和保存模型参数。
根据需求,保存整个模型显然是不合理的,因为我的核心是想要得到模型的参数,y=wx+b,参数就是w和b,也就是代码中的weight和bias
因为参数固定,那么模型就确定了,输入x,就能输出预测值。
思路有了,于是开始实践:
1、构建模型。把模型单独设置为一个类,名字不要乱取,最好见名知意,方便下次直接使用,模型的名字是LinearRegression,那么类的名字就是LinearRegression,整个文件名字是:LinearRegression.py
# -*- coding: utf-8 -*-
from torch import nn as nn
# 构建线性模型
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
# 输入和输出的维度都是1
self.linear = nn.Linear(1, 1)
def forward(self, x):
out = self.linear(x)
return out
2、训练模型。新建一个train.py
# -*- coding: utf-8 -*-
import torch
import numpy as np
from torch import nn, optim
from torch.autograd import Variable
# 引入模型
from LinearRegression import LinearRegression # 步骤1中构建的模型
# 训练数据
x_train = np.array([[3.3], [4.4], [5.5], [6.71], [6.93], [4.168],
[9.779], [6.182], [7.59], [2.167], [7.042],
[10.791], [5.313], [7.997], [3.1]], dtype=np.float32)
y_train = np.array([[1.7], [2.76], [2.09], [3.19], [1.694], [1.573],
[3.366], [2.596], [2.53], [1.221], [2.827],
[3.465], [1.65], [2.904], [1.3]], dtype=np.float32)
# 把训练数据转换为张量:numpy->torch,
x_train = torch.from_numpy(x_train)
y_train = torch.from_numpy(y_train)
# 判断是否有可用的GPU
if torch.cuda.is_available():
model = LinearRegression().cuda()
else:
model = LinearRegression()
# 损失函数:均方误差(计算损失的方法是什么,衡量误差的标准是什么)
criterion = nn.MSELoss()
# 采用随机梯度下降
optimizer = optim.SGD(model.parameters(), lr=1e-3)
num_epochs = 1000 # 训练总次数
for epoch in range(num_epochs):
if torch.cuda.is_available():
inputs = Variable(x_train).cuda()
target = Variable(y_train).cuda()
else:
inputs = Variable(x_train)
target = Variable(y_train)
# 向前传播
out = model(inputs)
loss = criterion(out, target)
# 向后传播
optimizer.zero_grad() # 梯度清零
loss.backward() # 向后传播
optimizer.step() # 更新参数
if (epoch + 1) % 20 == 0:
print('Epoch[{}/{}], loss:{:.6f}'.format(epoch + 1, num_epochs, loss.item()))
# 训练结束后,打印出w和b的值
print('w:', model.state_dict()['linear.weight'].numpy().squeeze())
print('b:', model.state_dict()['linear.bias'].numpy().squeeze())
# 保存模型的参数,也就是w和b的值
torch.save(model.state_dict(), "LinearRegression_train.pt")
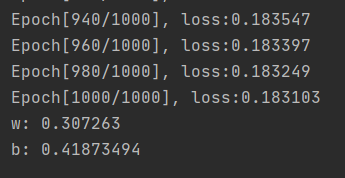
训练结束后可以看到参数值,我运行的时候运行结果:
3、预测。使用模型来预测值,这里我批量预测3个值。文件名可以随意取名了,因为模型参数已经保存在
LinearRegression_train.pt中,测试可以将文件名设置为test.py或者predict.py均可。
# -*- coding: utf-8 -*-
import torch
import numpy as np
from torch.autograd import Variable
from LinearRegression import LinearRegression
# 等待预测的数据
x_train = np.array([[1.0], [2.0], [3.0]], dtype=np.float32)
# 实例化模型
model = LinearRegression()
# 加载模型参数
model.load_state_dict(torch.load("LinearRegression_train.pt"))
# 根据用CPU还是GPU来计算,将预测结果显示出来
if torch.cuda.is_available():
predict = model(Variable(torch.from_numpy(x_train)).cuda())
predict = predict.data.cpu().numpy()
print(predict)
else:
predict = model(Variable(torch.from_numpy(x_train)))
predict = predict.data.numpy()
print("=======")
print(predict)运行结果:

从结果可以看出,电脑是使用的CPU计算的,因为打印出了等号。
其次,还需要手动计算一下,是否符合我们心中所想。
根据步骤2,参数w=0.307263 b=0.41873494
根据公式:y = w*x+b
则y1 = 0.307263*1.0+0.41873494 =0.72599794

y1 = 0.307263*2.0+0.41873494 = 1.03326094

y1 = 0.307263*3.0+0.41873494 = 1.34052394

将y1、y2、y3与程序运行结果对比,大致符合,因为计算机存在小数位数多的时候计算不精确,所以小数点后距离较远的数据存在差异。
总结:改进后的好处:模型训练好后,用于预测不需要再进行重新训练,节约了时间,训练模型的目的就是为了使用模型进行预测,如果预测时还需要耗时去重新训练模型,尤其是将模型用于B/S系统展示,前端用户会等待很长时间,用户体验极其不佳。虽然将一个文件拆分为了三个文件,但是思路更加清晰了!