一、自编码器
自编码器是一种特殊的神经网络,它包括三层。经过训练的自编码器可以计算出输入的表示,从而尽可能准确地重构原始数据,如下图所示。最近,自编码器被用于深度架构中,作为一种无监督学习算法。

接下来我们用神经网络的形式把自编码器画出来。其实这个算法非常简单,就是通过特征的学习,使得输入input和输出output尽可能相同,然后我们就可以利用中间层的feature进行下一步的学习。这种做法一方面可以压缩输入向量的维度,另一方面可以对输入信号进行降噪。

二、堆叠变分自编码器
2.1 预训练过程
贪婪逐层方法在预训练过程中分别对每一层的参数进行训练,同时冻结模型其余部分的参数。每次只训练网络中的一层,即我们首先训练一个只含一个隐藏层的网络,仅当这层网络训练结束之后才开始训练一个有两个隐藏层的网络,以此类推。光说可能看不懂,下面我们直接上图!

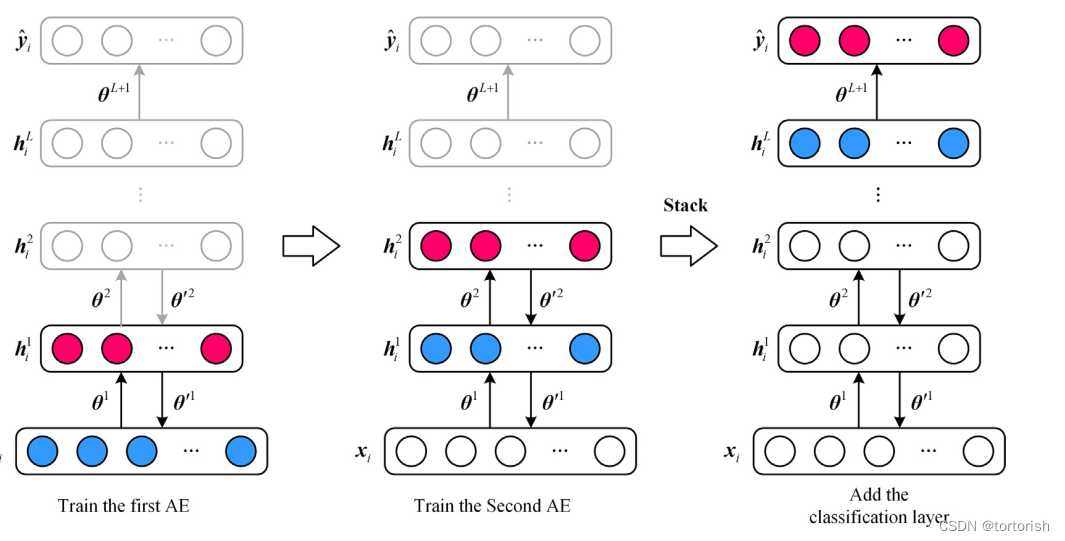
即第一步训练所得的隐含层Features1,是第二步训练的输入,接着再训练出Features2。同样的操作还可以继续进行很多次,不断的训练隐含层。 在每一步中,我们把已经训练好的前k-1层固定,然后增加第k层(也就是将我们已经训练好的前k-1的输出作为输入)。每一层的训练通常使用无监督方法(即自动编码器)。
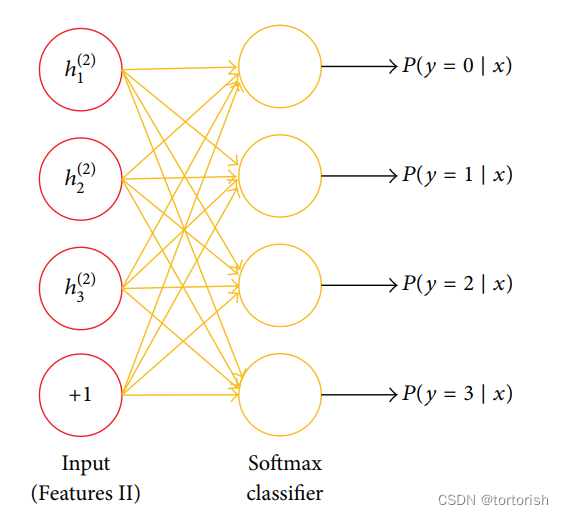
那么训练所得的隐含层如何用于分类任务呢?只要在第二步训练所得的Feature2后加一个softmax层就可以了!注意,softmax层的预训练权重是通过有监督学习获得的,而前面的Features层是通过无监督学习得到的。
这边我找了另外一张图来帮助读者理解,堆叠自编码器的具体训练过程如下图所示:
2.2 微调过程

为了产生更好的结果,在预训练阶段完成后,可以使用反向传播进行微调,通过同时调整所有层的参数来改善结果。
对网络权重进行微调会在测试数据上产生更好的分类性能。它将堆叠自编码器的所有层视为一个单一模型,这样在一次迭代中,我们可以使用反向传播算法来改善堆叠自编码器中的所有权重。
三、参考文献
[1]Lei Y ,Yang B ,Jiang X , et al. Applications of machine learning to machine fault diagnosis: A review and roadmap[J]. Mechanical Systems and Signal Processing,2020,138.
[2]Hongmei L ,Lianfeng L ,Jian M . Rolling Bearing Fault Diagnosis Based on STFT-Deep Learning and Sound Signals[J]. Shock and Vibration,2016,2016(Pt.6).