- 研究背景与方案
1.1.研究背景
在大数据时代背景下,各行业数据的规模大幅度增加,数据类别日益复杂,给数据分析工作带来极大挑战。气象行业和人们的生活息息相关,随着信息时代的发展,大数据技术的出现为气象数据的发展带来机遇。基于此,本项目使用Spark等大数据处理工具,采用机器学习、深度学习等多种数据分析方法,并借助可视化手段将多种类型数据与复杂数据进行解读与概括,探究大数据技术在气象数据中的应用,给受众传递更有价值的信息,进而有助于提升社会整体生产效率,推动市场经济的有效发展。
1.2.研究方案
一、选用合适的数据集。历史天气数据可以通过爬取气象网站获得,这种方法的优点在于可以灵活选择自己想要的数据,缺点在于耗时较长、可能遇到反爬机制,此外气象网站的天气数据往往特征维数不高,不适于机器学习、深度学习等任务。因此决定使用爬取的数据进行基于Spark的数据分析及可视化,选用数据竞赛网站Kaggle的更大更高维的数据进行基于学习的任务。
二、工具与环境配置。由于虚拟机受限于硬件,难以完成较大规模数据的分析任务,于是决定在本地Windows操作系统下部署相关大数据环境(Hadoop、Spark、深度学习框架等)。
三、选用合适的学习算法。不同类型的数据适合于不同的学习算法,天气数据的特点是存在趋势、周期性、节令性等规律,而由于循环神经网络RNN具有记忆能力,因此它对于处理时间序列数据非常有效。在训练过程中,网络会根据历史数据动态地更新权重,从而使得网络能够适应不同的数据分布和趋势。同时,RNN通过考虑前后时刻之间的依赖性,使得更容易捕获上述数据的特征,并可以自适应地更新模型以处理噪声和异常值的影响。因此选用RNN及其改进(LSTM等)完成深度学习任务。
2.数据集介绍
2.1爬取中央气象台网站天气数据
2.1.1.实验数据介绍
本次实验所采用的数据从中央气象台官方网站(关注阴晴冷暖,气象一直为你)爬取,主要是最近24小时各个城市的天气数据,包括时间点(整点)、整点气温、整点降水量、风力、整点气压、相对湿度等,总数据量达到58368条。正常情况下,每个城市会对应24条数据(每个整点一条)。有部分城市部分时间点数据存在缺失或异常。
2.1.2.数据获取
2.1.2.1.观察数据获取方式
打开中央气象台官方网站,任意点击“热点城市”中的一个城市。打开浏览器的Web控制台。通过切换“省份”和“城市”,我们可以发现网页中的数据是以json字符串格式异步地从服务器传送。可以发现以下数据和请求URL的关系:
表1 数据和请求URL的关系
|
由于省份三位编码(如福建省编码为ABJ)需要从省份数据获得中获得,城市编号需要从城市数据获得(如福州市编号为58847),所以为了获得各个城市最近24小时整点天气数据,依次爬取省份数据、城市数据、最近24小时整点数据。
2.1.2.2.数据爬取
由于可以直接通过访问请求URL,传回的响应的数据部分即是json格式的数据,所以只需要调用python的urllib2库中相关函数,对上述URL进行请求即可。不需要像平常爬取HTML网页时还需要对网页源码进行解析,查找相关数据。唯一需要注意的是,有些城市可能不存在或者全部缺失最近24小时整点数据,需要进行过滤,以免出错。
2.1.2.3数据存储
虽然上一步获取的json数据可以直接存储并可使用SparkSession直接读取,但是为了方便观察数据结构、辨识异常数据、对数据增加部分提示信息,爬取后的数据进行了一些处理之后,保存成了csv格式,包括省份数据(province.csv)、城市数据(city.csv)、各个城市最近24小时整点天气数据(passed_weather_ALL.csv)。由于所有城市过去24小时整点天气数据数量太多,为了避免内存不足,每爬取50个城市的数据后,就会进行一次保存。
3.实验环境搭建
3.1.Windows安装Hadoop
3.1.1.Hadoop简介
Apache Hadoop是一款支持数据密集型分布式应用程序并以Apache 2.0许可协议发布的开源软件框架,有助于使用许多计算机组成的网络来解决数据、计算密集型的问题。基于MapReduce计算模型,它为大数据的分布式存储与处理提供了一个软件框架。所有的Hadoop模块都有一个基本假设,即硬件故障是常见情况,应该由框架自动处理。
Apache Hadoop的核心模块分为存储和计算模块,前者被称为Hadoop分布式文件系统(HDFS),后者即MapReduce计算模型。Hadoop框架先将文件分成数据块并分布式地存储在集群的计算节点中,接着将负责计算任务的代码传送给各节点,让其能够并行地处理数据。这种方法有效利用了数据局部性,令各节点分别处理其能够访问的数据。与传统的超级计算机架构相比,这使得数据集的处理速度更快、效率更高。
3.1.2.安装Java开发环境
打开cmd窗口并输入java -version,若能成功显示Java JDK的版本号则代表java环境已安装成功,否则需要安装Java JDK。
3.1.3.下载安装Hadoop所需要的文件
Hadoop3.1.1版本的安装包:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.1/hadoop-3.1.0.tar.gz。Windows环境安装所需的bin:https://github.com/s911415/apache-hadoop-3.1.1-winutils。Hadoop是在Linux下编写的,winutil主要用于模拟Linux下的目录环境。所以Hadoop放在Windows下运行的时候,需要这个辅助程序才能运行。
3.1.4.替换原安装包的bin目录
hadoop-3.1.1解压后文件夹的路径为D:\hadoop-3.1.1。apache-hadoop-3.1.1-winutils-master这个文件夹解压后里面只有bin这一个文件夹,我们将这个bin文件夹复制到hadoop-3.1.1文件夹中替换原有的bin文件夹。
3.1.5.配置Hadoop环境变量
新建系统变量,变量名填HADOOP_HOME,变量值填hadoop-3.1.1对应的路径(比如我的是D:\hadoop-3.1.1。顺便可以检查JAVA_HOME有没有配置好,后面会用到)。然后点击Path变量进行编辑,在最前面加上%HADOOP_HOME%\bin。
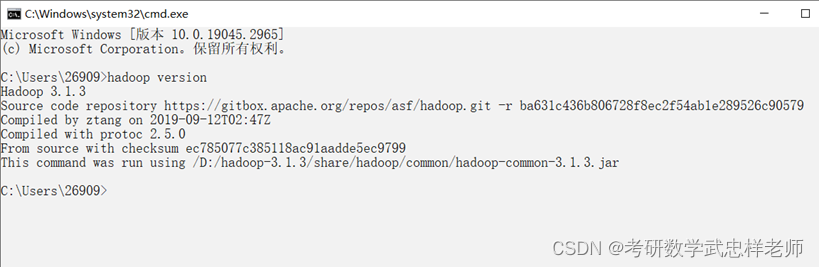
3.1.6.检查环境变量是否配置成功
配置好环境变量后,win+R 输入cmd打开命令提示符,然后输入hadoop version,按回车,如果出现如图所示版本号,则说明安装成功。
3.1.7.配置Hadoop的配置文件
3.1.7.1.配置core-site.xml文件
代码 2 配置core-site.xml文件
| <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:900</value> </property> </configuration> |
3.1.7.2.配置mapred-site.xml文件
代码 3 配置mapred-site.xml文件
| <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> |
3.1.7.3.配置yarn-site.xml文件
代码 4 配置yarn-site.xml文件
| <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration> |
3.1.7.4.配置hdfs-site.xml文件
在D:\hadoop-3.1.1创建data文件夹(也可以是别的名字,但后面配置要对应修改),在data2020文件夹中(D:\hadoop-3.1.1\data)创建datanode和namenode文件夹。之后打开hdfs-site.xml文件:
代码 5 配置hdfs-site.xml文件
| <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>D:\hadoop-3.1.1\data\namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>D:\hadoop-3.1.1\data\datanode</value> </property> </configuration> |
3.1.7.5.配置hadoop-env.sh文件
打开hadoop-env.sh,使用查找功能(Ctrl+F)查找export JAVA_HOME,找到相应的位置,在#export JAVA_HOME=下面一行配置自己电脑上对应的JAVA_HOME/bin路径(JAVA_HOME的具体路径在环境变量中查找到)。
3.1.7.6.配置hadoop-env.cmd文件
打开hadoop-env.cmd文件后使用查找功能(Ctrl+F),输入@rem The java implementation to use查找到对应行,在set JAVA_HOME那一行将自己的JAVA_HOME路径配置上去。
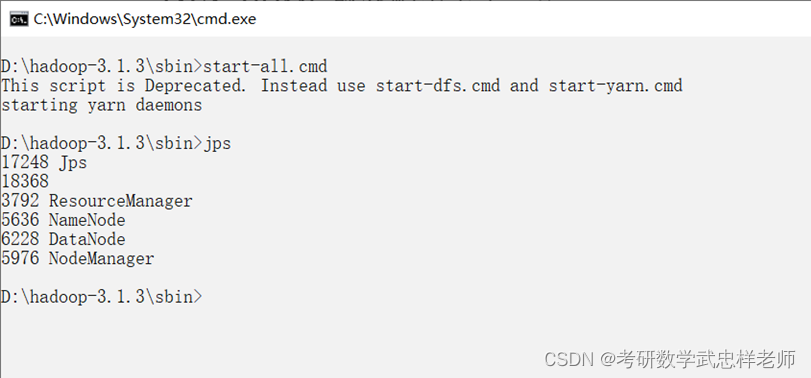
3.1.8.启动Hadoop服务
使用管理员模式进入sbin目录,输入start-all.cmd启动Hadoop服务:
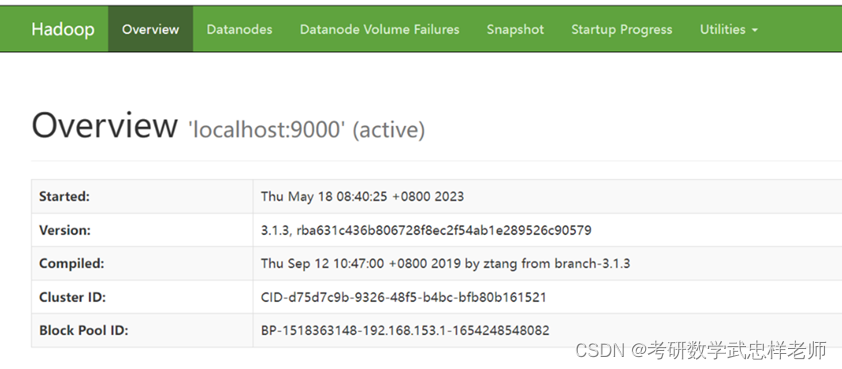
接着在浏览器中访问http://localhost:9870,如果成功出现以下界面则代表Hadoop安装和配置完成:
3.2.Windows安装Spark
3.2.1.Spark简介
Spark最初由美国加州伯克利大学的AMP 实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。 Spark于2013年加入Apache孵化器项目后发展迅猛,如今已成为Apache软件基金会最重要的三大分布式计算系统开源项目之一(Hadoop、Spark、Storm)。值得一提的是,Spark在2014年打破了Hadoop保持的基准排序记录。Spark使用206个节点,用时23分钟完成了100TB数据的排序,而Hadoop使用了2000个节点,耗时72分钟,完成了100TB数据的排序。也就是说Spark用十分之一的计算资源,获得了比Hadoop快3倍的速度。
Spark具有如下几个主要特点:运行速度快:使用DAG执行引擎以支持循环数据流与内存计算;容易使用:支持使用Scala、Java、Python和R语言进行编程,可以通过 Spark Shell进行交互式编程;通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件;运行模式多样:可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase和Hive等多种数据源。
传统大数据处理框架Hadoop存在如下一些缺点:表达能力有限;磁盘IO开销大;延迟高;任务之间的衔接涉及IO开销;在前一个任务执行完成之前,其他任务就无法开始,难以胜任复杂、多阶段的计算任务。Spark在借鉴Hadoop MapReduce优点的同时,很好地解决了MapReduce所面临的问题。相比于Hadoop MapReduce,Spark主要具有如下优点:Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比Hadoop MapReduce更灵活;Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高;Spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制。

Spark的运行架构包括集群管理器(Cluster Manager)、运行作业任务的工作节点(Worker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体任务的执行进程(Executor)。其中,集群管理器可以是Spark自带的资源管理器,也可以是YARN或Mesos等资源管理框架。与Hadoop MapReduce计算框架相比,Spark所采用的Executor有两个优点。一是利用多线程来执行具体的任务(HadoopMapReduce采用的是进程模型),减少任务的启动开销。二是 Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,当需要多轮迭代计算时,可以将中间结果存储到这个存储模块里,下次需要时就可以直接读该存储模块里的数据,而不需要读写到 HDFS 等文件系统里,因而有效减少了 IO 开销;或者在交互式查询场景下,Executor预先将表缓存到该存储系统上,从而可以提高读写IO的性能。
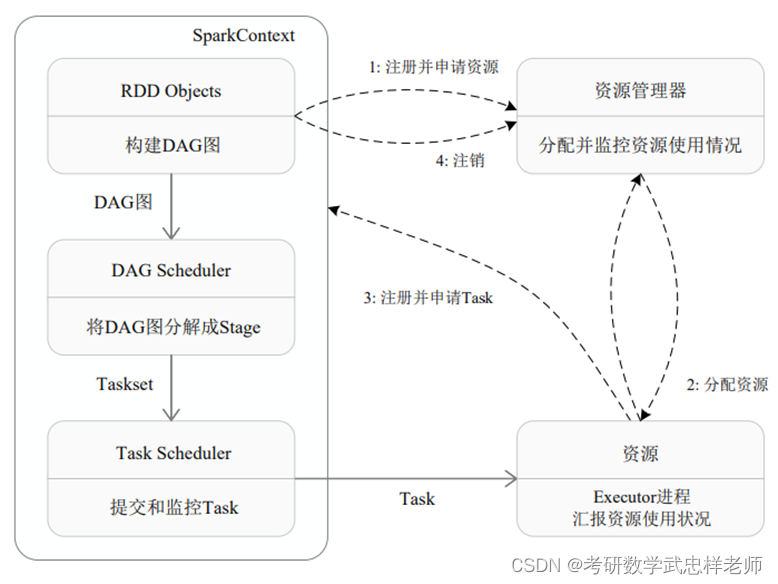
Spark运行基本流程如下图所示,流程如下。
(1)当一个Spark应用被提交时,首先需要为这个应用构建起基本的运行环境,即由任务控制节点(Driver)创建一个SparkContext,由SparkContext负责和资源管理器—Cluster Manager的通信,以及进行资源的申请、任务的分配和监控等。SparkContext 会向资源管理器注册并申请运行Executor的资源。
(2)资源管理器为Executor分配资源,并启动Executor进程,Executor运行情况将随着“心跳”发送到资源管理器上。
(3)SparkContext 根据 RDD 的依赖关系构建 DAG,并将 DAG 提交给 DAG 调度器(DAGScheduler)进行解析,将DAG分解成多个“阶段”(每个阶段都是一个任务集),并且计算出各个阶段之间的依赖关系,然后把一个个“任务集”提交给底层的任务调度器(TaskScheduler)进行处理;Executor 向 SparkContext 申请任务,任务调度器将任务分发给 Executor 运行,同时SparkContext将应用程序代码发放给Executor。
(4)任务在Executor上运行,把执行结果反馈给任务调度器,然后反馈给DAG调度器,运行完毕后写入数据并释放所有资源。
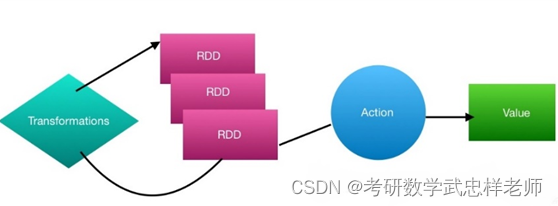
Spark的核心建立在统一的抽象RDD之上,这使得Spark的各个组件可以无缝地进行集成,在同一个应用程序中完成大数据计算任务。一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合。每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个 RDD 的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。两类操作的主要区别是,转换操作(如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。RDD采用了惰性调用,即在RDD的执行过程中,真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。
3.2.2.下载Spark
官网下载Spark2.4.3版本:Spark Release 2.4.3 | Apache Spark。下载完解压,和Hadoop3.1.1和winutils放在同一个盘或者目录下,方便以后的管理。
3.2.3.配置Spark环境变量
同之前配置Hadoop一样,需要配置SPARK_HOME和Path。
3.2.4.拷贝pyspark
进入spark安装目录,将pyspark复制到Python环境的Lib\site-packages目录下。
3.2.5.安装py4j
Py4J 是一个用 Python和 Java编写的库 ,通过 Py4J,Python程序能够动态访问Java虚拟机中的Java对象,Java程序也能够回调 Python对象。使用pip install py4j安装即可。
3.2.6.查看Spark是否安装成功
打开cmd窗口,输入spark-shell,出现以下内容说明配置成功:
4.基于Spark的数据分析与可视化
4.1.分析降水数据
我们首先计算各个城市过去24个小时的累积降水量。思路是按照城市对数据进行分组,对每个城市的rain1h字段进行分组求和。相关步骤如下:
(1)创建SparkSession对象spark;
(2)使用spark.read.csv(filename)读取passed_weather_ALL.csv数据生成Dateframe df;
(3)对df进行操作:使用Dateframe的select方法选择province、city_name、city_code、rain1h字段,并使用Column对象的cast(dateType)方法将rain1h转成数值型,再使用Dateframe的filter方法筛选出rain1h小于1000的记录(大于1000是异常数据),得到新的Dateframe df_rain;
(4)对df_rain进行操作:使用Dateframe的groupBy操作按照province、city_name、city_code的字段分组,使用agg方法对rain1h字段进行分组求和得到新的字段rain24h(过去24小时累积雨量),使用sort方法按照rain24h降序排列,经过上述操作得到新的Dateframe df_rain_sum;
(5)对df_rain_sum调用cache()方法将此前的转换关系进行缓存,提高性能;
(6)对df_rain_sum调用coalesce()将数据分区数目减为1,并使用write.csv(filename)方法将得到的数据持久化到本地文件;
(7)对df_rain_sum调用head()方法取前若干条数据(即24小时累积降水量Top-N的列表)供数据可视化使用。
代码 6 计算各城市过去24小时累积雨量
def passed_rain_analyse(filename):
print("开始分析累积降雨量")
spark = SparkSession.builder.config(conf=SparkConf()).getOrCreate()
df = spark.read.csv(filename, header=True)
df_rain = df.select(df['province'], df['city_name'], df['city_code'],
df['rain1h'].cast(DecimalType(scale=1))).filter(df['rain1h'] < 1000)
# 筛选数据,去除无效数据,一小时降水大于1000视为无效
df_rain_sum = df_rain.groupBy("province", "city_name", "city_code").agg(F.sum("rain1h").alias("rain24h")).sort(
F.desc("rain24h")) # 分组、求和、排序
df_rain_sum.coalesce(1).write.csv("passed_rain_analyse.csv")
print("累积降雨量分析完毕!")
return df_rain_sum.head(20) # 前20个 |
4.2.分析气温数据
根据国家标准(《地面气象服务观测规范》),日平均气温取四时次数据的平均值,四时次数据为:02时、08时、14时、20时。据此,应该先筛选出各个时次的气温数据,再按照城市对数据进行分组,对每个城市的tempeature字段进行分组求平均。相关步骤如下:
(1)创建SparkSession对象spark;
(2)使用spark.read.csv(filename)读取passed_weather_ALL.csv数据生成Dateframe df;
(3)对df进行操作:使用Dateframe的select方法选择province,city_name,city_code,temperature字段,并使用库pyspark.sql.functions中的date_format(col,pattern)方法和hour(col)将time字段转换成date(日期)字段和hour(小时)字段,(time字段的分秒信息无用),,得到新的Dateframe df_temperature;
(4)对df_temperature进行操作:使用Dateframe的filter操作过滤出hour字段在[2,8,14,20]中的记录,经过上述操作得到新的Dateframe df_4point_temperature;
(5)对df_4point_temperature进行操作:使用Dateframe的groupBy操作按照province、city_name、city_code、date字段分组,使用agg方法对temperature字段进行分组计数和求和(求和字段命名为avg_temperature),使用filter方法过滤出分组计数为4的记录(确保有4个时次才能计算日平均温),使用sort方法按照avg_temperature进行排列,desc是降序,asc是升序;再筛选出需要保存的字段province、city_name、city_code、date,avg_temperature(顺便使用库pyspark.sql.functions中的format_number(col, precision)方法保留一位小数),经过上述操作得到新的Dateframe df_avg_temperature;
(6)对df_avg_temperature调用cache()方法将此前的转换关系进行缓存,提高性能;
(7)对df_avg_temperature调用coalesce()将数据分区数目减为1,并使用write.csv(filename)方法将得到的数据持久化到本地文件;
(8)对df_rain_sum调用collect()方法取将Dateframe转换成list,方便后续进行数据可视化。
代码 7 计算各城市过去24小时平均气温
def passed_temperature_analyse(filename):
print("开始分析气温")
spark = SparkSession.builder.config(conf=SparkConf()).getOrCreate()
df = spark.read.csv(filename, header=True)
df_temperature = df.select( # 选择需要的列
df['province'],
df['city_name'],
df['city_code'],
df['temperature'].cast(DecimalType(scale=1)), # 转换为十进制类型,并将小数点后的位数保留1位
F.date_format(df['time'], "yyyy-MM-dd").alias("date"), # 得到日期数据
F.hour(df['time']).alias("hour") # 得到小时数据,命名为hour
).filter(df['temperature'] < 1000)
# 筛选四点时次
df_4point_temperature = df_temperature.filter(df_temperature['hour'].isin([2, 8, 14, 20]))
df_avg_temperature = df_4point_temperature.groupBy("province", "city_name", "city_code", "date").agg(
F.count("temperature"), F.avg("temperature").alias("avg_temperature")).sort(
F.asc("avg_temperature")).select("province", "city_name", "city_code", "date",
F.format_number('avg_temperature', 1).alias("avg_temperature"))
df_avg_temperature.show()
avg_temperature_list = df_avg_temperature.collect()
df_avg_temperature.coalesce(1).write.csv("passed_temperature.csv")
print("气温分析完毕")
return avg_temperature_list[0:20] # 前20个 |
我们可以使用同样的方法得到过去24小时各省级行政区的平均气温,只需修改groupby语句即可(修改为groupBy("province"))。
4.3.分析气压数据
先筛选出各个时次的气压数据,再按照城市对数据进行分组,对每个城市的pressure字段进行分组求平均。相关步骤如下:
(1)创建SparkSession对象spark;
(2)使用spark.read.csv(filename)读取passed_weather_ALL.csv数据生成Dateframe df;
(3)对df进行操作:使用Dateframe的select方法选择province、city_name、city_code、pressure字段,并使用库pyspark.sql.functions中的date_format(col,pattern)方法和hour(col)将time字段转换成date(日期)字段和hour(小时)字段,(time字段的分秒信息无用),,得到新的Dateframe df_pressure;
(4)对df_pressure进行操作:使用Dateframe的filter操作过滤出hour字段在[2,8,14,20]中的记录,经过上述操作得到新的Dateframe df_4point_pressure;
(5)对df_4point_pressure进行操作:使用Dateframe的groupBy操作按照province,city_name,city_code,date字段分组,使用agg方法对pressure字段进行分组计数和求和(求和字段命名为avg_pressure),使用filter方法过滤出分组计数为4的记录(确保有4个时次才能计算日平均温),使用sort方法按照avg_pressure进行排列,desc是降序,asc是升序;再筛选出需要保存的字段province、city_name、city_code、date,avg_pressure(顺便使用库pyspark.sql.functions中的format_number(col, precision)方法保留一位小数),经过上述操作得到新的Dateframe df_avg_pressure;
(6)对df_avg_pressure调用cache()方法将此前的转换关系进行缓存以提高性能;
(7)对df_avg_pressure调用coalesce()将数据分区数目减为1,并使用write.csv(filename)方法将得到的数据持久化到本地文件。
代码 8 计算各城市过去24小时平均气压
def passed_pressure_analyse(filename):
print("开始分析气压")
spark = SparkSession.builder.config(conf=SparkConf()).getOrCreate()
df = spark.read.csv(filename, header=True)
df_pressure = df.select( # 选择需要的列
df['province'],
df['city_name'],
df['city_code'],
df['pressure'].cast(DecimalType(scale=1)),
F.date_format(df['time'], "yyyy-MM-dd").alias("date"), # 得到日期数据
F.hour(df['time']).alias("hour") # 得到小时数据
)
df_4point_pressure = df_pressure.filter(df_pressure['hour'].isin([2, 8, 14, 20]))
df_avg_pressure = df_4point_pressure.groupBy("province", "city_name", "city_code", "date").agg(
F.count("pressure"), F.avg("pressure").alias("avg_pressure")).sort(
F.asc("avg_pressure")).select("province", "city_name", "city_code", "date",
F.format_number('avg_pressure', 1).alias("avg_pressure"))
avg_pressure_list = df_avg_pressure.collect()
df_avg_pressure.coalesce(1).write.csv("passed_pressure.csv")
print("气压分析完毕")
return avg_pressure_list[0:20] # 最低的20个 |
4.4.分析风力数据
我们首先筛选出各个时次的风向数据,再按照城市对数据进行分组,对每个城市的windDirection字段进行分组求平均。相关步骤与求平均温度与平均气压相似。注意到风向字段是一个0到360的数,我们可以将它划分为八个风向(北风、东北风、东风、东南风、南风、西南风、西风和西北风),每个风向区间大小为45°,以便进行后续的分析与可视化。
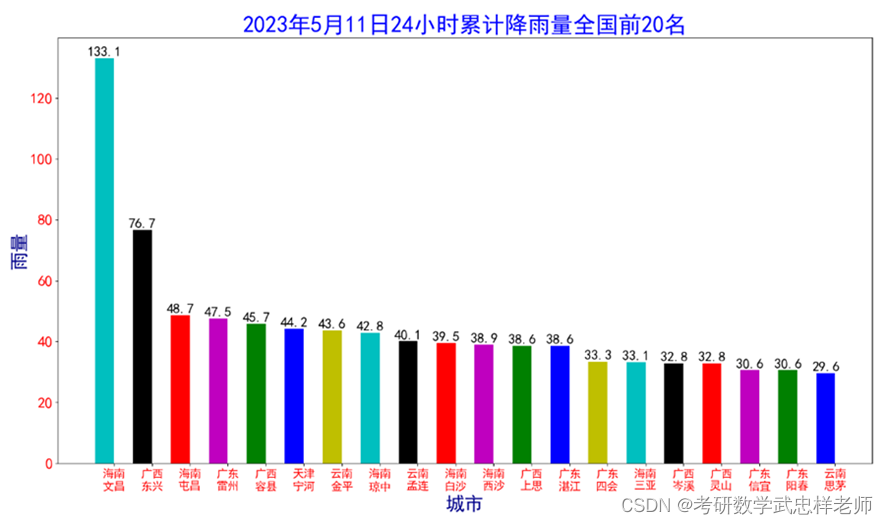
4.5.绘制累积降水量柱状图
首先draw_rain(rain_list)函数遍历传入的降雨列表,将每个城市的名称和24小时降雨量分别添加到name_list和num_list中。接着,设置一个索引列表,用于设置每个城市的柱状图位置。之后创建图形,并使用plt.bar()函数绘制柱状图。在绘制柱状图时,color参数设置每个柱子的颜色, width参数设置柱子的宽度。plt.xticks()函数设置x轴刻度标签的位置和字体大小,plt.ylim()函数设置y轴刻度范围,plt.xlabel()和plt.ylabel()函数设置x轴和y轴标签的名称和字体大小,plt.title()函数设置图形的标题和字体大小。在绘制完柱状图后,使用for循环遍历每个柱子,并使用plt.text()函数在柱子上方添加降雨量的数值。
代码 9 绘制各城市过去24小时累积降雨量图
def draw_rain(rain_list):
print("开始绘制累积降雨量图")
name_list = []
num_list = []
for item in rain_list:
name_list.append(item.province[0:2] + '\n' + item.city_name)
num_list.append(item.rain24h)
index = [i + 0.25 for i in range(0, len(num_list))]
plt.figure(figsize=(15, 15)) # 设置图的大小
rects = plt.bar(index, num_list, color='ckrmgby', width=0.5)
plt.xticks([i + 0.25 for i in index], name_list, fontsize=15, color='r') # fontsize设置x刻度字体大小
plt.ylim(ymax=(int(max(num_list) + 100) / 100) * 60, ymin=0) # 设置刻度间隔
plt.yticks(fontsize=20, color='r') # fontsize设置y刻度字体大小
plt.xlabel("城市", fontsize=25, color='darkblue') # fontsize设置x坐标标签字体大小
plt.ylabel("雨量", fontsize=25, color='darkblue') # fontsize设置y坐标标签字体大小
plt.title("2023年5月11日24小时累计降雨量全国前20名", fontsize=30, color='b') # fontsize设置标题字体大小
for rect in rects:
height = rect.get_height()
# fontsize设置直方图上字体大小
plt.text(rect.get_x() + rect.get_width() / 2, height, str(height), ha="center", va="bottom", fontsize=18)
plt.show()
print("累积降雨量图绘制完毕!") |
4.6.绘制平均气温柱状图
draw_temperature函数用于绘制气温图。函数首先创建两个空列表name_list和num_list,并将temperature_list中每个元素的省份、城市名和平均气温分别添加到name_list和num_list中。接下来,创建一个索引列表index,其中每个元素都是当前索引值加上0.25。然后通过用plt.figure创建指定大小的图形,并使用plt.bar创建一个条形图,其中每个条形的高度由num_list中的相应元素确定。函数使用plt.xticks设置x轴刻度标签,其中每个标签都是name_list中的相应元素。函数使用plt.ylim设置y轴刻度范围,其中最大值是num_list中的最大值乘以3.3并向上取整,最小值为0。plt.yticks设置y轴刻度标签的字体大小和颜色,plt.xlabel和plt.ylabel设置x轴和y轴标签的字体大小和颜色,plt.title设置图形标题的字体大小和颜色。最后,使用plt.text在每个条形上添加高度标签,并使用plt.show显示图形。
代码 10 绘制各城市过去24小时平均气温图
def draw_temperature(temperature_list):
print("开始绘制气温图")
name_list = []
num_list = []
date = temperature_list[1].date
for item in temperature_list:
name_list.append(item.province[0:2] + '\n' + item.city_name[0:2] + '\n' + item.city_name[2:])
num_list.append(float(item.avg_temperature))
index = [i + 0.25 for i in range(0, len(num_list))]
plt.figure(figsize=(20, 12)) # 设置图的大小
rects = plt.bar(index, num_list, color='ckrmgby', width=0.5)
plt.xticks([i + 0.25 for i in index], name_list, fontsize=20, color='r') # fontsize设置x刻度字体大小
plt.ylim(ymax=math.ceil(float(max(num_list))) * 3.3, ymin=0) # 设置刻度间隔
plt.yticks(fontsize=20, color='r') # fontsize设置y刻度字体大小
plt.xlabel("城市", fontsize=25, color='darkblue') # fontsize设置坐标标签字体大小
plt.ylabel("日平均气温", fontsize=25, color='darkblue') # fontsize设置坐标标签字体大小
plt.title("2023-5-11全国日平均气温最低前20名", fontsize=30, color='b') # fontsize设置标题字体大小
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height, str(height), ha="center", va="bottom", fontsize=18)
plt.show()
print("气温图绘制完毕!") |


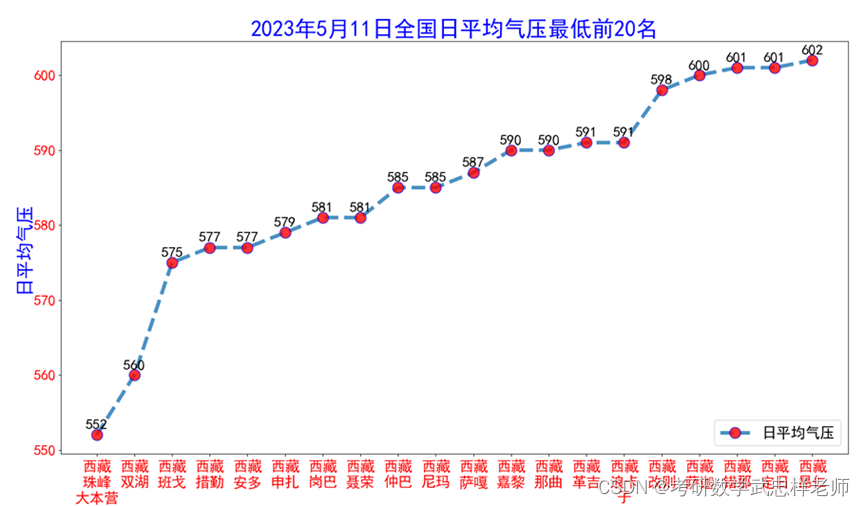
4.7.绘制平均气压折线图
draw_pressure函数用来绘制全国日平均气压最低前20名的城市的气压图。首先循环遍历数组中的每一行,将每个城市的名称和对应的日平均气压值分别添加到两个列表中。接下来使用matplotlib库中的plot函数绘制了气压图,并设置了图例、坐标轴标签、刻度字体大小等属性。最后,循环遍历列表中的每个城市,将其对应的气压值添加到图中,并设置了数字标签。
代码 11 绘制各城市过去24小时平均气压图
def draw_pressure(file_address):
print("开始绘制气压图")
name_list = []
num_list = []
df = pd.read_csv(file_address, header=None)
data = df.to_numpy()
print(data)
for i in data:
name_list.append(i[0][0:2] + '\n' + i[1][0:2] + '\n' + i[1][2:])
num_list.append(float(i[4]))
plt.figure(figsize=(15, 12))
plt.plot(name_list, num_list, label='日平均气压', alpha=0.8, mfc='r', ms=30, mec='b', marker='.', linewidth=5,
linestyle="--")
plt.xticks(fontsize=20, color='r') # fontsize设置x刻度字体大小
plt.yticks(fontsize=20, color='r') # fontsize设置y刻度字体大小
plt.xlabel("城市", fontsize=25, color='b') # fontsize设置坐标标签字体大小
plt.ylabel("日平均气压", fontsize=25, color='b') # fontsize设置坐标标签字体大小
# 设置数字标签
for a, b in zip(name_list, num_list):
plt.text(a, b + 0.5, int(b), ha='center', va='bottom', fontsize=20)
plt.title("2023年5月11日全国日平均气压最低前20名", fontsize=30, color='b') # fontsize设置标题字体大小
plt.rcParams.update({
'font.size': 20})
plt.legend(bbox_to_anchor=(1, 0.1)) # 图例移到右下角
plt.show()
print("气压图绘制完毕!") |
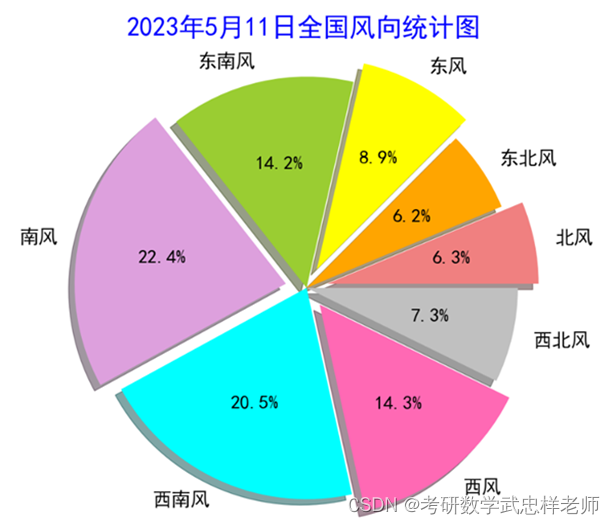
4.8.绘制全国风向统计饼状图
draw_windDirection用于绘制全国风向统计饼状图。首先定义了一个字典,用于存储各个方向的风的数量。接着提取出风向数据,并将其转换为浮点数类型。然后计算了数据的总数,并使用一个for循环遍历数据列表,将每个数据点分配到相应的风向类别中。接下来,将每个风向类别的数量存储在一个列表中,并定义了每个类别的标签和颜色。然后计算了每个类别的百分比,并定义了一个突出模块的偏移值。最后使用matplotlib库中的pie函数绘制了一个饼图,并设置标题和字体大小。
代码 12 绘制全国风向统计饼状图
def draw_windDirection(file_address):
dict = {
'bei': 0, 'dongbei': 0, 'dong': 0, 'dongnan': 0, 'nan': 0, 'xinan': 0, 'xi': 0, 'xibei': 0}
df = pd.read_csv(file_address)
data = df.to_numpy()
list = data[:, -1]
list = [float(x) for x in list]
Num = df.shape[0] # 4546
for i in list:
if 0 <= i <= 22.5 or 337.5 <= i <= 360:
dict['bei'] += 1
if 22.5 < i <= 67.5:
dict['dongbei'] += 1
if 67.5 < i <= 112.5:
dict['dong'] += 1
if 112.5 < i <= 157.5:
dict['dongnan'] += 1
if 157.5 < i <= 202.5:
dict['nan'] += 1
if 202.5 < i <= 247.5:
dict['xinan'] += 1
if 247.5 < i <= 292.5:
dict['xi'] += 1
if 292.5 < i <= 337.5:
dict['xibei'] += 1
# {'bei': 286, 'dongbei': 283, 'dong': 405, 'dongnan': 644, 'nan': 1017, 'xinan': 931, 'xi': 650, 'xibei': 330}
data = [dict['bei'], dict['dongbei'], dict['dong'], dict['dongnan'], dict['nan'], dict['xinan'], dict['xi'],
dict['xibei']]
# 数据标签
labels = ['北风', '东北风', '东风', '东南风', '南风', '西南风', '西风', '西北风']
# 各区域颜色
colors = ['lightcoral', 'orange', 'yellow', 'yellowgreen', 'plum', 'cyan', 'hotpink', 'silver']
# 数据计算处理
sizes = [data[0] / Num, data[1] / Num, data[2] / Num, data[3] / Num, data[4] / Num,
data[5] / Num, data[6] / Num, data[7] / Num]
# 设置突出模块偏移值
expodes = (0.1, 0, 0.1, 0, 0.1, 0, 0.1, 0)
plt.figure(figsize=(15, 15))
# 设置绘图属性并绘图
plt.pie(sizes, explode=expodes, labels=labels, shadow=True, colors=colors, autopct='%.1f%%',
textprops={
'fontsize': 22})
plt.axis('equal')
plt.title("2023年5月11日全国风向统计图", fontsize=30, color='b') # fontsize设置标题字体大小
plt.show() |
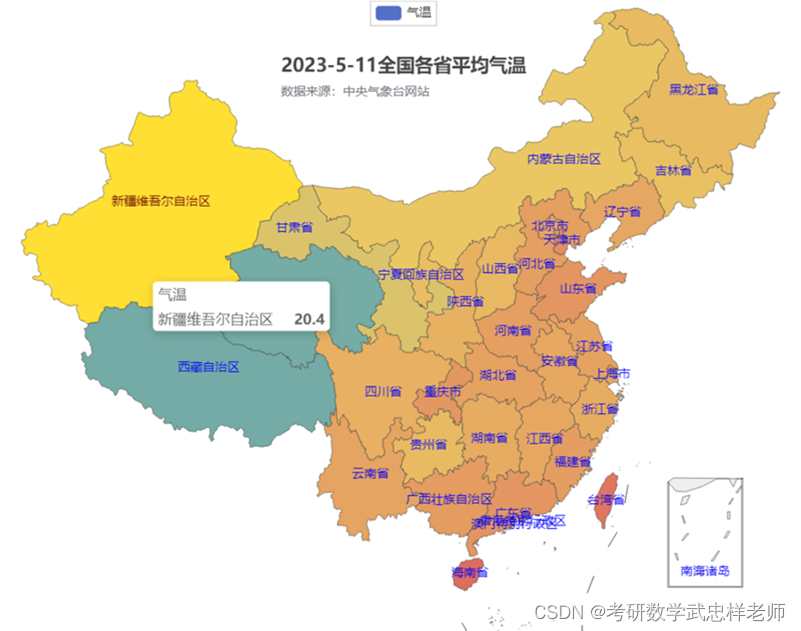
4.9.绘制全国各省平均气温地图
draw_province_temperature函数用来绘制全国各省平均气温地图。首先定义了一个包含各省名称和平均气温的列表,然后使用pyecharts库中的Map函数创建地图,设置了地图的初始高度和宽度,并添加了一个名为“气温”的系列,数据对为前面定义的列表,地图类型为china,启用了鼠标滚轮缩放和拖动平移,不显示图形标记。接下来设置了全局选项,包括标题、数据标准显示和可视化映射选项,其中标题包括主标题、副标题和位置,数据标准显示设置了最大值和最小值,可视化映射选项可以设置颜色范围。最后设置了系列选项,包括标签名称显示和颜色。最后使用render函数将地图渲染为html文件 。
代码 13 绘制全国各省平均气温地图
Map(init_opts=opts.InitOpts(height="1000px", width="1500px")).add(
series_name="气温",
data_pair=tempreture,
maptype="china",
is_roam=True,
is_map_symbol_show=False,
).set_global_opts(
title_opts=opts.TitleOpts(title="2023-5-11全国各省平均气温",
subtitle="数据来源:中央气象台网站",
pos_right="center",
pos_top="5%"),
visualmap_opts=opts.VisualMapOpts(max_=30,
min_=0),
).set_series_opts(
label_opts=opts.LabelOpts(is_show=True, color="blue")
).render("2023-5-11全国各省平均气温.html") |
4.10.绘制武汉市主城区一天风级雷达图
draw_windSpeed函数用于绘制武汉市主城区一天内不同风向下的风速平均值的极区图。degs = np.arange(45, 361, 45)定义了一个包含45度到360度之间每隔45度的角度的numpy数组,定义空列表temp用于存储不同风向下的风速平均值。之后对于每个角度deg,循环遍历24小时内的风向数据windd,如果windd[i]等于deg,则将对应的风速数据wind_speed[i]添加到speed列表中。如果speed列表为空,则将0添加到temp列表中,否则将speed列表中的所有元素求和并除以元素个数,将结果添加到temp列表中。theta = np.arange(0. + np.pi / 8, 2 * np.pi + np.pi / 8, 2 * np.pi / 8) 定义了一个整数N和一个包含N个元素的numpy数组theta,用于绘制极区图。radii = np.array(temp) 将temp列表转换为numpy数组radii,用于绘制极区图。plt.axes(polar=True)定义了一个极坐标系,colors = plt.cm.viridis(np.random.rand(N)) 定义了一个包含N个元素的numpy数组colors,用于设置每个扇区的颜色。plt.bar(theta, radii, width=(2 * np.pi / N), bottom=0.0, color=colors) 绘制了极区图,其中theta和radii分别表示角度和半径,width表示每个扇区的宽度,bottom表示每个扇区的起始位置,color表示每个扇区的颜色。plt.title设置了极区图的标题,其中x表示标题的水平位置,fontsize表示标题的字体大小,loc表示标题的位置 。
代码 14 绘制武汉市主城区一天风级雷达图
def draw_windSpeed(file):
data = pd.read_csv(file)
windd = []
wind = list(data['windDirection'])
wind_speed = list(data['windSpeed'])
for i in wind:
if i > 360:
windd.append(0)
if 0 <= i <= 22.5 or 337.5 <= i <= 360:
windd.append(90)
if 22.5 < i <= 67.5:
windd.append(45)
if 67.5 < i <= 112.5:
windd.append(360)
if 112.5 < i <= 157.5:
windd.append(315)
if 157.5 < i <= 202.5:
windd.append(270)
if 202.5 < i <= 247.5:
windd.append(225)
if 247.5 < i <= 292.5:
windd.append(180)
if 292.5 < i <= 337.5:
windd.append(135)
degs = np.arange(45, 361, 45)
temp = []
for deg in degs:
speed = []
for i in range(0, 24):
if windd[i] == deg:
speed.append(wind_speed[i])
if len(speed) == 0:
temp.append(0)
else:
temp.append(sum(speed) / len(speed))
N = 8
theta = np.arange(0. + np.pi / 8, 2 * np.pi + np.pi / 8, 2 * np.pi / 8)
radii = np.array(temp)
plt.axes(polar=True)
colors = plt.cm.viridis(np.random.rand(N))
plt.bar(theta, radii, width=(2 * np.pi / N), bottom=0.0, color=colors)
plt.title('2023-5-12武汉市主城区一天风级图', x=0.2, fontsize=15, loc='left')
plt.show() |

源代码
spider.py
import urllib.request, urllib.error
import json
import csv
import os
import importlib, sys
importlib.reload(sys)
class Crawler:
def get_html(self, url):
headers = {
'User-Agent': "Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1"
}
request = urllib.request.Request(url,headers=headers)
response = urllib.request.urlopen(request)
return response.read().decode()
def parse_json(self, url):
obj = self.get_html(url)
if obj:
json_obj = json.loads(obj)
else:
json_obj = list()
return json_obj
def write_csv(self, file, data):
if data:
print("开始写入 " + file)
with open(file, 'a+', encoding='utf-8-sig') as f: # utf-8-sig 带BOM的utf-8
f_csv = csv.DictWriter(f, data[0].keys())
# if not os.path.exists(file):
f_csv.writeheader()
f_csv.writerows(data)
print("结束写入 " + file)
def write_header(self, file, data):
if data:
print("开始写入 " + file)
with open(file, 'a+', encoding='utf-8-sig') as f:
f_csv = csv.DictWriter(f, data[0].keys())
f_csv.writeheader()
f_csv.writerows(data)
print("结束写入 " + file)
def write_row(self, file, data):
if data:
print("开始写入 " + file)
with open(file, 'a+', encoding='utf-8-sig') as f:
f_csv = csv.DictWriter(f, data[0].keys())
if not os.path.exists(file):
f_csv.writeheader()
f_csv.writerows(data)
print("结束写入 " + file)
def read_csv(self, file):
print("开始读取 " + file)
with open(file, 'r+', encoding='utf-8-sig') as f:
data = csv.DictReader(f)
print("结束读取 " + file)
return list(data)
def get_provinces(self):
province_file = 'C:/Users/26909/Desktop/province.csv'
if not os.path.exists(province_file):
print("开始爬取省份")
provinces = self.parse_json('http://www.nmc.cn/f/rest/province')
print("省份爬取完毕!")
self.write_csv(province_file, provinces)
else:
provinces = self.read_csv(province_file)
return provinces
def get_cities(self):
city_file = 'input/city.csv'
if not os.path.exists(city_file):
cities = list()
print("开始爬取城市")
for province in self.get_provinces():
url = province['url'].split('/')[-1].split('.')[0]
cities.extend(self.parse_json('http://www.nmc.cn/f/rest/province/' + url))
self.write_csv(city_file, cities)
print("爬取城市完毕!")
else:
cities = self.read_csv(city_file)
return cities
def get_passed_weather(self, province):
weather_passed_file = 'C:/Users/26909/Desktop/passed_weather_' + province + '.csv'
if os.path.exists(weather_passed_file):
return
passed_weather = list()
count = 0
if province == 'ALL':
print("开始爬取过去的天气状况")
for city in self.get_cities():
data = self.parse_json('http://www.nmc.cn/f/rest/passed/' + city['code'])
if data:
count = count + 1
for item in data:
item['city_code'] = city['code']
item['province'] = city['province']
item['city_name'] = city['city']
item['city_index'] = str(count)
passed_weather.extend(data)
if count % 50 == 0:
if count == 50:
self.write_header(weather_passed_file, passed_weather)
else:
self.write_row(weather_passed_file, passed_weather)
passed_weather = list()
if passed_weather:
if count <= 50:
self.write_header(weather_passed_file, passed_weather)
else:
self.write_row(weather_passed_file, passed_weather)
print("爬取过去的天气状况完毕!")
else:
print("开始爬取过去的天气状况")
select_city = filter(lambda x: x['province'] == province, self.get_cities())
for city in select_city:
data = self.parse_json('http://www.nmc.cn/f/rest/passed/' + city['code'])
if data:
count = count + 1
for item in data:
item['city_index'] = str(count)
item['city_code'] = city['code']
item['province'] = city['province']
item['city_name'] = city['city']
passed_weather.extend(data)
self.write_csv(weather_passed_file, passed_weather)
print("爬取过去的天气状况完毕!")
def run(self, range='ALL'):
self.get_passed_weather(range)
cr = Crawler()
cr.run('ALL')
analysis.py
import numpy as np
import pandas as pd
from pyspark import SparkConf
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from pyspark.sql.types import DecimalType, TimestampType
import matplotlib.pyplot as plt
import math
from pyecharts import options as opts
from pyecharts.charts import Map
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 计算各个城市过去24小时累积雨量
def passed_rain_analyse(filename):
print("开始分析累积降雨量")
spark = SparkSession.builder.config(conf=SparkConf()).getOrCreate()
df = spark.read.csv(filename, header=True)
df_rain = df.select(df['province'], df['city_name'], df['city_code'],
df['rain1h'].cast(DecimalType(scale=1))).filter(df['rain1h'] < 1000)
# 筛选数据,去除无效数据,一小时降水大于1000视为无效
df_rain_sum = df_rain.groupBy("province", "city_name", "city_code").agg(F.sum("rain1h").alias("rain24h")).sort(
F.desc("rain24h")) # 分组、求和、排序
df_rain_sum.coalesce(1).write.csv("passed_rain_analyse.csv")
print("累积降雨量分析完毕!")
return df_rain_sum.head(20) # 前20个
# 武汉过去24小时的风速和风向
def passed_windSpeed_analyse(filename):
print("开始分析风速")
df = pd.read_csv(filename)
df_windSpeed = df[df['city_name'] == '武汉']
df_windSpeed.to_csv("wuhan_wind.csv")
return df_windSpeed # 前20个
# 计算各个城市过去24小时平均气温
def passed_temperature_analyse(filename):
print("开始分析气温")
spark = SparkSession.builder.config(conf=SparkConf()).getOrCreate()
df = spark.read.csv(filename, header=True)
df_temperature = df.select( # 选择需要的列
df['province'],
df['city_name'],
df['city_code'],
df['temperature'].cast(DecimalType(scale=1)), # 转换为十进制类型,并将小数点后的位数保留1位
F.date_format(df['time'], "yyyy-MM-dd").alias("date"), # 得到日期数据
F.hour(df['time']).alias("hour") # 得到小时数据,命名为hour
).filter(df['temperature'] < 1000)
# 筛选四点时次
df_4point_temperature = df_temperature.filter(df_temperature['hour'].isin([2, 8, 14, 20]))
df_avg_temperature = df_4point_temperature.groupBy("province", "city_name", "city_code", "date").agg(
F.count("temperature"), F.avg("temperature").alias("avg_temperature")).sort(
F.asc("avg_temperature")).select("province", "city_name", "city_code", "date",
F.format_number('avg_temperature', 1).alias("avg_temperature"))
df_avg_temperature.show()
avg_temperature_list = df_avg_temperature.collect()
df_avg_temperature.coalesce(1).write.csv("passed_temperature.csv")
print("气温分析完毕")
return avg_temperature_list[0:20] # 前20个
# 计算各省过去24小时平均气温
def province_temperature_analyse(filename):
print("开始分析各省气温")
spark = SparkSession.builder.config(conf=SparkConf()).getOrCreate()
df = spark.read.csv(filename, header=True)
df_temperature = df.select( # 选择需要的列
df['province'],
df['temperature'].cast(DecimalType(scale=1)),
F.date_format(df['time'], "yyyy-MM-dd").alias("date"), # 得到日期数据
F.hour(df['time']).alias("hour") # 得到小时数据
).filter(df['temperature'] < 1000)
# 筛选四点时次
df_4point_temperature = df_temperature.filter(df_temperature['hour'].isin([2, 8, 14, 20]))
df_avg_temperature = df_4point_temperature.groupBy("province").agg(
F.count("temperature"), F.avg("temperature").alias("avg_temperature")).sort(
F.asc("avg_temperature")).select("province", F.format_number('avg_temperature', 1).alias("avg_temperature"))
df_avg_temperature.show()
avg_temperature_list = df_avg_temperature.collect()
df_avg_temperature.coalesce(1).write.csv("province_temperature.csv")
print("气温分析完毕")
return avg_temperature_list[0:20] # 最低的20个
# 计算各个城市过去24小时平均气压
def passed_pressure_analyse(filename):
print("开始分析气压")
spark = SparkSession.builder.config(conf=SparkConf()).getOrCreate()
df = spark.read.csv(filename, header=True)
df_pressure = df.select( # 选择需要的列
df['province'],
df['city_name'],
df['city_code'],
df['pressure'].cast(DecimalType(scale=1)),
F.date_format(df['time'], "yyyy-MM-dd").alias("date"), # 得到日期数据
F.hour(df['time']).alias("hour") # 得到小时数据
)
# 筛选四点时次
df_4point_pressure = df_pressure.filter(df_pressure['hour'].isin([2, 8, 14, 20]))
df_avg_pressure = df_4point_pressure.groupBy("province", "city_name", "city_code", "date").agg(
F.count("pressure"), F.avg("pressure").alias("avg_pressure")).sort(
F.asc("avg_pressure")).select("province", "city_name", "city_code", "date",
F.format_number('avg_pressure', 1).alias("avg_pressure"))
avg_pressure_list = df_avg_pressure.collect()
df_avg_pressure.coalesce(1).write.csv("passed_pressure.csv")
print("气压分析完毕")
return avg_pressure_list[0:20] # 最低的20个
# 计算各个城市过去24小时平均风向
def passed_windDirection_analyse(filename):
print("开始分析风向")
spark = SparkSession.builder.config(conf=SparkConf()).getOrCreate()
df = spark.read.csv(filename, header=True)
df_windDirection = df.select( # 选择需要的列
df['province'],
df['city_name'],
df['city_code'],
df['windDirection'].cast(DecimalType(scale=1)),
F.date_format(df['time'], "yyyy-MM-dd").alias("date"), # 得到日期数据
F.hour(df['time']).alias("hour") # 得到小时数据
).filter(df['windDirection'] < 400)
# 筛选四点时次
df_4point_windDirection = df_windDirection.filter(df_windDirection['hour'].isin([2, 8, 14, 20]))
df_avg_windDirection = df_4point_windDirection.groupBy("province", "city_name", "city_code", "date").agg(
F.count("windDirection"), F.avg("windDirection").alias("avg_windDirection")).sort(
F.asc("avg_windDirection")).select("province", "city_name", "city_code", "date",
F.format_number('avg_windDirection', 1).alias("avg_windDirection"))
df_avg_windDirection.coalesce(1).write.csv("passed_windDirection.csv")
print("风向分析完毕")
# 绘制累积降雨量图
def draw_rain(rain_list):
print("开始绘制累积降雨量图")
name_list = []
num_list = []
for item in rain_list:
name_list.append(item.province[0:2] + '\n' + item.city_name)
num_list.append(item.rain24h)
index = [i + 0.25 for i in range(0, len(num_list))]
plt.figure(figsize=(15, 15)) # 设置图的大小
rects = plt.bar(index, num_list, color='ckrmgby', width=0.5)
plt.xticks([i + 0.25 for i in index], name_list, fontsize=15, color='r') # fontsize设置x刻度字体大小
plt.ylim(ymax=(int(max(num_list) + 100) / 100) * 60, ymin=0) # 设置刻度间隔
plt.yticks(fontsize=20, color='r') # fontsize设置y刻度字体大小
plt.xlabel("城市", fontsize=25, color='darkblue') # fontsize设置x坐标标签字体大小
plt.ylabel("雨量", fontsize=25, color='darkblue') # fontsize设置y坐标标签字体大小
plt.title("2023年5月11日24小时累计降雨量全国前20名", fontsize=30, color='b') # fontsize设置标题字体大小
for rect in rects:
height = rect.get_height()
# fontsize设置直方图上字体大小
plt.text(rect.get_x() + rect.get_width() / 2, height, str(height), ha="center", va="bottom", fontsize=18)
plt.show()
print("累积降雨量图绘制完毕!")
def draw_temperature(temperature_list):
print("开始绘制气温图")
name_list = []
num_list = []
date = temperature_list[1].date
for item in temperature_list:
name_list.append(item.province[0:2] + '\n' + item.city_name[0:2] + '\n' + item.city_name[2:])
num_list.append(float(item.avg_temperature))
index = [i + 0.25 for i in range(0, len(num_list))]
plt.figure(figsize=(20, 12)) # 设置图的大小
rects = plt.bar(index, num_list, color='ckrmgby', width=0.5)
plt.xticks([i + 0.25 for i in index], name_list, fontsize=20, color='r') # fontsize设置x刻度字体大小
plt.ylim(ymax=math.ceil(float(max(num_list))) * 3.3, ymin=0) # 设置刻度间隔
plt.yticks(fontsize=20, color='r') # fontsize设置y刻度字体大小
plt.xlabel("城市", fontsize=25, color='darkblue') # fontsize设置坐标标签字体大小
plt.ylabel("日平均气温", fontsize=25, color='darkblue') # fontsize设置坐标标签字体大小
plt.title("2023-5-11全国日平均气温最低前20名", fontsize=30, color='b') # fontsize设置标题字体大小
for rect in rects:
height = rect.get_height()
# fontsize设置直方图上字体大小
plt.text(rect.get_x() + rect.get_width() / 2, height, str(height), ha="center", va="bottom", fontsize=18)
plt.show()
print("气温图绘制完毕!")
def draw_pressure(file_address):
print("开始绘制气压图")
name_list = []
num_list = []
df = pd.read_csv(file_address, header=None)
data = df.to_numpy()
print(data)
for i in data:
name_list.append(i[0][0:2] + '\n' + i[1][0:2] + '\n' + i[1][2:])
num_list.append(float(i[4]))
plt.figure(figsize=(15, 12))
plt.plot(name_list, num_list, label='日平均气压', alpha=0.8, mfc='r', ms=30, mec='b', marker='.', linewidth=5,
linestyle="--")
plt.xticks(fontsize=20, color='r') # fontsize设置x刻度字体大小
plt.yticks(fontsize=20, color='r') # fontsize设置y刻度字体大小
plt.xlabel("城市", fontsize=25, color='b') # fontsize设置坐标标签字体大小
plt.ylabel("日平均气压", fontsize=25, color='b') # fontsize设置坐标标签字体大小
# 设置数字标签
for a, b in zip(name_list, num_list):
plt.text(a, b + 0.5, int(b), ha='center', va='bottom', fontsize=20)
plt.title("2023年5月11日全国日平均气压最低前20名", fontsize=30, color='b') # fontsize设置标题字体大小
plt.rcParams.update({'font.size': 20})
plt.legend(bbox_to_anchor=(1, 0.1)) # 图例移到右下角
plt.show()
print("气压图绘制完毕!")
def draw_windDirection(file_address):
dict = {'bei': 0, 'dongbei': 0, 'dong': 0, 'dongnan': 0, 'nan': 0, 'xinan': 0, 'xi': 0, 'xibei': 0}
df = pd.read_csv(file_address)
data = df.to_numpy()
list = data[:, -1]
list = [float(x) for x in list]
Num = df.shape[0] # 4546
for i in list:
if 0 <= i <= 22.5 or 337.5 <= i <= 360:
dict['bei'] += 1
if 22.5 < i <= 67.5:
dict['dongbei'] += 1
if 67.5 < i <= 112.5:
dict['dong'] += 1
if 112.5 < i <= 157.5:
dict['dongnan'] += 1
if 157.5 < i <= 202.5:
dict['nan'] += 1
if 202.5 < i <= 247.5:
dict['xinan'] += 1
if 247.5 < i <= 292.5:
dict['xi'] += 1
if 292.5 < i <= 337.5:
dict['xibei'] += 1
# {'bei': 286, 'dongbei': 283, 'dong': 405, 'dongnan': 644, 'nan': 1017, 'xinan': 931, 'xi': 650, 'xibei': 330}
data = [dict['bei'], dict['dongbei'], dict['dong'], dict['dongnan'], dict['nan'], dict['xinan'], dict['xi'],
dict['xibei']]
# 数据标签
labels = ['北风', '东北风', '东风', '东南风', '南风', '西南风', '西风', '西北风']
# 各区域颜色
colors = ['lightcoral', 'orange', 'yellow', 'yellowgreen', 'plum', 'cyan', 'hotpink', 'silver']
# 数据计算处理
sizes = [data[0] / Num, data[1] / Num, data[2] / Num, data[3] / Num, data[4] / Num,
data[5] / Num, data[6] / Num, data[7] / Num]
# 设置突出模块偏移值
expodes = (0.1, 0, 0.1, 0, 0.1, 0, 0.1, 0)
plt.figure(figsize=(15, 15))
# 设置绘图属性并绘图
plt.pie(sizes, explode=expodes, labels=labels, shadow=True, colors=colors, autopct='%.1f%%',
textprops={'fontsize': 22})
plt.axis('equal')
plt.title("2023年5月11日全国风向统计图", fontsize=30, color='b') # fontsize设置标题字体大小
plt.show()
def draw_province_temperature():
tempreture = [
['甘肃省', 13.5],
['吉林省', 15.7],
['贵州省', 16.6],
['山西省', 16.9],
['陕西省', 17.7],
['四川省', 17.9],
['浙江省', 18.2],
['湖南省', 18.3],
['安徽省', 18.9],
['江西省', 18.9],
['上海市', 19.0],
['辽宁省', 19.0],
['北京市', 19.3],
['云南省', 19.4],
['湖北省', 19.6],
['江苏省', 19.6],
['河北省', 19.9],
['河南省', 20.0],
['福建省', 20.1],
['重庆市', 20.9],
['山东省', 21.1],
['广东省', 21.1],
['天津市', 22.1],
['台湾省', 25.0],
['海南省', 26.1],
['广西壮族自治区', 20.3],
['新疆维吾尔自治区', 20.4],
['澳门特别行政区', 22.4],
['香港特别行政区', 24.4],
['西藏自治区', 3.5],
['青海省', 3.6],
['黑龙江省', 16.5],
['内蒙古自治区', 15.0],
['宁夏回族自治区', 16.2]
]
Map(init_opts=opts.InitOpts(height="1000px", width="1500px")).add(
series_name="气温",
data_pair=tempreture,
maptype="china",
# 是否启用鼠标滚轮缩放和拖动平移,默认为True
is_roam=True,
# 是否显示图形标记,默认为True
is_map_symbol_show=False,
).set_global_opts(
# 设置标题
title_opts=opts.TitleOpts(title="2023-5-11全国各省平均气温",
subtitle="数据来源:中央气象台网站",
pos_right="center",
pos_top="5%"),
# 设置标准显示
visualmap_opts=opts.VisualMapOpts(max_=30,
min_=0),
# range_color=["#E0ECF8", "#045FB4"]),
).set_series_opts(
# 标签名称显示,默认为True
label_opts=opts.LabelOpts(is_show=True, color="blue")
).render("2023-5-11全国各省平均气温.html")
def draw_windSpeed(file):
data = pd.read_csv(file)
windd = []
wind = list(data['windDirection'])
wind_speed = list(data['windSpeed'])
for i in wind:
if i > 360:
windd.append(0)
if 0 <= i <= 22.5 or 337.5 <= i <= 360:
windd.append(90)
if 22.5 < i <= 67.5:
windd.append(45)
if 67.5 < i <= 112.5:
windd.append(360)
if 112.5 < i <= 157.5:
windd.append(315)
if 157.5 < i <= 202.5:
windd.append(270)
if 202.5 < i <= 247.5:
windd.append(225)
if 247.5 < i <= 292.5:
windd.append(180)
if 292.5 < i <= 337.5:
windd.append(135)
degs = np.arange(45, 361, 45)
temp = []
for deg in degs:
speed = []
# 获取 wind_deg 在指定范围的风速平均值数据
for i in range(0, 24):
if windd[i] == deg:
speed.append(wind_speed[i])
if len(speed) == 0:
temp.append(0)
else:
temp.append(sum(speed) / len(speed))
N = 8
theta = np.arange(0. + np.pi / 8, 2 * np.pi + np.pi / 8, 2 * np.pi / 8)
# 数据极径
radii = np.array(temp)
# 绘制极区图坐标系
plt.axes(polar=True)
# 定义每个扇区的RGB值(R,G,B),x越大,对应的颜色越接近蓝色
colors = plt.cm.viridis(np.random.rand(N))
plt.bar(theta, radii, width=(2 * np.pi / N), bottom=0.0, color=colors)
plt.title('2023-5-12武汉市主城区一天风级图', x=0.2, fontsize=15, loc='left')
plt.show()
return temp
sourcefile = "passed_weather_ALL.csv"
# 降雨
# rain_list = passed_rain_analyse(sourcefile)
# draw_rain(rain_list)
# 气温
# temperature_list = passed_temperature_analyse(sourcefile)
# draw_temperature(temperature_list)
# 气压
# pressure_list = passed_pressure_analyse(sourcefile)
# draw_pressure('low_pressure.csv')
# 风向
# windDirection_list = passed_windDirection_analyse(sourcefile)
# draw_windDirection('windDirection.csv')
# 各省气温
# province_temperature_analyse(sourcefile)
# draw_province_temperature()
# 风向雷达图
#passed_windSpeed_analyse(sourcefile)
draw_windSpeed('wuhan_wind.csv')