
Google Gemini 是 Google 正在推出的一套新的生成式 AI 服务,专门针对有兴趣扩展其 AI 服务的企业。它是由 Google DeepMind 项目创建的一系列多模态 AI 模型(我们将在下面详细介绍)。
博客:Introducing Gemini: Google’s most capable AI model yet (blog.google)

在一份技术报告中,Gemini 表示它超越了现存最强大的基础模型 GPT-4,并表明它不仅在文本生成方面领先,而且在多模态识别和处理方面也处于领先地位。 此外,谷歌还推出了三款尺寸的型号——Gemini Ultra、Gemini Pro 和 Gemini Nano——并公开披露了 Nano 的参数数量,分别是 Nano-1 的 1.8B 和 Nano-2 的 3.25B, 这是一个真正的sLM。
按型号尺寸划分的功能

Gemini Ultra 是市面上最大的型号,提供最强大的性能来处理复杂的任务。
- 极其复杂的任务:Gemini Ultra 旨在处理非常复杂的任务,并且在这一领域表现出色。它在多个领先的基准测试中实现了最先进的性能。
- 多模态理解:作为多模态模型,Gemini Ultra 在理解和推断不同类型的数据方面非常强大,包括文本、图像、音频、视频等。
- 规模和效率:它使用 TPUv4 加速器进行大规模训练,并针对大规模高效操作进行了优化。
- 最先进的性能:Gemini Ultra 在 MMLU 基准测试中达到了惊人的 90.04% 的准确率,并且在数学和编码等其他领域也表现出色。
Gemini Pro 是一种可以在各种任务中有效扩展的模型。
- 可跨各种任务进行扩展:Gemini Pro 最适合跨各种任务进行扩展。基础设施和学习算法允许使用比 Gemini Ultra 更少的资源进行快速预训练。
- 优化的性能:针对各种 AI 任务优化性能,非常适合希望构建和扩展 AI 的企业客户和开发人员。
- 多功能性:Gemini Pro 没有 Gemini Ultra 那么大,但它的性能与其他型号相似,可以更有效地服务。
Gemini Nano 是最小的型号,旨在高效地在个人设备内完成工作。
- 设备端操作的效率:Nano 模型专为设备端部署而设计,优先考虑效率和速度。
- 小而强大:尽管尺寸小,但纳米模型在总结和阅读理解等任务中表现出令人印象深刻的性能。
- 可访问性:Gemini Nano 模型能够在各种平台和设备上工作,使高级 AI 功能更易于访问。
Gemini AI 是谷歌 AI 技术进步开辟新天地的模型。凭借在从文本到多模态的广泛领域中的出色表现,以及有效理解和处理复杂信息的能力,它正在照亮人工智能的未来。它有望为每个使用人工智能的人提供高价值。
模型能力
文本处理能力
Gemini Ultra 在涵盖 57 个受试者的 MMLU 基准测试中以 90.0% 的表现优于人类专家。
在同一测试中,OpenAI 的 GPT-4 以 86.4% 的成绩优于 Gemini Ultra,而在复杂的数学推理的 Big-Bench Hard 中,Gemini Ultra 的表现优于 GPT-4,为 83.6%,为 83.1%。
多模态处理能力
在图像理解方面, Gemini Ultra 以 77.8% 的 77.2% 优于 GPT-4V 。
在文档理解方面, Gemini Ultra 的表现也优于 GPT-4V 的 88.4%,为 90.9%。
需要注意的事项
多模态理解:Gemini AI 在理解多模态的能力方面已经超越了当前的最先进的 (SOTA) 模型。展示在没有 OCR 系统帮助的情况下理解和解决图像问题的能力。
代码生成:可以从 Python 等流行的编程语言生成高质量的代码。这有助于开发人员更快、更高效地发布应用程序并改进他们的服务。
模型架构
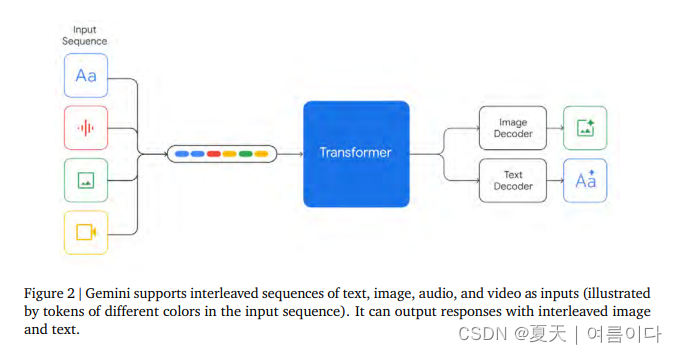
在模型架构方面,Gemini依然采用Transformer架构,采用了高效的Attention机制,支持32k的上下文长度。
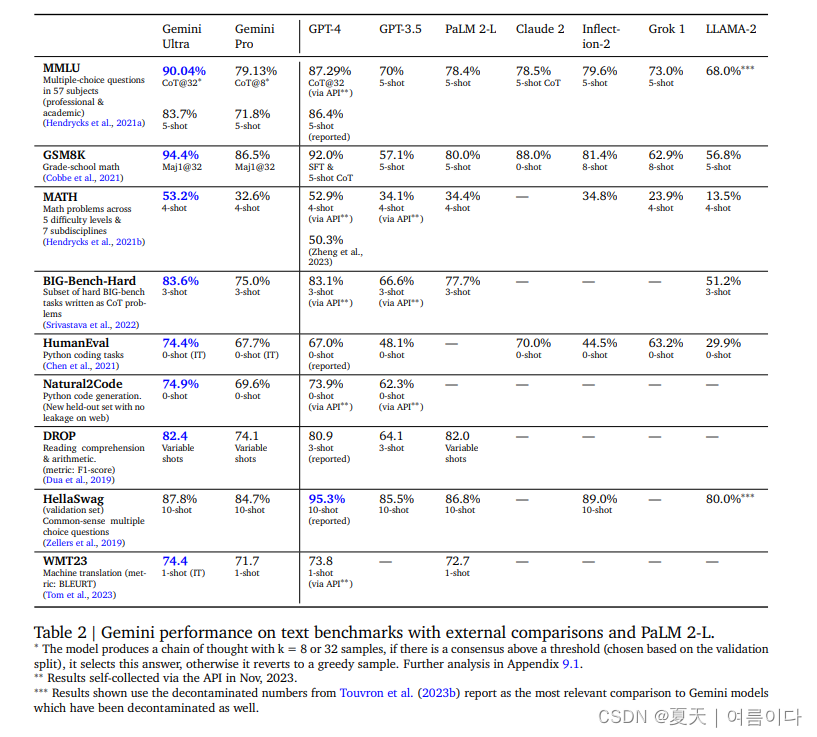
报告中,在多选问题、数学问题、Python代码任务、阅读等方面,Gemini Pro和Ultra与GPT-4、GPT-3.5等其他LLM的评分对比如下:
模型效果

Gemini AI 的工作原理
Gemini 可能会使用 Google Pathways 架构。在这种类型的 AI 架构中,最初会教一系列模块化机器学习 (ML) 模型如何执行特定任务。训练完成后,这些模块将被连接起来形成一个网络。
联网的模块可以独立工作,也可以协同工作以生成不同类型的输出。在后端,编码器将不同类型的数据转换为通用语言,解码器根据编码的输入和手头的任务以不同的模式生成输出。
预计谷歌将使用 Duet AI 作为 Gemini 的前端。这个用户友好的界面将隐藏 Gemini 架构的复杂性,并使具有不同技能水平的人能够将 Gemini 模型用于生成式 AI 目的。
Gemini AI 是如何训练的
据称,Gemini LLM 模型已使用以下技术组合进行训练:
- 监督学习:Gemini AI 模块经过训练,通过使用从标记训练数据中学习到的模式来预测新数据的输出。
- 无监督学习:Gemini AI 模块经过训练,可以自主发现数据中的模式、结构或关系,而无需标记示例。
- 强化学习:Gemini AI 模块通过反复试验过程迭代改进了他们的决策策略,该过程教会模块最大化奖励并最大限度地减少惩罚。
一些行业专家推测,谷歌严重依赖人类反馈强化学习(RLHF)在Cloud TPU v5e芯片上训练Gemini模块。据谷歌称,TPU 的计算能力是用于训练 Chat GPT 的芯片的五倍。
谷歌工程师很可能使用了LangChain框架,并重新利用了他们最近用来训练PaLM 2的数据。