一、Gemini 介绍
Gemini 是一个多模式模型系列,在图像、音频、视频和文本领域展示了真正强大的功能。其中功能最强大的模型 Gemini Ultra 在 32 个基准测试中的 30 个中提升了最先进水平,其中包括 12 个流行文本和推理基准测试中的 10 个、9 个图像理解基准测试中的 9 个、6 个视频理解基准测试中的 6 个以及 5 个语音基准测试中的 5 个识别和语音翻译基准。 Gemini Ultra 是第一个在 57 个科目的 MMLU 上达到人类专家表现且得分高于 90% 的模型。它还在新的 MMMU 多模态推理基准上取得了 62.4% 的新的最先进分数,比之前的最佳模型高出 5 个百分点以上。
介绍 Gemini:我们最大、最有能力的 AI 模型
Gemini 还是我们迄今为止最灵活的模型,它能够在从数据中心到移动设备的各种设备上高效运行。它的尖端技术能力将极大地改善开发者和企业用户使用 AI 构建和扩展应用的方式。
Gemini 模型建立在 Transformer 解码器之上,通过架构和模型优化的改进得到增强,以实现大规模稳定训练并在 Google 张量处理单元上进行优化推理。它们经过训练可支持 32k 上下文长度,采用高效的注意力机制(例如多查询注意力(Shazeer,2019))。
Gemini 有多种尺寸,包括两种版本的 Nano(专为手机等内存受限环境中的设备上使用而设计)、Pro(用于增强数据中心的性能和大规模可部署性)和 Ultra(用于高度复杂的环境)任务)。即使是较小的型号也非常棒!


1.1、产品集成
Gemini 目前已经集成到 Google 的许多产品中。
截至今天,Gemini Pro 型号现已为 Bard ( http://bard.google.com ) 提供支持。从 Bard 更新说明中可以知道,由于目前 Google Bard 新版中嵌入的 Gemini Pro 版本暂时只支持英文,所以大家在体验的时候可以用英文,中文效果会不太理想。

12 月 13 日,开发者可以通过 Google AI Studio 或 Google Cloud Vertex AI ( https://cloud.google.com/vertex-ai ) 上的 API 访问 Gemini Pro。 Android 开发者可以在 Pixel 8 Pro 上使用 Android Nano 尺寸。 明年初,Google 将完成对模型的进一步信任和安全检查,并通过额外的 RLHF 调整进一步完善它之后,将推出由 Gemini Ultra 模型提供支持的 Bard Advanced。作为其中的一部分,Google 将 Ultra 提供给选定的客户、开发人员、合作伙伴以及安全和责任专家,以便在更广泛地使用它之前进行早期实验和反馈。
1.2、多模态设计
Google从一开始就将 Gemini 设计为多模态,而不是从纯文本模型开始,然后在事后嫁接视觉和音频编码器。这意味着我们可以很自然地交错模式:说几句话,添加图像,添加一些文本,也许是短视频,同样,模型可以自然地交错文本和图像作为输出。
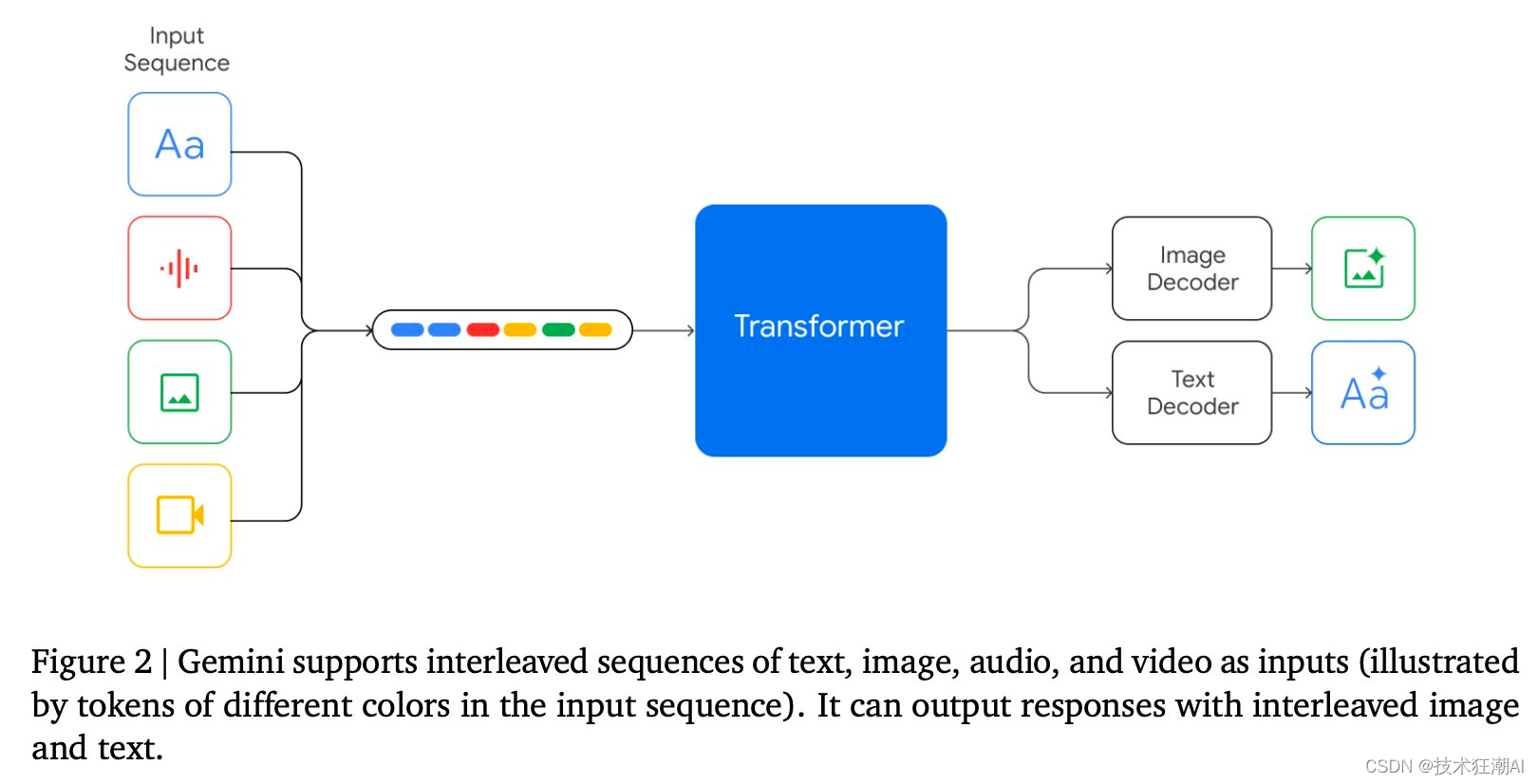
二、基准测试
MMMU 是上周刚刚发布的全新基准测试 ( https://mmmu-benchmark.github.io ),约有 11,500 个示例,需要图像理解、大学水平的学科知识和深思熟虑的推理。我们认为在这个基准测试中尝试 Gemini 模型来看看它们的表现会很有趣。凭借其多模式和推理功能,Gemini Ultra 远远超过了最先进的 GPT-4V。
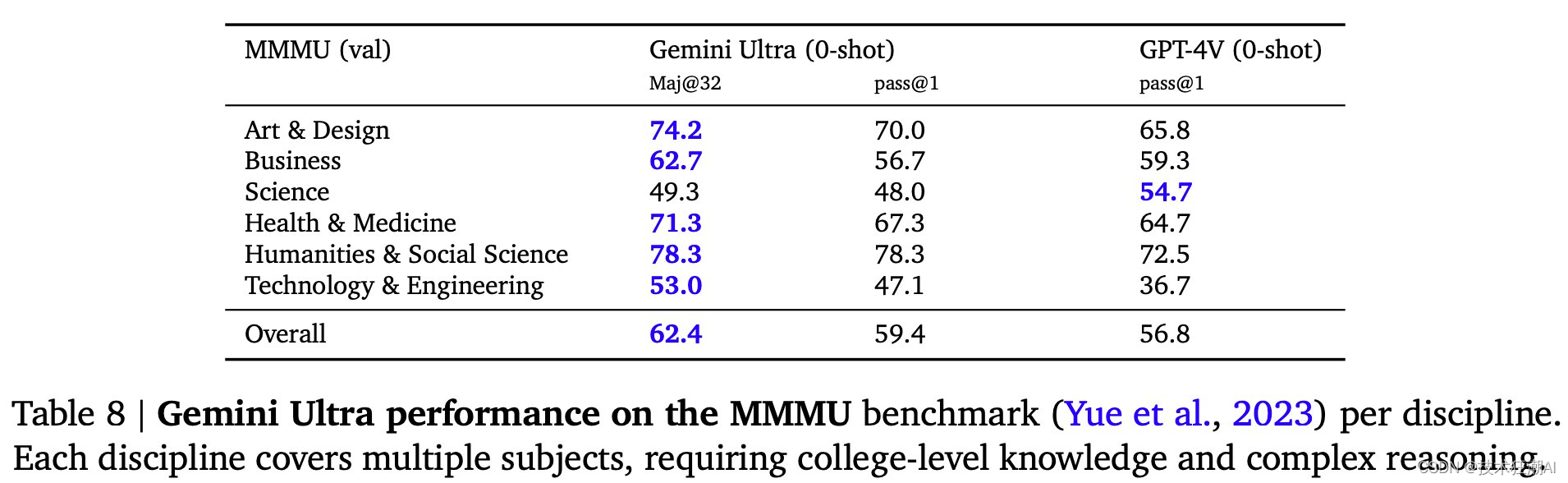
2.1、文本/编程能力
在各种文本、数学、编码和推理基准测试中,包括 MMLU、GSM8K、MATH、Big-Bench Hard、HumanEval、Natural2Code、DROP 和 WMT23,Gemini 均优于所有其他模型,并改进了现有模型艺术。在 MMLU 上,Gemini Ultra 是第一个在 57 个科目的 MMLU 上达到人类专家表现且得分高于 90% 的模型。
当使用 32 个样本的 CoT 时,Gemini Ultra 在 MMLU 上获胜 2.75%,但当使用 5 次提示时,以相同的差距输给 GPT-4。值得注意的是,G-Ultra 在编码任务方面似乎比 GPT-4 好得多。
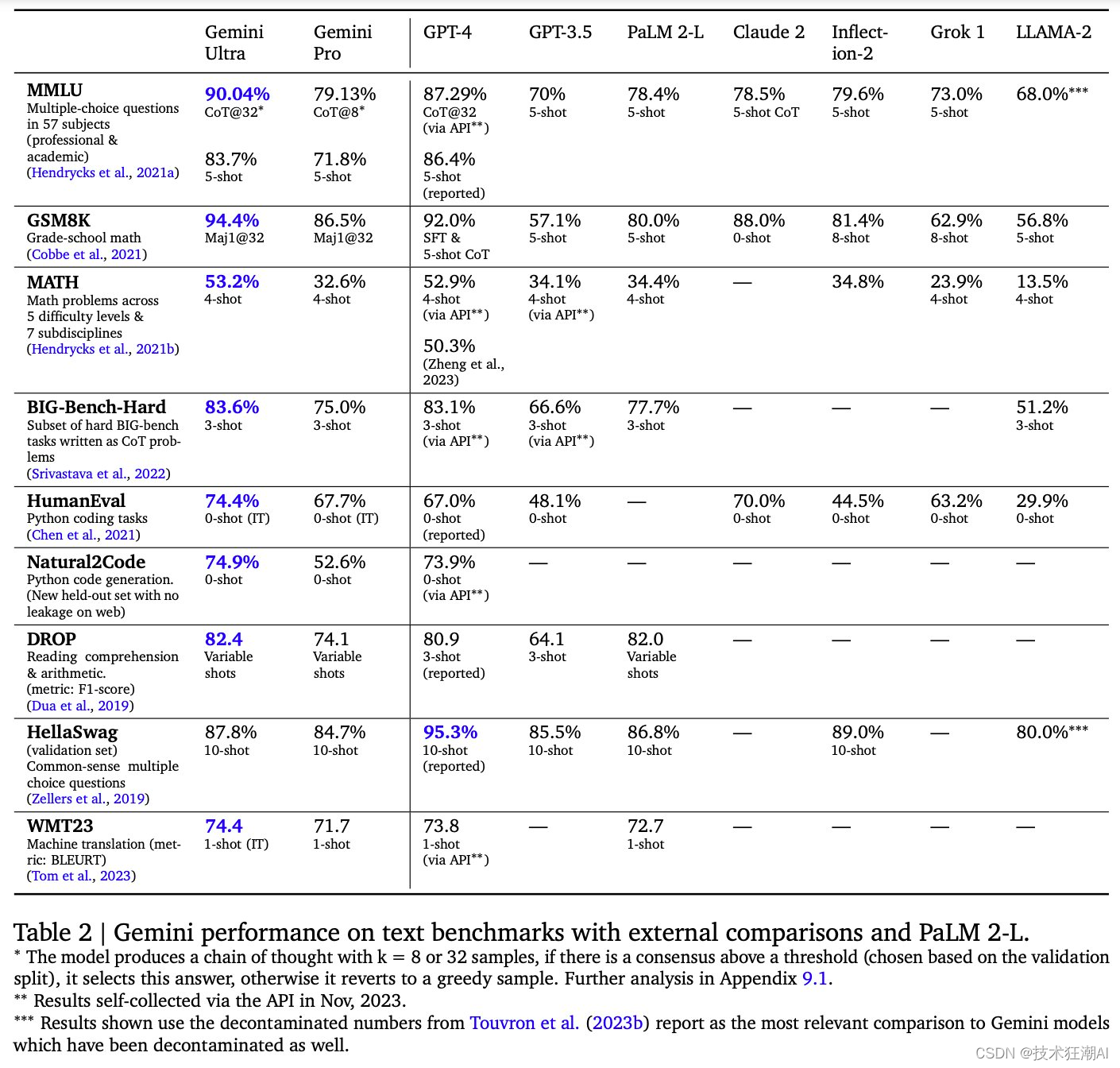
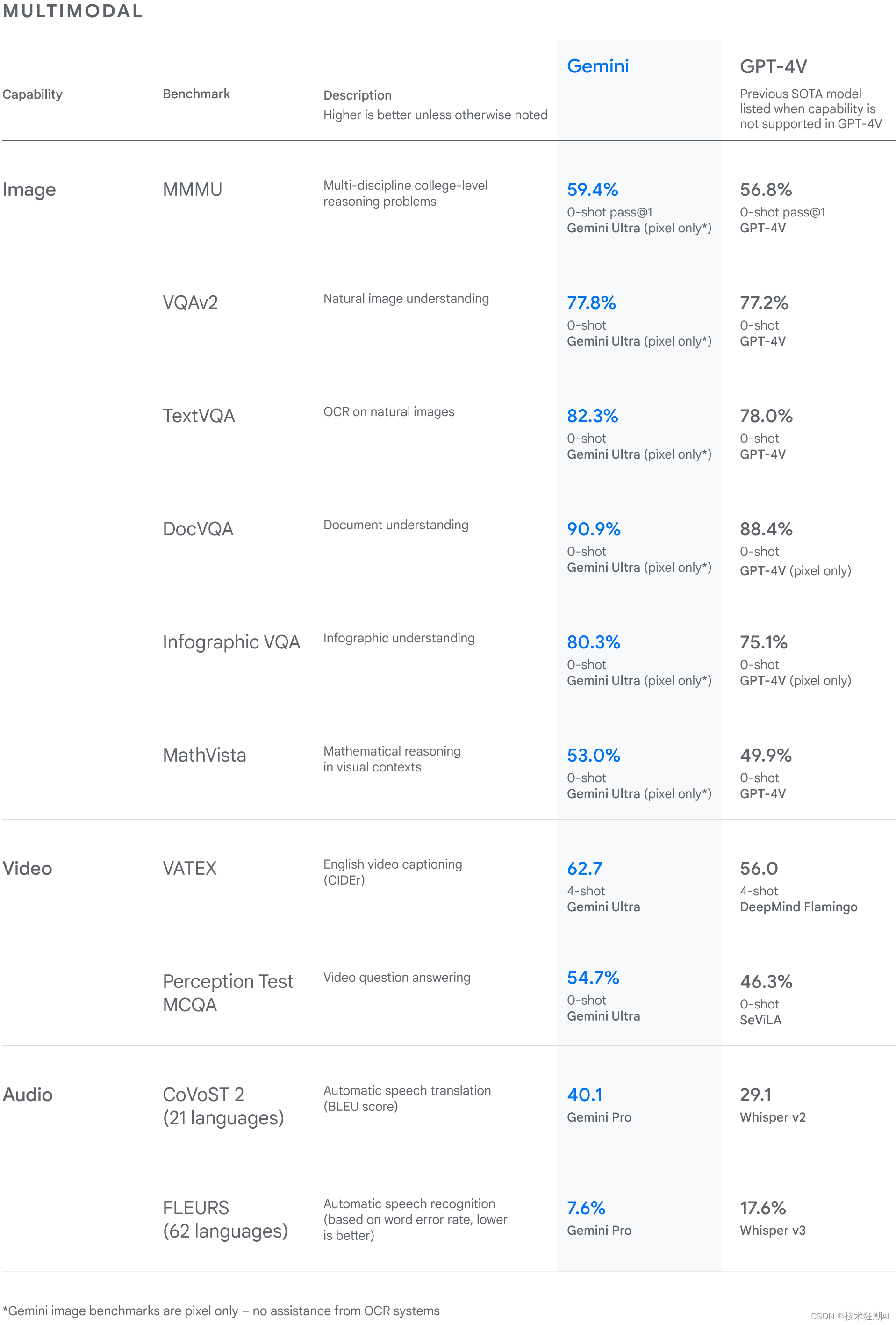
2.2、图像理解能力
在图像理解方面,Gemini 在我们检查的所有基准测试中都表现良好,Ultra 模型在每个基准测试中都创下了新的最先进结果。

2.3、多模态能力和推理能力
从发布的报告中的有个例子可以很好地说明 Gemini 的多模式能力和推理能力。
将此图像作为输入和提示:
“找出这些图表中突出的数据点及其含义。然后为显示的所有数据生成详细的降价表”
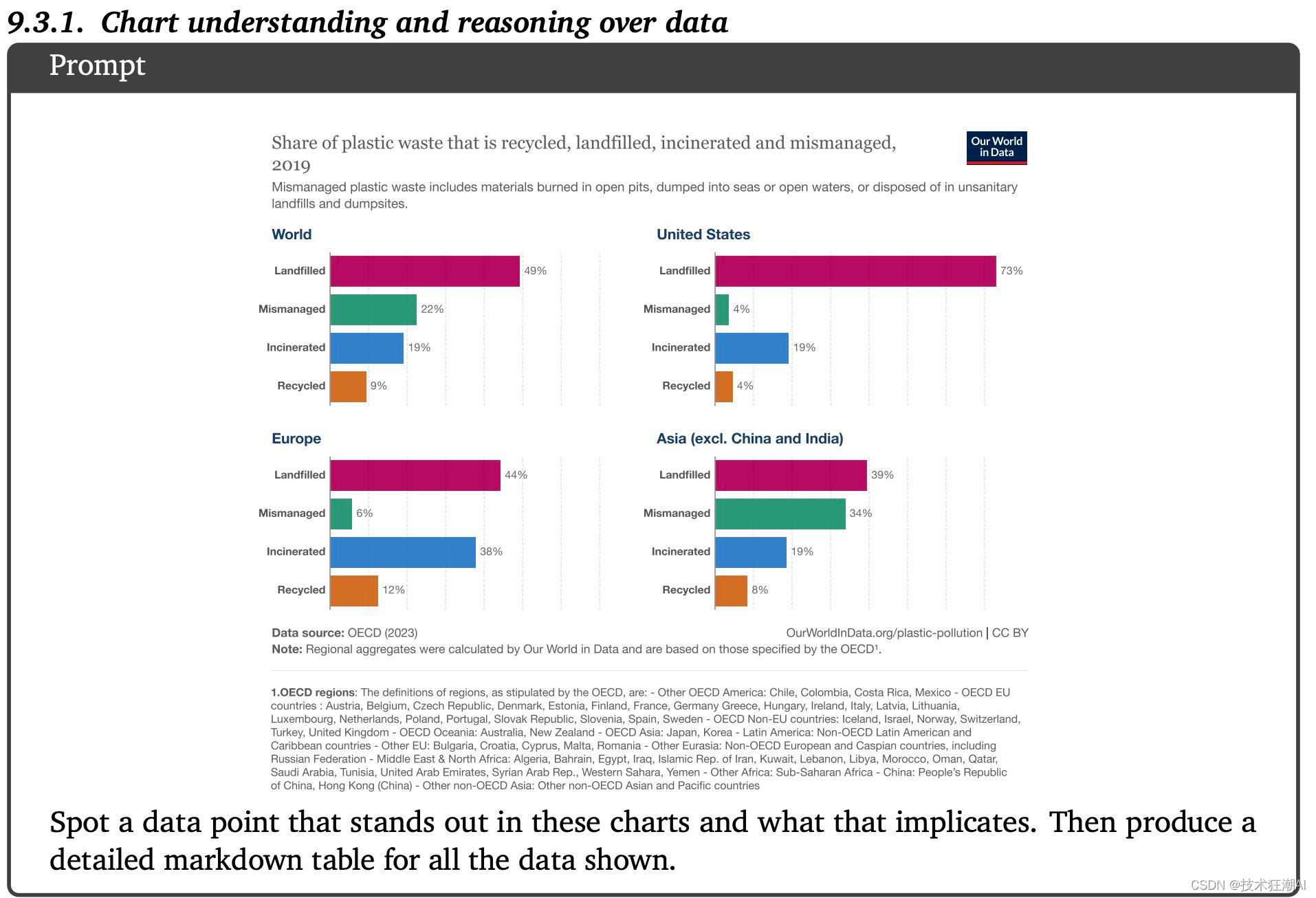
Gemini 能够产生如下所示的响应:
“最突出的数据点是美国填埋的塑料垃圾,占 73%。这明显高于显示的其他国家和地区。这意味着美国在回收或焚烧塑料废物方面没有像其他国家和地区那样做那么多。”
以及条形图中表示的每个数据点的渲染表格版本。

2.4、跨语言支持
Gemini 在跨多种不同语言的多语言图像理解任务中也表现出色。
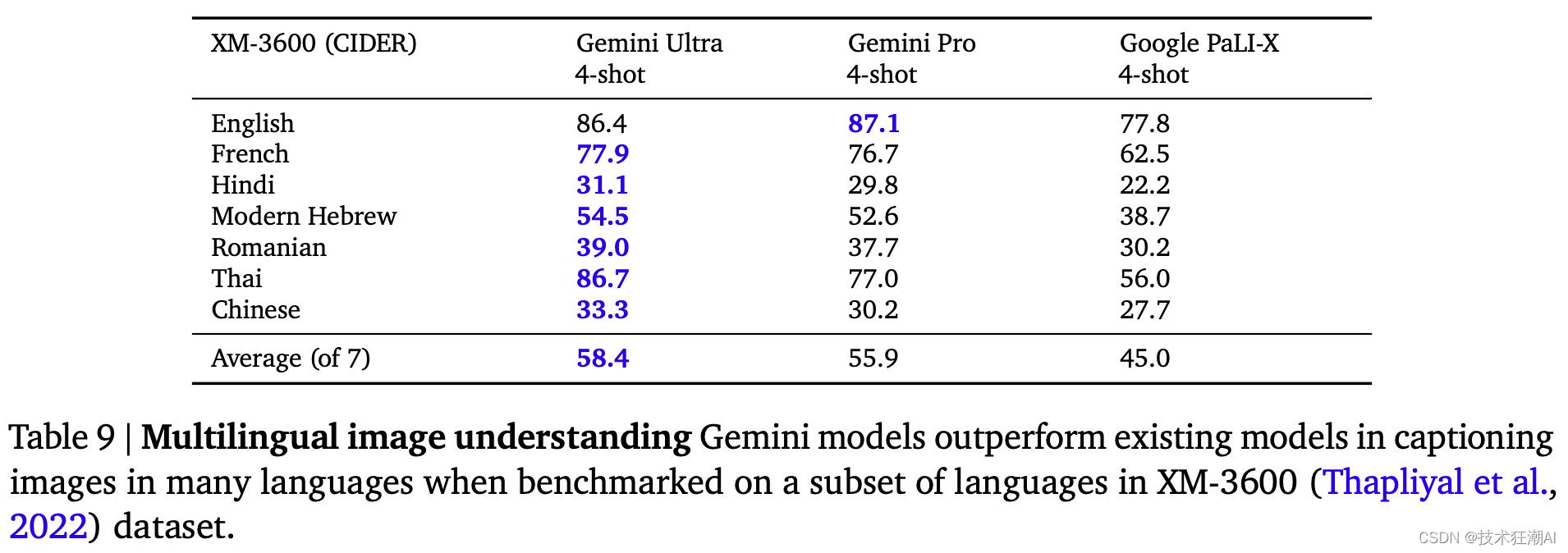
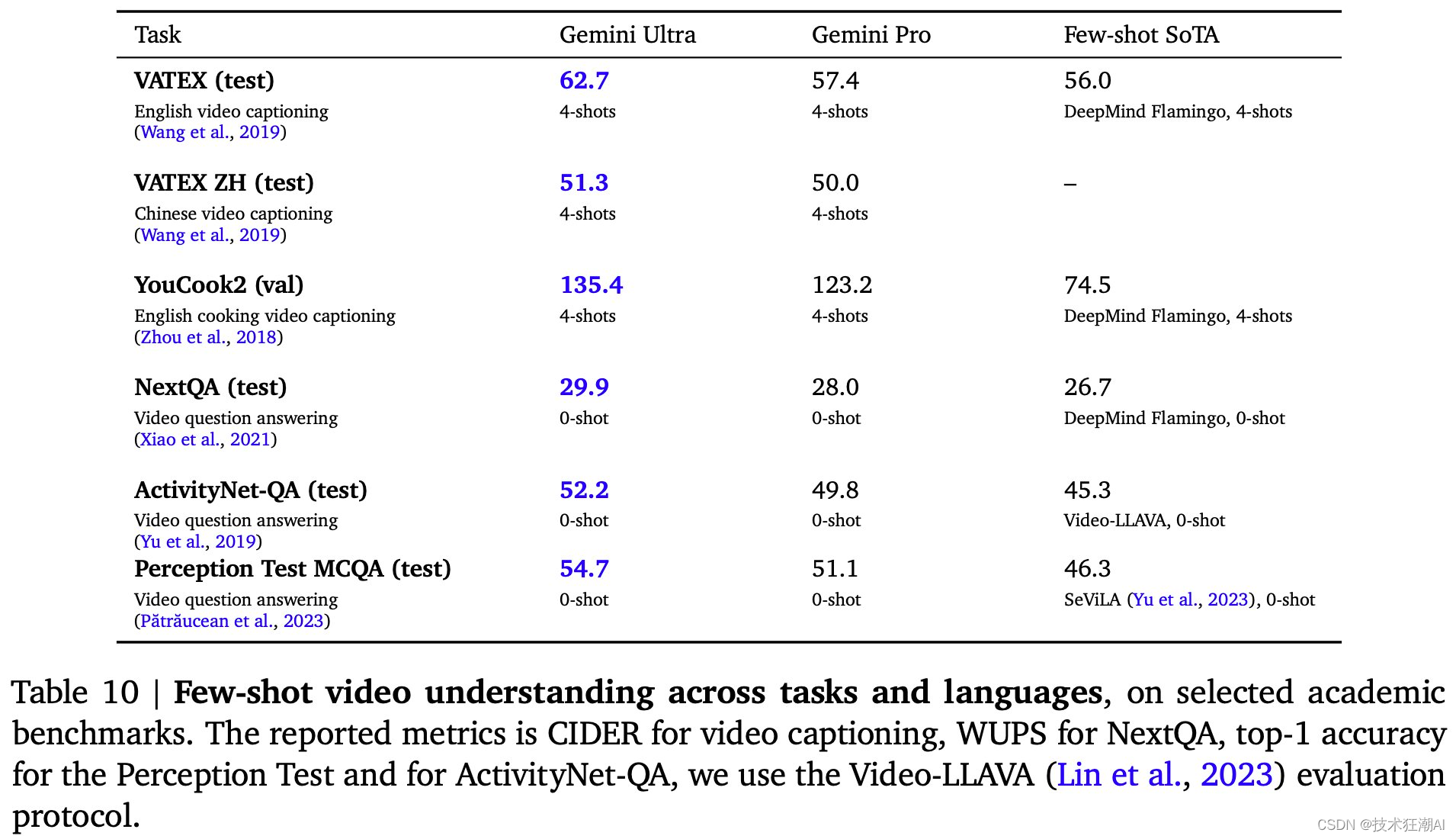
2.5、视频理解能力
Gemini Ultra 还在各种少镜头视频字幕任务以及零镜头视频问答任务中取得了最先进的结果。
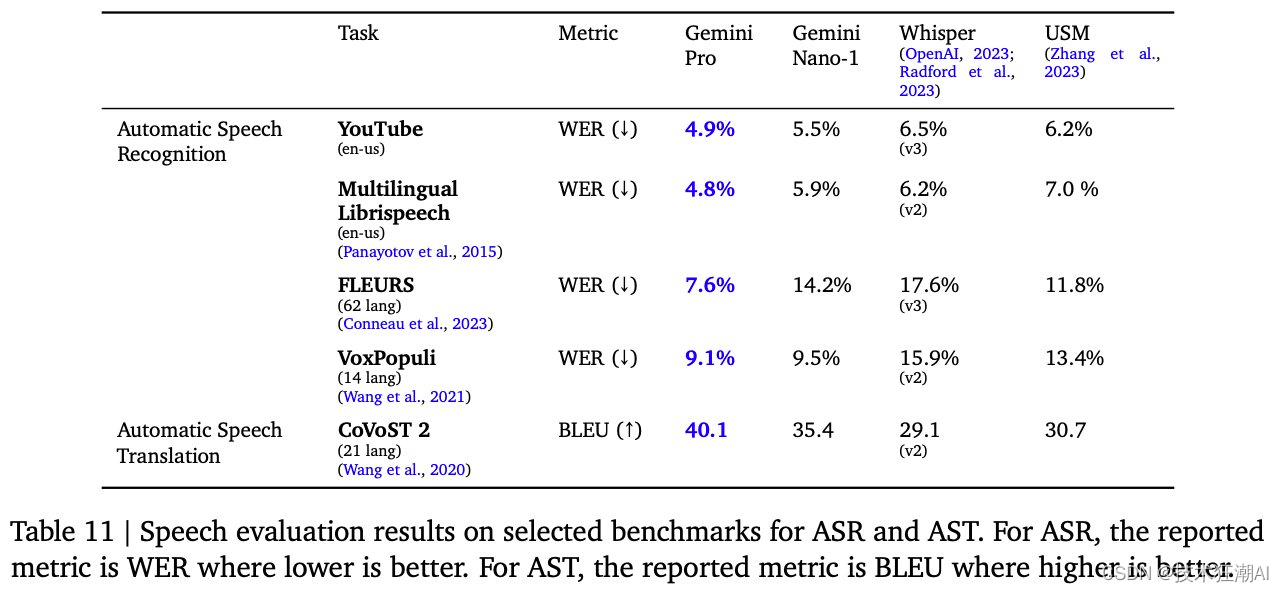
2.6、音频理解能力
在语音识别和语音翻译任务中,Gemini 也表现出色。我们尚未针对这些任务评估 Ultra 模型,但我们预计该模型规模的增加将产生比 Gemini Pro 模型更好的结果,Gemini Pro 模型已经在我们检查的所有五个基准中设定了新的最先进结果。
三、Gemini 特点
3.1、强劲的性能
Google 对 Gemini 模型进行了严格测试,并评估了它们在各种任务上的表现。从自然图像、音频和视频理解到数学推理,Gemini Ultra的性能在32个广泛使用的大型语言模型(LLM)研究和开发中的学术基准中有30项超过了当前的最新成果。
Gemini Ultra以90.0%的分数成为首个在MMLU(大规模多任务语言理解)上超越人类专家的模型,该模型使用数学、物理、历史、法律、医学和伦理学等57个学科的组合来测试世界知识和解决问题的能力。
Gemini 在文本基准测试上优于 GPT-4。但真的是这样吗?尽管结果令人印象深刻,但如果您注意使用相同提示技术(例如 Big-bench、Hellaswag 和 Math)报告的结果,您会发现性能差异很小。
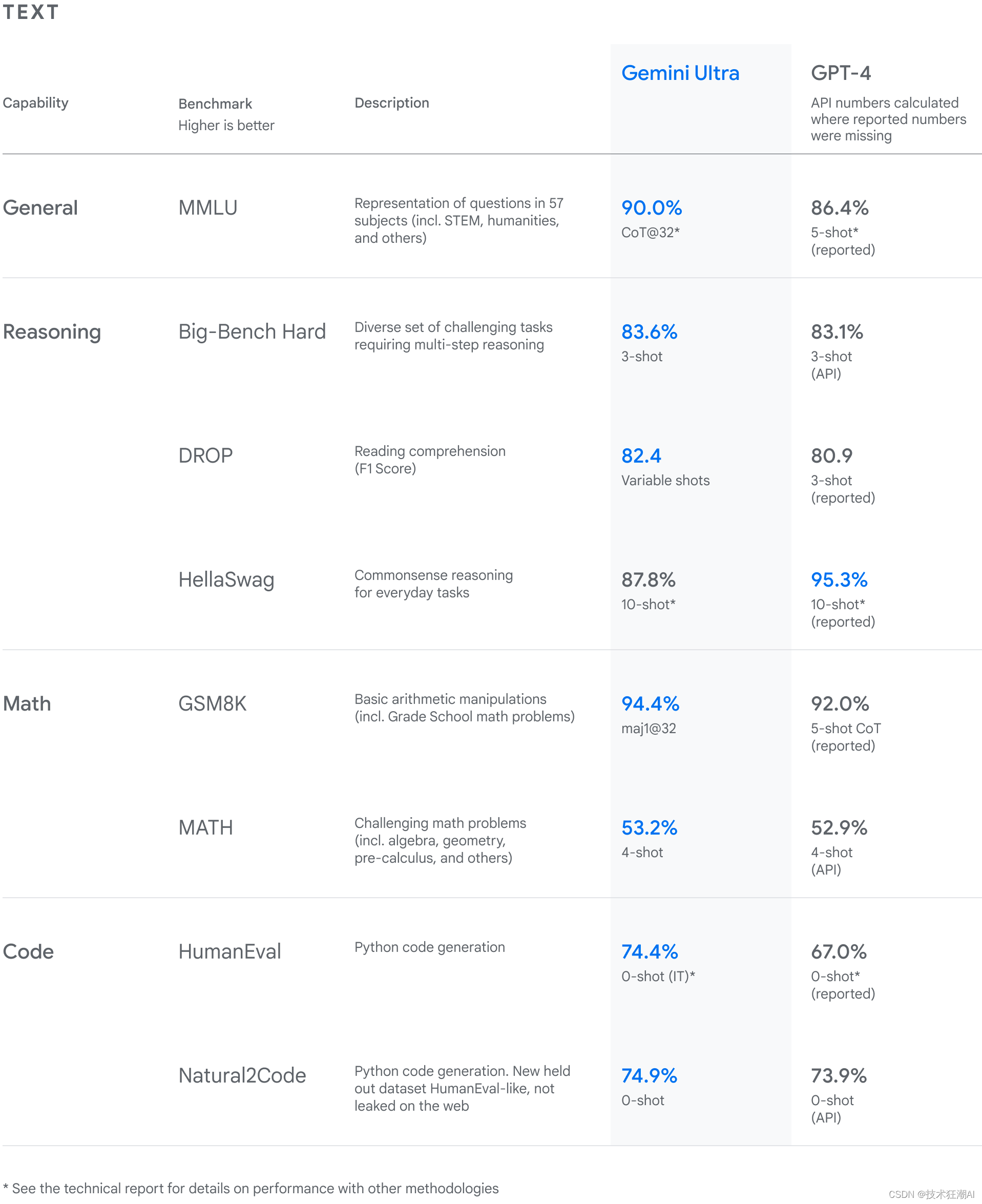
在新的 MMMU 基准测试中,Gemini Ultra 也取得了 59.4% 的高分。该测试包含了多个领域的多模态任务,需要深入的推理能力。 在我们测试的图像基准方面,Gemini Ultra 无需物体字符识别 (OCR) 系统的辅助,就超越了之前的尖端模型。这些基准测试突显了 Gemini 的天生多模态能力,并预示了其更为复杂的推理能力。
3.2、下一代模型能力
回想起我们曾经对多模态模型的那份笨拙拼接,它们虽能应对简单任务,如图像描述,但在抽象和复杂的逻辑推理面前却显得力不从心。如今,Google 以其创新精神,设计了Gemini——一个天生支持多模态的智能体。从摇篮期便在多种模态间游刃有余,它通过额外的多模态数据微调,其理解和推理的能力已远超过现有模型,成为各领域的领跑者。
一点一滴、细节之中,Gemini 1.0 展现了它处理复杂书面和视觉信息的能力。就如同在茫茫数据海洋中寻找那一线生机,它能洞察难以辨识的知识,无论是科学还是金融领域,都预示着数字化突破的曙光。
当我们谈论编程之美时,Google 的Gemini 展示了它在理解、解释、生成流行编程语言(比如 Python、Java、C++ 和 Go)方面的高超技艺。它跨语言的操作能力和对复杂信息的处理,让它在全球编程基础模型中脱颖而出。在多个编程基准测试中,包括行业标准的HumanEval和我们内部的Natural2Code数据集中,Gemini Ultra 的表现尤为出色。
不仅如此,Gemini 还可作为高级编码系统的动力核心。回想两年前我们推出了AlphaCode——首个在编程竞赛中达到竞争水平的AI代码生成系统。而今,借助Gemini专业版,我们打造了AlphaCode 2,它不仅擅长解决编程问题,更涵盖了复杂的数学和理论计算机科学难题。
到目前为止,创建多模态模型的标准方法涉及训练不同模态的单独组件,然后将它们拼接在一起,粗略模拟部分功能。这些模型有时可以很好地执行某些任务,比如描述图像,但在更概念化和复杂的推理方面表现不佳。
Google 设计了 Gemini,使其本能地支持多模态,从一开始就在不同的模态上进行了预训练。然后,我们使用额外的多模态数据对其进行了微调,以进一步提高其效果。这有助于Gemini从根本上无缝地理解和推理各种输入,远远优于现有的多模态模型——而且它的能力在几乎每个领域都是最先进的。
3.2.1、复杂推理能力
Gemini 1.0的复杂多模态推理能力可以帮助理解复杂的书面和视觉信息。这使它在发现在大量数据中难以辨别的知识方面具有独特的技能。
它惊人的能力通过阅读、过滤和理解信息从数十万份文件中提取见解,将有助于在从科学到金融等许多领域以数字速度实现新突破。
Gemini 揭示新的科学见解
3.2.2、理解文本、图像、音频等
Gemini 1.0 能够同时处理和理解文本、图像、音频等多种信息,这使它在理解复杂话题上更加细腻,能够回答那些涉及到复杂主题的问题。它在解释数学和物理等复杂科目的推理过程方面表现尤为出色。
Gemini 在数学和物理学方面的解释能力
3.2.3、高级编程
Google 推出首个版本的 Gemini 能够理解、解释并生成世界上最受欢迎编程语言(例如 Python、Java、C++ 和 Go)的高质量代码。其跨语言操作能力和对复杂信息的处理使其成为全球领先的编程基础模型之一。
Gemini Ultra 在多个编程基准测试中表现卓越,其中包括 HumanEval —— 一个评估编程任务性能的重要行业标准,以及我们的内部数据集 Natural2Code,该数据集使用作者生成的来源而不是基于网络的信息。
Gemini也可以用作更高级编码系统的引擎。两年前,我们推出了AlphaCode,这是第一个在编程竞赛中达到竞争水平的AI代码生成系统。
利用Gemini的专业版本,创建了一个更先进的代码生成系统AlphaCode 2,它擅长解决超越编码的竞赛编程问题,涉及复杂的数学和理论计算机科学。
Gemini 在编码和竞赛编程方面表现出色
在与原版 AlphaCode 相同的平台上进行评估时,AlphaCode 2 展现了显著提升,解决问题数量几乎翻倍。估计其性能超过了 85% 的竞赛参与者,相较于 AlphaCode 的近 50% 有显著提高。当程序员与 AlphaCode 2 协作,为代码样本定义特定属性时,其表现更为出色。
3.3、更加可靠、可扩展和高效
Google 在自家AI优化基础设施上,借助内部设计的Tensor处理单元(TPU)v4和v5e对Gemini 1.0进行了大规模训练。这不仅是我们最稳固和可扩展的训练模型,同时也是效率最高的服务模型之一。
在TPU上运行时,Gemini 的速度远超以往那些小巧但功能有限的模型。这些专为AI加速而生的处理器已成为Google众多AI驱动产品的核心——从搜索到YouTube、Gmail、Google地图、Google Play和Android——为全球数十亿用户提供服务,并帮助世界各地的公司以成本效益的方式训练大型AI模型。
此外,Google 还发布了迄今为止最强大、高效和可扩展的TPU系统Cloud TPU v5p。这一代TPU将加速Gemini 的发展,并助力开发者及企业客户更快速地训练大规模生成式人工智能模型,让新产品和功能更快地触达用户。

3.4、以责任和安全为核心构建
Google 始终致力于推动大胆而负责任的人工智能发展。基于谷歌的人工智能原则和我们产品的健全安全政策,Google 为Gemini增设了新的保护措施,以适应其多模态能力。在开发每一个阶段,我们都深思熟虑潜在风险,并致力于测试和减轻这些风险。
Gemini 经历了谷歌AI模型中最全面的安全评估,覆盖了偏见和毒性等关键问题。我们开展了针对网络攻击、说服力及自主性等新颖研究领域的探索,并应用了谷歌研究中最先进的对抗测试技术,在部署前提前识别关键安全问题。
为了更好地发现评估方法中可能存在的盲点,谷歌正与一系列多元化的外部专家和合作伙伴合作,对Gemini 进行各种问题上的压力测试。在训练阶段,我们通过使用真实有毒提示等基准来诊断内容安全问题,并确保其输出符合我们的政策。
为了减少可能造成的伤害,谷歌建立了专门的安全分类器来识别、标记和分类暴力或负面刻板印象内容。这种分层方法结合了强大的过滤器,使Gemini 对每个人都更加安全和包容。同时,我们将持续应对模型所面临的事实性、基础性、归因性和协作性等已知挑战。
责任和安全始终是我们模型开发和部署的核心。这是一项长期承诺,需要合作建设,因此我们正在与行业和更广泛的生态系统合作,通过组织如MLCommons、Frontier Model Forum及其AI安全基金以及我们的安全AI框架(SAIF)来定义最佳实践,并制定安全和安全基准,该框架旨在帮助减轻公共和私营部门AI系统特定的安全风险。在开发Gemini的过程中,我们将继续与全球的研究人员、政府和民间社会团体合作。
3.5、让Gemini面向全世界
Gemini 1.0现在正在一系列产品和平台上推出:
3.5.1、谷歌产品中的Gemini专业版
通过谷歌产品将Gemini 带给数十亿人。
从今天开始,Bard将使用Gemini Pro的精细调整版本进行更高级的推理、规划、理解等。这是Bard自推出以来最大的升级。
它将在全球170多个国家和地区提供英文版本,并计划在不久的将来扩展到不同的模式,并支持新的语言和地点。
还将Gemini引入Pixel。Pixel 8 Pro是第一款专为运行Gemini Nano而设计的智能手机,它为录音应用中的“摘要”功能和Gboard中的智能回复功能提供支持,首先在WhatsApp中推出,明年将在更多的消息应用中推出。
在未来几个月里,Gemini 将会在我们的更多产品和服务中推出,比如搜索、广告、Chrome 和 Duet AI。
已经开始在搜索中尝试Gemini,它使我们的搜索生成体验(SGE)对用户更快,在美国英语搜索中延迟减少了40%,同时提高了质量。
3.5.2、使用Gemini构建产品
从12月13日开始,开发人员和企业客户可以通过Google AI Studio或Google Cloud Vertex AI中的Gemini API访问Gemini Pro。
Google AI Studio是一个免费的基于网络的开发者工具,可帮助开发者和企业客户快速使用API密钥原型设计和推出应用程序。当需要完全托管的AI平台时,Vertex AI允许通过完全数据控制对Gemini进行定制,并从Google Cloud的其他功能中获益,以提高企业安全性、安全性、隐私和数据治理以及合规性。
Android开发者还可以通过AICore在Android 14上的Pixel 8 Pro设备上使用我们最高效的Gemini Nano模型进行设备任务构建。立即注册AICore的早期预览。
3.5.3、Gemini Ultra 即将推出
对于 Gemini Ultra,我们目前正在进行广泛的信任和安全检查,包括由可信赖的外部方进行红队测试,并在向人类反馈的基础上进一步完善模型,使用微调和强化学习,然后才会广泛推出。
作为这一过程的一部分,我们将使Gemini Ultra提供给一些特定的客户、开发者、合作伙伴以及安全和责任专家进行早期实验和反馈,然后在明年初向开发者和企业客户推出。
明年初,我们还将推出Bard Advanced,这是一种全新的、尖端的人工智能体验,让您可以使用我们最好的模型和能力,首先是Gemini Ultra。
3.5.4、Gemini 时代:开启创新未来之门
这是 AI 发展的关键里程碑,也标志着我们 Google 迈入了一个全新时代。我们将继续快速创新,并负责任地提升我们的模型能力。
我们已经在 Gemini 上取得了重大进展,并正在努力进一步拓展其未来版本的能力,如在规划和记忆方面的提升,以及增加处理更多信息的上下文窗口,以便提供更佳的响应。
我们对 AI 负责任地赋能世界所带来的巨大潜力感到兴奋。这是一个充满创新的未来,它将激发创造力,拓展知识,推动科学发展,并改变全球数十亿人的生活和工作方式。
四、模型训练
Gemini 是一项大规模的科学和工程工作,需要 ML、分布式系统、数据、评估、RL、微调等方面的各种不同专业知识(该报告的 800 多名作者)。最大的 Gemini 模型在大量 TPUv4 pod 上进行训练。它构建在 JAX 和 Pathways 系统 ( https://arxiv.org/abs/2203.12533 ) 之上,这使我们能够从单个 Python 进程跨多个数据中心的大量 TPUv4 Pod 协调大规模训练计算。
Gemini Ultra 的训练基础设施非常令人着迷,Gemini 在多个数据中心的多个 TPUv4 Superpod(4096 个 TPU)上并行训练数据。疯狂的是,他们的网络速度足以在多个数据中心之间同步梯度,而不会显著降低训练效率。

五、References
[1]. Gemini 官方介绍
https://blog.google/technology/ai/google-gemini-ai/#sundar-note
[2]. Gemini 技术报告
https://goo.gle/GeminiPaper
[3]. 多模式提示推理
https://developers.googleblog.com/2023/12/how-its-made-gemini-multimodal-prompting.html