前天谷歌DeepMind新发布的Gemini模型刷屏了,大家是不是也和奶茶一样被Gemini的效果震撼到了。觉得谷歌终于又“可以”了,第一个超越GPT-4的模型终于出现了!
然而,仅仅不到一天,谷歌Gemini就翻车了——网友们在仔细分析谷歌宣布的评测效果时,发现Gemini用了很多小动作,疑似“胜之不武”!存在刻意刷榜、夸大性能的嫌疑,演示视频也被扒出是“合成造假”...
大模型研究测试传送门
GPT-4传送门(免墙,可直接测试,遇浏览器警告点高级/继续访问即可):
http://hujiaoai.cn
而且,谷歌已经承认Gemini视频是“剪出来”的。

这到底是什么情况呢?奶茶带大家来一起“吃吃瓜”。
测评存在“猫腻”
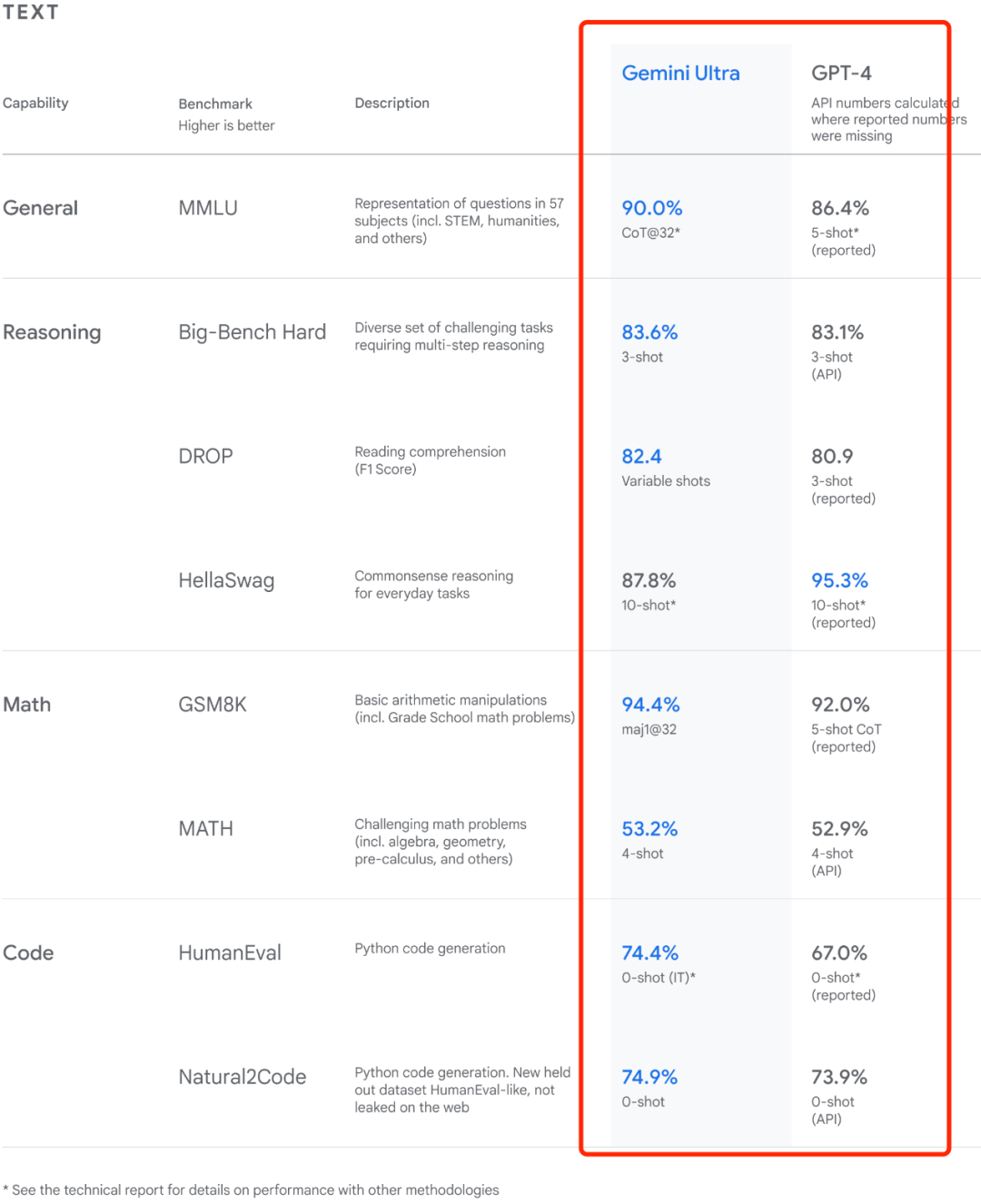
首先在MMLU基准测试中,Gemini Ultra打榜的表现不光超越GPT-4,甚至超越了人类专家。
然而,Gemini的这一表现依赖于CoT@32方法,该方法意思是谷歌使用了思维链提示技巧、每个问题回答32次选出其中出现次数最多的那个答案作为输出。

好家伙,这不是耍流氓吗?这就好比同样是数学考试,GPT-4只有笔和演草纸了,而Gemini却带着计算机。
相比之下,使用不带思维链prompt的标准5-shot方法,GPT-4的性能实际要优于Gemini(86.4%对比83.7%),即在常规MMLU 官方评测中Gemini不如 GPT-4)
谷歌相当于创造了一种CoT@32方法来宣称Gemini的性能优于GPT-4,这种方法很难不受质疑。
网友辣评:"是找了一种特殊的 CoT 方式“看上去”超过了 GPT-4。"
如下图第二列对比,如果让GPT-4也使用CoT@32,效果则超过Gemini!
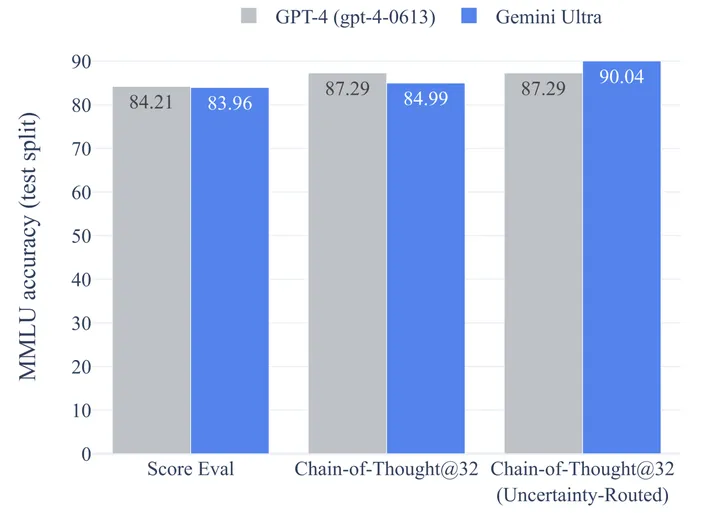
除此之外,如上图第三列显示,将未对齐的Gemini模型与已经对齐的GPT-4进行比较是不公平的。GPT-4的报告曾经明确指出,模型对齐会降低了知识方面的能力。那么采用未对齐的Gemini和对齐的GPT-4的比较是明显犯规的!
最后,就算谷歌没有搞小动作,假如下表的测试都是公平公正的,Gemini Ultra 也仅比 GPT-4性能高几个百分点,而 GPT-4 其实是 OpenAI在去年8月完成的工作,这意味着谷歌现如今最强大的AI模型仅比 OpenAI 至少一年前完成的工作进行了有限的改进,而且还是对齐后的GPT-4。
演示视频系剪辑合成
相信大家昨天都看到了Gemini的效果演示视频,那叫一个丝滑和惊艳啊!
然而,昨天,国外一位研究员在推特上发布声明,暗示视频中展示的是精心挑选的好结果,而且视频并不是实时录制而是事后剪辑的。
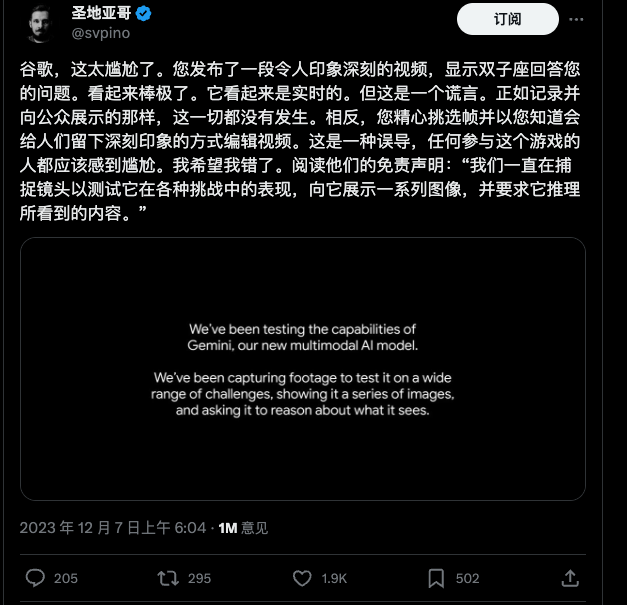
后来谷歌也在一篇博客文章中解释了多模态交互过程,隐隐约约地承认使用静态图片和多段提示词拼凑,才能达成这样的效果。
谷歌在YouTube描述中承认该视频经过编辑:“出于演示的目的,为了简洁起见,延迟已经减少,Gemini 输出的时间也被缩短,”。
这意味着 Gemini 每次响应所花费的时间实际上比视频中的时间要长。
事实上,演示不是实时进行的,或语音进行的。当彭博社问及该视频时,谷歌发言人表示,该视频是通过“使用视频中的静态图像帧并通过文本提示”制作的, 一篇博客展示了其他人如何通过双手照片与双子座进行互动,或图画或其他物体。
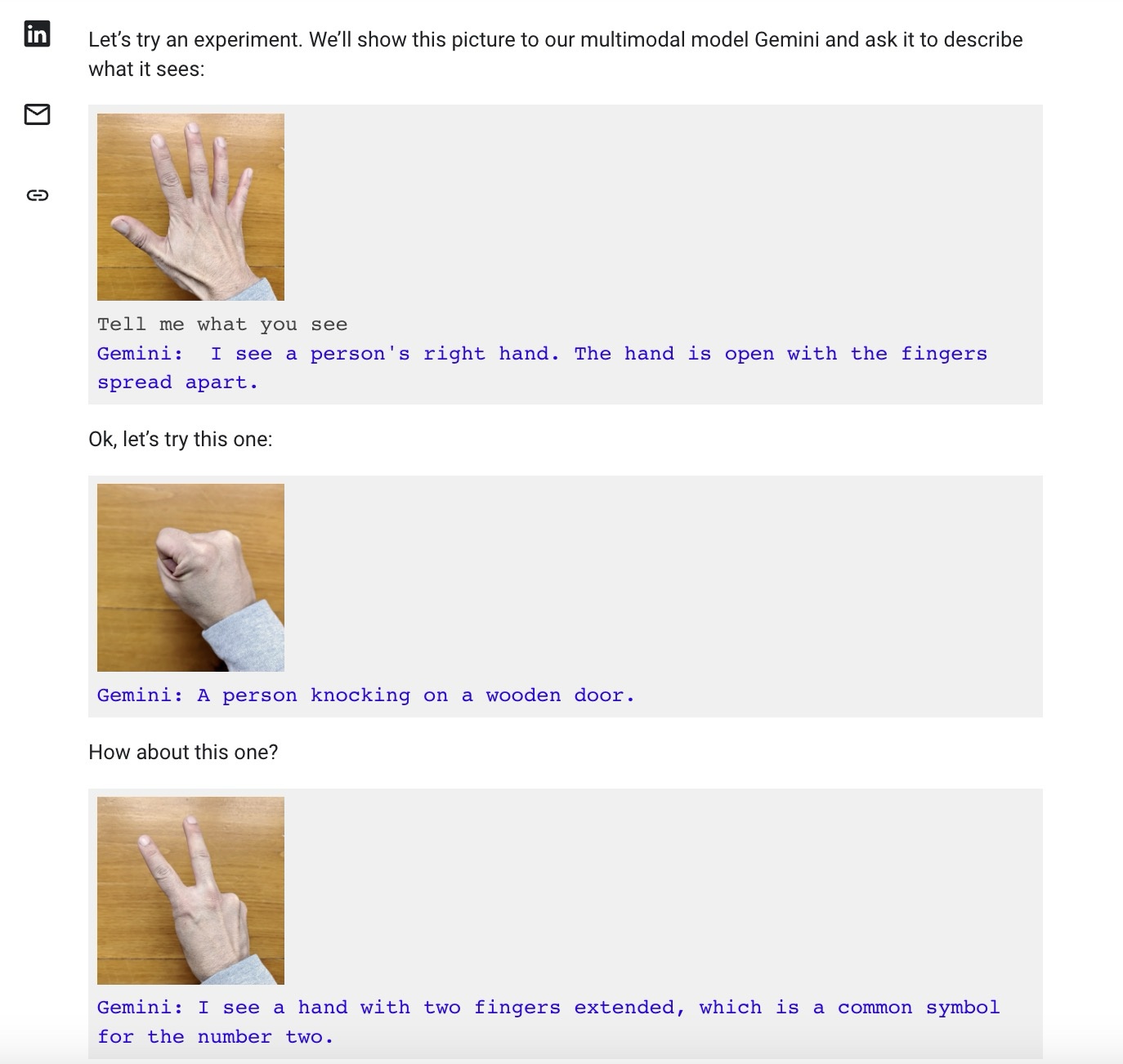
换句话说,演示中的声音正在读出他们向双子座发出的人造提示,并向他们展示静态图像。这与谷歌似乎暗示的完全不同:当 Gemini 实时观察周围的世界并做出反应时,一个人可以与 Gemini 进行流畅的语音对话。
好家伙,原来你也搁这录视频呢!

而且,谷歌在视频中也没有明确指出,这次演示可能是使用了还未上市的 Gemini Ultra 模型(预计明年上市)。谷歌对于接踵而至的批评回应到,视频很多是概念性的,而不是Gemini当前能力的真实反映。
好家伙,比概念的话你和GPT4比啥啊,应该GPT5打啊,估计明年也出了!
