拟合算法的介绍
拟合和插值问题的对比
- 回顾:【数模】插值算法
- 不同:
- 插值算法: 得到的多项式f(x)要经过所有样本点。
- 但若样本点太多,则该多项式次数过高,就会造成龙格现象。
- 拟合问题:不用曲线一定经过给定的点。
- 尽管分段可避免龙格现象,但多数情况更倾向得到确定曲线(即使其不经过每个样本点,但只要误差足够小即可 ⇒ 即拟合思想)
- 插值算法: 得到的多项式f(x)要经过所有样本点。
拟合问题的目标
- 寻求一个函数(曲线),使得该曲线在某种准则下与所有的数据点最为接近 ⇒ 即曲线拟合的最好(最小化损失函数)
- 拟合的结果:得到一个确定的曲线
具体示例
- 题目:
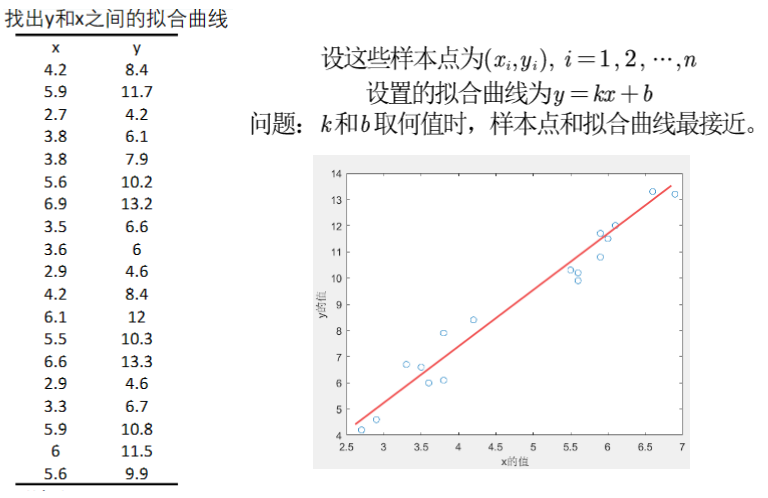
最小二乘法确定拟合曲线
- 采用最小二乘法,找到使样本点和拟合曲线最接近的k和b
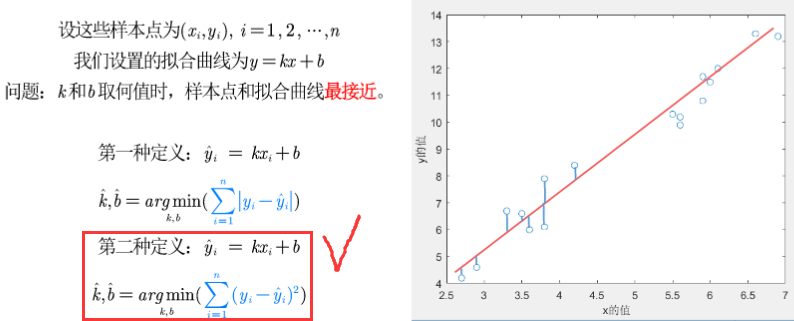
- 常见疑问:
- 为什么第一种定义要加绝对值呢?
- 绝对值表拟合曲线的y与实际y值的距离,若不加绝对值,会导致正负相抵消。
- 为什么采用第二种定义中的二次方而不用第一种定义中的绝对值呢?
- 因为有绝对值不容易求导,计算比较复杂。故不采用绝对值。
- 为什么采用二次方而不是三次方/四次方呢?
- 不采用奇数次方的原因:避免误差正负相抵。
- 不采用四次方:
- ①避免极端数据对拟合曲线的影响(如为了迎合极端数据,而过于偏离最接近的拟合曲线)。
- ②最小二乘法得到的结果和MLE极大似然估计一致。
- 为什么第一种定义要加绝对值呢?
matlab求解最小二乘
- 由上计算得 k和b的求解式子:
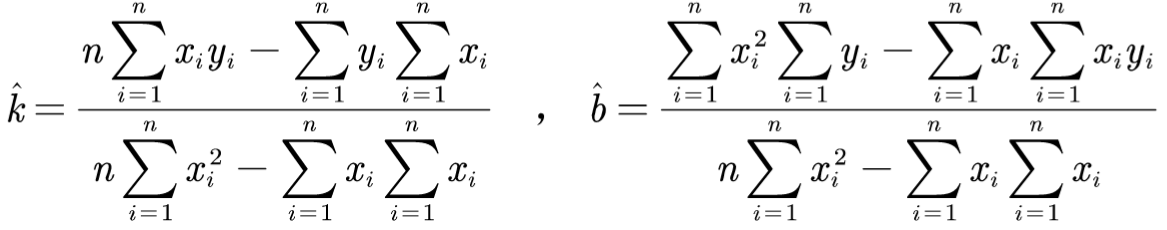
- 具体代码如下:
clear;clc
load data1
plot(x,y,'o')
% 给x和y轴加上标签
xlabel('x的值')
ylabel('y的值')
n = size(x,1);
k = (n*sum(x.*y)-sum(x)*sum(y))/(n*sum(x.*x)-sum(x)*sum(x))
b = (sum(x.*x)*sum(y)-sum(x)*sum(x.*y))/(n*sum(x.*x)-sum(x)*sum(x))
hold on % 继续在之前的图形上来画图形
grid on % 显示网格线
f=@(x) k*x+b;
fplot(f,[2.5,7]);
legend('样本数据','拟合函数','location','SouthEast')
matlab中的操作细节
- ①将excel中数据复制进matlab工作区时:注意不要把标头也复制进去
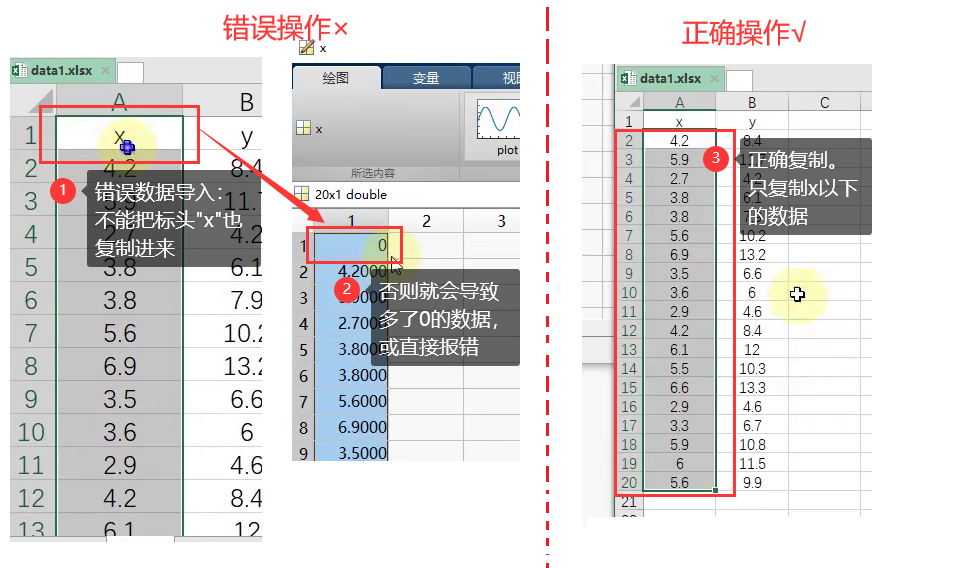
- ②保存工作区变量x和y:
拟合优度(可决系数)R² ⇒ 评价拟合好坏
介绍SST、SSE、SSR和R²
-
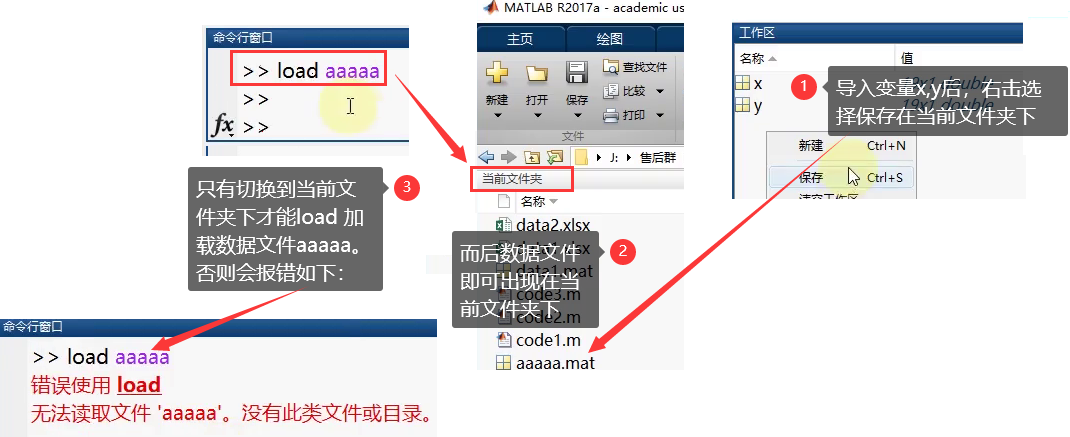
总体平方和SST:
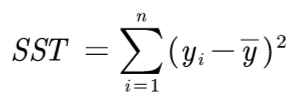
-
误差平方和SSE:
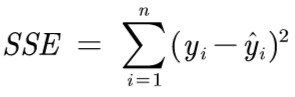
- SSE会存在量纲的影响(如y单位是万元和元时,结果不同)
- 对SSE取舍的思考:
- 拟合函数f(x)越复杂(次数越高),SSE越小(如用二元比用一元SSE小),但采用拟合初心是为了找到相对简单的模型。
- 选用的拟合函数:要简单(不能为了让SSE尽量地小,而选用非常复杂的拟合函数)
-
回归平方和SSR:
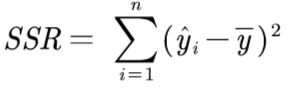
-
可证:
SST = SSE + SSR -
拟合优度R²:
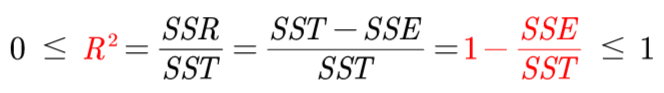
- R²越接近1,说明误差平方和越接近0,误差越小 ⇒ 说明拟合的越好。
- 注意:R²只能用于拟合函数是 线性函数 时 ,拟合结果的评价 ⇒ 不滥用R²(除非拟合函数能确定是线性函数,否则老实用SSE)
- 线性函数和其他函数(例如复杂的指数函数)比较拟合的好坏,直接看误差平方和SSE即可
- R²也可能出现负数,负数时更暗示
SST = SSE + SSR不成立
-
线性函数的介绍:
- 此处的线性函数是指 对参数为线性(线性于参数) :在函数中,参数仅以一次方出现,且不能乘以或除以其他任何的参数(如:
y=a/(x-b)²;不是线性函数),并不能出现参数的复合函数形式(如:y=asin(b+cx)不是线性函数)。 - 故 y = a + bx² 和 y= eβ1+β2x ,也是线性函数(因为参数都是1次幂,且不存在乘/除/复合形式)
- 此处的线性函数是指 对参数为线性(线性于参数) :在函数中,参数仅以一次方出现,且不能乘以或除以其他任何的参数(如:
计算拟合优度的代码
y_hat = k*x+b; % y的拟合值
SSR = sum((y_hat-mean(y)).^2) %回归平方和
SSE = sum((y_hat-y).^2) %误差平方和
SST = sum((y-mean(y)).^2) %总体平方和;mean()是求均值的函数。
SST-SSE-SSR
R_2 = SSR / SST
- SST-SSE-SSR计算结果为5.6843e-14=5.6843*10^(-14) ⇒ matlab浮点数计算的误差(极小可以忽略)
matlab曲线拟合工具箱的使用
- 打开方式:
- ①
- ②
- ①
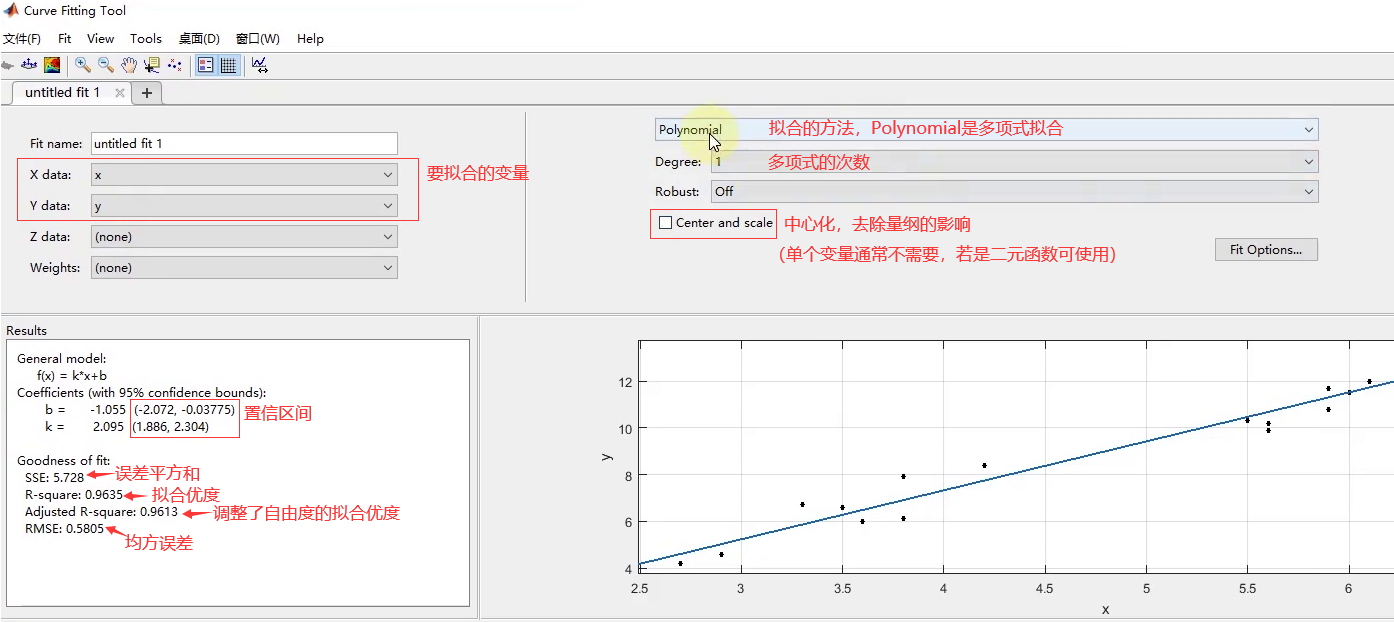
- 拟合工具箱的介绍:
- Adjusted square:调整后的拟合优度。⇒ #待补充(学习回归时)
- RMSE:均方误差 。⇒ #待补充(学习预测模型时)
- 拟合方法的选择有多种,以下是两种常见的:
- Polynomial:多项式拟合。(可以自定义多项式次幂)
- Custom Equation:自定义拟合方程。
- 如:
y=f(x)=k*x+b; 和y=f(x)=a+b*x+c*x^2⇒ 自己权衡
- 如:
- 中心化公式:
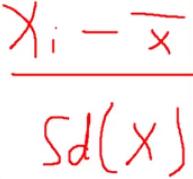
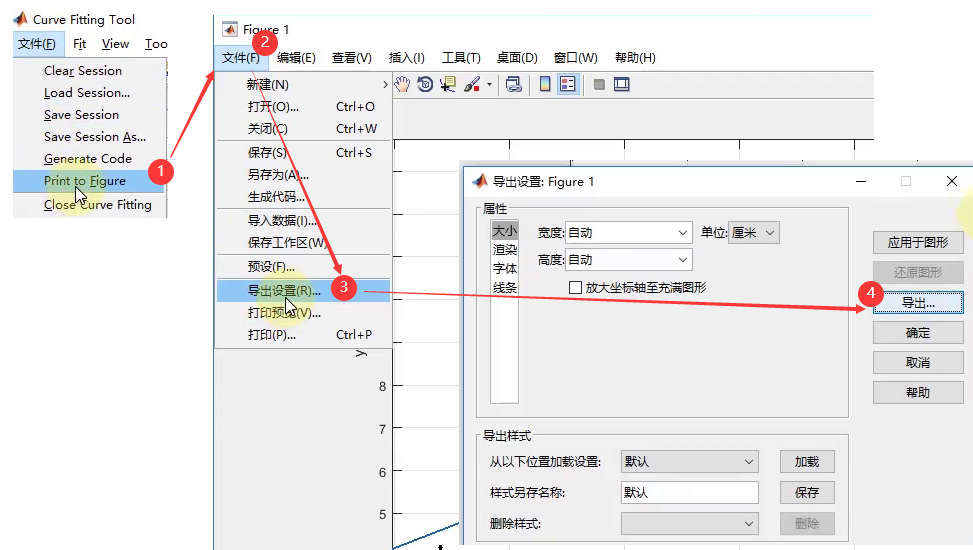
- 存图方式
- ①截图(可能不够高清)
- ②高清导出(图片清晰度可以在“导出设置→渲染→分辨率”中调整,分辨率越高,图越清晰,相对于图片文件大小更大)
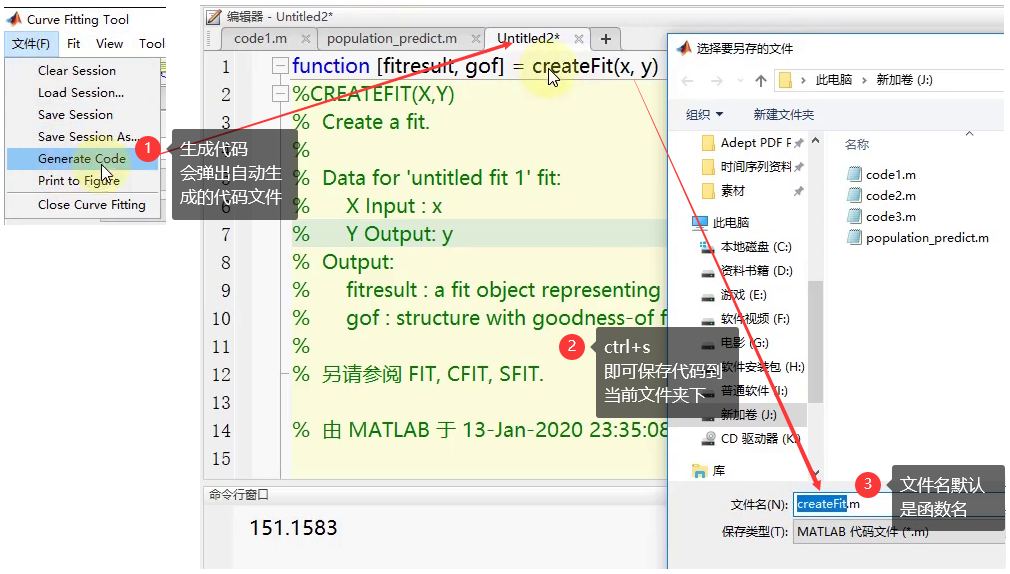
- 保存并调用工具箱代码
- 保存代码:
- 在主代码文件下执行拟合工具箱:
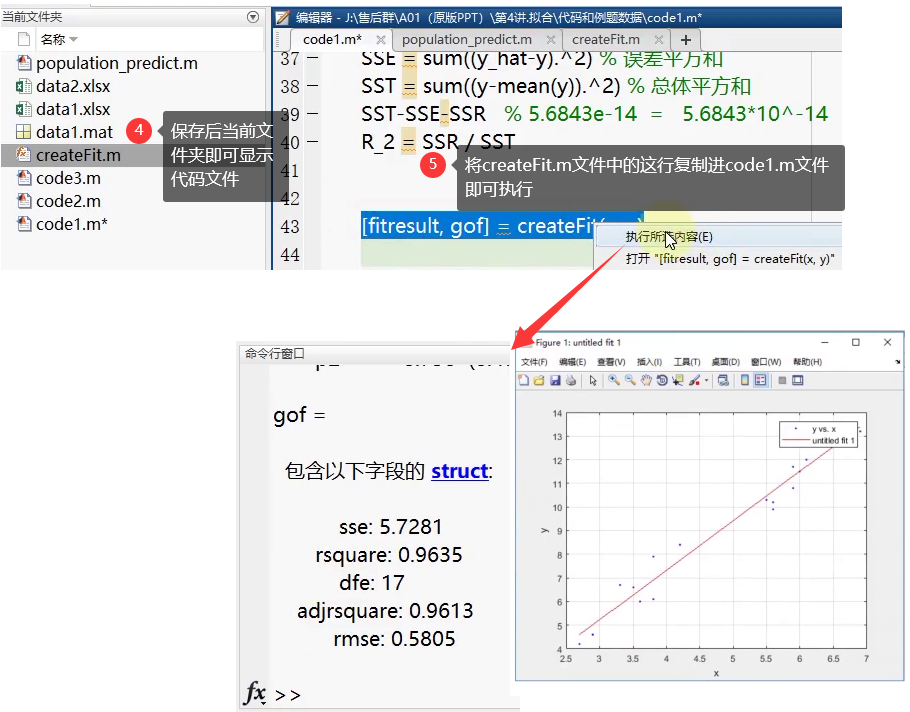
- 可添加进论文附录的代码部分,及修改建议:
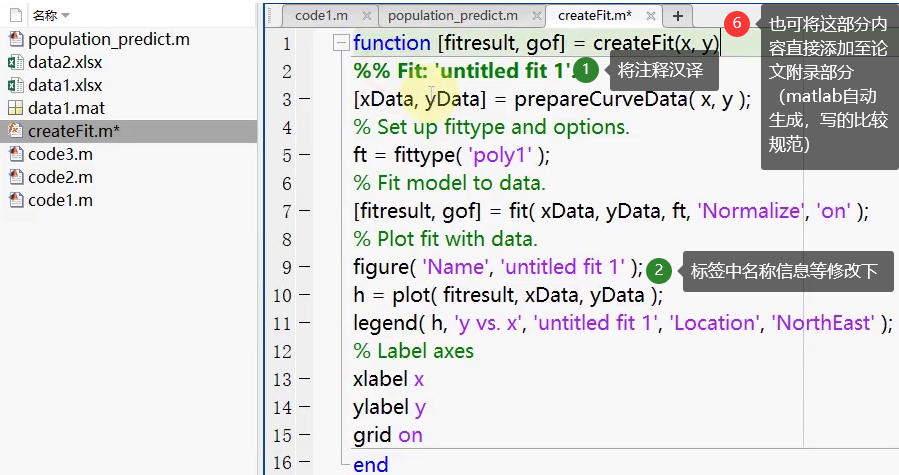
- 保存代码:
拟合工具箱示范用例
示例1:利用拟合工具箱预测美国人口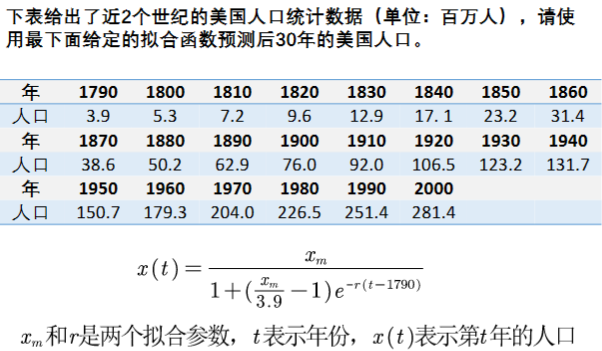
- 运用拟合工具箱
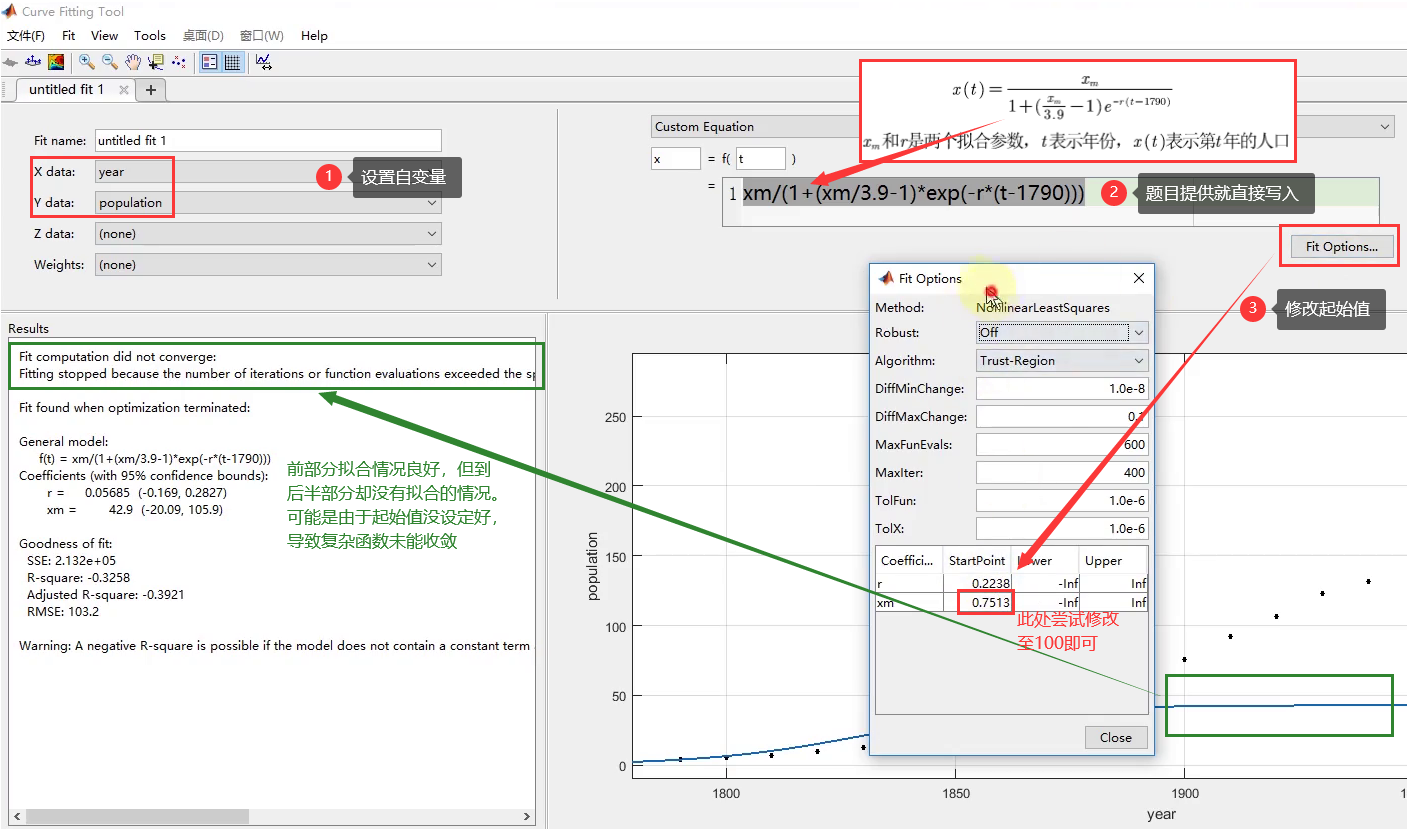
- 数据分析
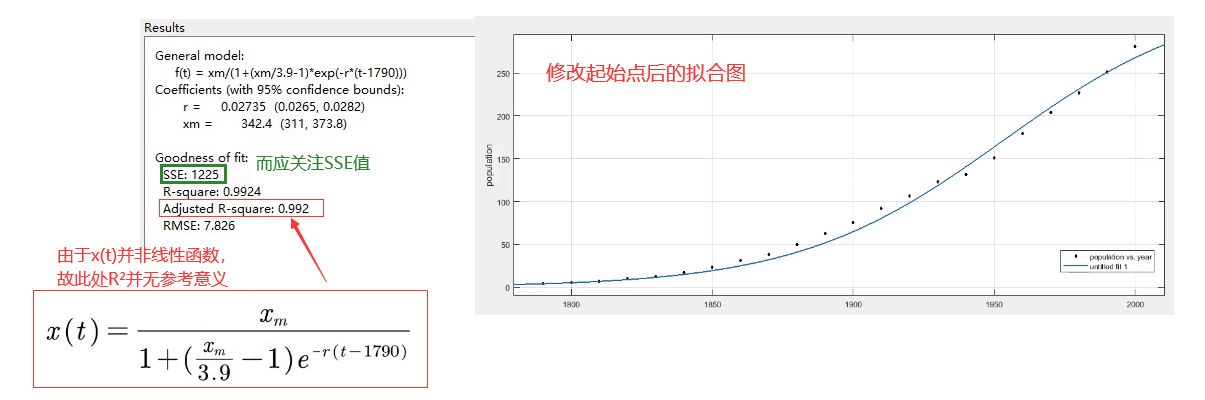
- 题目给的函数并非线性函数,R²没有参考意义,故看SSE
- SSE=1225,看起来数值很大,但由于题目中原始数据本身就大,且SSE还是平方的结果,所以其实拟合效果还不错了。
示例2:自行模拟数据进行演示
- 随机数生成的规则
- (1)randi : 产生均匀分布的随机整数
%产生一个1至10之间的随机矩阵,大小为2x5; s1 = randi(10,2,5); %产生一个-5至5之间的随机矩阵,大小为1x10; s2 = randi([-5,5],1,10);- (2) rand: 产生均匀分布的随机数
%产生一个0至1之间的随机矩阵,大小为1x5; s3 = rand(1,5); %产生一个a至b之间的随机矩阵,大小为1x5; % a + (b-a) * rand(1,5); 如:a,b = 2,5 s4= 2 + (5-2) * rand(1,5);- (3)normrnd:产生正态分布的随机数
%产生一个均值为0,标准差为2的正态分布的随机矩阵,大小为3x4; s5 = normrnd(0,2,3,4);- (4)roundn—任意位位置四舍五入
a = 3.1415 roundn(a,-2) % ans = 3.1400 roundn(a,2) % ans = 0 a =31415 roundn(a,2) % ans = 31400 - 具体模拟数据演示及拟合效果:
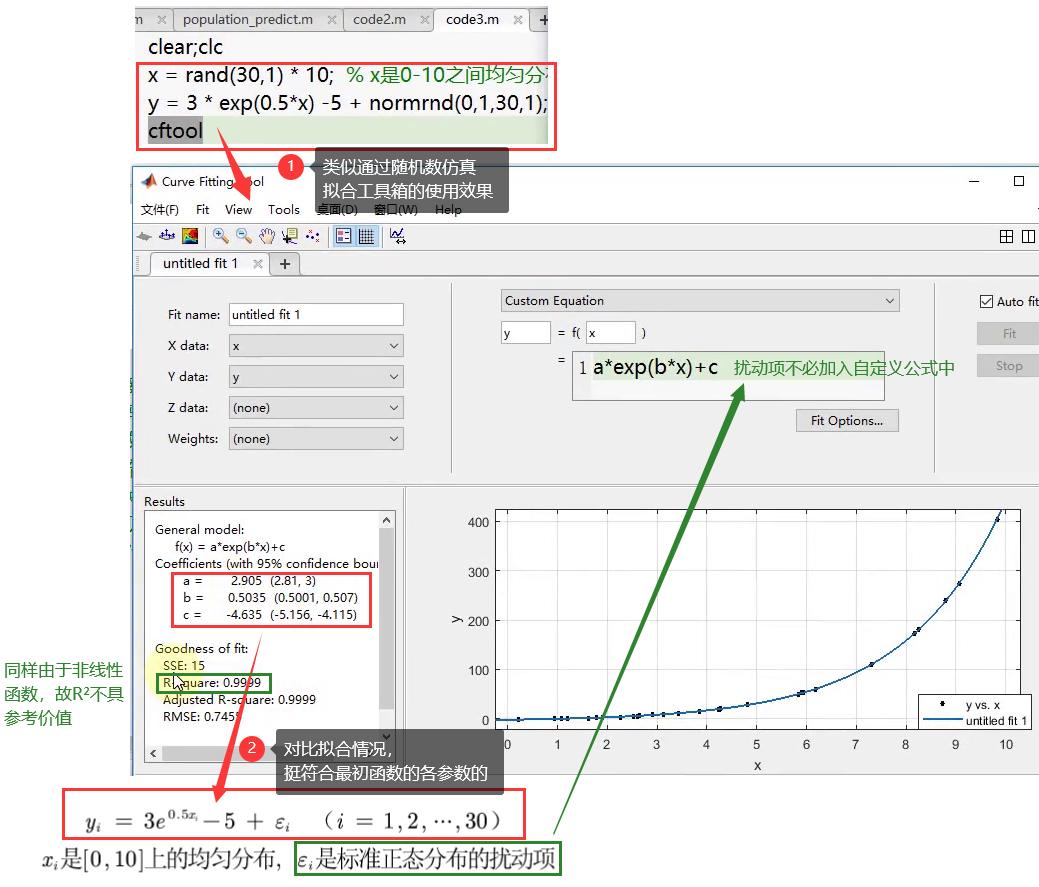
课后习题
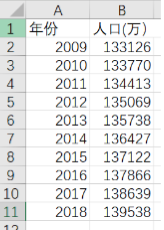
- 题目:根据data2中的中国人口数据,确定你认为最合适的拟合函数,并说明原因。
附言
- 参考课程可见 B站清风数模,如上仅作个人学习后笔记整理。