文章目录
IOUtils方式读取文件
1.文件准备
上传README.txt文件到HDFS上,文件内容自定义。

2.下载安装Eclipse


- 上面的是安装包的方式进行安装,下载好后找到下载位置点击eclipse-inst安装,选择java即可
- 下面的直接是对应的源码下载,eclipse可以进行多种语言开发,我们选择java版本的
- 选择上面任意一种方式后,多点几下click here,有的时候有点慢
3.打开eclipse,新建java项目,添加关于hadoop的一些包
新建一个java project,以下红框内方法都行:

这里选择我们linux系统上安装的java版本,而不用eclipse自带的版本,避免后续的问题(待会会提到):

创建项目中的包:


添加一些我们要用的hadoop的jar包:


-
包在对应的hadoop安装目录:/home/chenqi/hadoop-3.3.6/share/hadoop
-
将hadoop目录下的common里面的包,和里面lib下面的包导入即可

-
对应的还有hdfs、mapreduce、yarn相关的包,也是同样的操作
4.包内新建类进行开发



代码解析:
package org.chenqi.hadoop.hdfs.fs;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDatalnputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class FileSystemCat {
public static void main(String[] args) {
//设置输入文件路径
String uri ="hdfs://master:9000/README.txt";
//配置项对象
Configuration conf = new Configuration();
//初始化FileSystem及输入流对象FSDataInputStream
FileSystem fs = null;
FSDataInputStream in = null;
try{
//给FileSystem对象赋值
fs = FileSystem.get(conf);
//打开uri位置的文件的输入流
in = fs.open(new Path(uri));
//使用IO工具类,将输入流拷贝到标准输出流中,每次拷贝4096字节,且流不自动关闭
IOUtils.copyBytes(in,System.out,4096,false);
}catch(IOException e){
e.printStackTrace();
}finally{
//在finally中,做关闭操作
if(in != null){
//关闭输入流
IOUtils.closeStream(in);
}
if(fs !=null){
try{
//关闭文件系统
fs.close();
}catch(IOException e){
e.printStackTrace();
}
}
}
}
}
-
注意:代码中的url为配置hadoop时,在core-site.xml文件中自己设置的hdfs的访问路径
-
调用FileSystem静态方法get生成File System对象fs(静态get方法有两种重载方式),这里采用了第一种方式。

第二种方式:
FileSystem fs = FileSystem.get(URl.create(uri),conf); -
调用fs的open方法返回一个FSDataInputStream流(open方法有两种重载方式),这里采用了第一种方式
//第一种方式: in = fs.open(new Path(uri)); //第二种方式:增加了缓冲区 in = fs.open(new Path(uri),4096);
5.利用打包的方式生成java jar包



6.验证代码正确性
提交jar包至HDFS上运行(其中org.chenqi.hadoop.hdfs.fs.FileSystemCat是自定义FileSystemCat类的全限定名),查看结构:显示Readme.txt文件的内容。
hadoop jar FileSystemCat.jar org.chenqi.hadoop.hdfs.fs.FileSystemCat

内容正确:为我们开头上传到hdfs中的文件
其它问题:
Exception in thread “main“ java.lang.UnsupportedClassVersionError

解决办法:
eclipse创建项目时默认使用的jdk版本为1.7,但我们Linux系统安装的jdk为1.8,版本不一样导致该问题,改一下eclipse项目使用的jdk版本即可:

-
修改Java Build Path
右键点击项目,选择“Properties”,依次选择“Java Build Path”->“Libraries”,单击选中“JRE System Library”,然后点击“Edit”按钮进行编辑。选择“Alternate JRE”或“Workspace default JRE”的jdk版本(一般应该相同)均可,点击“Finish”。
在创建项目的时候,我们已经选择使用系统中的jdk版本,所有一般这里不会有问题


-
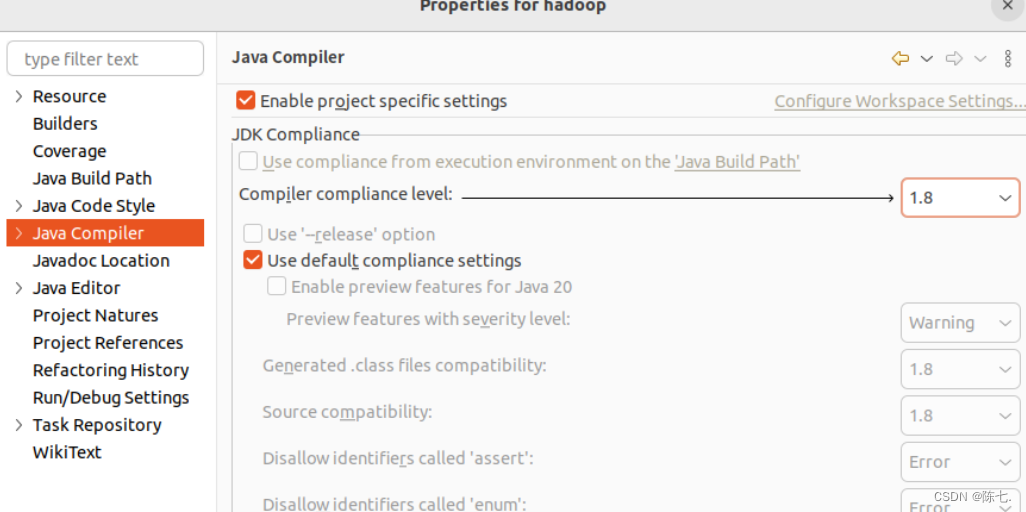
修改Java Compiler
选择“Java Compiler”,勾选“Enable project specific settings”,将“Compiler compliance level”设置为与jvm一致的版本(1.8)。