前言
比起图像识别,现在图片生成技术要更加具有吸引力,但是要步入AIGC技术领域,首先不推荐一上来就接触那些已经成熟闭源的包装好了再提供给你的接口网站,会使用别人的模型生成一些图片就能叫自己会AIGC了吗?那样真正成为了搬运工了,而且是最廉价的。 生成图片技术更多是根据一些基础的图像处理技术来演变而来,从最基础的图像处理技术学习,你就能明白图片生成是怎么一回事。最近看了很多关于目标检测的文章和博客,也在学习AIGC技术,从基础手工设计特征到如今的深度学习模型,二者技术发展历史其实可以说是有比较共同性的。
在本文中,我们将探索目标检测算法的发展历程,从早期依赖于人工设计特征的传统方法,到深度学习技术的崛起,以及目标检测在各个领域中取得的巨大成就。我们将回顾这一漫长而精彩的历程,探讨各个阶段的重要算法和方法,以及它们在实际应用中的价值。
一、目标检测概述
目标检测无非做两个事情,一是检测出该目标在图片或者视频里面所处的位置以及该目标的类别。二是对于有多个目标的图片,检测出所有目标所处的位置及其类别。那么对于第一个要解决的问题,我们可以来了解具体需要干什么事情。
1.定位和分类
首先我们知道图片都是由无数个像素点构成,而视频也可以理解为每一帧的图片连贯形成的,也就是点到线,线到面之间的关系。定位和分类问题就是分类到目标检测的一个过度问题,从单纯的图片分类后给出目标所处的问题,再到多目标的类别和位置。

关于分类问题,我们清楚只要有相应的特征,检测的目标在不同场景里面都有一些相同的通性,细化来说也就是像素组合的形状纯在一定的可归类性,我们可以利用该类特征进行分类。关于定位问题,则需要模型返回目标所在的外界矩形框,即目标的(x,y,w,h)四元组。将二者组合起来,我们可以理解为一个同时使用分类和回归得到分类和定位的结果,只不过该回归是定位问题,返回的是四个值。

2.目标检测
目标检测需要获取图片中所有目标的位置以及类别,我们一般会想到用滑窗的方法来依次检测图片,但是我们又得设计多大的尺寸的滑框来解决问题呢,平均要检测多少次呢,显然这个计算量非常大不是很符合预期效果。有没有什么方法是得我们能快速定位到目标的位置呢?
不少领域专家在此设计出了很多算法,比较有名的方法有selective search方法,此方法可以从图片选出潜在物体候选框(Regions of Interest,ROI)。有了获取ROI的方法,接下来就可以通过分类和合并的方法来获取最终的目标检测结果。

算法逻辑可以分为一下几步,像此类滑窗方法做目标检测存在的问题:滑窗的尺寸、大小、位置不同将产生非常大的计算量。:

二、目标检测算法总览
1.目标检测算法发展史
传统方法的起步(20世纪90年代至2000年代初):
- 1990s:早期的目标检测方法主要依赖于手工设计的特征提取器(如Haar特征、SIFT特征等)结合基于滑动窗口的分类器进行目标定位。
- 2001年:Viola-Jones算法通过使用积分图像和强分类器(Cascade of Classifiers)实现了高效的人脸检测。
基于机器学习的方法(2000年代至2010年代初):
- 2000s:出现了使用机器学习算法(如支持向量机、随机森林等)进行目标检测的方法,同时特征的选取也逐渐从手工设计转向了可学习的特征。
- 2005年:Felzenszwalb等人提出了基于图像分割的目标检测方法,它能够检测不同尺寸和形状的目标。
深度学习革新(2010年代至今):
- 2010s:随着深度学习的兴起,特别是卷积神经网络(CNN)的成功,目标检测取得了显著的进展。
- 2012年:AlexNet在ImageNet图像分类比赛中获得胜利,标志着深度学习在计算机视觉领域的崛起。
- 2013年:RCNN(Region-based Convolutional Neural Networks)首次将卷积神经网络应用于目标检测,将目标定位任务转化为区域建议的问题。
- 2015年:Faster R-CNN提出了一种联合训练目标区域提取器和目标分类器的方法,实现了更高的速度和准确性。
- 2016年:YOLO(You Only Look Once)算法引入了单次前向传播的思想,实现了实时目标检测。
目标检测的细粒度和多模态发展:
- 最近几年,研究者们开始关注细粒度目标检测(如人体姿态检测、物体部位检测等)以及多模态目标检测(结合图像、文本、语音等信息)。
实时和端侧目标检测:
- 随着硬件技术的提升和优化算法的发展,实时和端侧(Edge)目标检测在嵌入式设备和边缘计算中得到了广泛的应用。

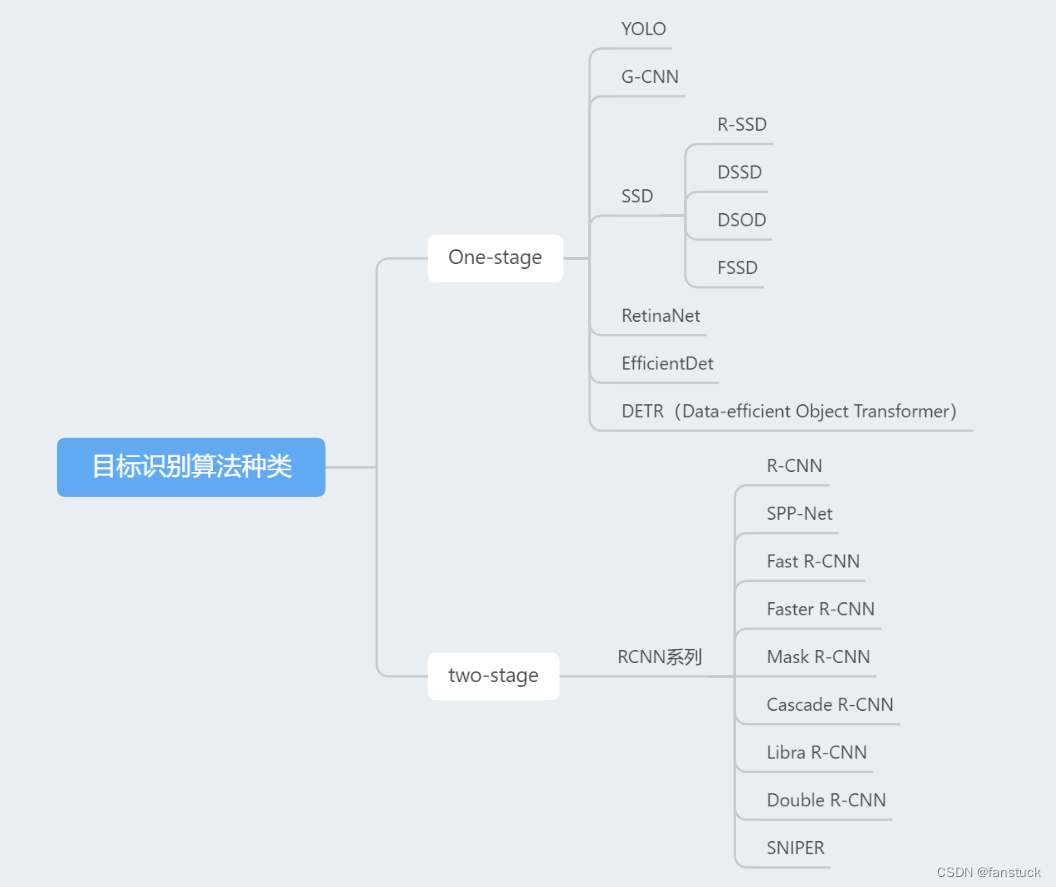
2.目标检测算法类别
主流目标检测算法大致分为one-stage与two-stage两类,前者单阶段目标检测器,这类方法一次性完成目标定位和分类,通常使用密集的滑动窗口或锚框(anchor box)来进行检测。YOLO(You Only Look Once)和SSD(Single Shot Multibox Detector)是代表性的单阶段检测器。
后者两阶段目标检测器,这类方法首先生成目标的候选区域,然后对每个区域进行分类和微调以得到最终的检测结果。经典的方法包括RCNN系列(如Fast R-CNN、Faster R-CNN)。这类方法通常具有更高的准确性,但可能会牺牲一些速度,它们通常能够精准地定位和识别目标,选择合适的两阶段目标检测器取决于具体的应用场景和性能要求。
3.R-CNN算法
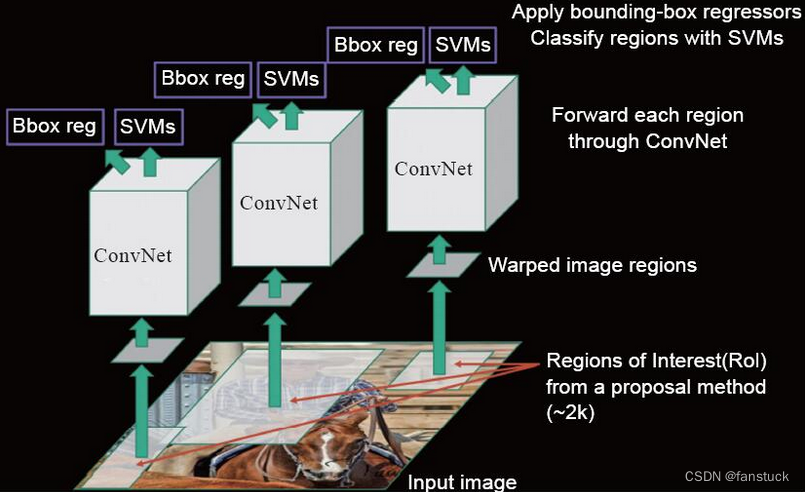
R-CNN可以说作为目标检测具有革命性的算法,后续两阶段目标检测器的思想基本上都是根据R-CNN的算法原理衍生出来的。R-CNN训练过程可以分为四步,我们以R-CNN用于ImageNet数据集上训练为1例:
(1).选出潜在目标候选框(ROI)
objecctness、selective search、category-independent object proposals等很多论文都讲述了此算法,R-CNN使用selective search的方法选出了2000个潜在物体候选框ROI(Region of Interest)。
ROI代表“Region of Interest”,即感兴趣区域。ROI通常指的是在图像中的一个区域,该区域被认为可能包含一个目标物体。在两阶段目标检测器(如RCNN系列)中,首先会通过一个区域建议网络(Region Proposal Network,RPN)生成候选的ROI。这些候选区域将被用于后续的分类和位置微调。ROI的选择是目标检测过程中的关键步骤,它可以帮助算法聚焦在可能包含目标的区域上,从而提高检测的效率和准确性。
(2).训练特征提取器
提取特征使用AlexNet、VGGNet、GoogLeNet等都可以做到。为了获取到一个更好的特征提取器,会在ImageNet预训练好的模型基础上调整,唯一的改动就是将ImageNet中的1000个类别输出改为(C+1)个输出,其中C是真实需要预测的类别个数,1是背景类。新特征的训练方法是使用随机梯度下降,与前几章介绍的普通神经网络的训练方法相同。
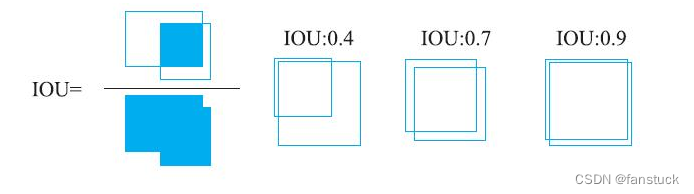
提到训练,就一定要有正样本和负样本,这里先抛出一个用于衡量两个矩形交叠情况的指标:联合之上的交集其实就是两个矩形面积的交集除以并集,一般情况下,当欠条>=0.5时,可以认为两个矩形基本相交,所以在这个任务中,假定在两个矩形框中,1个矩形代表投资回报率,另一个代表真实的矩形框,那么当投资回报率和真实矩形框的欠条>=0.5时则认为是正样本,其余为负样本。
需要注意的是,需要对负样本进行采样,因为训练数据中证样本太少会导致正负样本季度不平衡。最终在该步得到的是一个卷积神经网络的特征提取器,其特征是一个4096维度的特征向量。
(3).训练最终分类器
R-CNN的提出者做了一个实验来选择最优IOU阈值,最终选择真实值的矩形框作为正样本。正负样本选择有规则,Fast R-CNN和Faster R-CNN都是根据IOU的大小选取正负样本。
(4).训练回归模型
为每一个类训练一个回归模型,用来微调ROI与真实矩形框位置和大小的偏差:

关于IOU指标的计算方式为:
def calculate_iou(box1, box2):
# box1和box2的格式为 (xmin, ymin, xmax, ymax)
# 计算交集的坐标范围
x1 = max(box1[0], box2[0])
y1 = max(box1[1], box2[1])
x2 = min(box1[2], box2[2])
y2 = min(box1[3], box2[3])
# 计算交集的面积
intersection_area = max(0, x2 - x1 + 1) * max(0, y2 - y1 + 1)
# 计算两个边界框的面积
area_box1 = (box1[2] - box1[0] + 1) * (box1[3] - box1[1] + 1)
area_box2 = (box2[2] - box2[0] + 1) * (box2[3] - box2[1] + 1)
# 计算并集的面积
union_area = area_box1 + area_box2 - intersection_area
# 计算IOU值
iou = intersection_area / union_area
return iou
预测阶段可以分为:
- 使用selective search方法先选出2000个ROI。
- 所有ROI调整为特征提取网络所需的输入大小并进行特征提取,得到与2000个ROI对应的2000个4096维的特征向量。
- 将2000个特征向量分别输入到SVM中,得到每个ROI预测的类别
- 通过回归网络微调ROI的位置
- 最终使用非极大值抑制 (Non-MaximumSuppression,NMS) 方法对同一个类别的ROI进行合并得到最终检测结果。NMS的原理是得到每人矩形框的分数 (置信度),如果两个矩形框的IOU超过指定闻值,则仅仅保留分数大的那个矩形框。
还是可以看出R-CNN存在很多问题,比如按照以上流程去训练会花费很长的时间。
4.Fast R-CNN
Firshick等人于2015年提出的Fast R-CNN,它非常巧妙地解决了RCNN的几个主要问题。
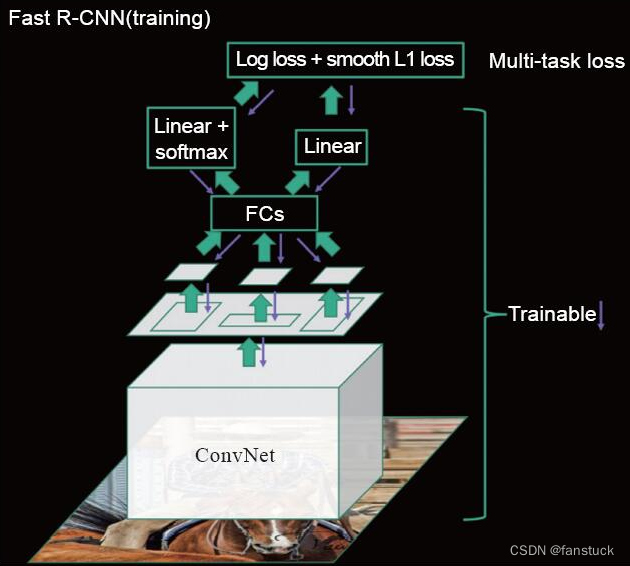
1)将整张图片和ROI直接输入到全卷积的CNN中,得到特征层和对应在特征层上的ROI (特征层的ROI信息可用其几何位置加卷积坐标公式推导得出)。
2)与R-CNN类似,为了使不同尺寸的ROI可以统一进行训练,Fast R-CNN将每块候选区域通过池化的方法调整到指定的M*N,此时特征层上将调整后的ROI作为分类器的训练数据。与R-CNN不同的是,这里将分类和回归任务合并到一起进行训练,这样就将整个流程串联起来。Fast R-CNN的池化示意图如图9-11所示,即先将整张图通过卷积神经网络进行处理,然后在特征层上找到ROI对应的位置并取出,对取出的ROI进行池化(此处的池化方法有很多) 。池化后,全部2000个M*N个训练数据通过全连接层并分别经过2个head: softmax分类以及L2回归,最终的损失函数是分类和回归的损失函数的加权和。利用这种方式即可实现端到端的训练。
Fast R-CNN极大地提升了目标检测训练和预测的速度,如图9-12所示。从图:
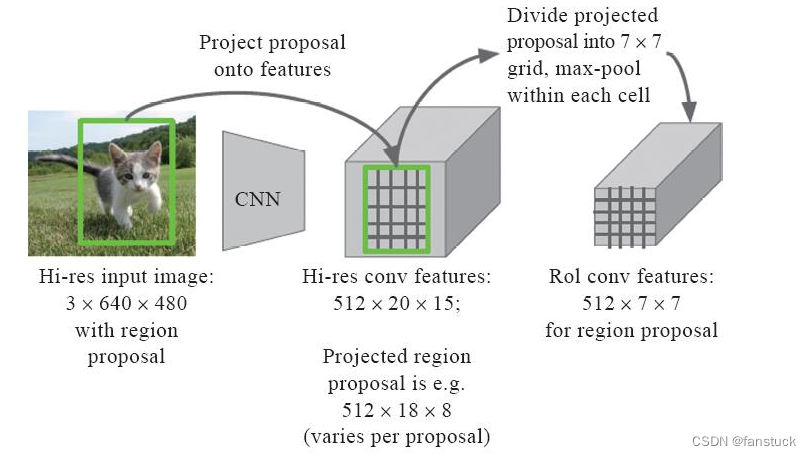
中我们可以看出,Fast R-CNN将训练时长从R-CNN的84小时下降到了8.75小时,每张图片平均总预测时长从49秒降低到2.3秒。从图:
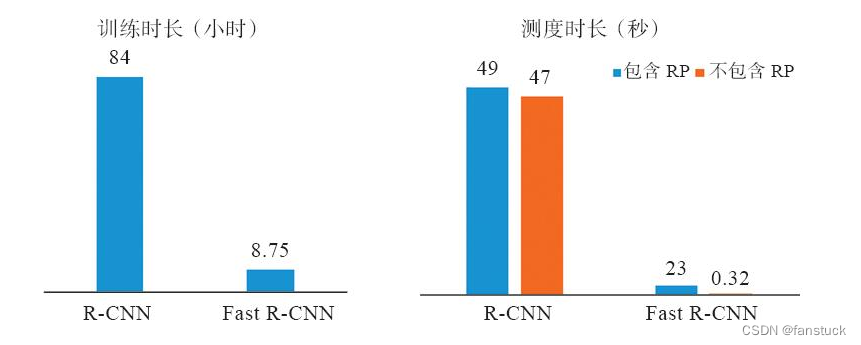
中我们还可以看出,在Fast R-CNN预测的这2.3秒中,真正的预测过程仅占0.32秒,而Regionproposal占用了绝大多数的时间。
5.YOLO
由于在R-CNN的系列算法中需要先获取大量的proposal,但是proposal之间又有很大的重叠,会带来很多重复的工作。YOLO[5]一改基于proposal的预测思路,将输入图片划分成S*S个小格子,在每个小格子中做预测,最终将结果合并。
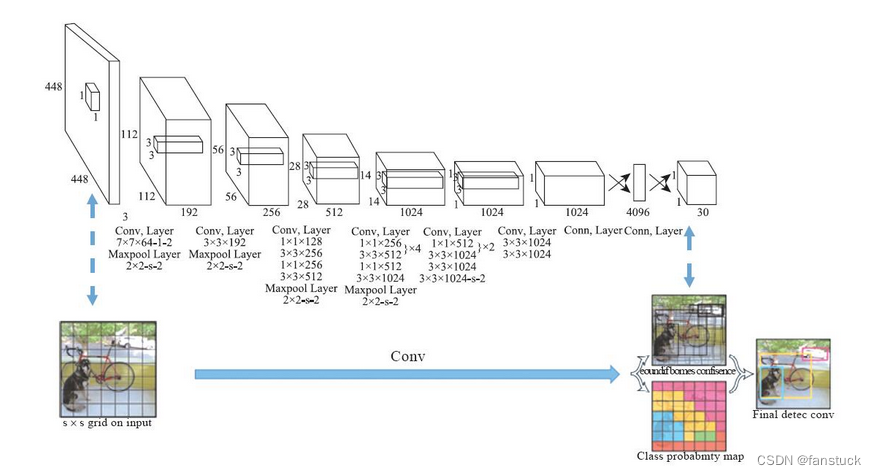
YOLOv1(You Only Look Once)
步骤和原理:
-
将图像划分成网格:
YOLOv1将输入图像划分为 S x S 个网格单元。每个网格单元负责检测该区域内的物体。 -
生成预测:
每个网格单元负责预测 B 个边界框(Bounding Box)以及每个边界框的置信度(Confidence Score)和类别概率。 -
计算边界框的位置:
边界框的位置信息由相对于该网格单元的坐标和宽高来表示。这些信息经过sigmoid函数变换,以确保它们在0到1之间。 -
计算置信度和类别概率:
置信度表示该边界框内是否存在目标物体,类别概率表示物体属于哪个类别。 -
计算损失函数:
YOLOv1使用综合的损失函数来平衡置信度、位置和类别概率的预测,其中包括分类损失、定位损失和置信度损失。 -
非极大值抑制(NMS):
通过非极大值抑制来移除重叠较大的边界框,保留最准确的预测。
YOLOv2/v3(YOLO9000)
YOLOv2(Darknet-19)和YOLOv3是YOLO系列的进化版本,带来了一些重要的改进:
-
Darknet-19网络:YOLOv2引入了一个更深的神经网络(Darknet-19)作为特征提取器,提高了特征的表达能力。
-
Anchor Boxes:引入了锚定框(Anchor Boxes)的概念,使得模型能够更好地适应不同尺度和宽高比的目标。
-
多尺度检测:YOLOv3在输出层使用了三个不同尺度的特征图来提高小物体的检测性能。
-
YOLO9000:YOLOv2和v3引入了多类别检测,能够在更广泛的类别上进行检测。
YOLOv4/v5
-
Backbone网络:YOLOv4引入了更强大的特征提取网络,如CSPDarknet53。
-
数据增强和技巧:引入了一系列的数据增强和训练技巧,进一步提升了模型性能。
-
YOLOv5:YOLOv5是YOLO系列的最新版本,引入了一些创新性的设计和模型架构优化。
总的来说,YOLO系列算法通过将目标检测任务转化为单次前向传播,实现了实时目标检测的目标。随着版本的更新和算法的改进,YOLO系列在性能和速度上不断取得突破,成为了目标检测领域的重要研究方向之一。
目标检测技术的发展离不开数不尽的研究者们的不懈努力和创新,也离不开硬件技术的进步和大量标注数据集的贡献。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。