超分辨率技术(Super-Resolution)是指从观测到的低分辨率图像重建出相应的高分辨率图像,在监控设备、卫星图像和医学影像等领域都有重要的应用价值。SR可分为两类:从多张低分辨率图像重建出高分辨率图像和从单张低分辨率图像重建出高分辨率图像。基于深度学习的SR,主要是基于单张低分辨率的重建方法,即Single Image Super-Resolution (SISR)。
SISR是一个逆问题,对于一个低分辨率图像,可能存在许多不同的高分辨率图像与之对应,因此通常在求解高分辨率图像时会加一个先验信息进行规范化约束。在传统的方法中,这个先验信息可以通过若干成对出现的低-高分辨率图像的实例中学到。而基于深度学习的SR通过神经网络直接学习分辨率图像到高分辨率图像的端到端的映射函数。
较新的基于深度学习的SR方法,包括SRCNN,DRCN, ESPCN,VESPCN和SRGAN等。 本文重点介绍SRGAN及其实现。
SRGAN (Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, arxiv, 21 Nov, 2016)将生成式对抗网络(GAN)用于SR问题。其出发点是传统的方法一般处理的是较小的放大倍数,当图像的放大倍数在4以上时,很容易使得到的结果显得过于平滑,而缺少一些细节上的真实感。因此SRGAN使用GAN来生成图像中的细节。
在这篇文章中,将生成对抗网络(Generative Adversarial Network, GAN)用在了解决超分辨率问题上。文章提到,训练网络时用均方差作为损失函数,虽然能够获得很高的峰值信噪比,但是恢复出来的图像通常会丢失高频细节,使人不能有好的视觉感受。SRGAN利用感知损失(perceptual loss)和对抗损失(adversarial loss)来提升恢复出的图片的真实感。感知损失是利用卷积神经网络提取出的特征,通过比较生成图片经过卷积神经网络后的特征和目标图片经过卷积神经网络后的特征的差别,使生成图片和目标图片在语义和风格上更相似。一个GAN所要完成的工作,GAN原文举了个例子:生成网络(G)是印假钞的人,判别网络(D)是检测假钞的人。G的工作是让自己印出来的假钞尽量能骗过D,D则要尽可能的分辨自己拿到的钞票是银行中的真票票还是G印出来的假票票。开始的时候呢,G技术不过关,D能指出这个假钞哪里很假。G每次失败之后都认真总结经验,努力提升自己,每次都进步。直到最后,D无法判断钞票的真假……SRGAN的工作就是: G网通过低分辨率的图像生成高分辨率图像,由D网判断拿到的图像是由G网生成的,还是数据库中的原图像。当G网能成功骗过D网的时候,那我们就可以通过这个GAN完成超分辨率了。
传统的方法使用的代价函数一般是最小均方差(MSE),即
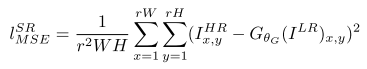
该代价函数使重建结果有较高的信噪比,但是缺少了高频信息,出现过度平滑的纹理。SRGAN认为,应当使重建的高分辨率图像与真实的高分辨率图像无论是低层次的像素值上,还是高层次的抽象特征上,和整体概念和风格上,都应当接近。整体概念和风格如何来评估呢?可以使用一个判别器,判断一副高分辨率图像是由算法生成的还是真实的。如果一个判别器无法区分出来,那么由算法生成的图像就达到了以假乱真的效果。
因此,该文章将代价函数改进为
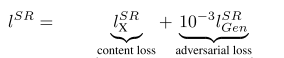 第一部分是基于内容的代价函数,第二部分是基于对抗学习的代价函数。基于内容的代价函数除了上述像素空间的最小均方差以外,又包含了一个基于特征空间的最小均方差,该特征是利用VGG网络提取的图像高层次特征:
第一部分是基于内容的代价函数,第二部分是基于对抗学习的代价函数。基于内容的代价函数除了上述像素空间的最小均方差以外,又包含了一个基于特征空间的最小均方差,该特征是利用VGG网络提取的图像高层次特征:
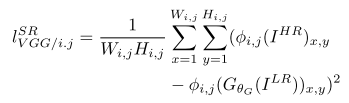 对抗学习的代价函数是基于判别器输出的概率:
对抗学习的代价函数是基于判别器输出的概率:
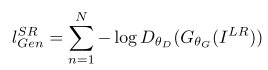
其中是一个图像属于真实的高分辨率图像的概率。
是重建的高分辨率图像。SRGAN使用的生成式网络和判别式网络分别如下:
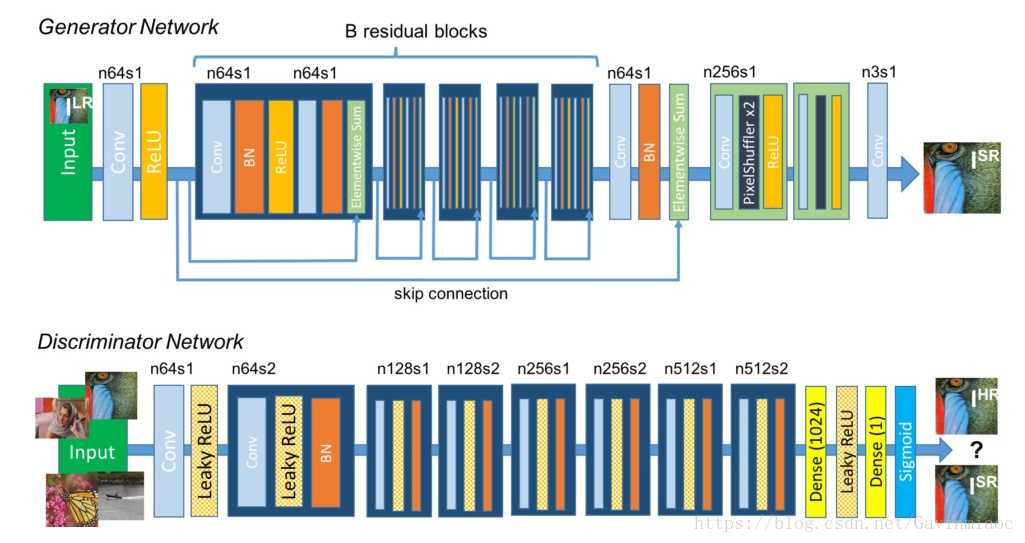
关于SRGAN论文相关可以参见我到另一篇文章论文阅读之《Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network》
在生成网络部分(SRResNet)部分包含多个残差块,每个残差块中包含两个3×3的卷积层,卷积层后接批规范化层(batch normalization, BN)和PReLU作为激活函数,两个2×亚像素卷积层(sub-pixel convolution layers)被用来增大特征尺寸。在判别网络部分包含8个卷积层,随着网络层数加深,特征个数不断增加,特征尺寸不断减小,选取激活函数为LeakyReLU,最终通过两个全连接层和最终的sigmoid激活函数得到预测为自然图像的概率。SRGAN的损失函数为:
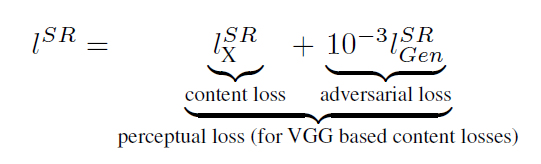
其中内容损失可以是基于均方误差的损失的损失函数:
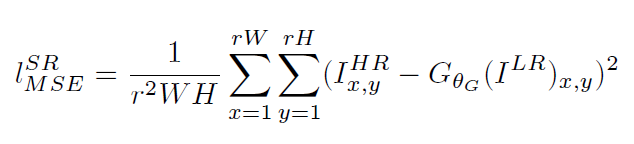
也可以是基于训练好的以ReLU为激活函数的VGG模型的损失函数:
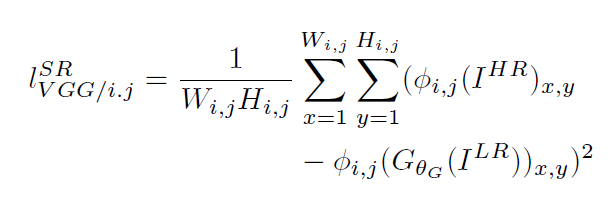
i和j表示VGG19网络中第i个最大池化层(maxpooling)后的第j个卷积层得到的特征。对抗损失为:
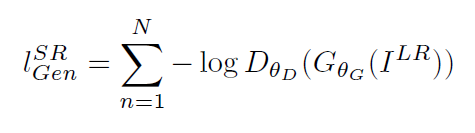
文章中的实验结果表明,用基于均方误差的损失函数训练的SRResNet,得到了结果具有很高的峰值信噪比,但是会丢失一些高频部分细节,图像比较平滑。而SRGAN得到的结果则有更好的视觉效果。其中,又对内容损失分别设置成基于均方误差、基于VGG模型低层特征和基于VGG模型高层特征三种情况作了比较,在基于均方误差的时候表现最差,基于VGG模型高层特征比基于VGG模型低层特征的内容损失能生成更好的纹理细节。
github(tensorflow): https://github.com/zsdonghao/SRGANhttps://
github(tensorflow): https://github.com/buriburisuri/SRGANhttps://
github(torch): https://github.com/junhocho/SRGANhttps:/AN
github(caffe): https://github.com/ShenghaiRong/caffe_srganhttps:///caffe_srgan
github(tensorflow): https://github.com/brade31919/SRGAN-tensorflowhttps://RGAN-tensorflow
github(keras): https://github.com/titu1994/Super-Resolution-using-Generative-Adversarial-Networkshttps://er-Resolution-using-Generative-Adversarial-Networks
github(pytorch): https://github.com/ai-tor/PyTorch-SRGAN
论文介绍到此。下面介绍SRGAN的tensorflow实现。
先看一组图:

训练方法大致就是构建好网络后,找一个高清图片数据集,对每个图片做处理得到低分辨率的图片,从而得到低分辨率图片数据集。用这两个数据集来训练网络,实现低分辨率到高分辨率图片的转化。
如果你对这个实验感兴趣,也可以自己来尝试一下。在Github可以搜到很多TensorFlow下的开源代码,如果自己机器显卡够强的话可以自己按照说明训练,如果显卡不行也没关系,我实验的这份源码作者提供了预训练好的模型,源码: https://github.com/brade31919/SRGAN-tensorflow
要注意的是,这份代码只能输入png图片,如果你是jpg图片,请先将图片格式进行转换。手动或者代码批量转换。
下载源代码和模型后,将模型文件夹“SRGAN_pre-trained”直接放到源代码目录下,创建一个你的图片目录,将png图片丢进去,修改“inference_SRGAN.sh”文件的红框部分为你的图片路径:
#!/usr/bin/env bash
CUDA_VISIBLE_DEVICES=0 python main.py \
--output_dir ./result/inference/ \
--summary_dir ./result/log/ \
--mode inference \
--is_training False \
--task SRGAN \
--input_dir_LR ./data/myimages/ \ # modify the path to your image path
--num_resblock 16 \
--perceptual_mode VGG54 \
--pre_trained_model True \
--checkpoint ./SRGAN_pre-trained/model-200000
然后在终端运行“inference_SRGAN.sh”文件即可,当然IDE里运行也是可以的,先做好参数配置,然后运行main.py即可。
也可以
Run test using pre-trained modelRun the training process
当然train自己的数据集,需要在GPU上跑的。这块暂未测试。来看看结果:
人脸提升:

从对比来看很容易发现确实提高了分辨率,至少视觉上看总觉得上边的是略模糊的。
我们放大来看一下算法到底做了什么:




从放大图中可以看到,人脸上多了很多奇怪的纹路,但是缩小后,看起来分辨率确实提高了。
对于低分辨率的图,我们用原训练的模型预测效果不是很好,需要自己重新训练了。

分别是input,output,target.可见,output与target差距还是蛮大的。后面重新训练模型后效果会好。