一、 背景介绍
Etherscan 是 2015 年推出的一个以太坊区块探索和分析的分布式智能合同平台, 由于区块链中的交易信息等数据都是公开透明的 , 而 Etherscan 作为探索以太坊的窗口, 用户可以使用其查看自己的交易详情以及以太坊中的任何信息。
我们都有过这样的经历, 打开 taobao, 选了一件自己心仪已久的商品之后, 迫不及待的付了款, 看着卖家发了货之后, 心满意足的笑了笑。然而过了一天…两天…WTF (要文明, 其实是 where’s the food:)), 联系了卖家, 卖家告诉你 “亲, 我们已发货… …” 这时候, 有一个工具就是你的 “救命稻草” - 快递查询工具, 使用快递查询工具, 它会告诉你, 你的宝贝已经到了哪里, 距离你还有多少公里, 虽然对于快递的速度有些不爽, 但也足以安抚你焦躁的心灵。
其实在区块链世界中, 也有一个类似于上述 “快递查询工具” 的应用, 它就是 Etherscan, 网址是https://etherscan.io/
-----上文摘抄自知乎不得不备的工具 - Etherscan.io
在本项目中,打算在使用者给出一个Block的范围后,对该范围内的所有交易的信息做一个提取,并将最后提取的信息存入ether.json文件中。
二、信息提取规则
在最初始的Block网页中,先对每个交易的Txn_Hash和Method进行提取,再点击Txn_Hash进入详情页后,对详情页中的内容进行查找,假如有Transaction_Action这一项,则将该项爬取下来,否则直接返回即可。

详情页:

三、项目所用功能分析
该项目除了要使用最基本的网页爬取功能,还要实现对范围内的url的遍历、翻页功能、模拟打开详情页并将上一页的内容带入详情页中等一系列操作。
四、代码实现
爬虫的主体部分在spider文件夹的ether.py文件中:
import scrapy
import re
class EtherSpider(scrapy.Spider):
handle_httpstatus_list = [404]
name = 'ether'
allowed_domains = ['etherscan.io']
#start_urls = ['https://etherscan.io/txs?block=16538039&p=1']
start_urls = 'https://etherscan.io/txs?block='
def start_requests(self):
#print()
start = input('Please enter the Start and End Block values\n')
end = input()
#print(a)
#print(b)
for i in range(int (start),int (end)+1):
#使用拼接以实现Block范围内数据的爬取
url = self.start_urls + str(i) + '&p=1'
#print(url)
#continue
#cookies为保障隐私不写出
temp = ''
cookies = {
data.split('=')[0]: data.split('=')[-1]for data in temp.split(';')} #将cookies转化为字典
yield scrapy.Request(
url=url,
callback=self.parse,
cookies=cookies
)
def parse(self, response):
#获取当前页下的所有节点
node_list = response.xpath('//*[@id="paywall_mask"]/table/tbody/tr')
print(len(node_list))
#遍历所有节点
for node in node_list:
temp = {
}
temp['Txn_Hash'] = node.xpath('./td[2]/span/a/text()').extract_first()
temp['Method'] = node.xpath('./td[3]/span/text()').extract_first()
#response.urljoin()用于拼接相对路径的url
temp['link'] = response.urljoin(node.xpath('./td[2]/span/a/@href').extract_first())
#print(temp)
#构建详细页面请求
yield scrapy.Request(
url=temp['link'],
callback=self.parse_detail,
meta={
'temp':temp}
)
#模拟翻页
part_url = response.xpath('//*[@id="ContentPlaceHolder1_topPageDiv"]/nav/ul/li[4]/a/@href').extract_first()
#print(part_url)
#判断终止条件
if part_url != None:
next_url=response.urljoin(part_url)
print(next_url)
#构建请求对象并且返回给引擎
yield scrapy.Request(
url=next_url,
callback=self.parse
#dont_filter=True
)
def parse_detail(self,response):
temp= response.meta['temp']
# temp['Transaction Action'] = response.xpath('//*[@id="ContentPlaceHolder1_maintable"]/div[5]/div[2]/text()').extract_first().strip()
#用于定位详情页中是否有Transaction_Action这个内容,以state的状态是否为None来判断
state = response.xpath('//i[contains(@class, "fa-lightbulb-on") and contains(@class, "text-info")]/../../..//ul[@id="wrapperContent"]').extract_first()
#if temp['Method'] == 'Approve':
if state != None:
#print('Yes-----------')
#print(state)
state = re.sub('\<.*?\>',' ',state)
temp['Transaction_Action'] = re.sub(' +', ' ', state)
#print(temp)
#print('aaaa--------------')
#temp['Transaction Action'] = BeautifulSoup(state,'html.parser')
#print(temp)
yield temp
#print('111')
由于最后爬取的文件要存储在一个文件中,所以还要在管道(pipelines.py)文件中进行编辑。
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import json
class Task1Pipeline:
def __init__(self):
self.file=open('ether.json',"w")
def close_spider(self):
self.file.close()
def process_item(self, item, spider):
# print('-----------------')
# print(item)
# print('-----------------')
#将字典序列化
json_data = json.dumps(item) + ',\n'
#print(json_data)
#print('0000000000000000000000000000')
#将数据写入文件
self.file.write(json_data)
#默认使用完管道后需要将数据返回给引擎
return item
五、代码运行
执行以下命令后:
C:\python\task1>scrapy crawl ether
按提示输入以下内容(为节省时间故只爬连续的两页):
Please enter the Start and End Block values
16538039
16538040
六、运行结果分析
在爬虫开始时,文件夹中会出现一个ether.json的文件,但在爬虫结束前,该文件还一直都只是空的,在爬虫结束后,我们可以发现此时爬虫内容如下:
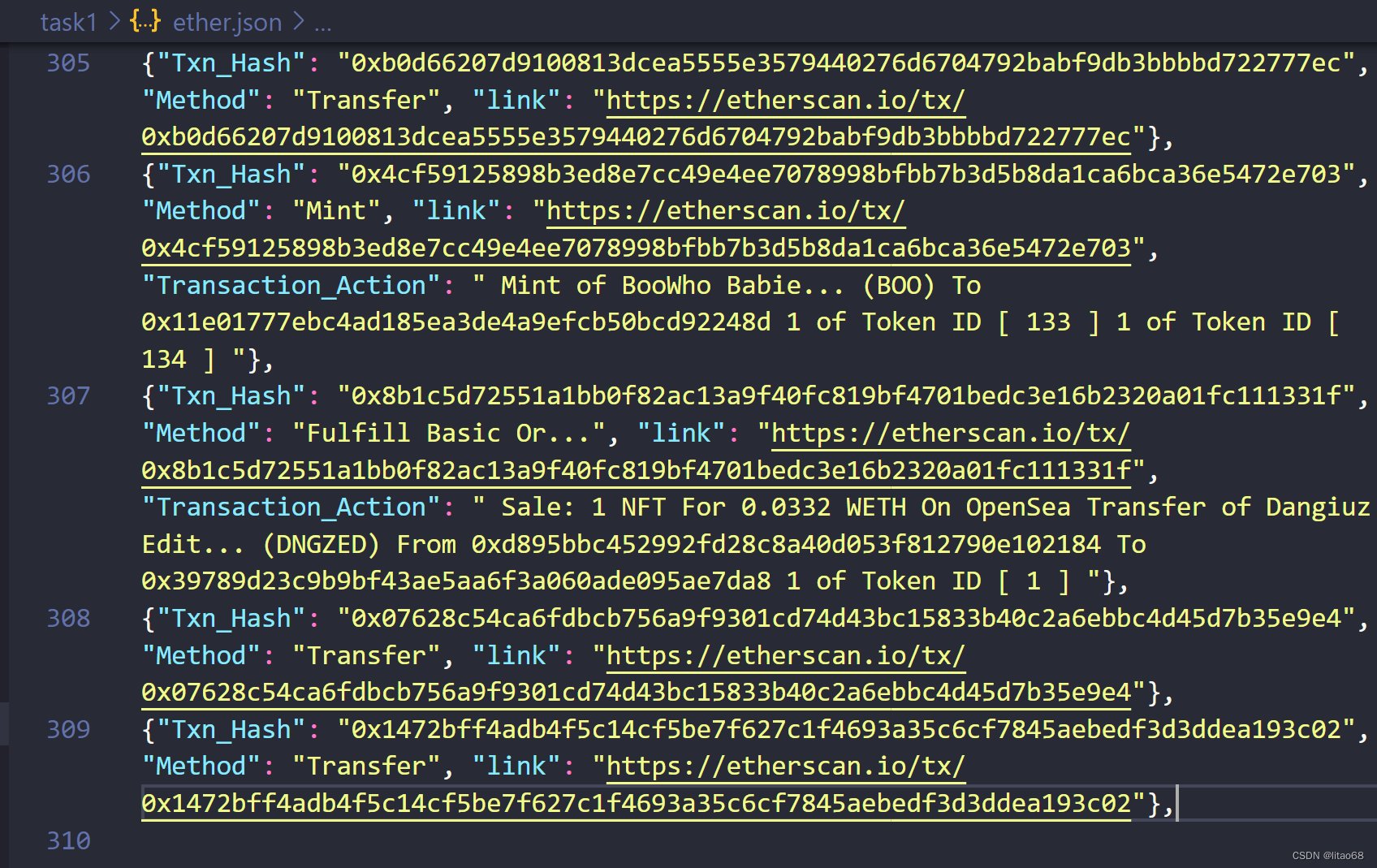
可以看到最后爬取到了309条信息,如何验证我们最后爬取到的内容是正确的呢?
我们可以先看Block为16538039和16538040中总共有多少笔交易:
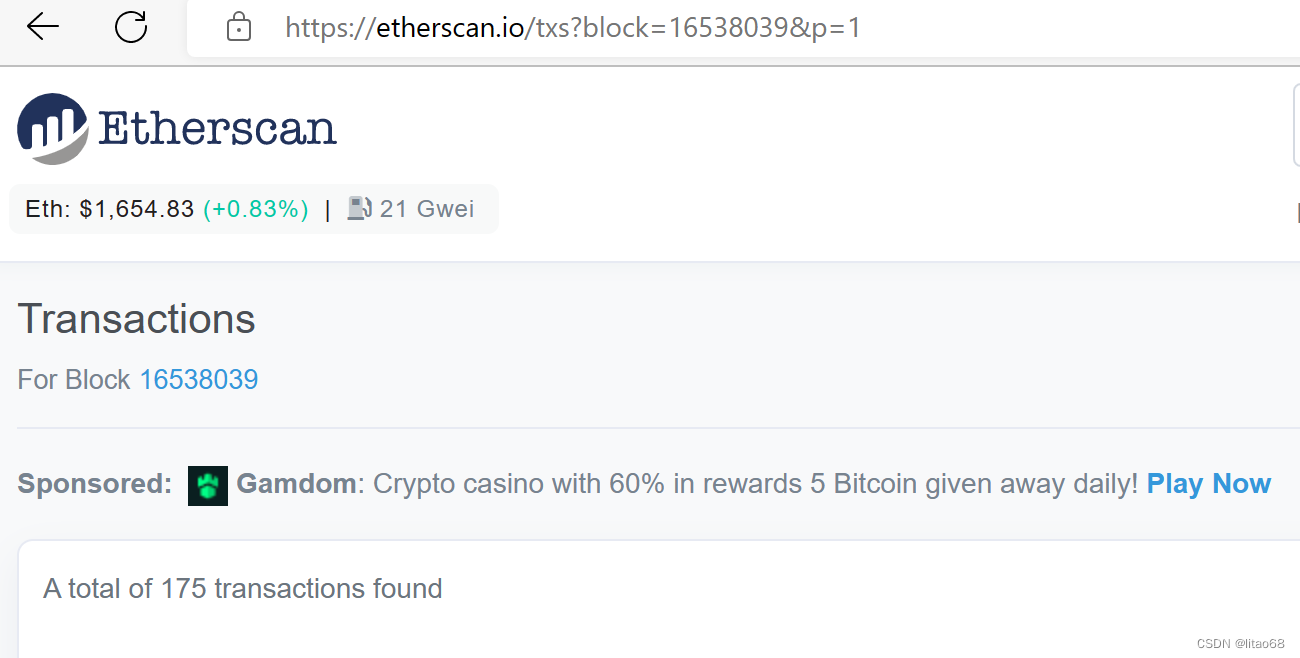

可以发现175+134=309,和我们最后爬取出来的数据数目一致。
接着,我们可以随机从爬取出的数据里挑一条出来验证一下:
{
"Txn_Hash": "0x2a8ddede06368c884a5c2b5d86262ee66661ccd938ebfb759b65e212e6505740", "Method": "Borrow", "link": "https://etherscan.io/tx/0x2a8ddede06368c884a5c2b5d86262ee66661ccd938ebfb759b65e212e6505740", "Transaction_Action": " Borrow 6,000 USDC From Aave Protocol V2 "},
进入link,查看这笔交易的信息:

二者信息是一致的。
由以上两个过程基本可以确定我们本次爬虫爬取到的数据是正确的。
七、实验总结
在该实验过程中确实遇到了很多之前为遇到过的问题,如该网站有一定的反爬措施,最后通过修改setting.py文件中的USER_AGENT参数即在爬取时带上cookies参数可以解决。在爬取时还会预定因为自己程序爬取速度过快导致被网站直接认定为机器人后服务器直接熔断导致无法爬取到完整的数据,最后通过调整CONCURRENT_REQUESTS与DOWNLOAD_DELAY两个参数解决了被服务器熔断的问题。
虽然最后该爬虫可以基本完成实验要求,但其还有一个最致命的缺点----爬取时间太长了,在该样例中,只是进行爬取了两个Block内309条交易的信息,就总共花费了9分钟的时间,究其原因还是因为该程序的思路还是太过简单了,是一页一页进行爬取,爬完一页再进行翻页操作的,后续可以通过多页同时发起请求的方式进行爬取,以提高程序效率。