1.前言:
上篇已经说过ik的集成,这篇说下ik的实际使用
2.2、IK分词器测试
IK提供了两个分词算法ik_smart 和 ik_max_word
- ik_smart:为最少切分
- ik_max_word:为最细粒度划分。
2.2.1、最小切分示例
-
#分词器测试ik_smart -
POST _analyze{"analyzer":"ik_smart","text":"我是中国人"}
结果:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "中国人",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
}
]
}2.2.2、最细切分示例
#分词器测试ik_max_wordPOST _analyze
{
"analyzer":"ik_max_word",
"text":"我是中国人"

}
结果:
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "中国人",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "中国",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "国人",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
}
]
}3、IK分词器为何如此智能
通过上面的示例我们也看到了,这种中文的分词效果是ES内置的分词器无法比拟的。那么它是如何做到的呢?不要过于惊讶,因为原理其实非常简单,它是通过索引字典来达到的,这样说可能比较抽象难懂,我们来实际看看ES的plugins/ik/config目录:
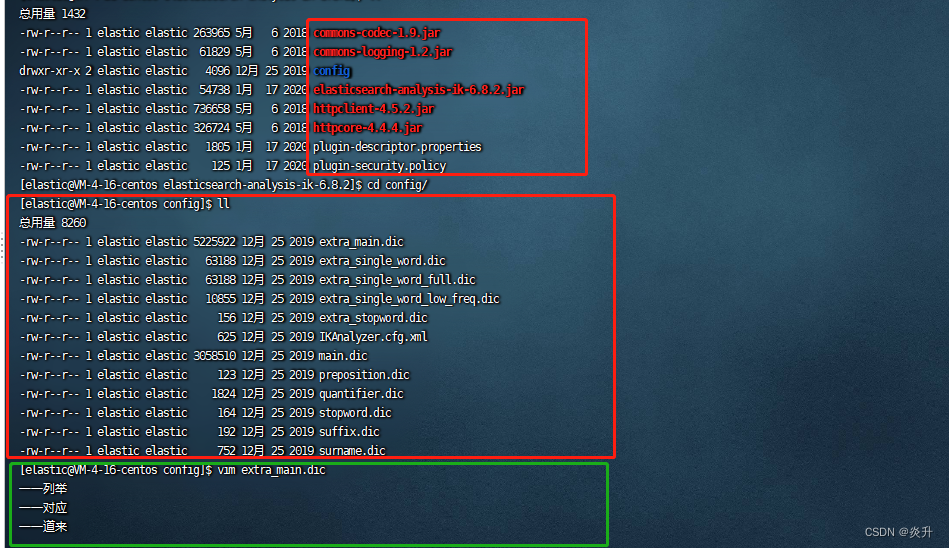
3.1、ik分词器的字典
看到那些*.dic结尾的文件了吗?其实它就是dictionary(字典)的简写,来实际看看字典内容:如上图。
实际的词汇量是非常巨大的,根本不可能完全收录到字典中。如果有需要,我们完全可以通过在字典文件中增加我们想要的词语来扩展我们自己的分词规则。
4、扩展ik分词器的字典
示例:
“麻花疼”使用ik_smart、ik_max_word 分词后的结果都是:麻花、疼。
无法分词为一个完整的“麻花疼”,因为ik分词器的词典中没有这个词。示例如下图:
麻花疼
使用ik_smart分词GET _analyze{
"analyzer": "ik_smart", "text": "麻花疼"}
{
"tokens": [
{
"token": "麻花",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 1
},
{
"token": "疼",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 2
}
]
}如何将“麻花疼”分词为一个完整的词,需要将其添加到词典中。
4.1、ik分词器的配置文件目录

在plugins/elasticsearch-analysis-ik-6.8.2/config/config目录下有ik分词配置文件:
- IKAnalyzer.cfg.xml,用来配置自定义的词库
- main.dic,ik原生内置的中文词库,只要是这些单词,都会被分在一起。
- surname.dic,中国的姓氏。
- suffix.dic,特殊(后缀)名词,例如
乡、江、所、省等等。- preposition.dic,中文介词,例如
不、也、了、仍等等。- stopword.dic,英文停用词库,例如
a、an、and、the等。- quantifier.dic,单位名词,如
厘米、件、倍、像素等。- extra开头的文件,是额外的词库。
4.2、IKAnalyzer.cfg.xml配置文件

4.3、新增字典配置文件,后缀为dic
在新的字段配置文件my_ik.dic中添加新词:“麻花疼”。
注意:词库的编码必须是utf-8。

4.4、将新增的配置文件添加到IK字典配置文件中,并重启ES和KIBANA

ES启动控制台中会显示已经读取到自定义字典:

再次查询,该词已经成功识别 。

4.5、IK插件还支持热更新:
IKAnalyzer.cfg.xml配置文件中的有如下配置:

其中 words_location 是指一个 url,比如 http://yoursite.com/getCustomDict,该请求只需满足以下两点即可完成分词热更新。
- 该 http 请求需要返回两个头部(header),一个是
Last-Modified,一个是ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。 - 该 http 请求返回的内容格式是一行一个分词,换行符用
\n即可。
满足上面两点要求就可以实现热更新分词了,不需要重启es 。
可以将需自动更新的热词放在一个 UTF-8 编码的 .txt文件里,放在 nginx 或其他简易 http server 下,当 .txt文件修改时,http server 会在客户端请求该文件时自动返回相应的 Last-Modified 和 ETag。可以另外做一个工具来从业务系统提取相关词汇,并更新这个 .txt文件。
5.java调用ik分词器的analyzer:
这里是用httpClient实现的,没用es的客户端,网上找了半天也没找到合适的文章,大多都是用es高亮客户端,还得用索引库,费劲感觉有点。自己用httpClient写吧
public static String httpPostNeedPassword(String json,String url,String username,
String password) {
String result = "";
try {
HttpClient httpClient = new HttpClient();
PostMethod postMethod = new PostMethod(url);
//需要验证
UsernamePasswordCredentials creds = new UsernamePasswordCredentials(username, password);
httpClient.getState().setCredentials(AuthScope.ANY, creds);
StringRequestEntity requestEntity = new StringRequestEntity(json, "application/json", "UTF-8");
postMethod.setRequestEntity(requestEntity);
int i = httpClient.executeMethod(postMethod);
InputStream inputStream = postMethod.getResponseBodyAsStream();
BufferedReader br = new BufferedReader(new InputStreamReader(inputStream));
String s;
StringBuffer sb = new StringBuffer();
while ((s = br.readLine()) != null) {
sb.append(s + "\n");
}
result = new String(sb.toString().getBytes(),"UTF-8");
postMethod.releaseConnection();
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
@Test
public void test(){
String s = httpPostNeedPassword("{ \"analyzer\": \"ik_max_word\", \"text\":\"洛阳古迹风景很好,是旅游胜地,毛泽东也去过,发呆着\" }", "http://123.57.220.31:9200/_analyze", "elastic", "mycomm123");
System.out.println(s);
}结果:
