本任务是C语言课程与Intel合作的任务。主要是对Intel提供的并行矩阵乘法计算的方法进行学习和理解,以进一步自主实现并行归并排序算法和图像卷积并行加速。本文中代码版权归属于Intel公司。转载请说明来源。
一、描述
编写⼀个基于oneAPI的C++/SYCL程序来执行矩阵乘法操作。需要考虑大尺寸矩阵的乘法操作以及不同线程之间的数据依赖关系。通常在实现矩阵乘法时,可以使用块矩阵乘法以及共享内存来提高计算效率。
二、分析
利用基于SYCL的编程模型在GPU上实现矩阵乘法的计算,步骤如下:
- 分配内存:在主机端分配内存空间用于存储输⼊矩阵和输出矩阵,同时在GPU端分配内存空间用于存储相应的输入和输出数据。
- 数据传输:将输入矩阵数据从主机端内存传输到GPU端内存中。
- 核函数调用:在SYCL中,矩阵乘法的计算通常会在GPU上使用核函数来实现并行计算。核函数会分配线程块和线程来处理不同的数据块。
- 并行计算:在核函数中,每个线程负责计算输出矩阵的⼀个单独的元素。为了最大限度地利用GPU的并行计算能力,通常会使用⼆维线程块和线程网格的方式来处理矩阵的乘法计算。
- 数据传输:计算完成后,将输出矩阵数据从GPU端内存传输回主机端内存中,以便进⼀步处理或分析。在并行计算矩阵乘法时,可以利用线程块和线程的层次结构来优化计算。通过合理划分矩阵数据并利用共享内存来减少全局内存访问的次数,可以⼤幅提高计算效率。此外,还可以利用GPU上的多个计算单元并执行行矩阵乘法,进⼀步提高计算速度。
三、概览与声明
1、在本实验中,主要利用多种方法分别实现并行矩阵乘法,最终对几种方法进行对比分析。
2、声明:本实验是基于Intel官方并行矩阵乘法代码的指导,并在此基础上进行小修改。
四、实现一:基于SYCL基础并行矩阵乘法算法
说明:使用 SYCL 基本并行内核实现矩阵乘法。这是使用 SYCL 的最简单实现,没有任何优化。
4.1 选择加速设备
选择在哪个设备上执行后续的计算任务。选择的设备将被用作后续计算的目标设备,例如执行矩阵乘法的设备。oneAPI允许在不同的硬件加速器上执行相同的代码,从而提供更大的灵活性和性能优势。
import ipywidgets as widgets
device = widgets.RadioButtons(
options=['GPU Gen9', 'GPU Iris XE Max', 'CPU Xeon 6128', 'CPU Xeon 8153'],
value='CPU Xeon 6128',
description='Device:',
disabled=False
)
display(device)
4.2 用于矩阵乘法的SYCL内核
该内核实现了基本的矩阵乘法,可以在不同的设备上执行。
-
mm_kernel函数接受一个 SYCL 队列q以及三个矩阵的引用matrix_a、matrix_b和matrix_c,还有两个参数N和M分别表示矩阵的大小。 -
在函数内部,首先输出矩阵的大小信息。
-
创建了三个缓冲区(
buffer)a、b和c用于存储矩阵数据。这些缓冲区将在设备上进行计算。 -
使用
q.submit提交命令组(command group)到设备。在这个命令组中,创建了三个访问器(accessor),分别用于从主机内存拷贝数据到设备(A和B),以及从设备将结果拷贝回主机(C)。 -
h.parallel_for启动并行计算,通过二维索引访问矩阵元素。对于每个元素(i, j),使用一个内部循环对矩阵的第三个维度进行求和,计算矩阵乘法的结果。 -
c.get_access<access::mode::read>()确保在主机端等待内核执行完成,以便后续读取计算结果。 -
通过事件(
e)的 profiling 信息,计算并输出内核的执行时间。
在使用时,需要创建一个 SYCL 队列,并将输入矩阵传递给 mm_kernel 函数以执行矩阵乘法。
在代码的注释中,根据题目一的分析规划的步骤(分配内存、数据传输、核函数调用、并行计算、数据传输)进行说明。
%%writefile lab/basic_matrix.cpp
//版权归属:Copyright © 2021 Intel Corporation
#include <CL/sycl.hpp>
using namespace sycl;
void mm_kernel(queue &q, std::vector<float> &matrix_a, std::vector<float> &matrix_b, std::vector<float> &matrix_c, size_t N, size_t M) {
std::cout << "Configuration : MATRIX_SIZE= " << N << "x" << N << "\n";
//# 步骤1:分配内存。
//# 在这一步,使用SYCL的buffer类在主机端为输入矩阵 A、B 和输出矩阵 C 分配内存。
buffer a(matrix_a);
buffer b(matrix_b);
buffer c(matrix_c);
//# 提交要在设备上执行的命令组
auto e = q.submit([&](handler &h){
//# 步骤2:数据传输
//# 这里创建了三个访问器,分别对应于矩阵 A、B 和 C。这些访问器会在设备端访问对应的缓冲区。通过这些访问器,数据会在主机和设备之间传输。
auto A = a.get_access<access::mode::read>(h);
auto B = b.get_access<access::mode::read>(h);
auto C = c.get_access<access::mode::write>(h);
//# 步骤3和步骤4:核函数调用和并行计算矩阵乘法
h.parallel_for(range<2>{
N,N}, [=](item<2> item){
const int i = item.get_id(0);
const int j = item.get_id(1);
for (int k = 0; k < N; k++) {
C[i*N+j] += A[i*N+k] * B[k*N+j];
}
});
});
//# 步骤5:数据传输
//# 确保在主机端等待内核执行完成,以便后续读取计算结果。这样就完成了数据的传输,可以在主机端访问计算后的输出矩阵。
c.get_access<access::mode::read>();
//# print kernel compute duration from event profiling
auto kernel_duration = (e.get_profiling_info<info::event_profiling::command_end>() - e.get_profiling_info<info::event_profiling::command_start>());
std::cout << "Kernel Execution Time : " << kernel_duration / 1e+9 << " seconds\n";
}
执行脚本进行计算
#!/bin/bash
source /opt/intel/inteloneapi/setvars.sh > /dev/null 2>&1
# Command Line Arguments
arg=" -n 1024" # set matrix size
src="lab/"
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/intel/oneapi/compiler/latest/linux/lib
echo ====================
echo mm_dpcpp_basic
dpcpp ${src}mm_dpcpp_basic.cpp ${src}mm_dpcpp_common.cpp -o ${src}mm_dpcpp_basic -w -O3 -lsycl
./${src}mm_dpcpp_basic$arg
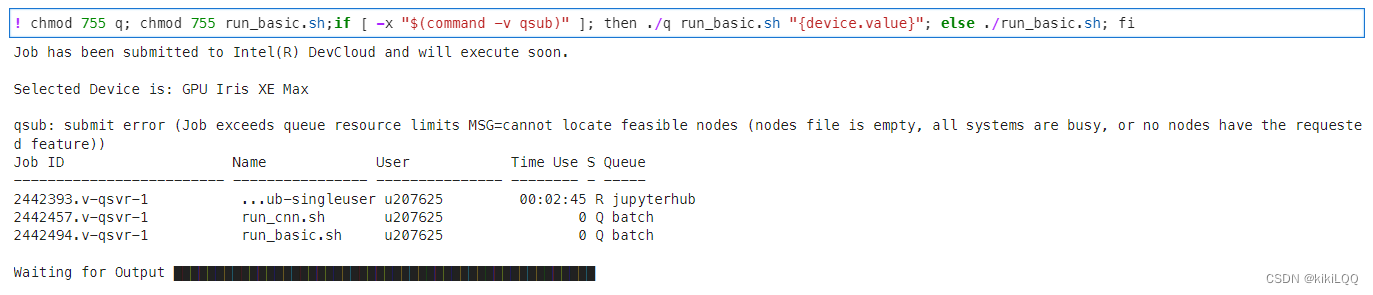
4.3 分析一:Roofline报告
在这里分别报告在两种不同的GPU硬件上,不同的数据矩阵大小( 1024 × 1024 1024\times 1024 1024×1024、 5120 × 5120 5120\times 5120 5120×5120、 10240 × 10240 10240\times 10240 10240×10240)进行矩阵计算的Roofline图。
4.3.1 Roofline图介绍
Roofline 图是一种用于性能分析的图表,特别是在高性能计算领域中被广泛使用。它通常用于可视化算法的性能,并帮助开发人员识别性能瓶颈和优化机会。
Roofline 图的横轴通常表示浮点运算性能(通常以每秒浮点运算次数 FLOP/s 为单位),纵轴表示性能效率(通常以每瓦特的性能为单位)。图中通常包含两个主要部分:
-
Roofline 带(Roof): 表示硬件性能的上限。这个带的形状通常是一个“屋顶”状,因此得名 Roofline 图。带的左侧通常表示内存带宽的上限,右侧表示计算性能的上限。 -
数据点: 表示不同算法或应用程序在性能-效率空间中的位置。每个数据点对应一个特定的算法或应用程序,并用一个点表示。这个点的横坐标表示算法的性能,纵坐标表示性能效率。一般情况下,希望数据点越接近 Roofline 带,性能效率越高。
在本实验中,使用红点标记关键数据点,表示基础的SYCL内核并行矩阵计算的性能和效率。
4.3.2 Roofline图展示
(篇幅限制,这里仅展示两张)
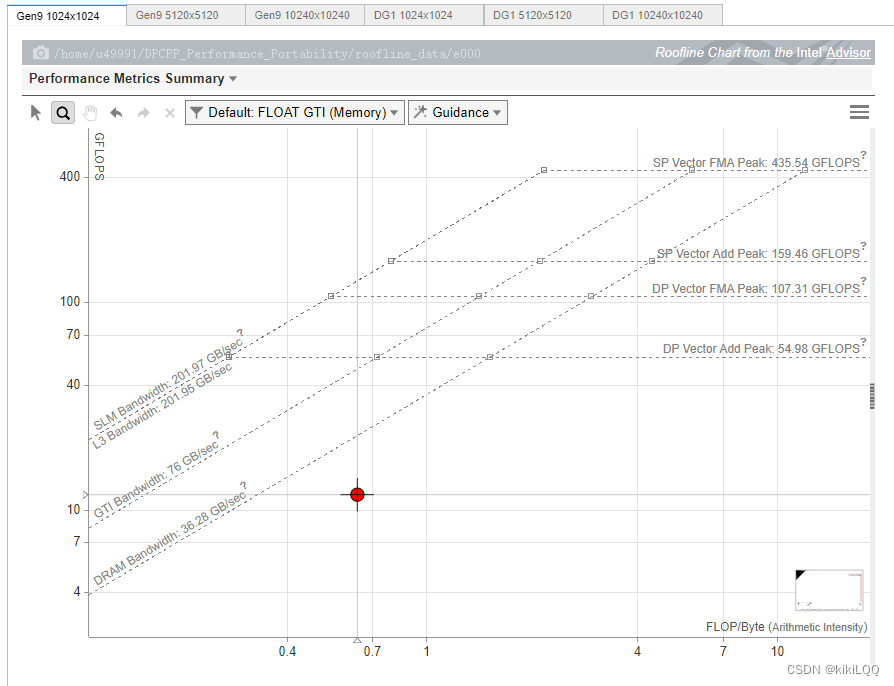
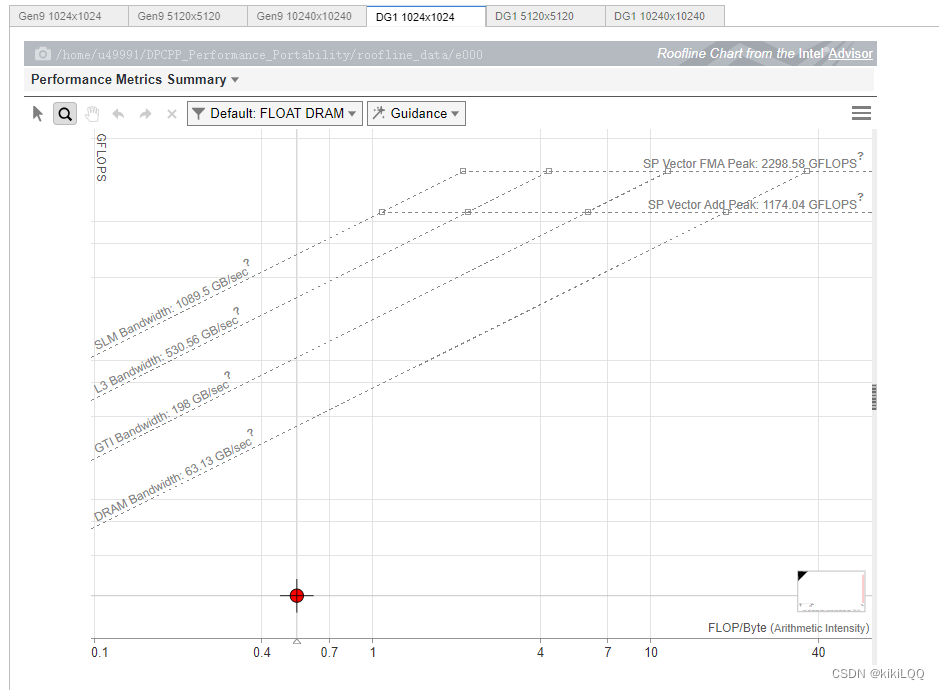
4.3.3 Roofline图分析
-
接近 Roofline 带的程度: 基础的基于SYCL的并行矩阵乘法的性能离Roofline 带较远,说明它并没有达到硬件性能的极限,即还有优化空间。
-
纵轴上的位置: 纵轴上的位置表示性能效率,根据图中的结果,发现数据点位置较低。在接下来的几种优化算法中,希望能够将数据点移动到更高的位置,提高性能效率。
-
横轴上的位置: 横轴上的位置表示算法的性能,根据图中的结果,可以发现数据点横轴值较小,在接下来的几种优化算法中,希望能够将数据点的横坐标提高,即提高算法的性能,使其更接近硬件性能的上限。
4.4 分析二: VTune™ Profiler分析
在本小节中,利用Intel VTune Profiler进行性能分析。
4.4.1 VTune Profiler介绍
VTune Profiler能够提供深入的性能分析,帮助开发人员找到和解决应用程序中的性能瓶颈。VTune Profiler支持多种分析功能,其中包括摘要(Summary)分析。
VTune Profiler摘要分析提供了对应用程序整体性能的高层次概览。以下是可以从摘要分析中获取的信息:
-
总体概览: VTune Profiler的摘要页面通常提供了关于应用程序整体性能的概览,包括总执行时间、CPU使用率、内存使用等信息。
-
Hotspots(热点): 热点是指在应用程序中执行时间最长的代码区域。摘要分析通常会列出这些热点,以便开发人员能够快速识别哪些部分是最耗时的。
-
函数级性能数据: 摘要分析还可能提供函数级别的性能数据,包括每个函数的执行时间、调用次数等信息。这可以帮助开发人员定位到需要优化的具体函数。
-
硬件事件: VTune Profiler可以收集与硬件事件相关的信息,如缓存命中率、指令执行数等。这些信息对于深入了解程序在硬件层面上的性能特征非常有用。
4.4.2 VTune Profiler结果展示
(篇幅限制,这里仅展示四张)
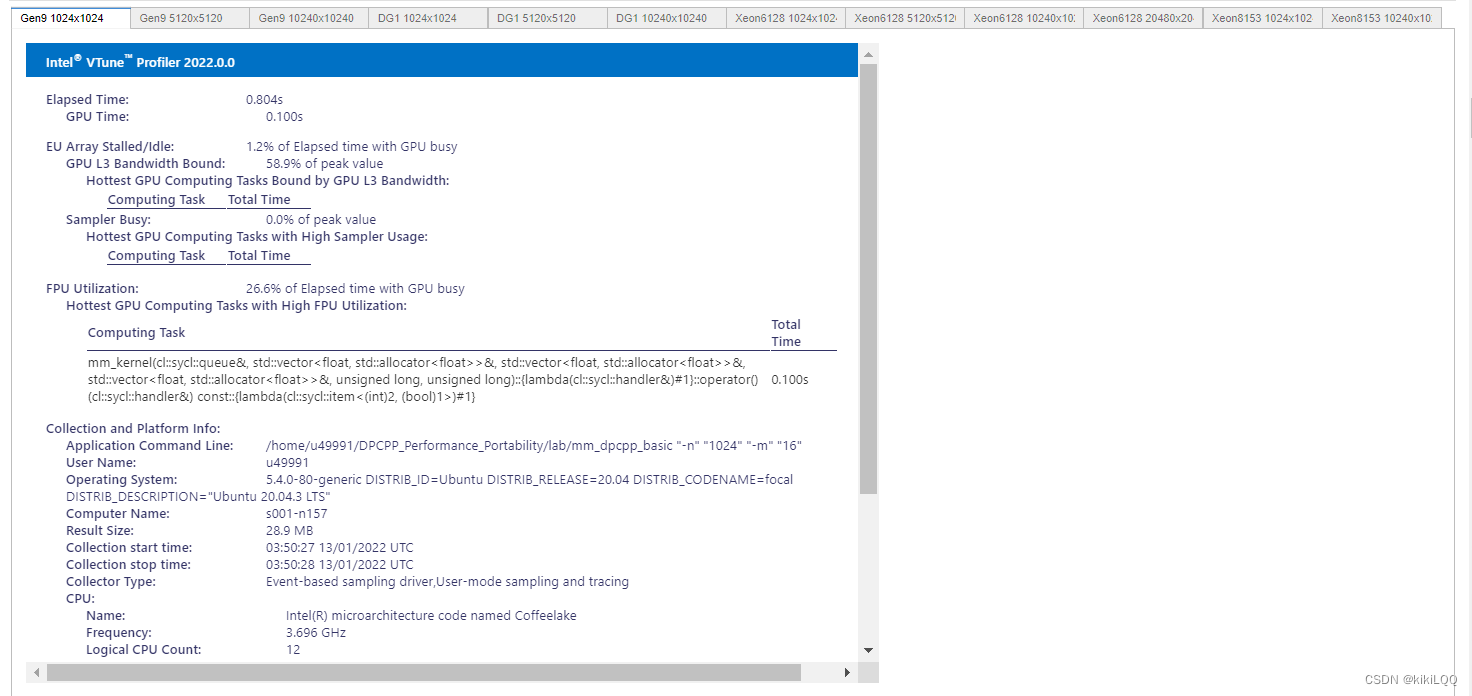
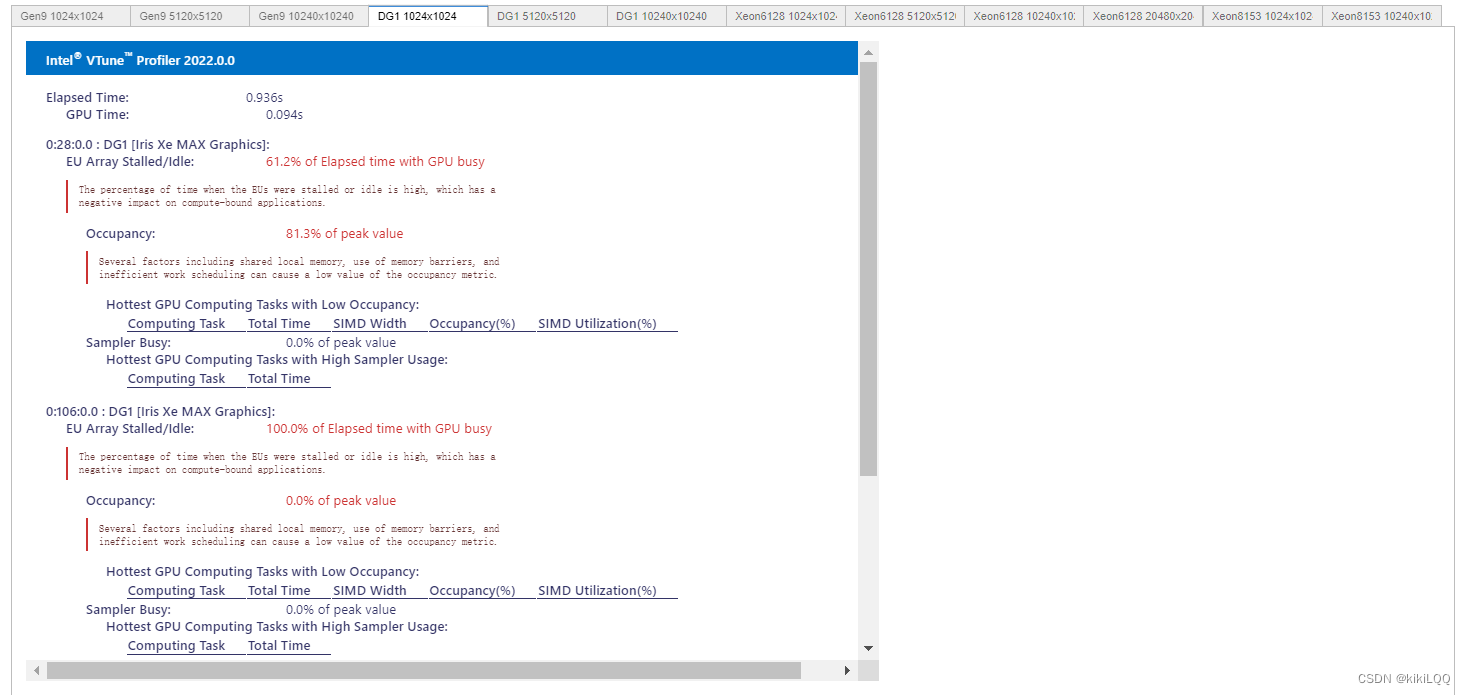
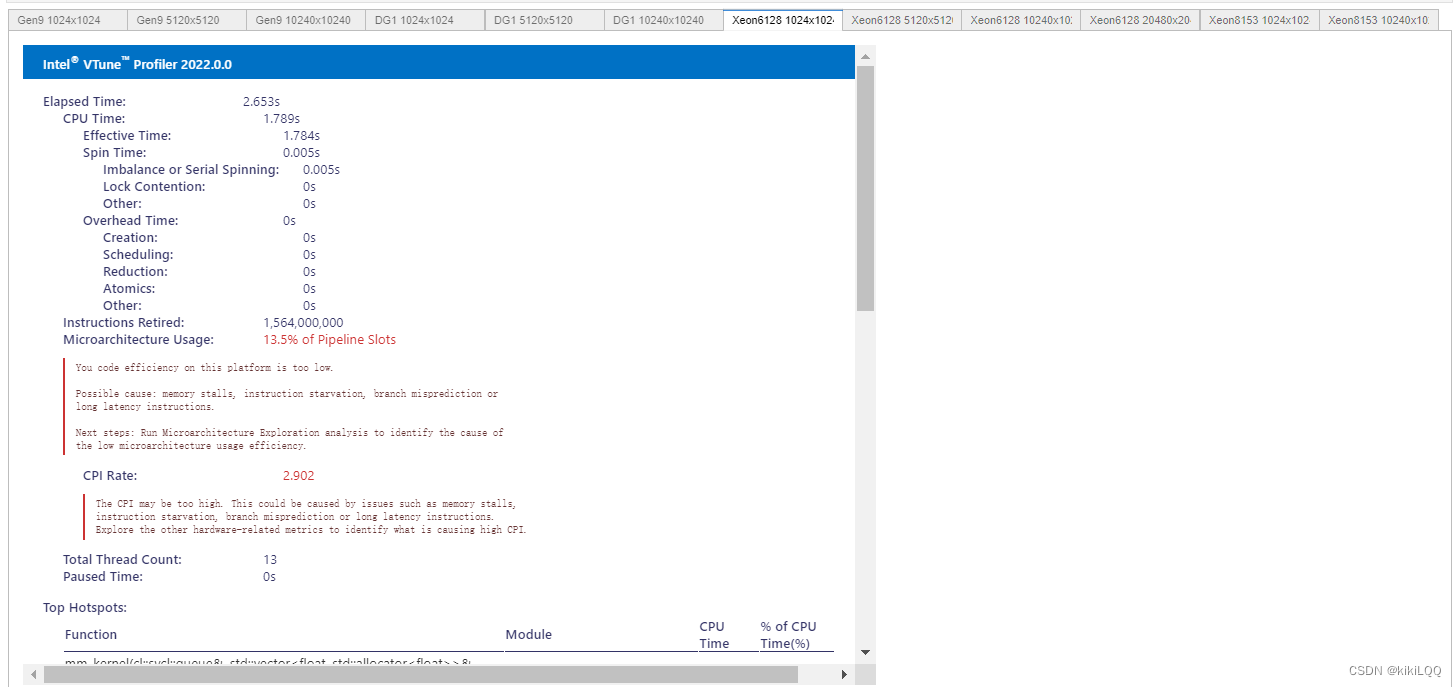
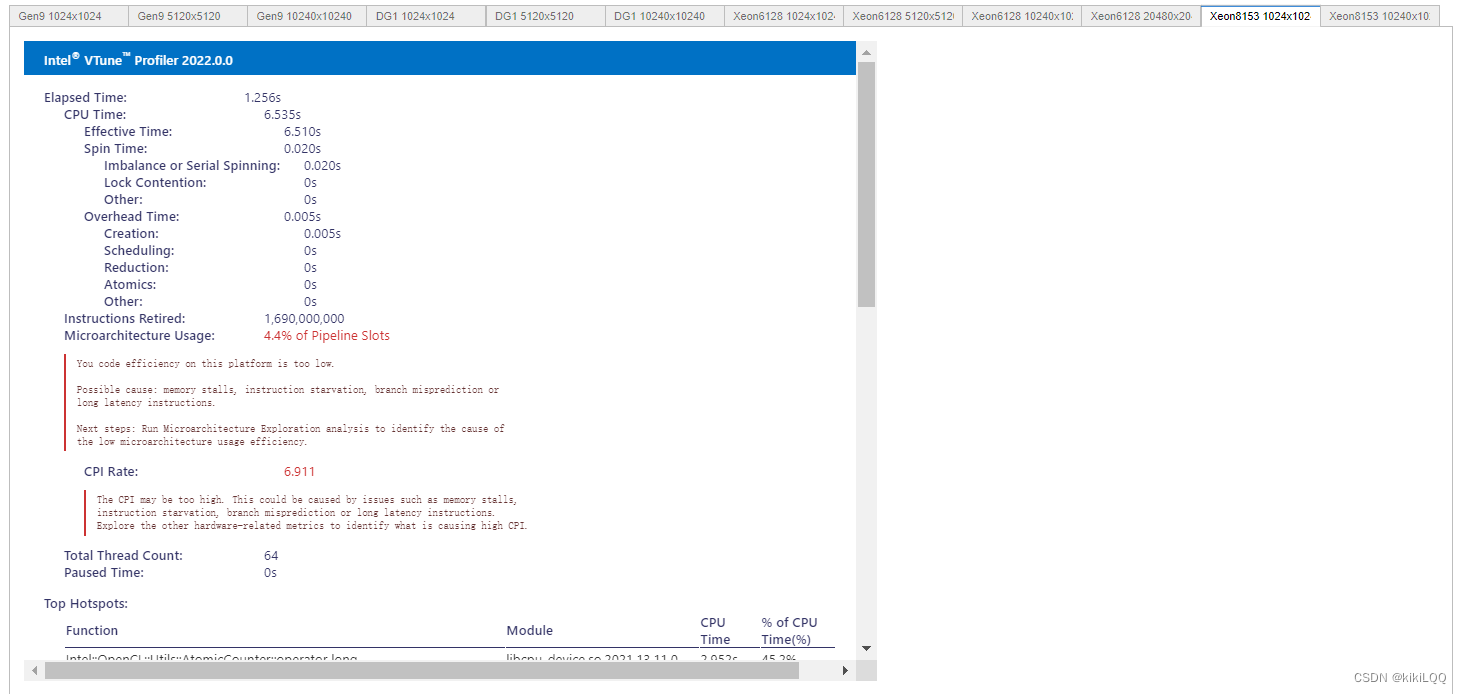
4.4.3 VTune™ Profiler分析结果
根据上表中的结果,可以观察到在不同硬件上运行效率的对比(在相同数据量的大小下GPU相较于CPU更快)、数据量大小对运行效率的影响。但总体而言,运行效率仍有优化提升空间。
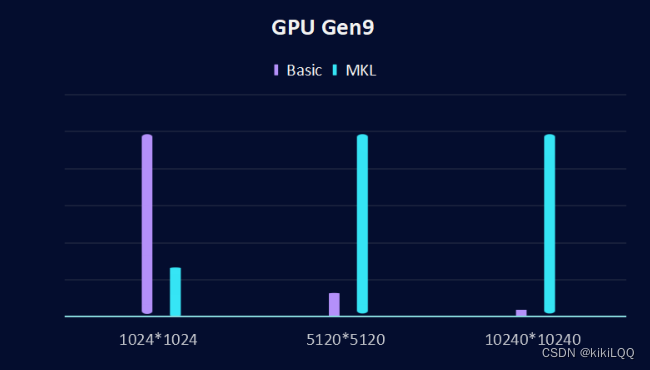
4.5 总结:与数学内核库速率对比
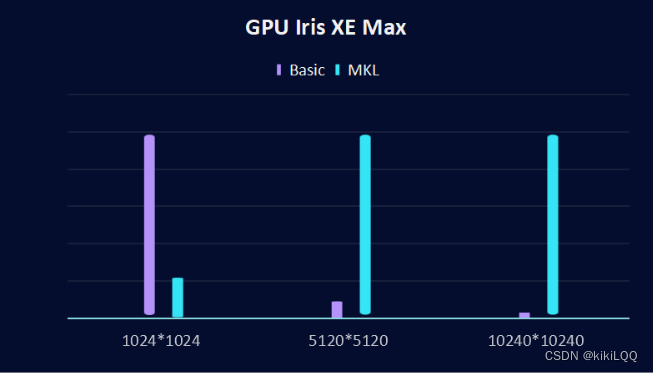
在基础实验部分,这里实现了使用SYCL实现在不同矩阵大小下的执行时间,根据与Intel发布的数学内核库时间的对比,可以发现,在小矩阵中(1024x1024),基础的SYCL实现的性能优于MKL实现,但是当增加了矩阵的大小,Intel测算的MKL的实现性能优于SYCL的实现。
在下面这张两张图中,分别在两个GPU下(GPU Gen9和GPU Iris XE Max)测试矩阵大小为1024x1024、5120x5120 和 10240x10240时,在不同硬件上的执行时间,绘制对比图如下:
1、GPU Gen9对比结果:
2、GPU Iris XE Max对比结果
五、实现二:基于ND-Range内核的性能优化
5.1 算法描述
5.1.1 ND-range内核描述
之前的基础计算方法无法在硬件层面进行性能优化。本节中,使用ND-Range 内核来表达并行性,通过提供对全局和本地内存的访问,并将执行映射到硬件上的计算单元,实现更低层次的性能调整。在这个过程中,将整个迭代空间划分为更小的组,称为工作组。工作项被组织到这些工作组中,并在硬件上的单个计算单元上进行调度。
工作组的大小必须在每个维度上精确划分整个迭代空间的大小。这些尺寸因硬件平台而异,可以通过使用下面的设备查询来确定可能的尺寸。为了找到最佳的组合,开发人员必须考虑工作负载。
将内核执行分组为工作组有助于控制资源使用和负载平衡工作分配。nd_range 类使用全局执行范围和每个工作组的本地执行范围来表示分组执行范围。nd_item 类表示内核函数的单个实例,允许查询工作组范围和索引。
5.1.2 基于ND-Range内核的矩阵乘法运算算法描述
在下例中,是演示使用 ND-Range 内核计算矩阵乘法。工作组大小取决于加速器的硬件能力,因此使用命令行参数设置工作组大小。有些硬件要求矩阵大小与工作组大小相等,本实验中默认使用工作组大小为 16x16 (256)以适用于要测试的所有加速器硬件。
这里补充矩阵计算算法的图
5.2 算法实现
算法实现步骤如下:
-
mm_kernel函数定义了矩阵乘法的核心计算逻辑,并将其封装在 SYCL 的queue对象中。这个函数接受一个队列q,以及三个矩阵matrix_a、matrix_b和matrix_c,以及矩阵的大小N和工作组大小M。 -
通过
buffer类创建了三个缓冲区a、b和c,用于在设备上存储输入和输出数据。这里的matrix_a、matrix_b和matrix_c分别是输入矩阵A、B和输出矩阵C的数据。 -
使用
queue::submit向设备提交一个命令组。在这个命令组中,定义了一个handler对象h,它用于设置与设备交互的各种操作。 -
在命令组内,首先通过
get_access创建了访问器A、B和C,用于在设备上访问缓冲区中的数据。mode::read表示对应的访问器是只读的,而mode::write表示对应的访问器是可写的。 -
然后,定义了
range<2>类型的global_size和work_group_size,分别表示全局大小和工作组大小。这里使用了二维的 ND-Range,其中N表示矩阵的维度。 -
在
parallel_for中,通过nd_range<2>定义了全局大小和工作组大小,以及一个 lambda 函数作为并行执行的内核。在这个内核中,每个工作项(线程)根据其全局ID获取矩阵的特定元素,然后进行矩阵乘法的累加运算。 -
最后,通过
get_profiling_info获取内核执行时间,并打印出来。
这个代码的关键在于使用了 ND-Range 的并行计算模型,通过将工作项映射到矩阵的不同元素上,实现了矩阵乘法的并行计算。这可以显著提高矩阵乘法的计算性能(特别是在大规模矩阵上)。
%%writefile lab/mm_dpcpp_ndrange.cpp
//==============================================================
// 矩阵乘法:SYCL ND-Range
// 版权归属:Copyright © 2021 Intel Corporation
//==============================================================
#include <CL/sycl.hpp>
using namespace sycl;
// SYCL ND-Range 矩阵乘法内核函数
void mm_kernel(queue &q, std::vector<float> &matrix_a, std::vector<float> &matrix_b, std::vector<float> &matrix_c, size_t N, size_t M) {
std::cout << "配置 : MATRIX_SIZE= " << N << "x" << N << " | WORK_GROUP_SIZE= " << M << "x" << M << "\n";
//# 为矩阵创建缓冲区
buffer a(matrix_a);
buffer b(matrix_b);
buffer c(matrix_c);
//# 提交命令组以在设备上执行
auto e = q.submit([&](handler &h){
//# 创建访问器以将缓冲区复制到设备
auto A = a.get_access<access::mode::read>(h);
auto B = b.get_access<access::mode::read>(h);
auto C = c.get_access<access::mode::write>(h);
//# 定义 ND-Range 和工作组大小
range<2> global_size(N,N);
range<2> work_group_size(M,M);
//# 并行计算矩阵乘法
h.parallel_for(nd_range<2>{
global_size, work_group_size}, [=](nd_item<2> item){
const int i = item.get_global_id(0);
const int j = item.get_global_id(1);
for (int k = 0; k < N; k++) {
C[i*N+j] += A[i*N+k] * B[k*N+j];
}
});
});
c.get_access<access::mode::read>();
//# 从事件分析中打印内核计算持续时间
auto kernel_duration = (e.get_profiling_info<info::event_profiling::command_end>() - e.get_profiling_info<info::event_profiling::command_start>());
std::cout << "内核执行时间 : " << kernel_duration / 1e+9 << " 秒\n";
}
5.3 分析一:Roofline报告
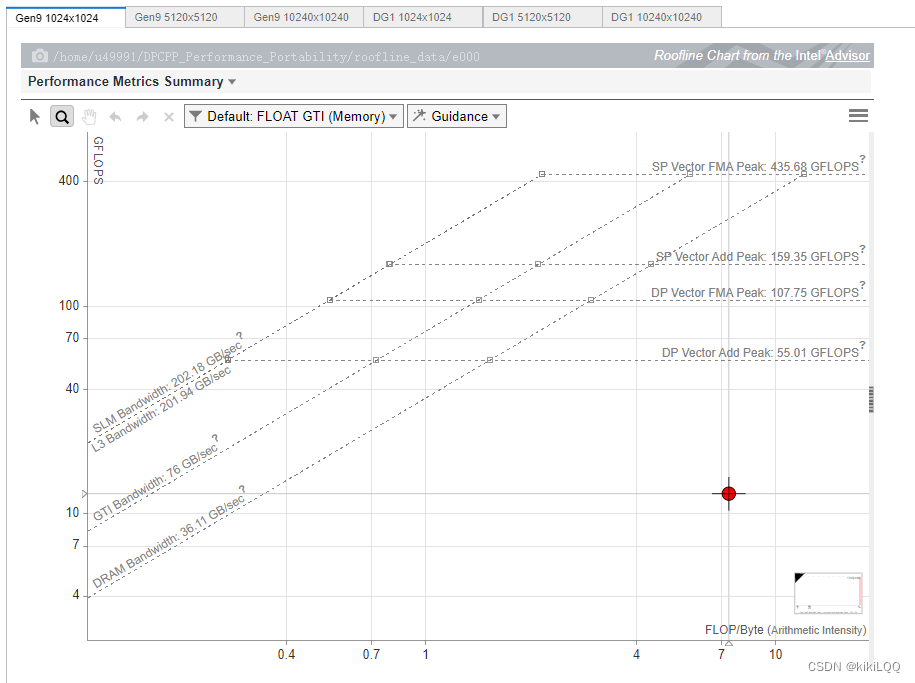
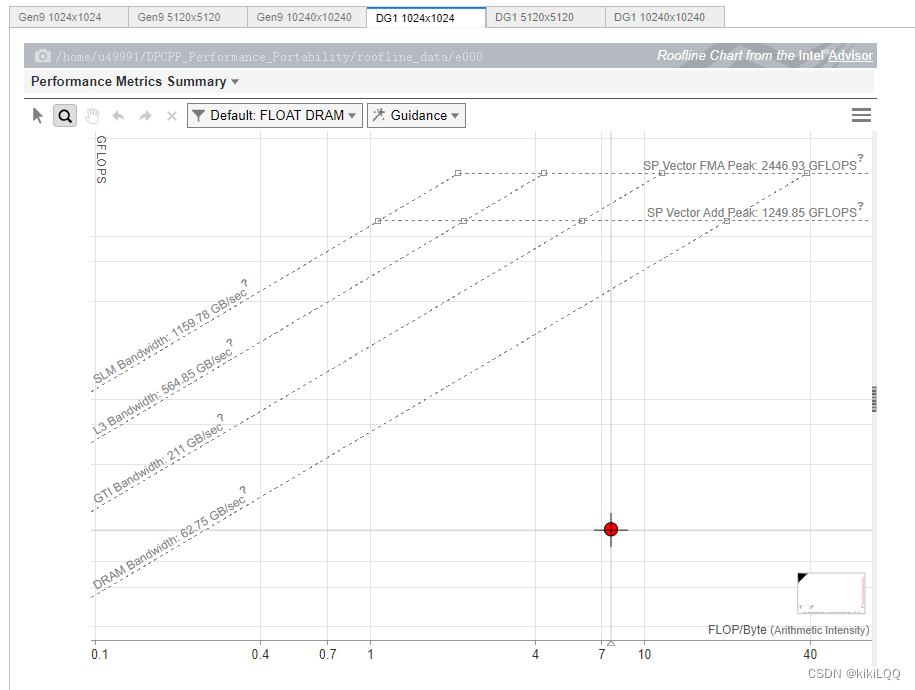
在这里分别报告在两种不同的GPU硬件上,不同的数据矩阵大小( 1024 × 1024 1024\times 1024 1024×1024、 5120 × 5120 5120\times 5120 5120×5120、 10240 × 10240 10240\times 10240 10240×10240)的Roofline图。
5.3.1 Roofline图展示
(篇幅限制,这里仅展示两张)
5.3.2 Roofline图分析
-
接近 Roofline 带的程度: 基于ND-Range内核的性能优化相交于基础的SYCL的并行矩阵乘法,性能离Roofline更近,说明它有提升,但仍然还有优化空间。
-
纵轴上的位置: 纵轴上的位置表示性能效率,根据图中的结果,发现数据点位置相较于基础的算法有明显提升。
-
横轴上的位置: 横轴上的位置表示算法的性能,根据图中的结果,可以发现数据点相较于基础的并行计算算法,明显右移,说明有明显提升。
5.4 分析二: VTune™ Profiler分析
在本小节中,利用Intel VTune Profiler进行性能分析。
5.4.1 VTune Profiler结果展示
(篇幅限制,这里仅展示四张)
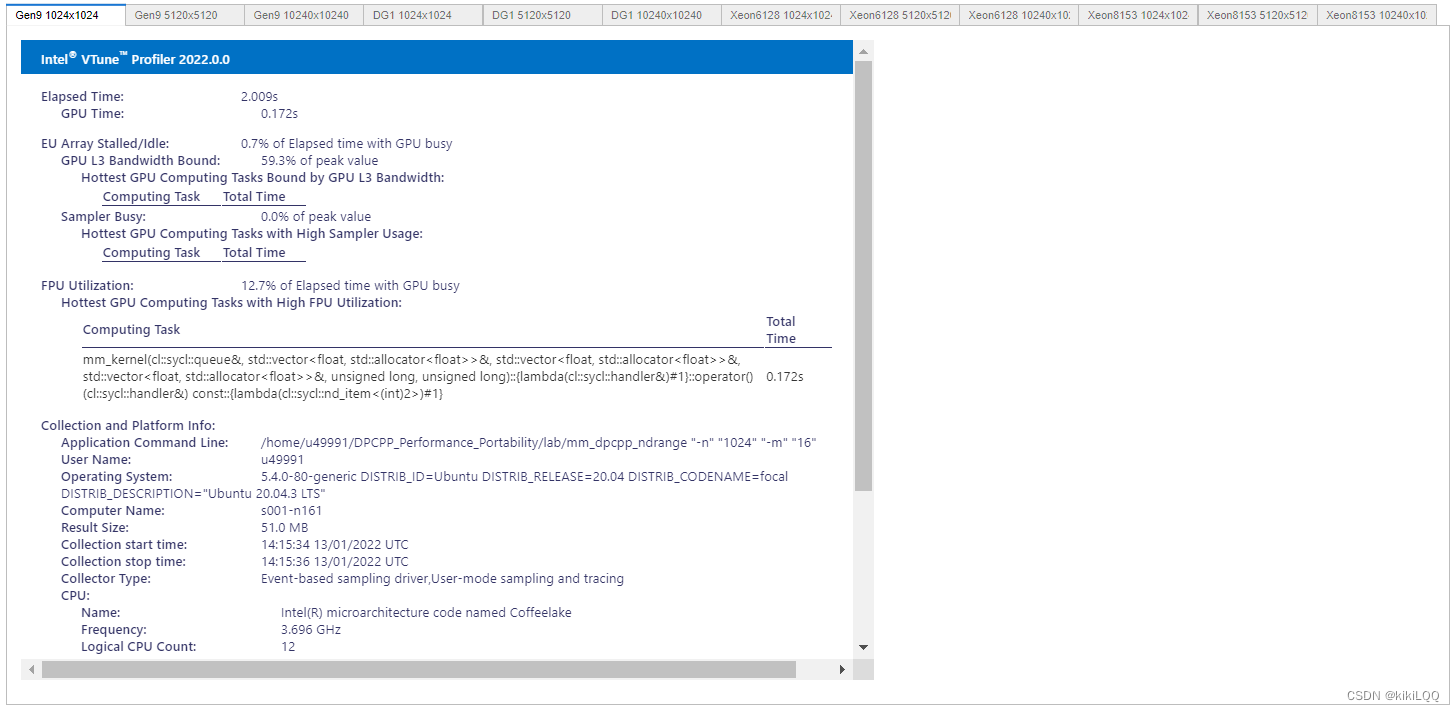
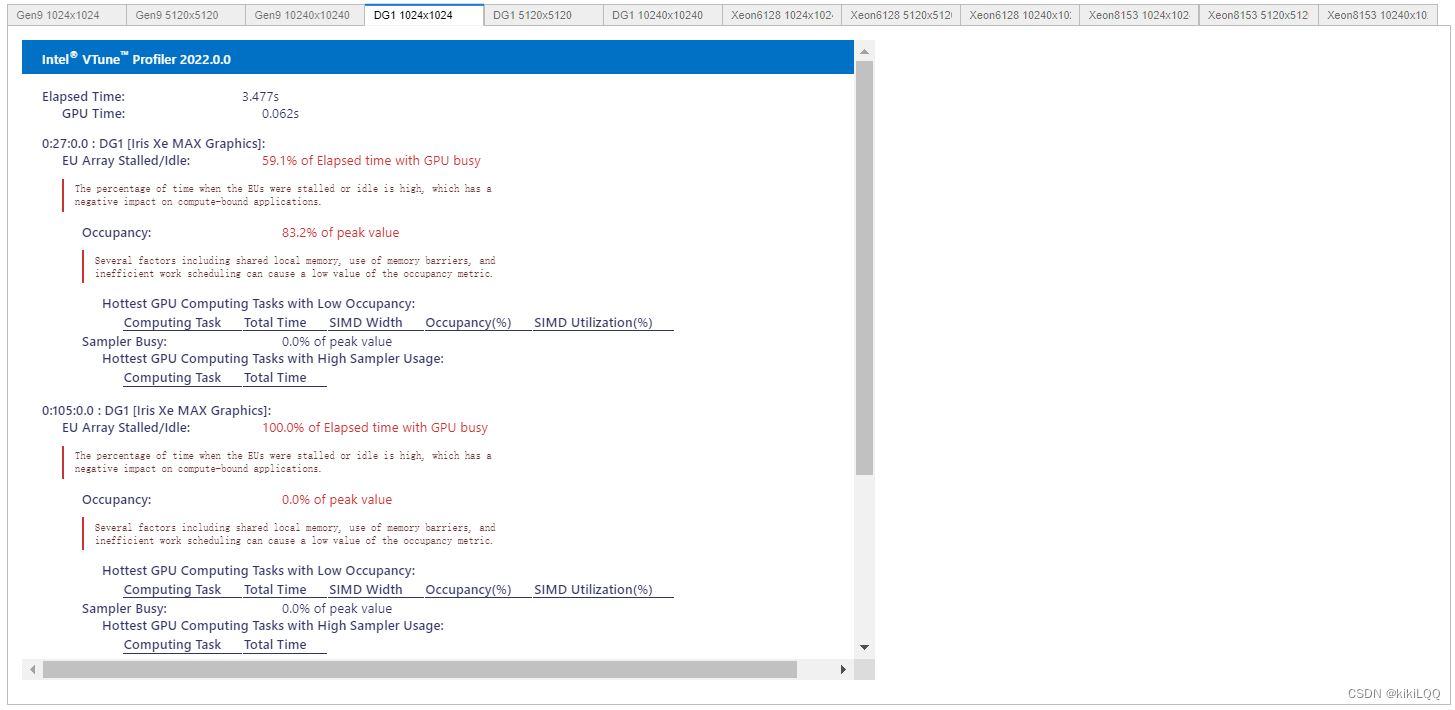
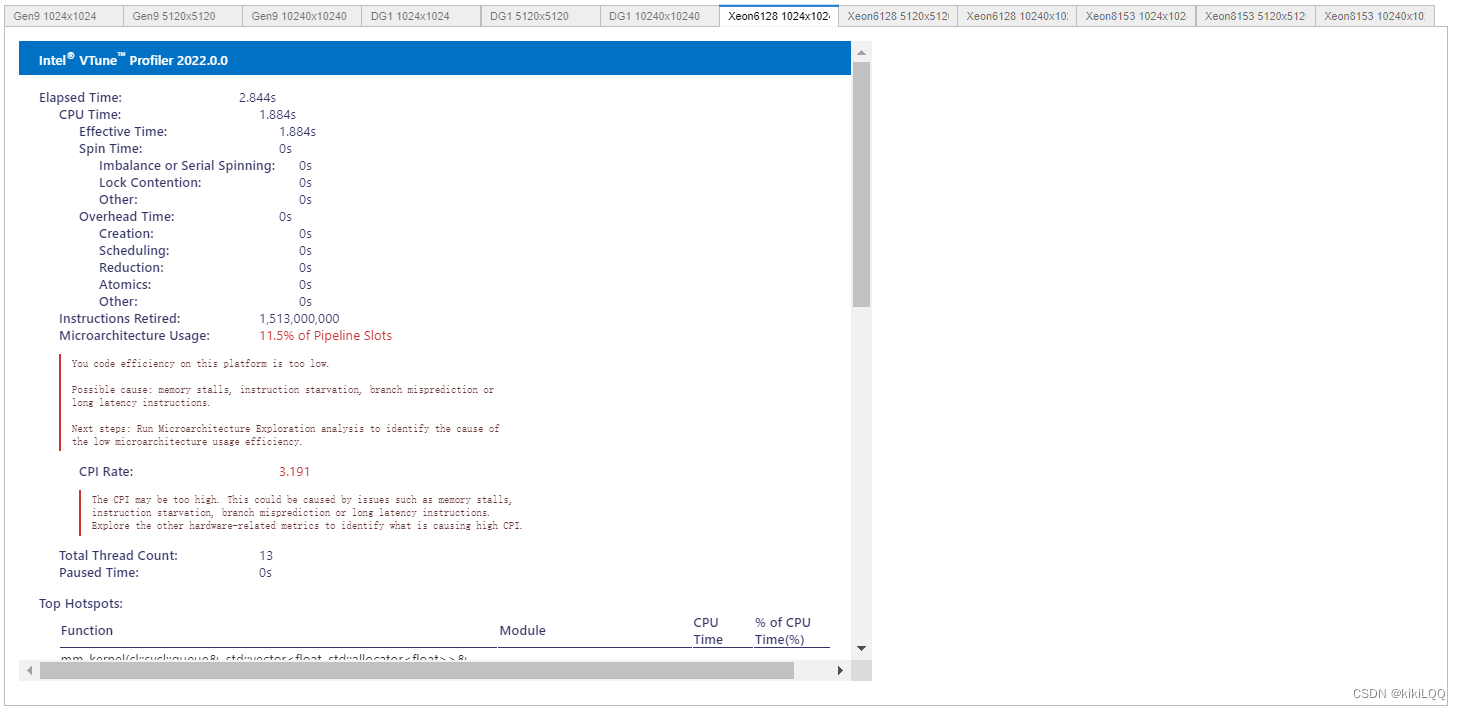
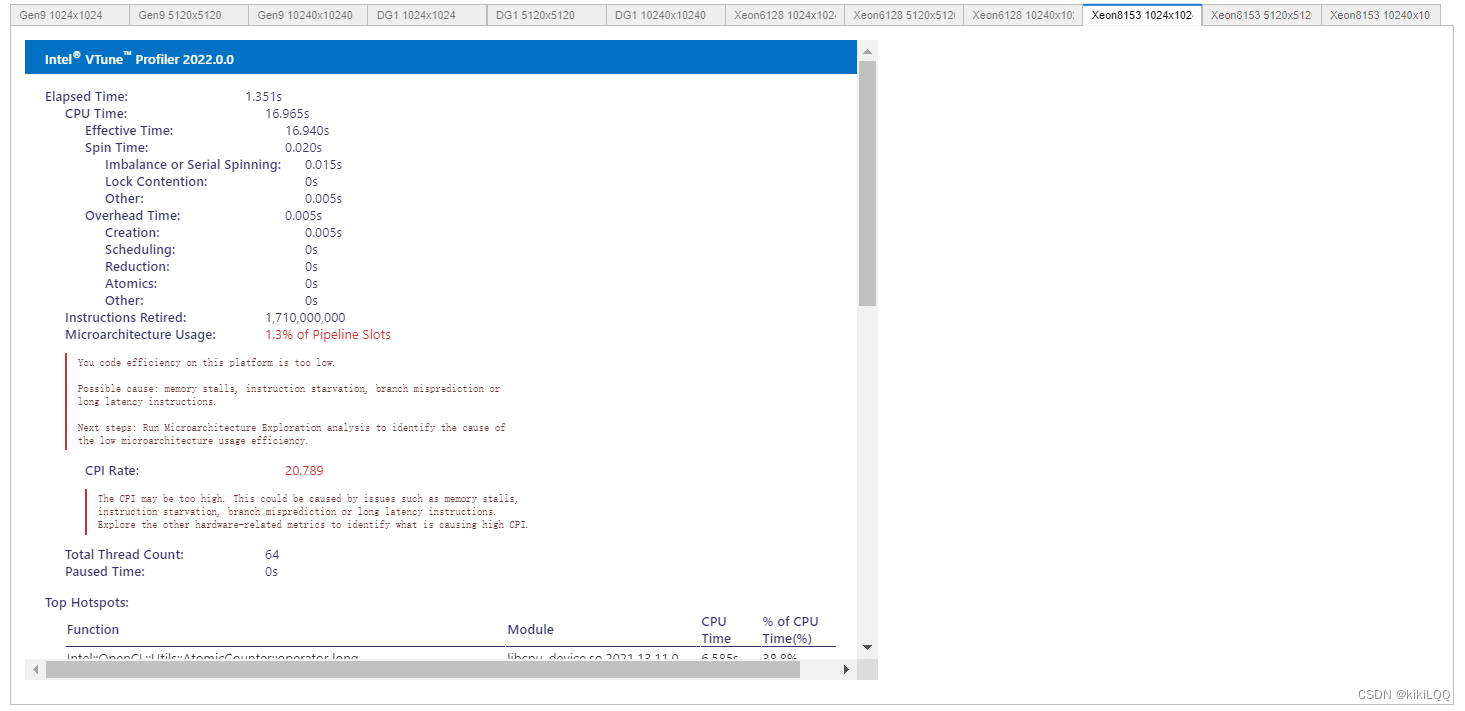
5.4.2 VTune Profiler结果分析
根据上述结果,矩阵和工作组的大小都会影响内核在不同平台上的性能。但在相同的条件下,与基础的算法相比,不同的硬件上的性能都有所提高,即获得了更好的优化,数组大小越大,效果越明显。
5.5 优化设计
如果能将循环中的中间结果写入内核,该变量将转化为加速器硬件中的寄存器。就可以最大限度地减少了全局内存写入次数,也就意味着提高了性能,因为每个工作组只写回一次结果。 这里简单展示代码运行:
%%writefile lab/mm_dpcpp_ndrange_var.cpp
//==============================================================
// 矩阵乘法:SYCL ND-range 私有内存
// 版权归属:Copyright © 2021 Intel Corporation
//==============================================================
#include <CL/sycl.hpp>
using namespace sycl;
void mm_kernel(queue &q, std::vector<float> &matrix_a, std::vector<float> &matrix_b, std::vector<float> &matrix_c, size_t N, size_t M) {
std::cout << "配置信息 : MATRIX_SIZE= " << N << "x" << N << " | WORK_GROUP_SIZE= " << M << "x" << M << "\n";
//# 为矩阵创建缓冲区
buffer a(matrix_a);
buffer b(matrix_b);
buffer c(matrix_c);
//# 提交命令组以在设备上执行
auto e = q.submit([&](handler &h){
//# 创建访问器以将缓冲区复制到设备
auto A = a.get_access<access::mode::read>(h);
auto B = b.get_access<access::mode::read>(h);
auto C = c.get_access<access::mode::write>(h);
//# 定义 ND-Range 和工作组大小
range<2> global_size(N, N);
range<2> work_group_size(M, M);
//# 并行计算矩阵乘法
h.parallel_for(nd_range<2>{
global_size, work_group_size}, [=](nd_item<2> item){
const int i = item.get_global_id(0);
const int j = item.get_global_id(1);
//# 使用私有内存存储中间结果
float temp = 0.f;
for (int k = 0; k < N; k++) {
temp += A[i * N + k] * B[k * N + j];
}
C[i * N + j] = temp;
});
});
c.get_access<access::mode::read>();
//# 从事件分析中打印内核计算持续时间
auto kernel_duration = (e.get_profiling_info<info::event_profiling::command_end>() - e.get_profiling_info<info::event_profiling::command_start>());
std::cout << "内核执行时间 : " << kernel_duration / 1e+9 << " 秒\n";
}
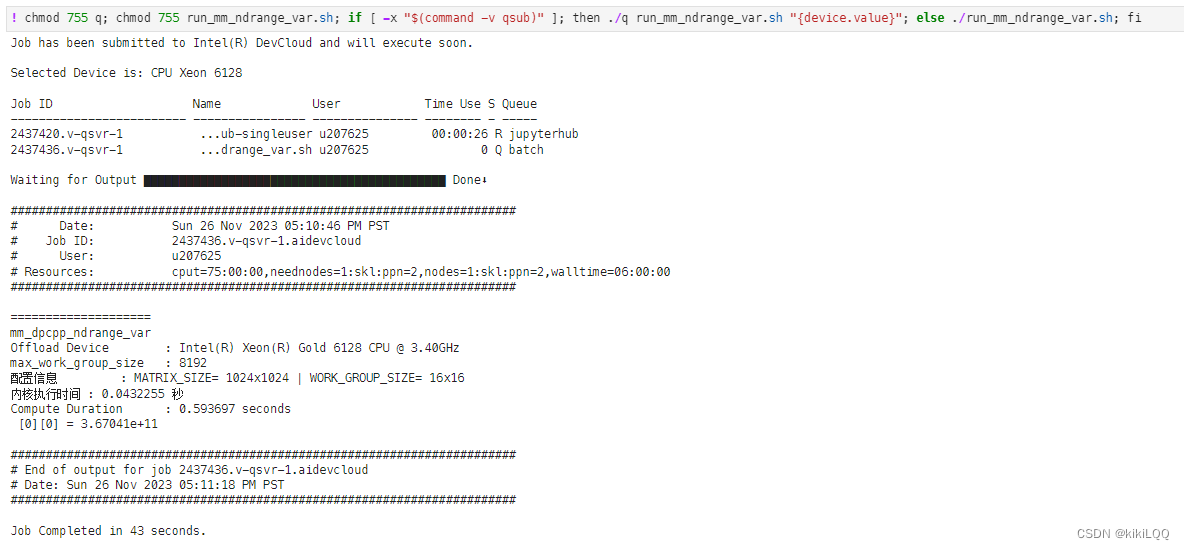
5.6 总结
使用 ND-Range 算法实现并行矩阵乘法相对于直接进行并行矩阵乘法效果更优,其原因主要有以下几点:
-
更灵活的并行度控制: ND-Range 模型允许更灵活地控制全局大小和工作组大小。通过合理地设置这些参数,以更好地适应不同的硬件架构和矩阵大小。这种灵活性有助于充分发挥硬件并行性,以获得更好的性能。
-
适应不同设备: ND-Range 模型是为不同类型的并行硬件设计的,包括多核 CPU、GPU 和加速器等。通过使用 ND-Range,可以编写更通用的代码,使其能够在不同类型的设备上运行,并更好地利用这些设备的并行性。
-
负载均衡: ND-Range 模型有助于实现更好的负载均衡。每个工作项在矩阵的不同位置执行,这有助于避免工作项之间的不均匀负载分布。相比之下,简单的并行模型可能导致某些工作组处理的数据量过大,而另一些工作组处理的数据量较小,从而导致负载不均衡。
-
数据局部性: ND-Range 模型有助于利用数据的局部性。每个工作项只关注矩阵中的特定元素,这有助于提高缓存的命中率,减少内存访问的延迟,从而提高性能。
-
硬件层面的优化: ND-Range 模型允许编译器和硬件执行更多的优化。这是因为 ND-Range 提供了更多的信息,编译器和硬件可以更好地了解工作项之间的依赖关系和并行性,从而更好地进行指令调度和资源分配。
总体而言,ND-Range 模型提供了更高级别的抽象,使得并行算法的实现更加灵活和可移植,有助于更好地发挥并行硬件的性能,因而相较于本是严重的第一种算法,具有更好的性能。
此外,将使用了私有内存的方法与普通的ND-Range方法效果进行对比,运行结果如下:
1、GPU Gen9对比结果:

2、GPU Iris XE Max对比结果
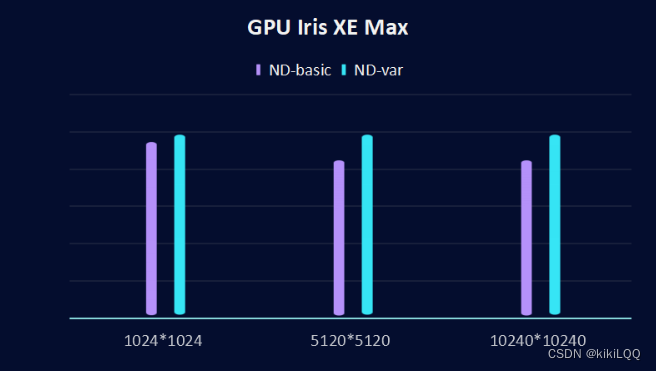
根据图表中的结果,发现使用私有内存后,在相同硬件(GPU)和相同矩阵大小下,引入私有内存优化后,效果得到了进一步的提升。
六、实现三:本地内存实现优化并行矩阵乘法
6.1 共享本地内存(SLM)优化描述
-
数据加载到本地内存: 矩阵乘法中的数据在计算中具有高度的复用性。因此,算法的第一步是将待计算的矩阵 A 和 B 加载到每个工作组的本地内存中。这样一来,工作组内的工作项可以更快地访问数据,减少了从全局内存加载数据的延迟。
-
本地内存的生命周期: 本地内存在每个工作组开始时被初始化,并在工作组执行结束后被丢弃。这意味着本地内存主要用于在工作组执行期间临时存储数据,而不会在工作组之间共享。
-
本地访问器的使用: 为了声明本地内存,本地访问器被引入。在描述中提到的 A_tile 和 B_tile 就是这样的本地访问器,用于加载 16x16 的数据块。这些本地访问器在计算中间结果时发挥作用,并且这些中间结果不需要反复使用全局内存计算。
-
工作组内通信的优化: 为了加速工作组内的通信,算法引入了一个专门用于工作组内通信的本地内存空间。这个特殊的本地内存空间有助于简化内核的开发,并提高工作组内工作项之间的通信效率。
-
屏障的引入: 为了确保工作组内的所有工作项都完成了本地内存的读写操作,屏障被引入。这有助于同步工作组内的工作项,以确保正确的计算结果。
-
性能提升: 相对于最初的 ND 范围样本和使用本地内存的 ND 范围样本,这个算法在性能上有所提升。特别是在一些设备上,如许多 GPU 设备,由于本地内存是专门的资源,通过本地内存进行通信可能比通过全局内存更高效。
综合来说,通过在算法中引入本地内存和相应的优化手段,可以有效地提高矩阵乘法的并行计算性能。
6.2 代码实现
%%writefile lab/mm_dpcpp_localmem.cpp
//==============================================================
// Matrix Multiplication: SYCL Local Accessor
// 版权归属:Copyright © 2021 Intel Corporation
//==============================================================
#include <CL/sycl.hpp>
using namespace sycl;
void mm_kernel(queue &q, std::vector<float> &matrix_a, std::vector<float> &matrix_b, std::vector<float> &matrix_c, size_t N, size_t M) {
std::cout << "Configuration : MATRIX_SIZE= " << N << "x" << N << " | WORK_GROUP_SIZE= " << M << "x" << M << "\n";
//# Create buffers for matrices
buffer a(matrix_a);
buffer b(matrix_b);
buffer c(matrix_c);
//# Submit command groups to execute on device
auto e = q.submit([&](handler &h){
//# Create accessors to copy buffers to the device
auto A = a.get_access<access::mode::read>(h);
auto B = b.get_access<access::mode::read>(h);
auto C = c.get_access<access::mode::write>(h);
//# Define size for ND-range and work-group size
range<2> global_size(N,N);
range<2> work_group_size(M,M);
//# Create local accessors
accessor<float, 2, access::mode::read_write, access::target::local> A_tile(range<2>(M, M), h);
accessor<float, 2, access::mode::read_write, access::target::local> B_tile(range<2>(M, M), h);
//# Parallel Compute Matrix Multiplication
h.parallel_for(nd_range<2>{
global_size, work_group_size}, [=](nd_item<2> item){
const int i = item.get_global_id(0);
const int j = item.get_global_id(1);
const int x = item.get_local_id(0);
const int y = item.get_local_id(1);
float temp = 0.f;
int k;
for (int t = 0; t < N; t+=M) {
A_tile[x][y] = A[i * N + (t + y)];
B_tile[x][y] = B[(t + x) * N + j];
item.barrier(access::fence_space::local_space);
for (k = 0; k < M; k++) {
temp += A_tile[x][k] * B_tile[k][y];
}
item.barrier(access::fence_space::local_space);
}
C[i*N+j] = temp;
});
});
c.get_access<access::mode::read>();
//# print kernel compute duration from event profiling
auto kernel_duration = (e.get_profiling_info<info::event_profiling::command_end>() - e.get_profiling_info<info::event_profiling::command_start>());
std::cout << "Kernel Execution Time : " << kernel_duration / 1e+9 << " seconds\n";
}
执行脚本运行如下:
6.3 分析一:Roofline报告
在这里分别报告在两种不同的GPU硬件上,不同的数据矩阵大小( 1024 × 1024 1024\times 1024 1024×1024、 5120 × 5120 5120\times 5120 5120×5120、 10240 × 10240 10240\times 10240 10240×10240)的Roofline图。
6.3.1 Roofline图展示
(篇幅限制,这里仅展示两张)
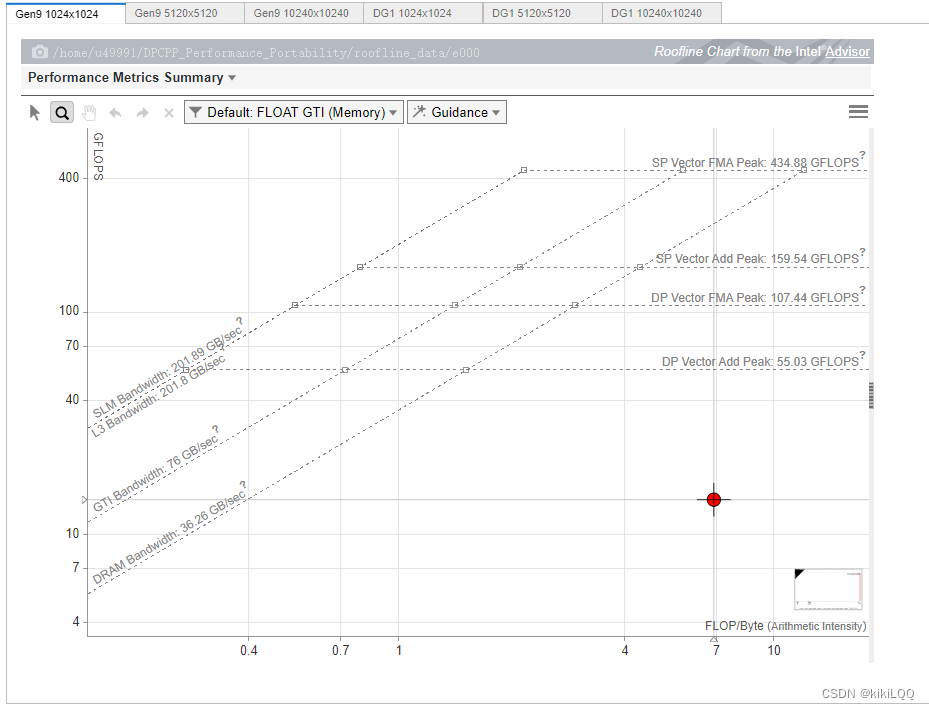

6.3.2 Roofline图分析
-
接近 Roofline 带的程度: 使用共享本地内存(SLM)优化算法,相较于上一节中基于ND-Range内核的性能优化,性能离Roofline更近,说明它有提升,但仍然还有优化空间。
-
纵轴上的位置: 纵轴上的位置表示性能效率,根据图中的结果,发现数据点位置相较于前述几种算法有明显提升。
-
横轴上的位置: 横轴上的位置表示算法的性能,根据图中的结果,可以发现数据点相较于前述几种并行计算算法,明显右移,说明有明显提升。
6.4 分析二: VTune™ Profiler分析
在本小节中,利用Intel VTune Profiler进行性能分析。
6.4.1 VTune Profiler结果展示
(篇幅限制,这里仅展示四张)
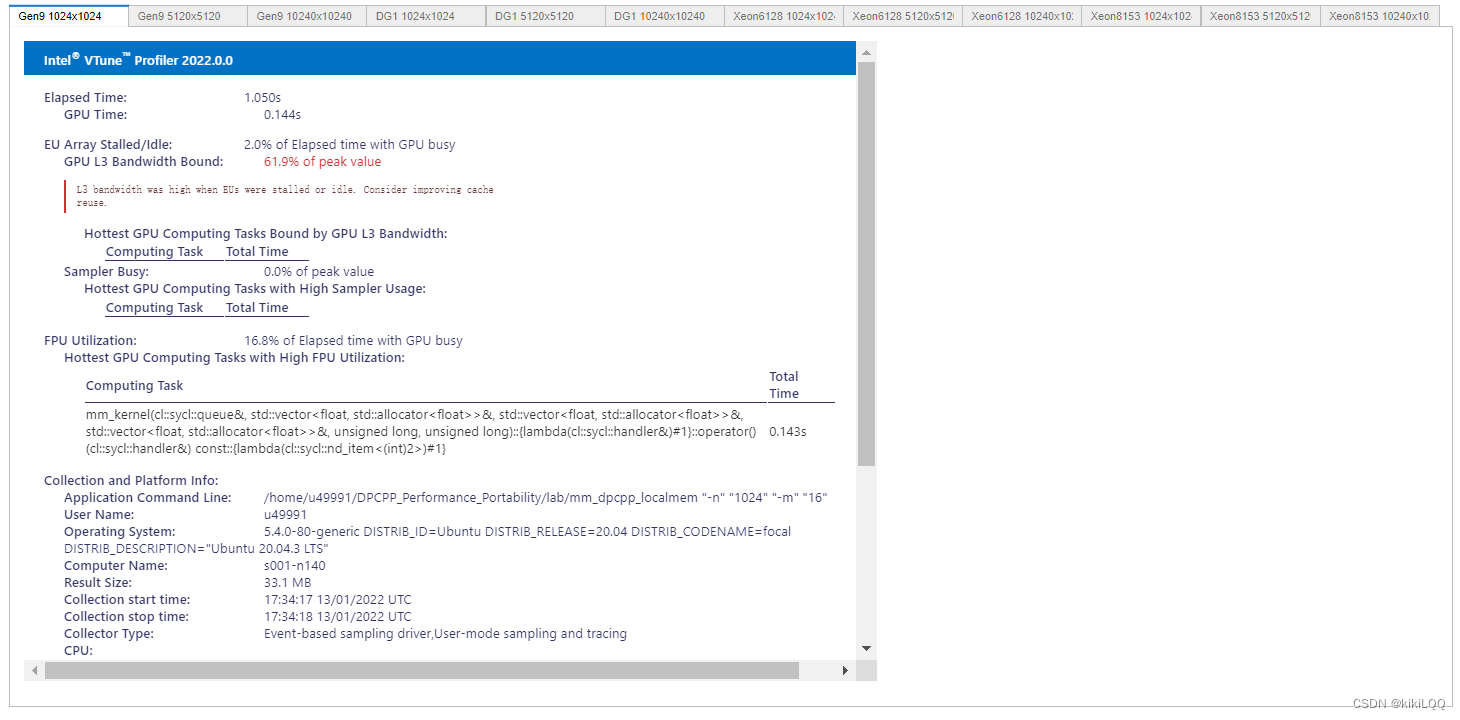
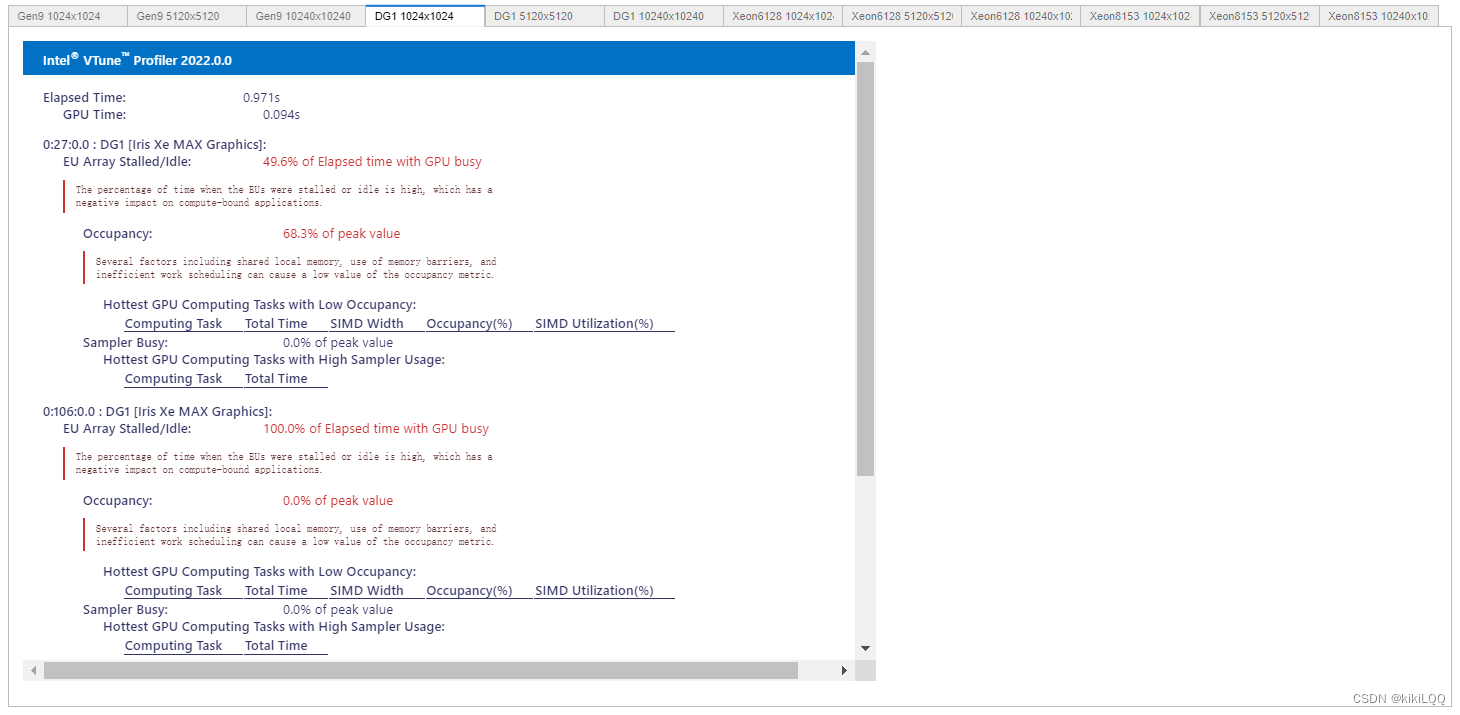
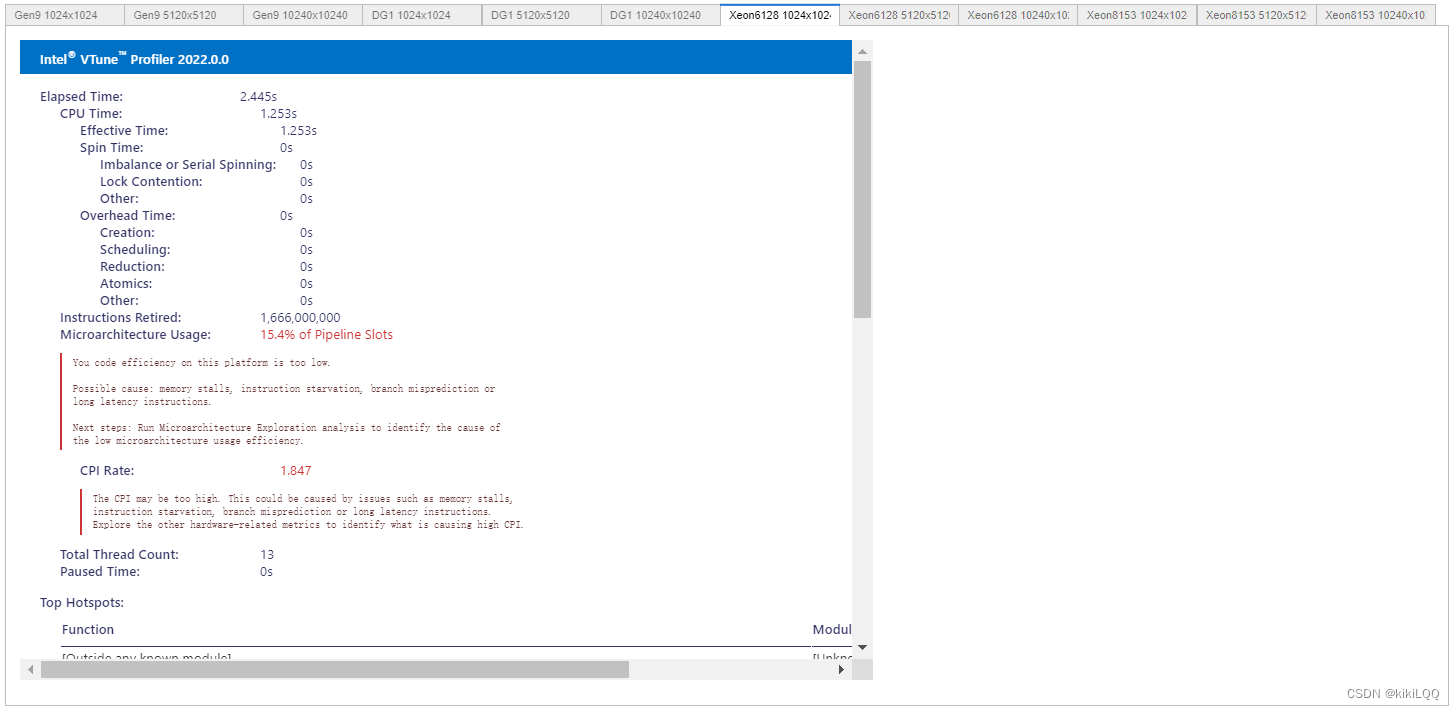
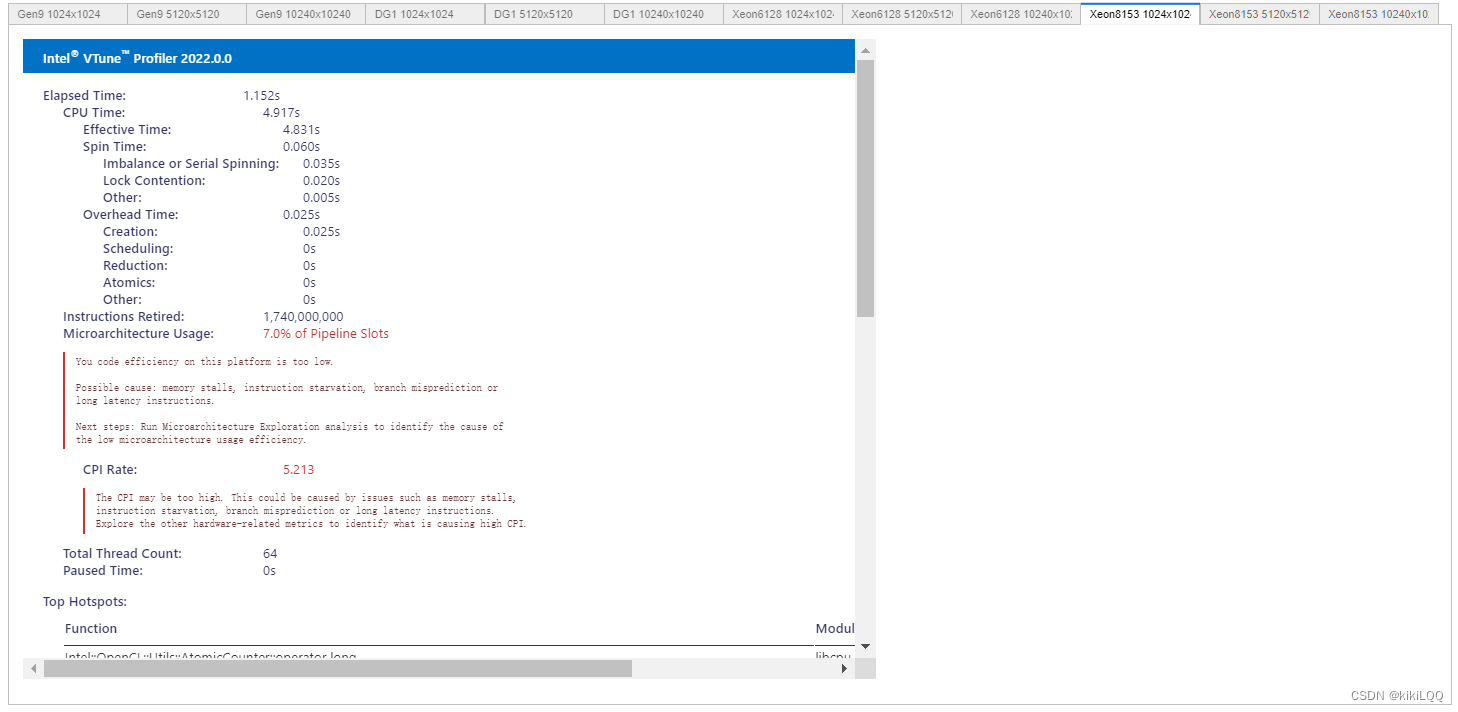
6.4.2 VTune Profiler结果分析
根据结果展示,使用共享本地内存方法进行优化后,在相同硬件条件和矩阵大小下,整体运行速度相较于之前的几种算法,得到了更多的提升。
6.5 分析
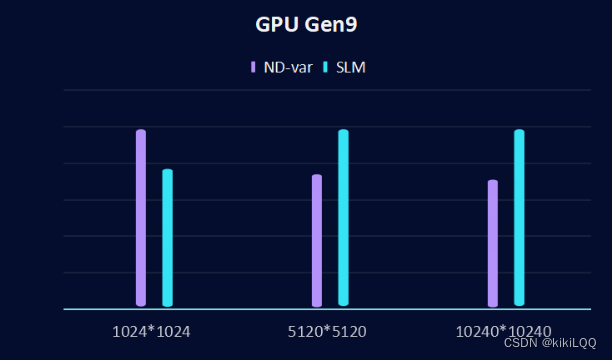
在这里,将本算法与之前最优的基于ND-range的私有内存优化算法进行比较,在不同的硬件和矩阵大小下可视化后结果如下所示:
1、GPU Gen9对比结果:
2、GPU Iris XE Max对比结果
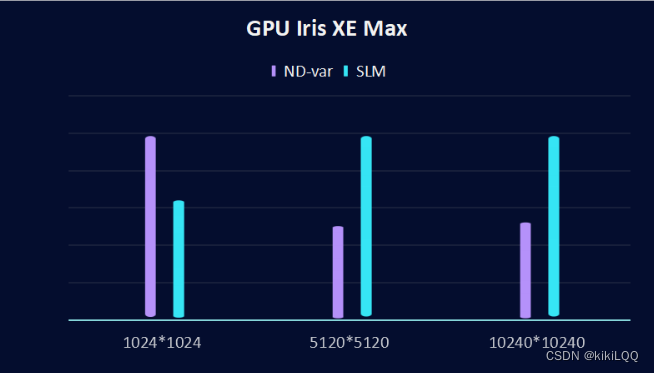
通过对比,可以观察到使用SLM算法后实现的矩阵乘法性能更好。
七、总结与心得
在大矩阵(20480*20480)上对以上三种方法以及Intel的MKL进行对比,分别在四种设备上进行测试,最终绘制优化对比图如下所示:
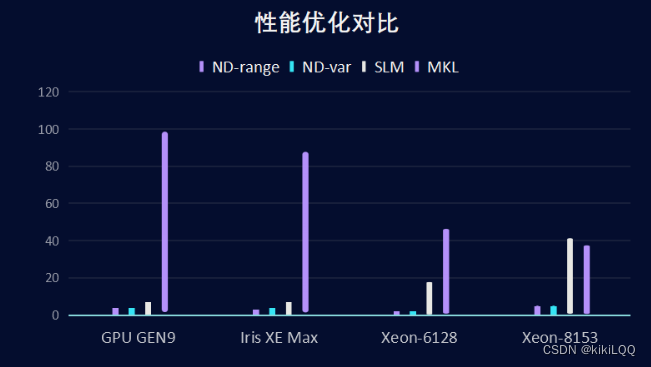
在本次实验中,主要是基于Intel提供的官方并行矩阵计算指导进行学习。通过对算法的一步一步优化,发现矩阵乘法计算的运行效果也在逐步提升。通过本次学习,对并行算法的实现有了更深入的了解,也会在学习的基础上进一步实现并行排序算法与并行排序算法。