目录
本任务是C语言课程与Intel合作的任务。通过自己撰写图像卷积并⾏加速算法,理解数据分割与合并以及线程之间的协作对于运行效率的作用。
转载请说明来源。
1.1 描述
使用基于oneAPI的C++/SYCL实现一个用于计算图像的卷积操作。输⼊为一个图像矩阵和一个卷积核矩阵,输出为卷积后的图像。
1.2 分析
图像卷积是一种常见的图像处理操作,用于应用各种滤波器和特征检测器。其原理可以简单地描述为在图像的每个像素上应用一个小的矩阵(通常称为卷积核或滤波器),并将卷积核中的元素与图像中对应位置的像素值相乘,然后将所有乘积的和作为结果。这个过程可以看作是对图像进行了平滑、锐化、边缘检测等操作。
假设有⼀个大小为M × N 的输入图像I 和一个大小为m × n 的卷积核 K 。图像卷积操作可以用下面的数学公式来表示:
S ( i , j ) = ∑ k ∑ l I ( i + k , j + l ) ⋅ K ( k , l ) S(i, j)=\sum_k \sum_l I(i+k, j+l) \cdot K(k, l) S(i,j)=k∑l∑I(i+k,j+l)⋅K(k,l)
其中, S(i,j)是卷积操作的结果图像中位置 (i, j) 处的像素值。 I(i + k, j + l) 是图像中位置 (i + k, j + l) 处的像
素值, K(k, l) 是卷积核中位置 (k, l) 处的权重。卷积核通常是一个小的⼆维矩阵,用于捕捉图像中的特定特征。在异构计算编程中,可以使用并行计算来加速图像卷积操作。通过将图像分割成小块,然后在GPU上并行处理这些块,可以实现高效的图像卷积计算。通过合理的块大小和线程组织方式,可以最大限度地利用GPU的并行计算能力来加速图像处理过程。
基于GPU的图像卷积操作的原理基于并行处理和矩阵乘法的基本原理,通过将图像数据和卷积核数据分配给不同的线程块和线程,利用GPU的并行计算能力实现对图像的快速处理。
2 算法描述
在本实验中,我是基于提供的黑客松数据集进行测试,读取数据需要考虑其特定的数据格式。
2.1 理论描述
卷积是信号处理和图像分析中的一个基本操作。以下是使用卷积核对矩阵进行卷积过程的逐步描述:
-
卷积核放置:卷积从将卷积核放置在输入矩阵的左上角开始。
-
逐元素乘法:卷积核的每个元素都与其覆盖的矩阵部分的对应元素相乘。
-
求和:这些乘法的结果相加,产生一个输出值。这个和是输出(卷积后)矩阵中的第一个元素的值。
-
卷积核滑动:然后卷积核水平地向右滑动一个列,对每个新位置重复乘法和求和步骤。
-
行尾处理:当到达一行的尾部时,卷积核向下移动到下一行,并返回到最左侧位置。
-
边缘处理:由于您描述的卷积操作是“有效”卷积,这意味着卷积核仅在完全位于输入矩阵边界内的位置上滑动。因此,输出矩阵比原始输入矩阵小。
-
最终输出:过程持续进行,直到卷积核滑过所有可能的位置,在这些位置上它完全适合输入矩阵。最终结果是卷积后的矩阵。
在本实验中,我们使用黑客松基准数据集进行测试。
2.2 算法实现
2.2.1 设备选择
首先选择我们进行卷积计算的设备:
import ipywidgets as widgets
device = widgets.RadioButtons(
options=['GPU Gen9', 'GPU Iris XE Max', 'CPU Xeon 6128', 'CPU Xeon 8153'],
value='CPU Xeon 8153',
description='Device:',
disabled=False
)
display(device)

2.2.2 卷积算法
之后,我们设计卷积计算的算法,下面的代码是一个使用 SYCL(一种高层次的异构编程模型)编写的图像卷积程序。程序的主要目标是读取一个图像矩阵和一个卷积核矩阵,执行卷积操作,并将结果保存到文件中。
1、导入库:
%%writefile lab/image_convolution.cpp
#include <CL/sycl.hpp>
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include <sstream>
using namespace sycl;
2、 基于并行处理和矩阵乘法的基本原理实现卷积提取特征
-
函数定义:
convolution_kernel: 这是执行卷积操作的核心函数。它接受图像矩阵、卷积核、结果矩阵、图像宽度、图像高度以及卷积核大小作为参数。
-
内存分配:
- 使用
buffer类创建输入图像、卷积核和输出结果的内存缓冲区。这些缓冲区用于在主机(CPU)和设备(GPU)之间传输数据。
- 使用
-
提交命令组:
q.submit: 这部分代码将命令组提交到队列。它定义了如何在设备上执行计算。
-
并行计算:
- 使用
parallel_for构造实现并行处理。这里为每个输出像素定义了一个工作项。
- 使用
-
卷积计算:
- 对于每个像素位置
(i, j),内部循环遍历卷积核的每个元素(ki, kj)。 - 计算卷积核覆盖的图像部分的坐标
(imageX, imageY)。 - 如果这些坐标在图像内,将乘积累加到输出数据中。
- 对于每个像素位置
void convolution_kernel(queue &q, std::vector<float> &image, std::vector<float> &kernel,
std::vector<float> &result, size_t width, size_t height, size_t kernelSize) {
// 分配内存
buffer input(image);
buffer convKernel(kernel);
buffer output(result);
// 提交命令组
q.submit([&](handler &h) {
// 数据传输
auto inputData = input.get_access<access::mode::read>(h);
auto kernelData = convKernel.get_access<access::mode::read>(h);
auto outputData = output.get_access<access::mode::write>(h);
// 并行计算
h.parallel_for(range<2>{
width, height}, [=](item<2> item) {
int i = item.get_id(0);
int j = item.get_id(1);
// 计算卷积
for (int ki = 0; ki < kernelSize; ++ki) {
for (int kj = 0; kj < kernelSize; ++kj) {
int imageX = i + ki - kernelSize / 2;
int imageY = j + kj - kernelSize / 2;
if (imageX >= 0 && imageX < width && imageY >= 0 && imageY < height) {
outputData[i * width + j] +=
inputData[imageX * width + imageY] * kernelData[ki * kernelSize + kj];
}
}
}
});
}).wait(); // 确保在主机端等待内核执行完成
}
2、读取矩阵函数:
由于黑客松数据集特定的数据格式,因此对于数据读取需要额外的处理。
readMatrix: 从文件中读取矩阵,并返回一个包含矩阵值的向量。同时计算矩阵的行和列。
std::vector<float> readMatrix(std::ifstream &file, size_t &rows, size_t &cols) {
std::vector<float> matrix;
std::string line;
rows = 0;
cols = 0;
while (std::getline(file, line) && !line.empty()) {
std::istringstream iss(line);
float value;
size_t currentRowCols = 0;
while (iss >> value) {
matrix.push_back(value);
++currentRowCols;
}
if (rows == 0) {
cols = currentRowCols;
}
++rows;
}
return matrix;
}
3、 主函数:
- 打开文件并读取图像和卷积核矩阵。
- 调用
convolution_kernel函数进行卷积计算。 - 将结果写入文件。
int main() {
std::ifstream file("problem-3.txt");
if (!file.is_open()) {
std::cerr << "Unable to open file problem-3.txt" << std::endl;
return 1;
}
// 跳过 "Matrix:" 行
std::string line;
std::getline(file, line);
// 读取图像矩阵
size_t width, height;
std::vector<float> image = readMatrix(file, height, width);
// 跳过 "Convolution Kernel:" 行
std::getline(file, line);
// 读取卷积核
size_t kernelWidth, kernelHeight;
std::vector<float> kernel = readMatrix(file, kernelHeight, kernelWidth);
file.close();
// 卷积核大小
size_t kernelSize = kernelWidth; // 假设卷积核是方形的
// 初始化结果矩阵
std::vector<float> result(width * height, 0.0f);
// 创建队列
queue q;
// 执行卷积操作
convolution_kernel(q, image, kernel, result, width, height, kernelSize);
// 打开一个文件流用于写入结果
std::ofstream outputFile("convolution_result.txt");
if (!outputFile.is_open()) {
std::cerr << "Unable to open file for writing results." << std::endl;
return 1;
}
// 写入卷积后的矩阵到文件
for (size_t i = 0; i < height; ++i) {
for (size_t j = 0; j < width; ++j) {
outputFile << result[i * width + j] << " ";
}
outputFile << std::endl;
}
outputFile.close();
return 0;
}
最后,撰写脚本运行:
#!/bin/bash
source /opt/intel/inteloneapi/setvars.sh > /dev/null 2>&1
# Command Line Arguments
src="lab/"
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/intel/oneapi/compiler/latest/linux/lib
echo ====================
echo image_convolution
dpcpp ${src}image_convolution.cpp -o ${src}image_convolution -w -O3 -lsycl
./${src}image_convolution
3 运行结果
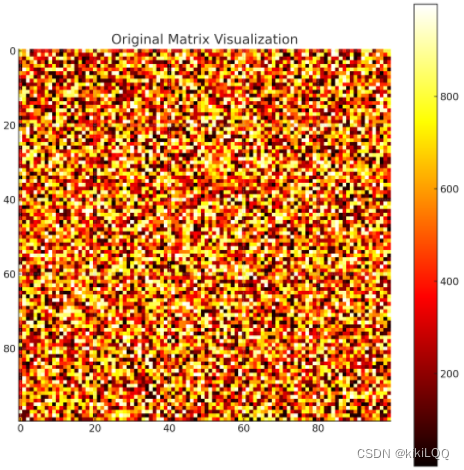
3.1 原始数据集可视化
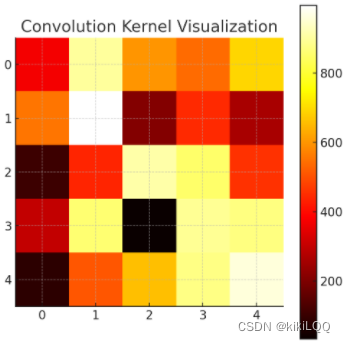
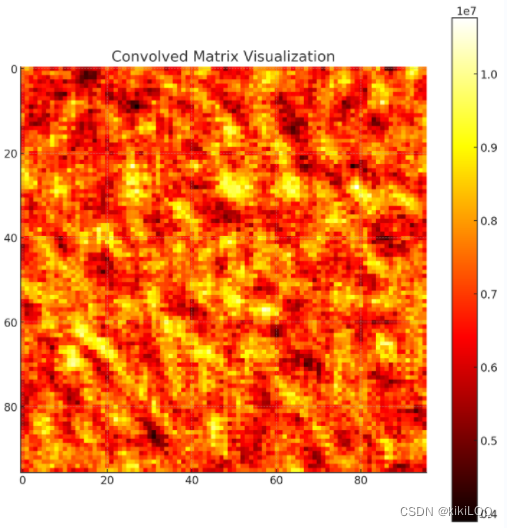
将原始图片与卷积核可视化后的结果如下所示,这个热图代表了提供的用于卷积的矩阵的值和卷积核内的值,其中颜色的强度表示它们的大小。输入矩阵大于卷积核。当卷积核滑过矩阵并重复上述步骤时,它根据卷积核的值提取了矩阵中的信息与特征,从而得到卷积后的矩阵。
原始图片热图:
卷积核热图:
3.2 运行过程
3.3 卷积结果
将卷积后的结果可视化后绘制成如下所示的热图:
4 算法分析
卷积过程的重点:
-
边界处理:代码在处理边界时通过检查
imageX >= 0 && imageX < width && imageY >= 0 && imageY < height来确保不会越界访问。 -
性能:由于使用了 SYCL 和并行处理,这个程序可以在支持的设备(如 GPU)上高效地执行卷积操作。
-
通用性:代码假设卷积核是方形的(
kernelSize),但可以轻松地修改以支持非方形卷积核。 -
结果输出:最终的卷积结果被写入一个文件,方便后续处理或分析。
整体来看,这个程序是一个高效的图像卷积实现,充分利用了并行计算的优势,适合于处理大型图像数据。
5 总结与心得
本次任务是C语言课程与Intel合作的任务。在第一个的任务中,参考了Intel的示例学习了并行矩阵计算。而本次并行卷积操作是三个任务中相对最复杂的,但其本质也是矩阵的计算。以前实现与机器学习相关的代码总是使用python进行,这一次需要利用C实现,且需要为了提速考虑基于GPU的图像卷积操作的原理、并行处理和矩阵乘法的基本原理,通过将图像数据和卷积核数据分配给不同的线程块和线程,具有一定难度,在代码撰写过程中也是遇到了许多问题,例如缺少部分库(因为使用云平台进行,缺乏root权限,一些依赖库无法安装)、运行时间过长导致无法输出结果等等。但通过优化算法等方式,最终也将这些问题进行解决,在解决问题的过程中也让自己对并行计算和算法设计有了更深的理解。