强化学习 Q-learning 小例子
本节内容的例子可参见:
代码原型可参见:
本文仅仅是按问题修改了一下代码。
Q-learning算法:

例子:
对于下面一个找宝藏问题:
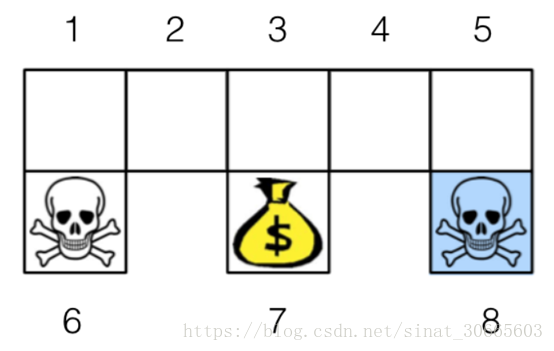
初始点位于[1, 2, 3,4, 5] 进行随机游走,到达[6, 8]给予reward-1 的惩罚,到达7给与reward 1的奖励,求Q-learning对应的近似矩阵。
代码:
import numpy as np
import pandas as pd
import time
np.random.seed(2)
N_STATES = 8
ACTIONS = ['n', 'e', 's', 'w']
EPSILON = 0.9
ALPHA = 0.1 # learning rate
LAMBDA = 0.9 # discount factor
MAX_EPISODES = 50 # maximum episodes
FRESH_TIME = 0.0 # fresh time for one move
def build_q_table(n_states, actions):
table = pd.DataFrame(
np.zeros((n_states, len(actions))),
columns=actions,
)
return table
def choose_actions(state, q_table):
state_actions = q_table.iloc[state, :]
if (np.random.uniform() > EPSILON) or (state_actions.all() == 0):
action_name = np.random.choice(ACTIONS)
else:
action_name = state_actions.argmax()
return action_name
def get_env_feedback(S, A):
S += 1
S_, R = [None] * 2
if S in [1, 3, 5]:
if A == "s":
S_ = "terminal"
if S in [1, 5]:
if S == 1:
S_ += "6"
else:
S_ += "8"
R = -1
else:
S_ += "7"
R = 1
elif A == "n":
S_ = S
R = 0
elif A == "e":
if S in [1, 3]:
S_ = S + 1
R = 0
else:
S_ = 5
R = 0
elif A == "w":
if S in [3, 5]:
S_ = S - 1
R = 0
else:
S_ = 1
R = 0
else:
if A in ["n", "s"]:
S_ = S
R = 0
elif A == "w":
S_ = S - 1
R = 0
else:
S_ = S + 1
R = 0
if type(S_) != type(""):
S_ -= 1
return S_, R
def update_env(S, episode, step_counter):
env_list = ['-'] * 5
background_list = ["x", ",", ":", ",", "x"]
if type(S) == type("") and S.startswith("terminal"):
S = int(S.replace("terminal", ""))
interaction = "Episode %s: total_steps = %s" % (episode + 1, step_counter)
print('\r{}'.format(interaction), end='\n')
if S == 6:
background_list[0] = 'o'
elif S == 7:
background_list[2] = 'o'
else:
background_list[4] = 'o'
print('\r{}'.format(''.join(background_list)), end='')
if S != 7:
print("\tDead!")
else:
print("\tGet it!")
time.sleep(2)
print("\r ", end='')
else:
env_list[S] = 'o'
interaction = ''.join(env_list)
print('\r{}'.format(interaction), end='')
print('\r{}'.format(''.join(background_list)), end='')
time.sleep(FRESH_TIME)
def rl():
q_table = build_q_table(N_STATES, ACTIONS)
for episode in range(MAX_EPISODES):
step_counter = 0
S = np.random.choice([0, 1, 2, 3, 4])
#S = np.random.choice([0, 2, 4])
is_terminated = False
update_env(S, episode, step_counter)
while not is_terminated:
A = choose_actions(S, q_table)
S_, R = get_env_feedback(S, A)
q_predict = q_table.ix[S, A]
if not(type(S_) == type("")):
q_target = R + LAMBDA * q_table.iloc[S_, :].max()
else:
q_target = R
is_terminated = True
q_table.ix[S, A] += ALPHA * (q_target - q_predict)
S = S_
update_env(S, episode, step_counter + 1)
step_counter += 1
return q_table
if __name__ == "__main__":
q_table = rl()
print("\r\nQ-TABLE")
print(q_table)
50步运行结果(单步运行时间随着Q(s, a)的优化收敛逐步减少):
Q-TABLE
n e s w
0 0.003391 0.141718 -0.468559 0.000322
1 0.007448 0.567647 0.013570 0.000960
2 0.009000 0.053627 0.988027 0.000810
3 0.037849 0.000375 0.000810 0.709087
4 0.000713 0.002898 -0.190000 0.226229
5 0.000000 0.000000 0.000000 0.000000
6 0.000000 0.000000 0.000000 0.000000
7 0.000000 0.000000 0.000000 0.000000
基本符合预期。