CartPole是OpenAI gym中的一个游戏测试
https://gym.openai.com/envs/CartPole-v1/

目的是通过强化学习让Agent控制cart,使pole尽量长时间不倒
这里用Q-learning实现,理解Q-learning
Q矩阵定义:
CartPole状态是保存在observation中的,有4个变量,cart位置和速度,pole的角度和速度,它们都是连续值,现在要把这些连续值离散化
cart位置:-2.4 ~ 2.4
cart速度:-inf ~ inf
pole角度:-0.5 ~ 0.5 (radian)
pole角速度:-inf ~ inf
离散化为6个bins,4个变量,所以有64 = 1296种state,action只有左和右2种
因此Q矩阵size是1296 * 2
定义3个class:Agent,Brain,Environment,它们的关系如下:
(1) Agent把当前的observation传给Brain
(2) Brain把observation的状态离散化后,根据Q矩阵决定action,然后把action给Agent
(3) Agent把action用到Environment,Environment把action反馈的observation_t+1和reward_t+1返回给Agent
(4) Agent把当前observation_t, action_t, 行动后的observation_t+1, reward_t+1给Brain
(5) Brain更新Q矩阵
更新observation=observation_t+1,重复(1) ~ (5)
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import gym
ENV = 'CartPole-v1'
NUM_DIGITIZED = 6
GAMMA = 0.99 #decrease rate
ETA = 0.5 #learning rate
MAX_STEPS = 200 #steps for 1 episode
NUM_EPISODES = 2000 #number of episodes
class Agent:
def __init__(self, num_states, num_actions):
self.brain = Brain(num_states, num_actions)
#update the Q function
def update_Q_function(self, observation, action, reward, observation_next):
self.brain.update_Q_table(
observation, action, reward, observation_next)
#get the action
def get_action(self, observation, step):
action = self.brain.decide_action(observation, step)
return action
class Brain:
#do Q-learning
def __init__(self, num_states, num_actions):
self.num_actions = num_actions #the number of CartPole actions
#create the Q table, row is the discrete state(digitized state^number of variables), column is action(left, right)
self.q_table = np.random.uniform(low=0, high=1, size=(NUM_DIGITIZED**num_states, num_actions)) #uniform distributed sample with size
def bins(self, clip_min, clip_max, num):
#convert continous value to discrete value
return np.linspace(clip_min, clip_max, num + 1)[1: -1] #num of bins needs num+1 value
def digitize_state(self, observation):
#get the discrete state in total 1296 states
cart_pos, cart_v, pole_angle, pole_v = observation
digitized = [
np.digitize(cart_pos, bins = self.bins(-2.4, 2.4, NUM_DIGITIZED)),
np.digitize(cart_v, bins=self.bins(-3.0, 3.0, NUM_DIGITIZED)),
np.digitize(pole_angle, bins=self.bins(-0.5, 0.5, NUM_DIGITIZED)), #angle represent by radian
np.digitize(pole_v, bins=self.bins(-2.0, 2.0, NUM_DIGITIZED))
]
return sum([x* (NUM_DIGITIZED**i) for i, x in enumerate(digitized)])
def update_Q_table(self, observation, action, reward, observation_next):
state = self.digitize_state(observation)
state_next = self.digitize_state(observation_next)
Max_Q_next = max(self.q_table[state_next][:])
self.q_table[state, action] = self.q_table[state, action] + \
ETA * (reward + GAMMA * Max_Q_next - self.q_table[state, action])
def decide_action(self, observation, episode):
#epsilon-greedy
state = self.digitize_state(observation)
epsilon = 0.5 * (1 / (episode + 1))
if epsilon <= np.random.uniform(0, 1):
action = np.argmax(self.q_table[state][:])
else:
action = np.random.choice(self.num_actions)
return action
class Environment:
def __init__(self):
self.env = gym.make(ENV)
num_states = self.env.observation_space.shape[0] #4
num_actions = self.env.action_space.n #2
self.agent = Agent(num_states, num_actions) #create the agent
def run(self):
complete_episodes = 0 #succeed episodes that hold on for more than 195 steps
is_episode_final = False #last episode flag
frames = [] #for animation
for episode in range(NUM_EPISODES): #1000 episodes
observation = self.env.reset() #initialize environment
for step in range(MAX_STEPS): #steps in one episode
if is_episode_final is True: #True / False is singleton in Python, so can use "is" to compare the object, while "==" compares the value
frames.append(self.env.render(mode='rgb_array'))
action = self.agent.get_action(observation, episode) #not step
#get state_t+1, reward from action_t
observation_next, _, done, _ = self.env.step(action) #reward and info not need
#if use default reward, use following:
#observation_next, reward, done, _ = self.env.step(action) #Test
#self.agent.update_Q_function(observation, action, reward, observation_next) #Test
#observation = observation_next #Test
#get reward
if done: #step > 200 or larger than angle
if step < 195:
reward = -1 #give punishment if game over less than last step
complete_episodes = 0 #game over less than 195 step then reset
else:
reward = 1
complete_episodes += 1
else:
reward = 0 #until done, reward is 0
#update Q table
self.agent.update_Q_function(observation, action, reward, observation_next)
#update observation
observation = observation_next
if done:
print('{0} Episode: Finished after {1} time steps'.format(episode, step + 1))
break
if is_episode_final is True: #save the animation
display_frames_as_gif(frames)
break
if complete_episodes >= 10:
print('succeeded for 10 times')
is_episode_final = True
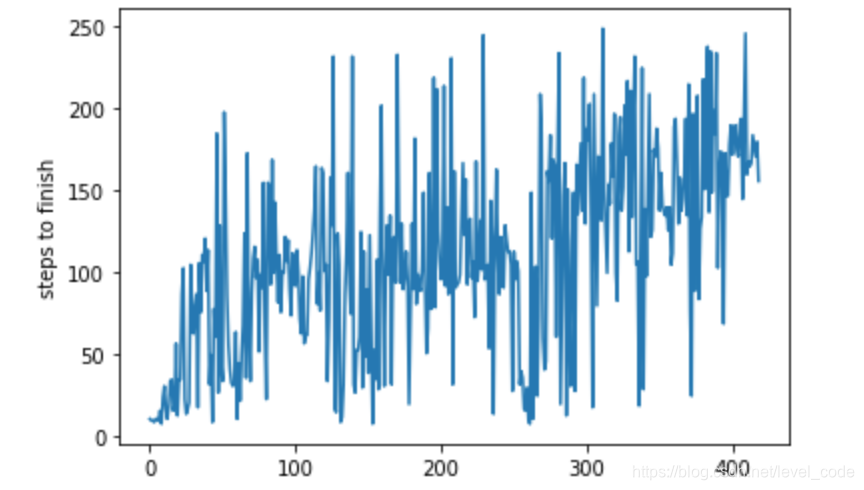
测试到的收敛性如下,可以看到从刚开始的很快就done,到后来可以坚持200step