目录
前言
代码语言:C语言
开发环境:Visual Studio 2022
通过这篇文章,你将了解到:
- 整型家族成员;
- 整型在内存中的存储方式;
- 大小端字节序存储。
1. 数据类型
1.1. 常见的数据类型
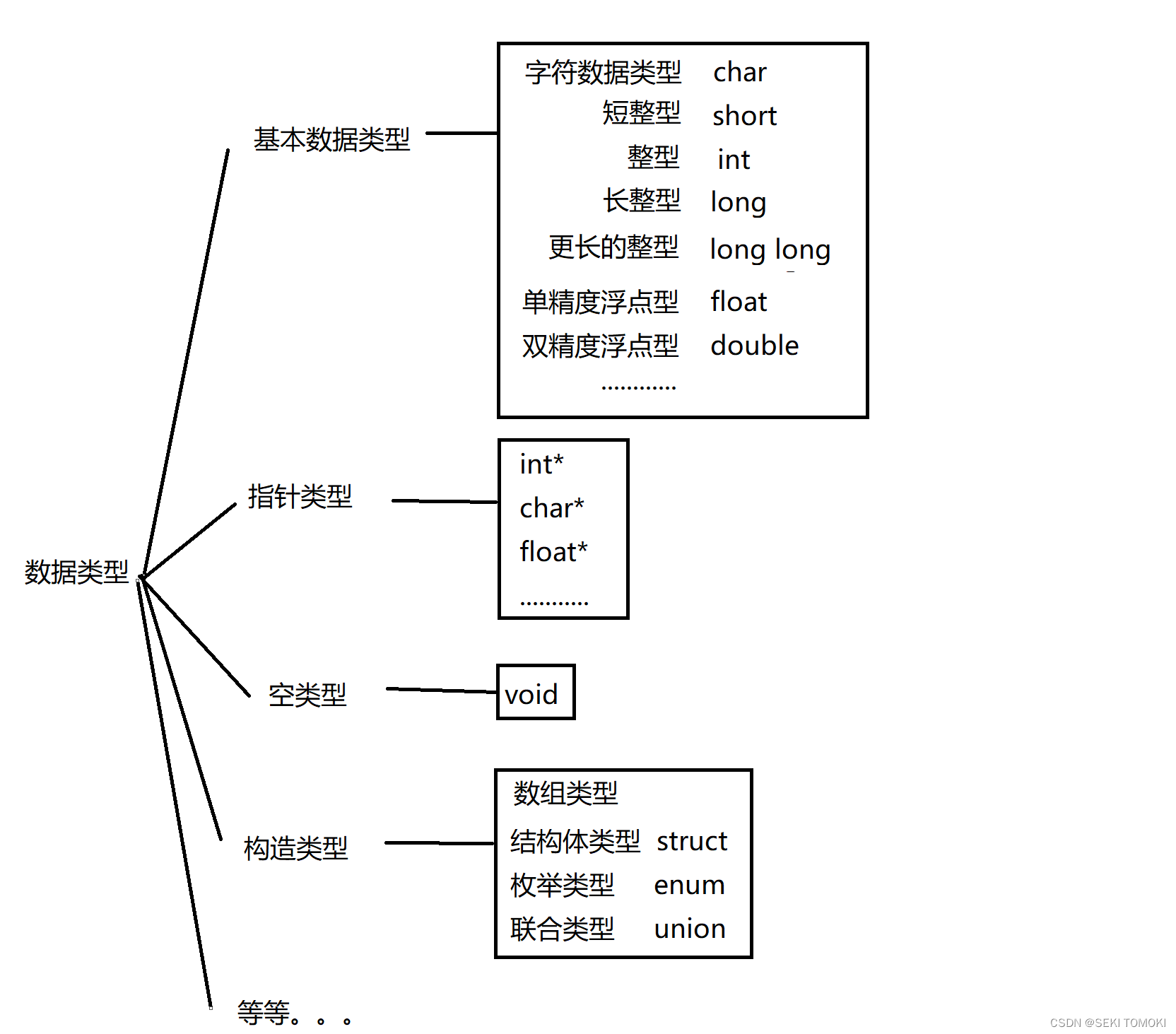
1.1.1. 基本数据类型的分类
以下是基本数据类型的归类:
对上图的解释:
- signed是有符号,unsigned是无符号,平常写的int类型就是signed int类型,以此类推。signed通常可以省略不写。
- [int]指的是该int可以省略不写。比如unsigned short int类型,可以省略int,等价于unsigned short类型。
- char类型是字符类型,字符存储的时候存的是ASCII码值,ASCII码值是整数,所以char类型归类到整型家族。
- 整型家族的各个成员只是存储数据的取值范围不同,但都是整数。既然是整数就可以表示正整数,0和负整数,有unsigned修饰的数据类型就不能表示负整数。
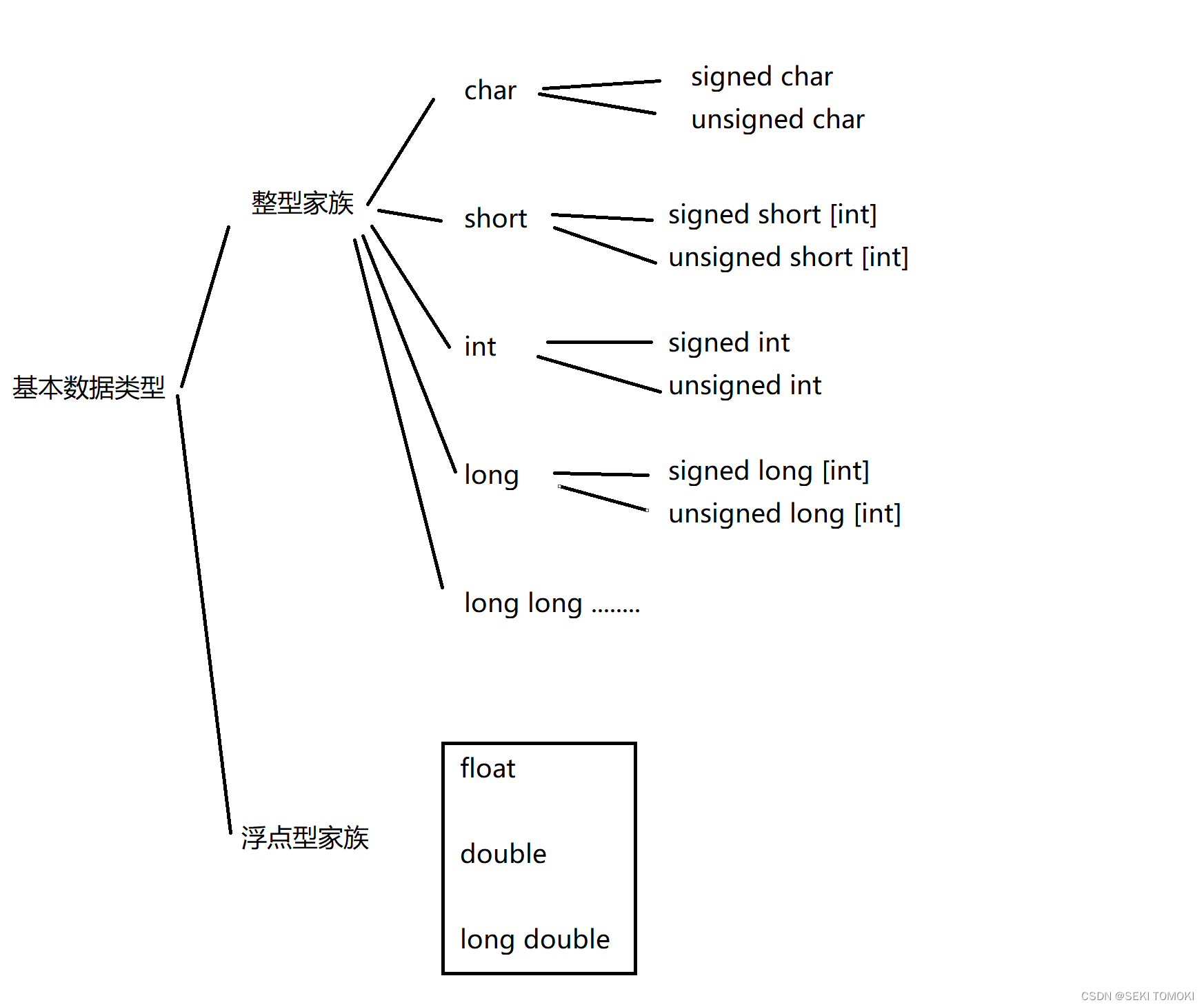
1.1.2. 基本数据类型所占存储空间的大小

对上图对的解释:
1.在不同的编译器下长整型的存储空间是不同的,C语言只规定:long类型所占空间大小 >= int类型所占空间大小( sizeof(long) >= sizeof(int) )。
2. C语言还明确规定long long类型是8个字节,float类型是4个字节,double类型是8个字节。
1.2. 为什么要有不同的数据类型?
- 不同类型占不同大小的空间,根据具体的数据合理分配空间。
- 不同的数据类型决定了开辟内存空间的大小。内存空间的大小不同,存储数据的取值范围也就不同。
- 数据类型不同,看待内存空间的视角就不同。
2. 整型数据在内存中的存储
创建一个变量,就要给这个变量开辟一个空间,这个空间的大小由数据类型决定。创建好一个变量后,下一步就是存储数据。10怎么存储?-10又怎么存储?下面就是讲整型家族的数据是如何存储的。
2.1. 计算机的数据存储
在计算机中,任何数据都是以二进制的形式存储。
2.1.1. 常见的进制
最常见的十进制数字:由0,1,2,3,4,5,6,7,8,9组成。逢10进1
二进制数字:由0,1组成。逢2进1
16进制数字:由0, 1, 2, 3, 4, 5, 6, 7, 8, 9, a, b, c, d, e, f 组成。逢16进1
16进制数字如果用10,11,12,13,14,15表示会与前面的0到5的数字产生歧义,所以从10到15,分别用a,b,c,d,e,f表示。
八进制数字:由0,1,2,3,4,5,6,7组成。逢8进1
为了防止把16进制的1,二进制的1,八进制的1和十进制的1混淆,一个16进制数字会在前面加一个前缀0x。一个八进制数字会在前面加一个前缀0。
C语言中没有直接表示二进制的前缀。
例子:
0x1234中的0x除了表示1234是16进制数字没有任何其他意思。
01234中的0是八进制的标志。
1234没有任何前缀就是十进制的1234。1234的二进制是010011010010。具体怎么换算看下一节。
2.1.2. 进制的换算方法
通过两个例子举一反三
-
任意进制转十进制


-
十进制转任意进制(短除法)


-
使用进制换算计算器计算,这里用Windows自带的计算器介绍。
打开Windows计算器,点击左上角的打开导航,选中计算器的程序员。
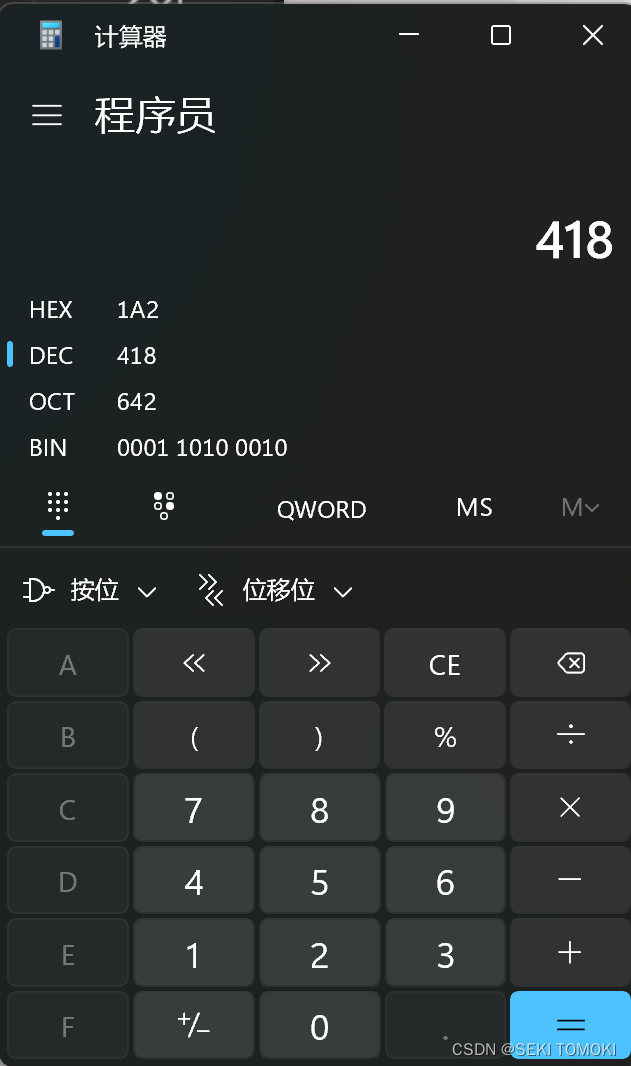
HEX是16进制
DEC是十进制
OCT是八进制
BIN是二进制
点击DEC输入418,就可以看到各个进制的表示形式
2.2. 原码,反码,补码
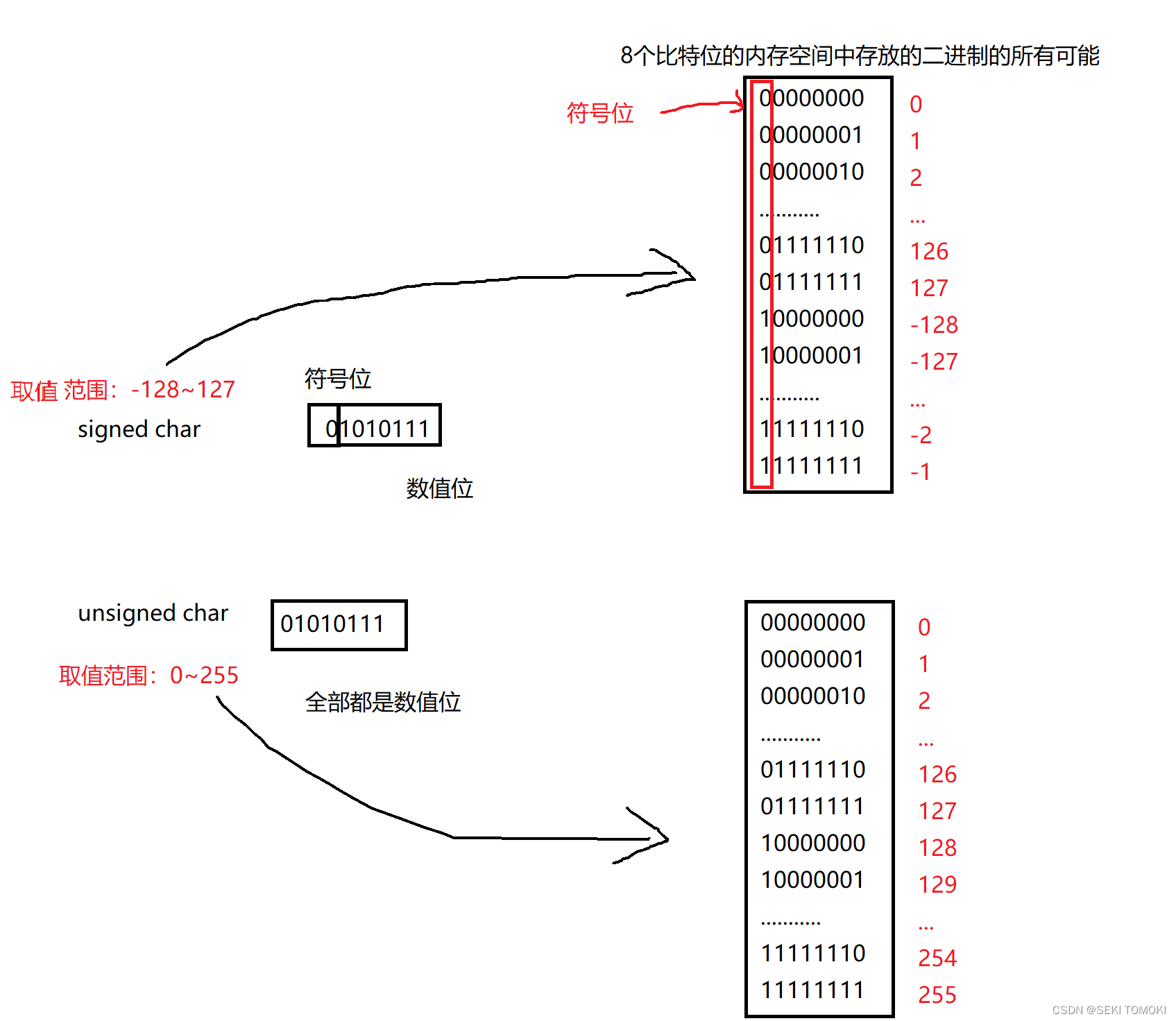
原码:十进制数据的二进制表示形式。为了分清正负数,把最高位(最左边)规定为符号位(0为正,1为负),其他位为数值位。
以一个字节大小(8个比特位)为例:00010101是21的原码,10010101是-21的原码

现在想让 21 和 -21 的原码进行相加,是否会等于0呢?
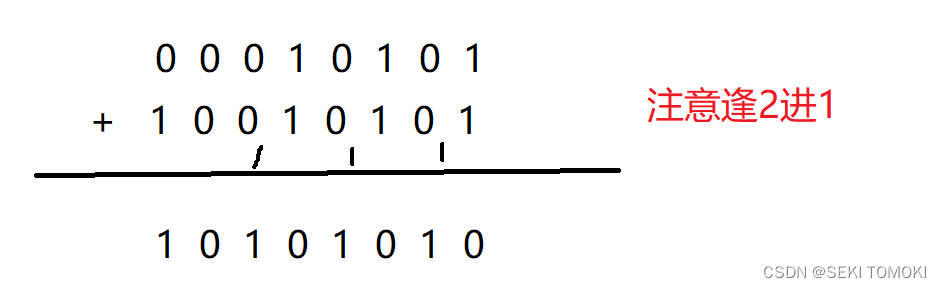
0的二进制应该是00000000,可是上面计算的结果显然不是。试试 21 加 1:
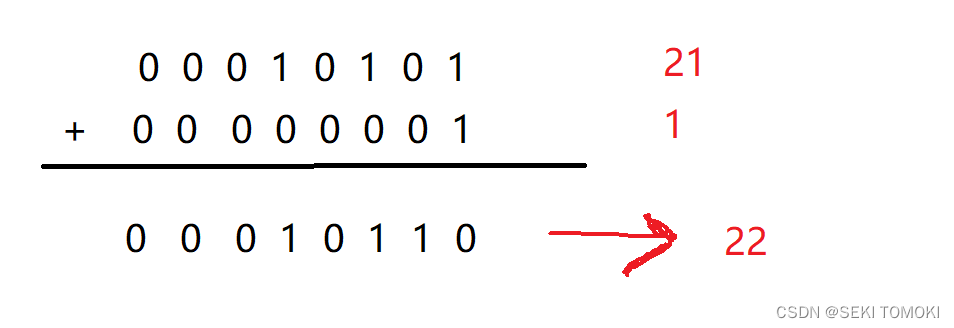
正数相加没问题,再看看负数相加,比如 -21和-1相加:
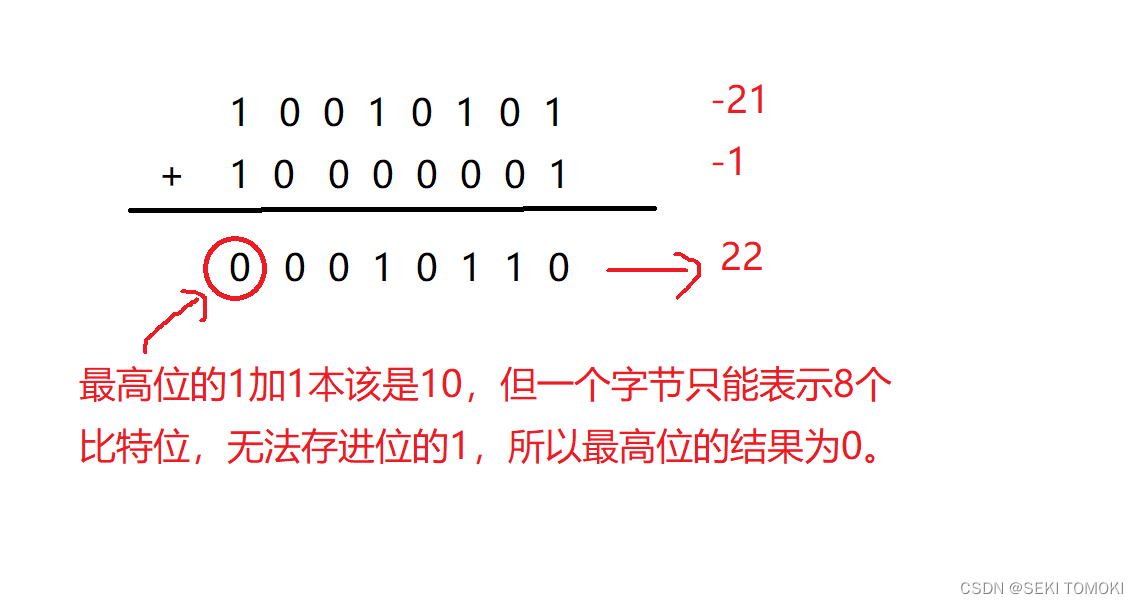
-21+(-1)本应该是-22,可结果得到的是22。由这3个例子可以知道:
原码是负数时不能计算出正确的结果。
而反码的存在就是为了能解决负数计算的问题。
反码:正数的反码是原码本身,负数的反码是符号位不变,其余位取反。
举个例子(以一个字节的大小为例):

因为正数的反码和原码一样,也能进行正数的计算。接着我们试试用反码进行负数的计算:

貌似可以计算,但还有特殊情况:

为什么小了1?因为0多算了一次。0有+0和-0,+0的反码是原码本身:00000000,-0的原码是10000000,所以-0的反码是11111111。因为0算了两次,所以少了个1。也体现出反码计算的缺陷:负数计算的结果跨越0,会有1的偏差。 而补码的出现就是为了解决跨0计算的问题。
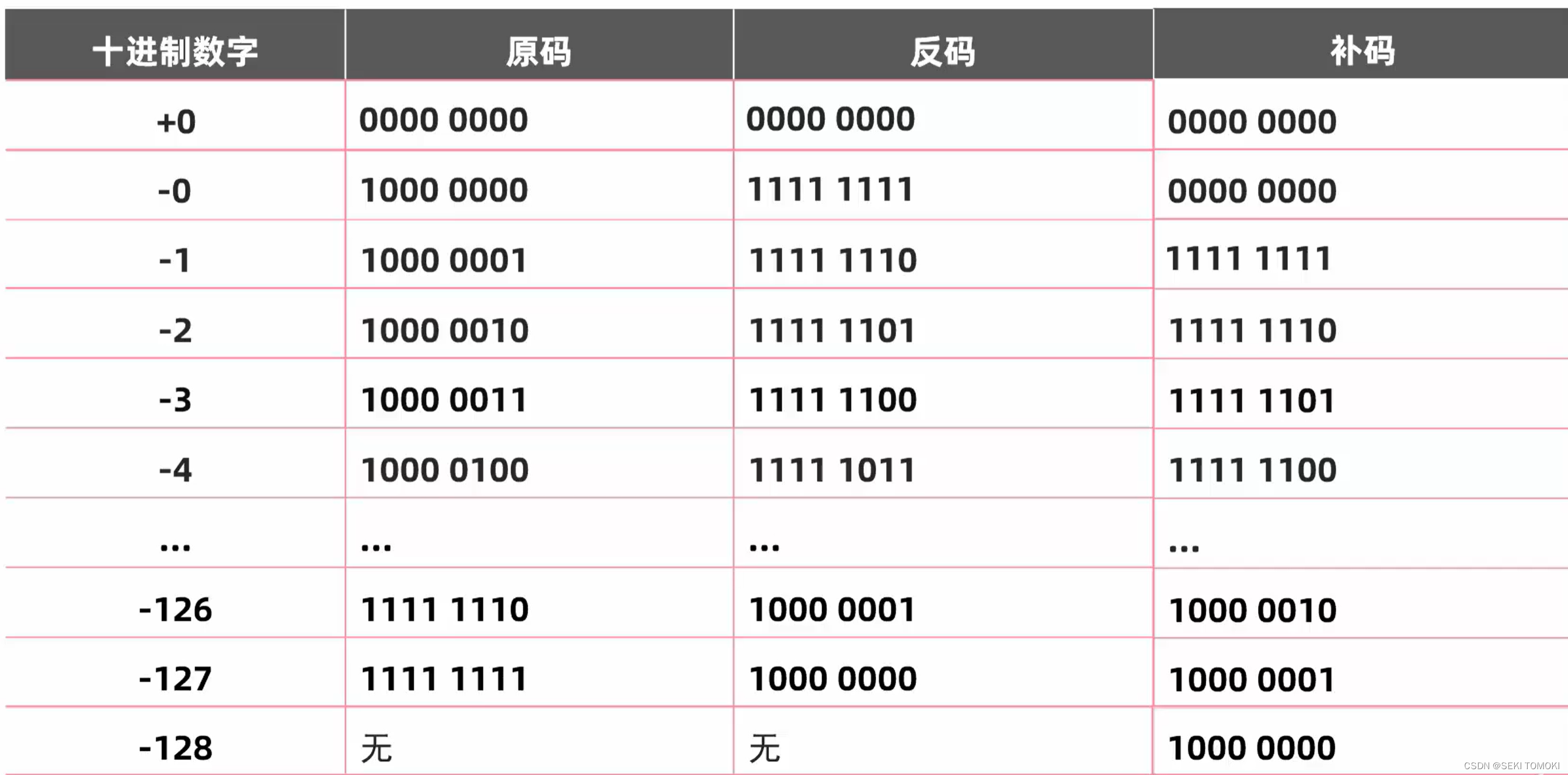
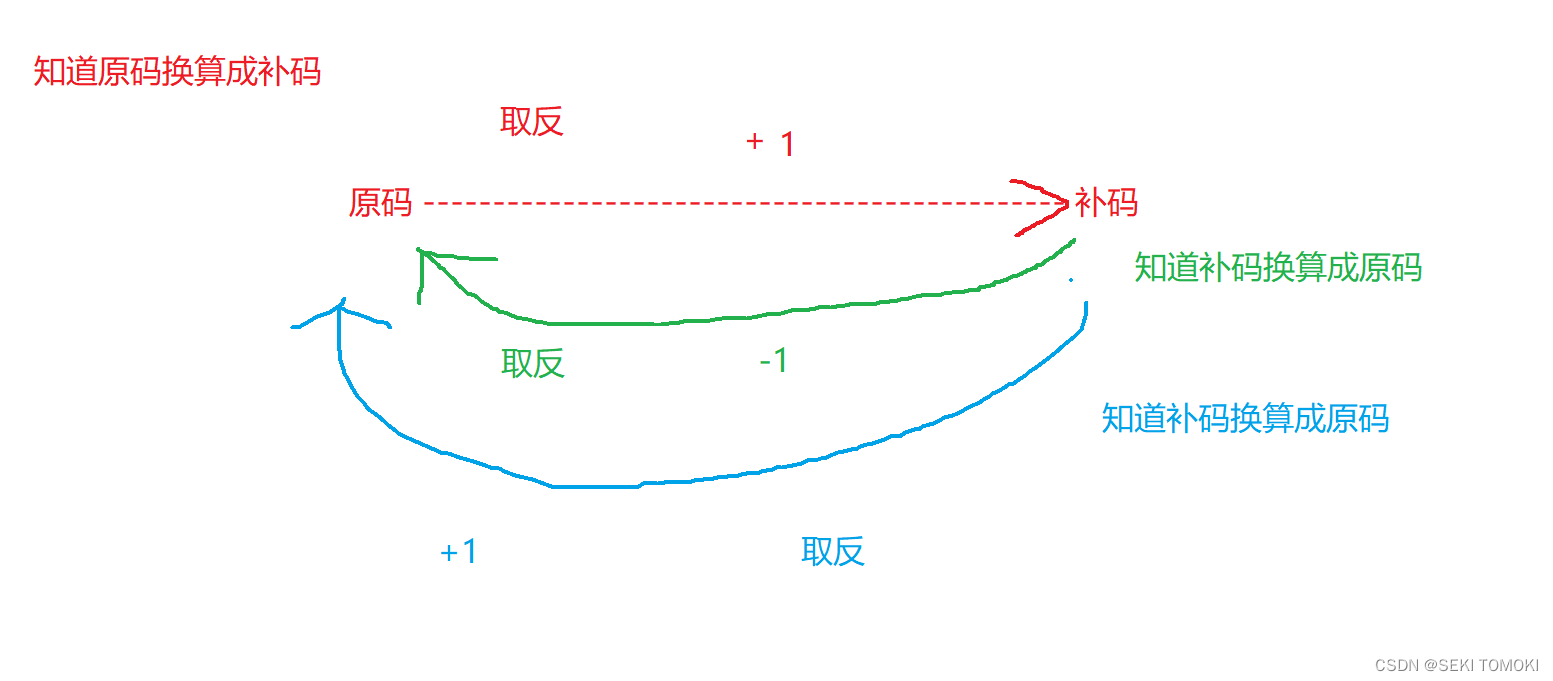
补码:正数的原码,反码和补码都是相同的,负数的补码就是反码加1。
一张图明白负数的原码,反码和补码:
此时不管是+0还是-0都是00000000,就不影响计算了。
2.2.1. 原反补码存在的意义
实际上,整型数据在内存中都是以补码的形式存储的。当我们输入一个整数,计算机先把这个整数转换为二进制的形式,也就是原码,然后再转换为补码的形式进行运算。
为什么还要转换为补码再进行计算,不麻烦吗?
用补码可以直接计算正负整数,且CPU只有加法器,也就是只能进行加减法运算(减法可以加一个负数实现),并且原码转补码和补码转原码可以用取反加1实现转换,不需要再使用额外的机器进行换算。效率反而更高。
最后再回过头来看看10和-10的存储方式:

我们可以在开发环境下看到10和-10在内存中存储的位置:
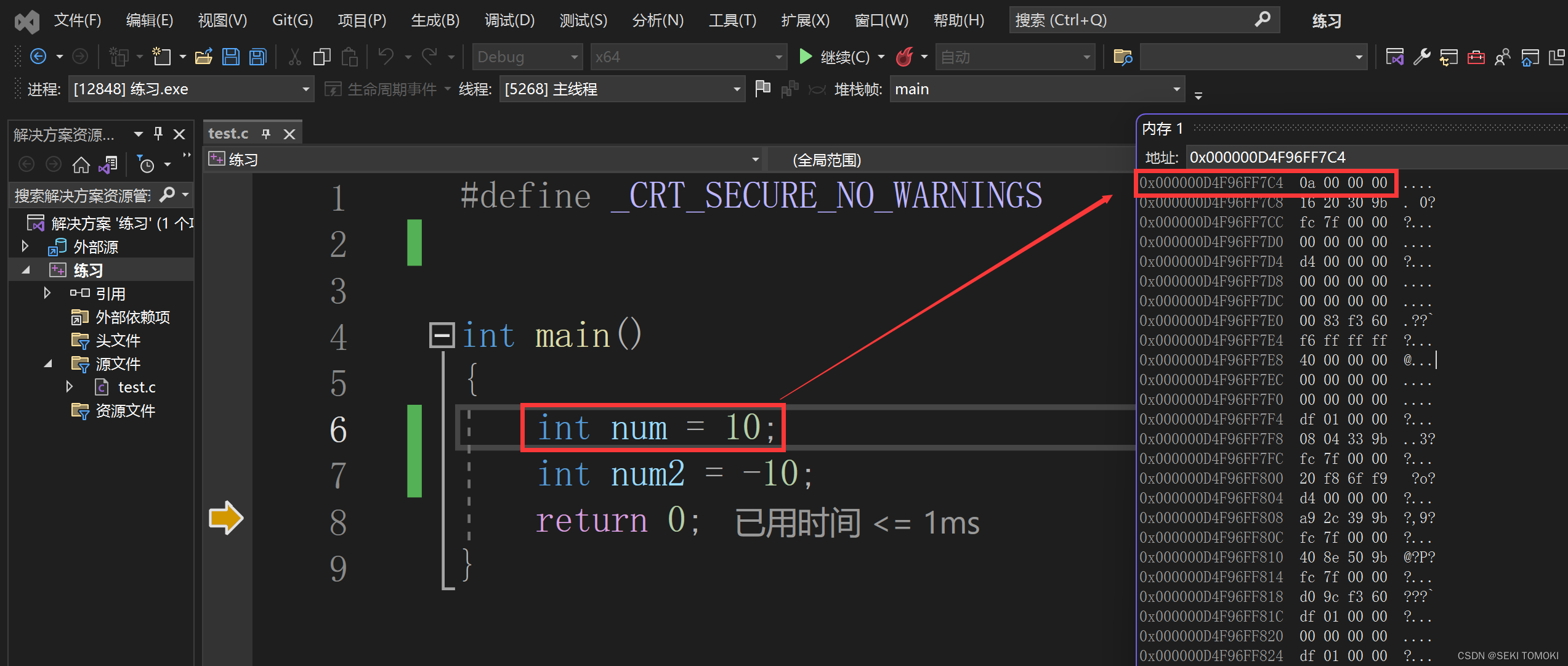
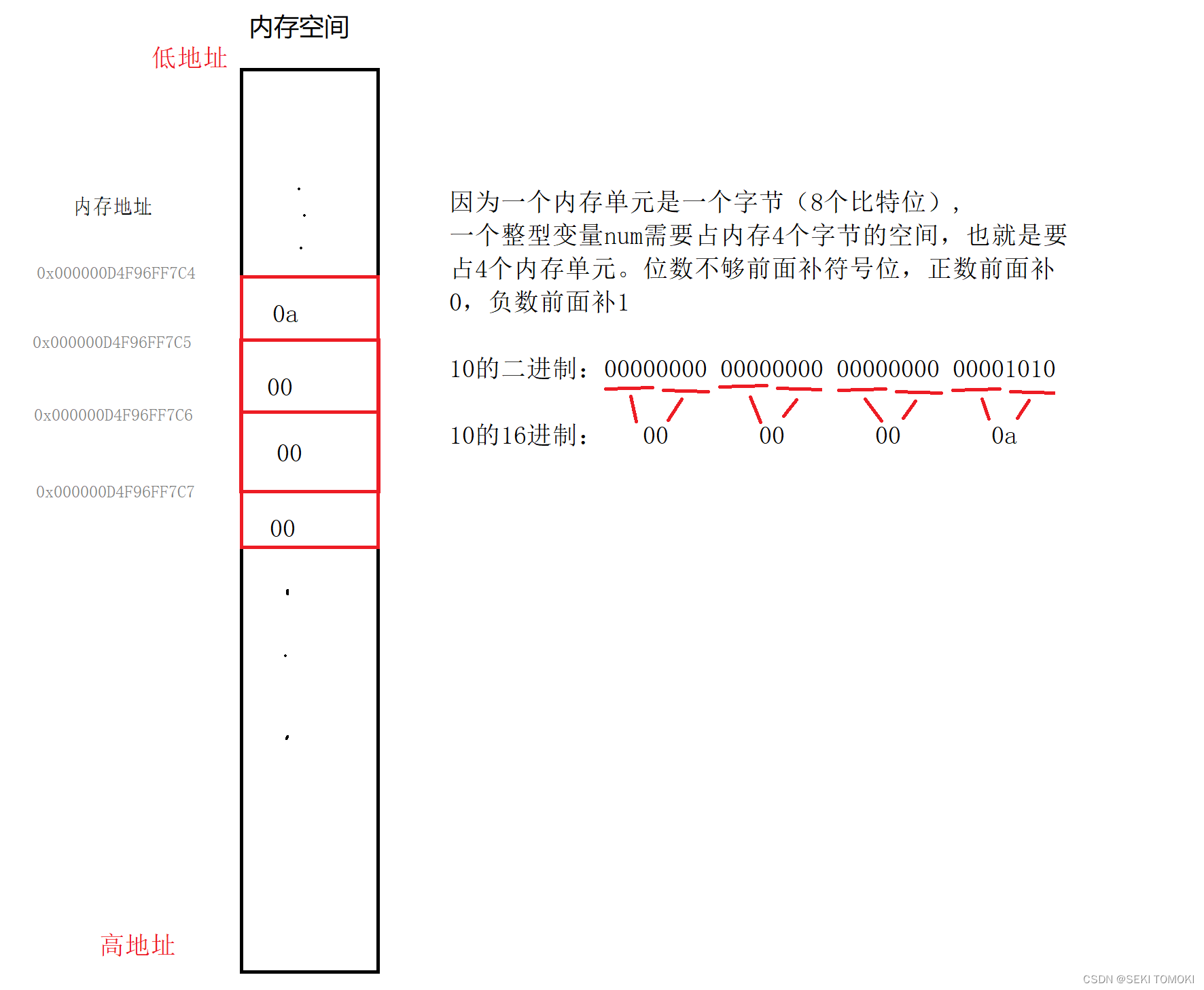
本质上内存存放的是二进制,但为了方便显示,该环境(vs2022)显示的是16进制 (注意内存中的数据要倒着读,原因在大小端字节序中解释。),变量num和num2的空间大小都是4个字节(也就是32个比特位),因为1个16进制数字需要用4个二进制数字表示,8个16进制数字就要32个二进制数字表示,所以16进制的00 00 00 0a就是二进制的00000000 00000000 00000000 00001010,也就是10。
画图解释:
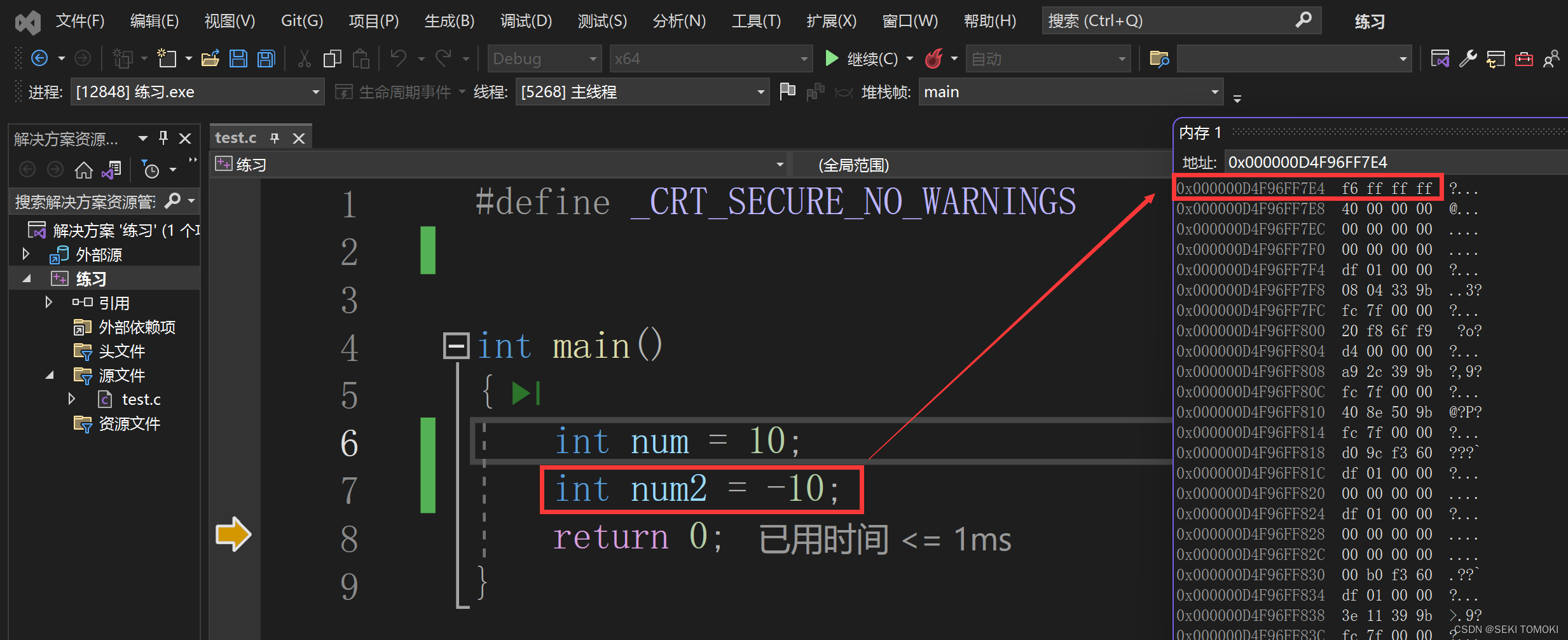
-10同理:

2.3. 整数类型存储的取值范围
列举部分整型家族的数据类型:
char:-128 到 127 (有符号)
unsigned char: 0 到 255 (无符号)
short:-32,768 到 32,767 (有符号)
unsigned short: 0到65535 (无符号)
int:-2,147,483,648 到 2,147,483,647 (有符号)
unsigned int: 0到4294967295 (无符号)
long:-9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 (有符号)
unsigned long: 0到18446744073709551615 (无符号)
怎么得出的取值范围?以char类型为例:
char类型的大小是1个字节(8个比特位)
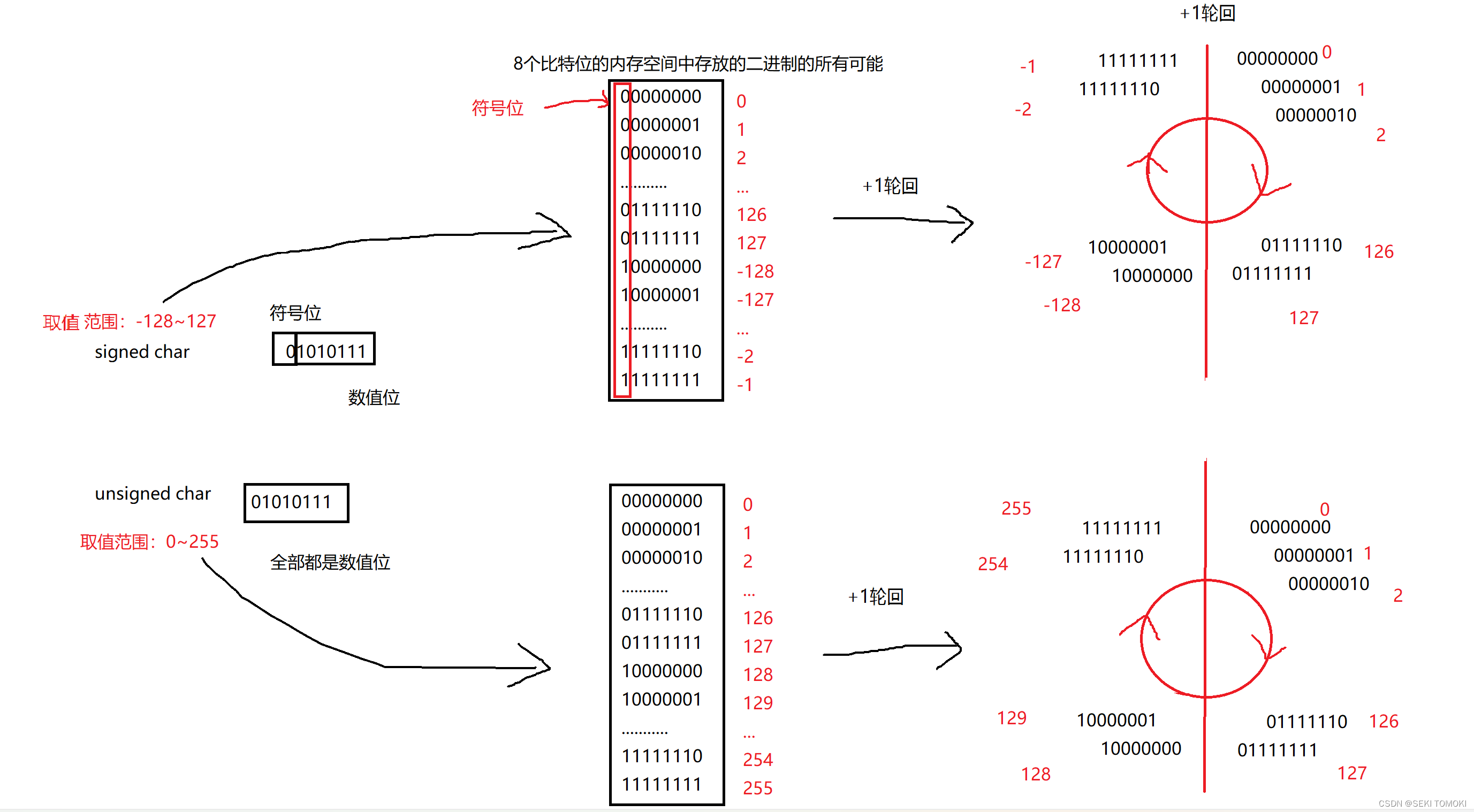
+1轮回:
3. 大小端字节序存储
内存里以1个字节为单位,如果需要存储一个大小为多个字节的整型数据时,就需要多个内存单元存储这个数据,那么要怎么存?顺着存还是倒着存?这是个问题。实际上,不同的机器存的顺序不同,这里需要了解大小端的概念。
3.1. 什么是大小端字节序?
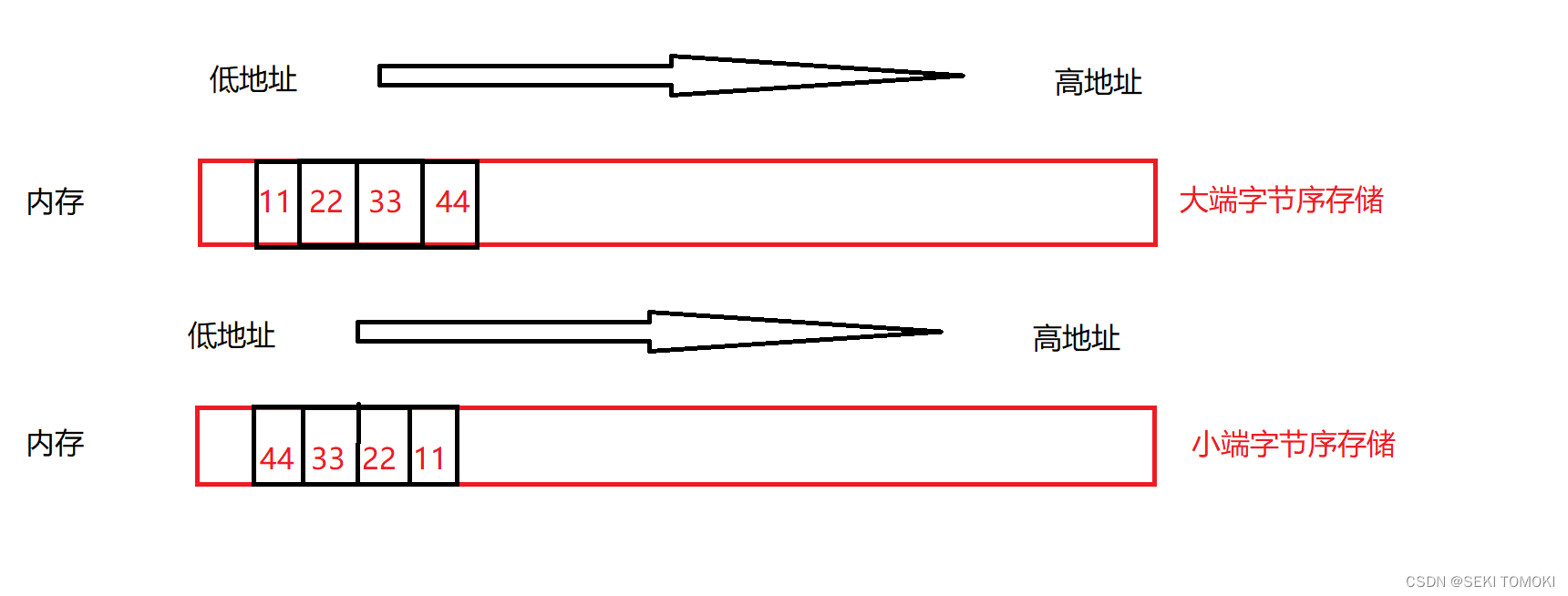
1. 字节序:以字节为单位讨论存储顺序。char类型不讨论顺序,因为char类型的数据只占一个字节。
2. 大端字节序存储:把一个数据的低位字节的内容,存放在高地址处,把这个数据的高位字节的内容,存放在低地址处。
3。 小端字节序存储:把一个数据的低位字节的内容,存放在低地址处,把这个数据的高位字节的内容,存放在高地址处。
举例,在int类型的变量中存储一个数 0x11223344:
3.2. 测试当前机器是大端还是小端?
创建一个整型变量a,把1赋值给a,内存会为变量a开辟连续的4个字节的空间并且存储1。如果该机器是小端字节序存储,那么读取变量a的最低位的字节时读取到的应该是1,否则该机器是大端字节序存储。
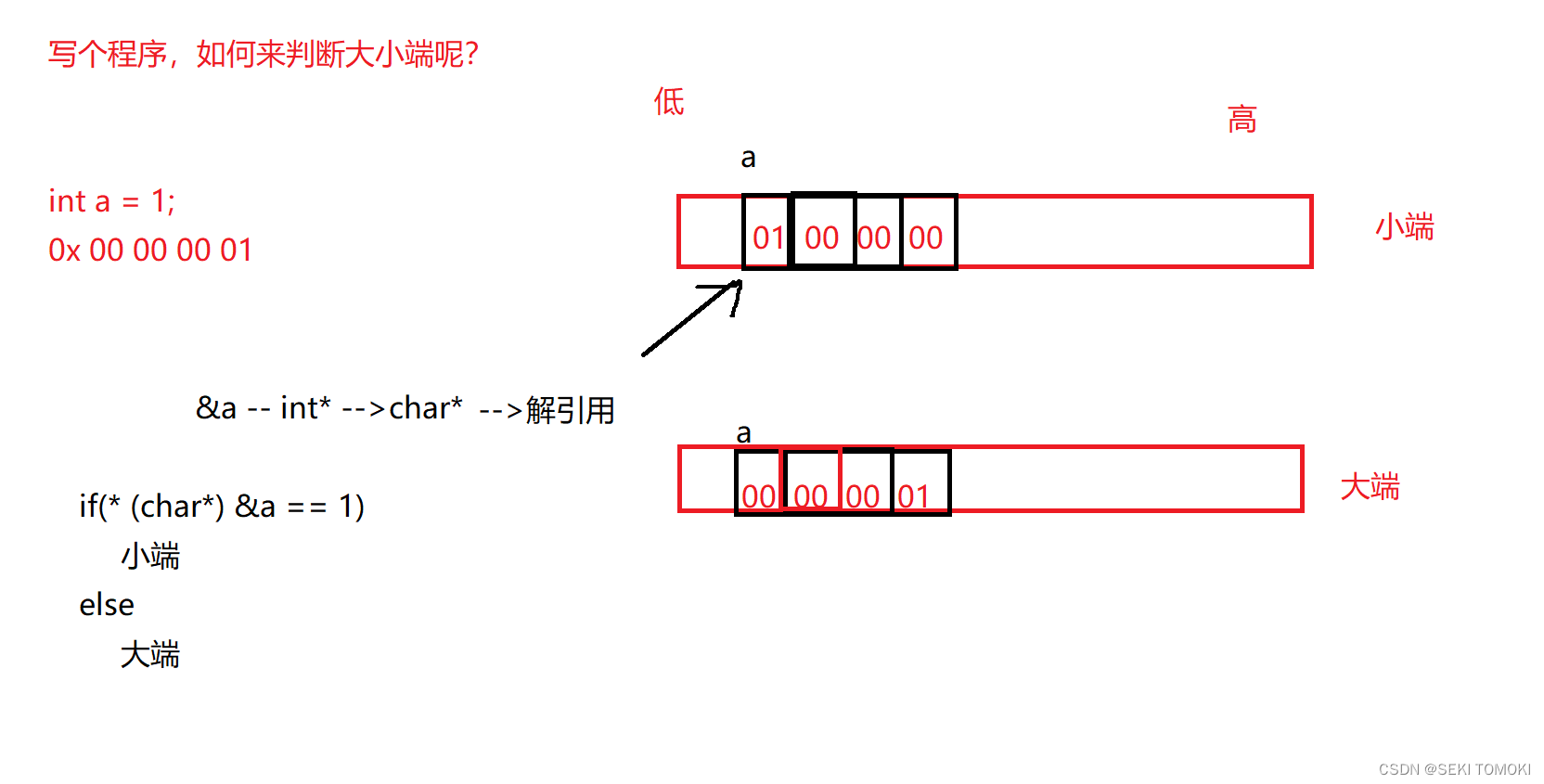
为什么(int* )类型的地址a要强制转换为(char*)类型?
对(int* )类型的地址进行解引用,对该地址访问对象的大小是4个字节;
对(char* )类型的地址进行解引用,对该地址访问对象的大小是1个字节;
而我们只需要看变量a地址指向的第一个的字节是否是1即可,不访问后面3个字节的数据,所以把地址a的(int* )类型强制转换为(char*)类型。
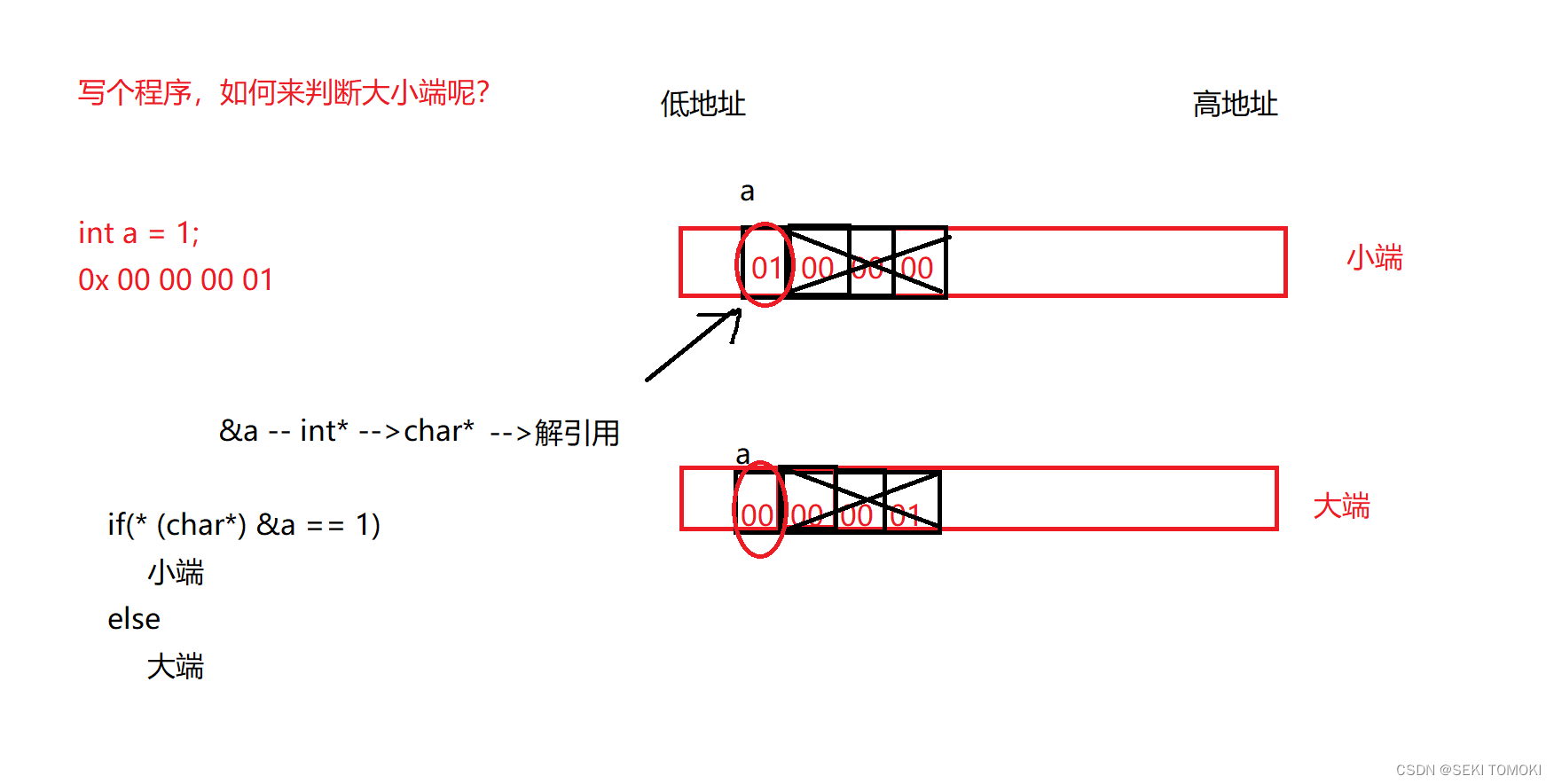
代码实现如下:
#include<stdio.h>
//小端返回1,大端返回0
int check_system()
{
int a = 1;
return *(char*)&a;
}
int main()
{
int ret = check_system();
if(ret ==1)
printf("小端");
else
printf("大端");
return 0;
}
4. 例题和解析
例1:
#include<stdio.h>
int main()
{
char a = -1;
signed char b = -1;
unsigned char c = -1;
printf("a=%d b=%d c=%d", a, b, c);
return 0;
}
例1解析:

例2:
#include<stdio.h>
int main()
{
char a = -128;
char b = 128;
printf("%u,%u", a,b);
return 0;
}
例2解析:


例3:
#include<stdio.h>
int main()
{
int i = -20;
unsigned int j = 10;
printf("%d\n", i + j);
return 0;
}
例3解析:

例4:
#include<stdio.h>
int main()
{
unsigned int i;
for (i = 9; i >= 0; i--)
{
printf("%u\n", i);
}
return 0;
}
例4解析:
unsigned int类型的取值范围:0到4294967295,是不可能出现负数的,所以i>=0是恒成立的,出现死循环。
0减1会变成32个1组成的二进制序列,直接转换为二进制序列就是4294967295,然后一只减1,最后减到0又回到4294967295…
例5:
#include<stdio.h>
#include<string.h>
int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d", strlen(a));
return 0;
}
例5解析:

例6:
#include<stdio.h>
int main()
{
unsigned char i=0;
for (i = 0; i <= 255; i++)
{
printf("hello world\n");
}
return 0;
}
例6解析:
死循环,因为i<=255恒成立,unsigned char类型的变量只能存一个字节,255是一个字节能表示的最大的数字了,255加1因为无法存储第9位,前8位数都变成0…