目录
前言
一、TableAgent介绍
1. 人人都是数据分析师
2. TableAgent 特点
3. 融合创新应用的新成果
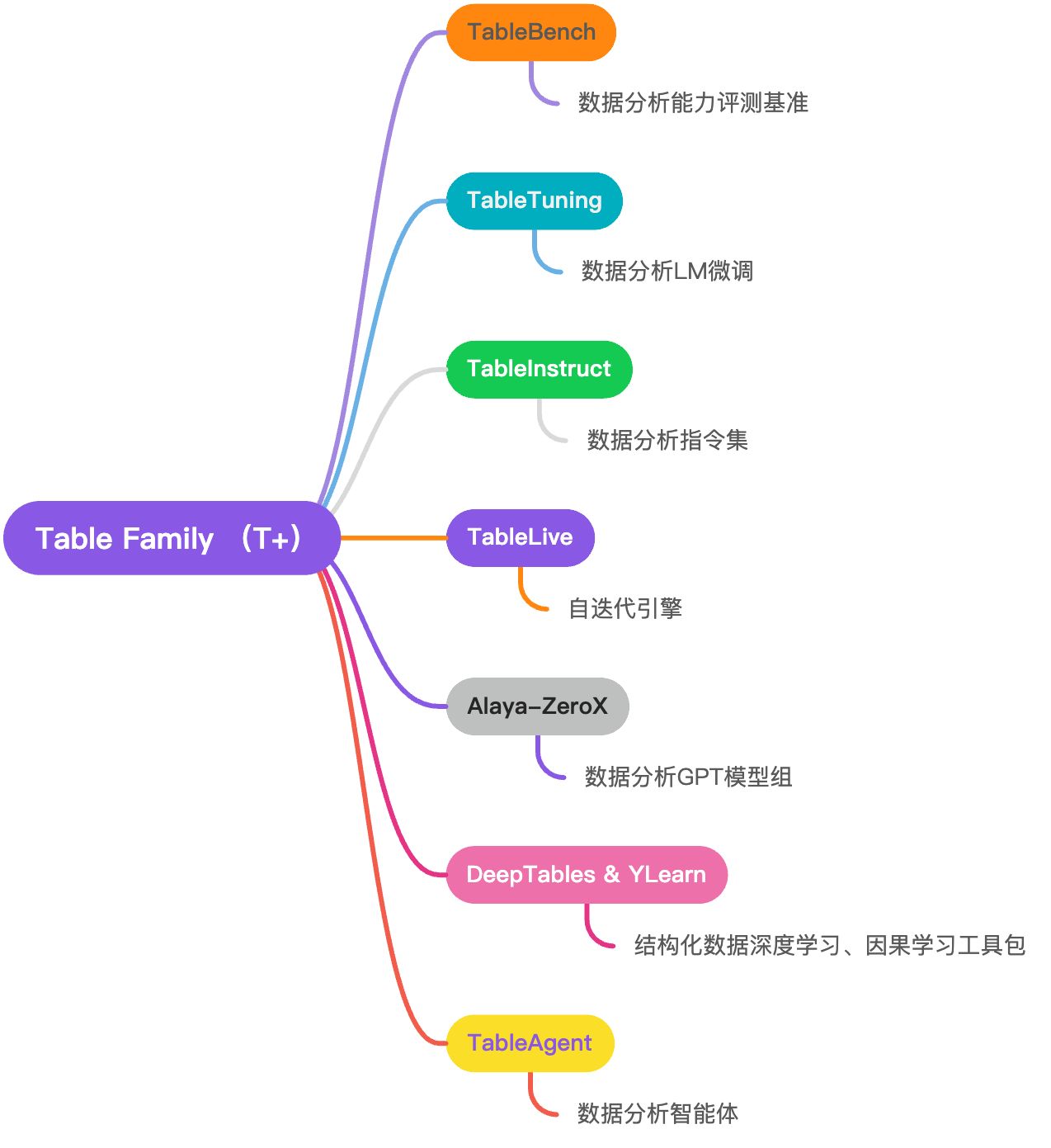
3.1. DataCanvas Table Family (T+)
二、注册并体验TableAgent
1. 注册
2. 样例数据集体验
2.1. 选择样例数据集
2.2. 数据分析能力
三、实际场景数据分析
1. 准备数据
2. 数据概览
3. 数据分析方向
4. 导入数据
4.1. 年龄分布分析
4.1.1. 效果展示
4.1.2. 代码分析
4.1.3. 年龄分布对比分析结果
5. 性别比例分析
5.1.1. 效果展示
5.1.2. 代码分析
5.1.3. 性别比例对比分析结果
6. 学历分布分析
6.1.1. 代码分析
6.1.2. 学历分布对比分析结果
7. 工作年限统计分析
7.1.1. 效果展示
7.1.2. 代码分析
7.1.3. 工作年限对比分析结果
8. 其他方向数据分析
四、总结
前言
在当今数字化时代,数据分析已成为企业决策和业务发展中不可或缺的一环。然而,随着数据量的不断增长和多样化,传统的数据分析方法已无法满足对复杂数据的深入挖掘和理解。为了应对这一挑战,我们迫切需要一种与众不同的数据分析工具来帮助我们更好地理解和利用海量数据。
目前九章云极DataCanvas公司自主研发的TableAgent举办产品体验的活动接来,我们就一起体验一下吧!!
一、TableAgent介绍
TableAgent是基于九章云极DataCanvasAlaya九章元识大模型的自主研发智能体。它具备出色的意图理解、分析建模和洞察力,并支持私有化部署,适用于企业级数据分析。TableAgent在充分理解用户意图后,利用统计科学、机器学习和因果推断等高级建模技术从数据中挖掘价值,为用户提供深刻见解的分析观点和行动指导。
1. 人人都是数据分析师

九章云极DataCanvas公司主任架构师杨健介绍称,TableAgent在Alaya元识基础上进化而来,是从0到1的交互式结构化数据分析的突破,是企业数据分析的全新方式,让“人人都是数据分析师”得以从梦想照进现实。
2. TableAgent 特点

3. 融合创新应用的新成果
Alaya九章元识大模型是支撑TableAgent关键技术的产物,由九章云极DataCanvas公司自主研发。Alaya-ZeroX模型组在Alaya基础大模型的基础上进行微调,通过一系列擅长不同能力的模型组合来完成复杂的分析任务。不同参数规模的模型同时满足了对生成质量和推理性能的要求。
3.1. DataCanvas Table Family (T+)
二、注册并体验TableAgent
1. 注册
目前TableAgent 有免费公测地址,注册后可以免费使用5次,次数使用完了,可以认证申请增加次数(每天15次)

点击立刻体验
管理界面
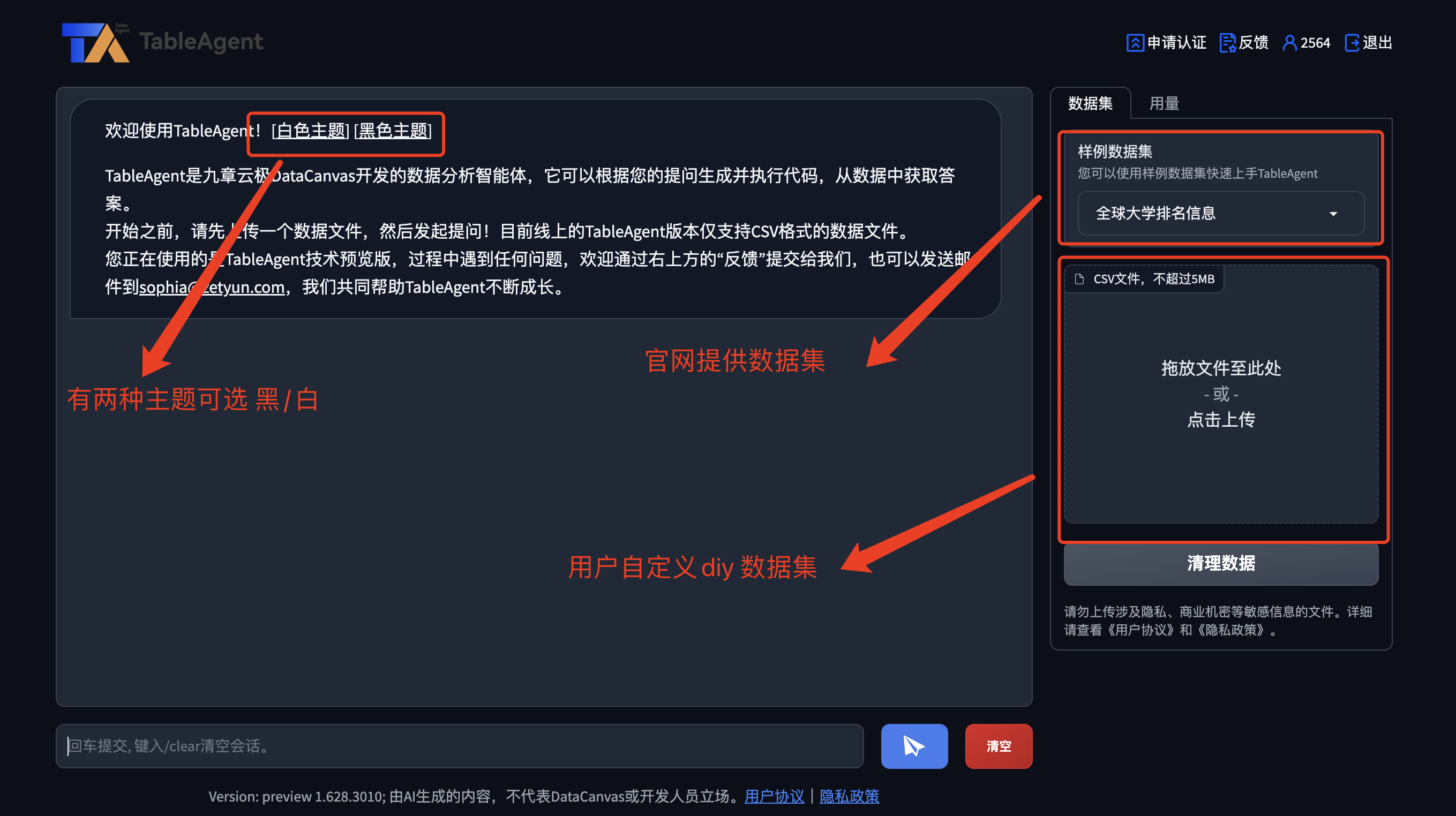
2. 样例数据集体验
2.1. 选择样例数据集
如下图所示 我们选择 《电影点评》 的数据集
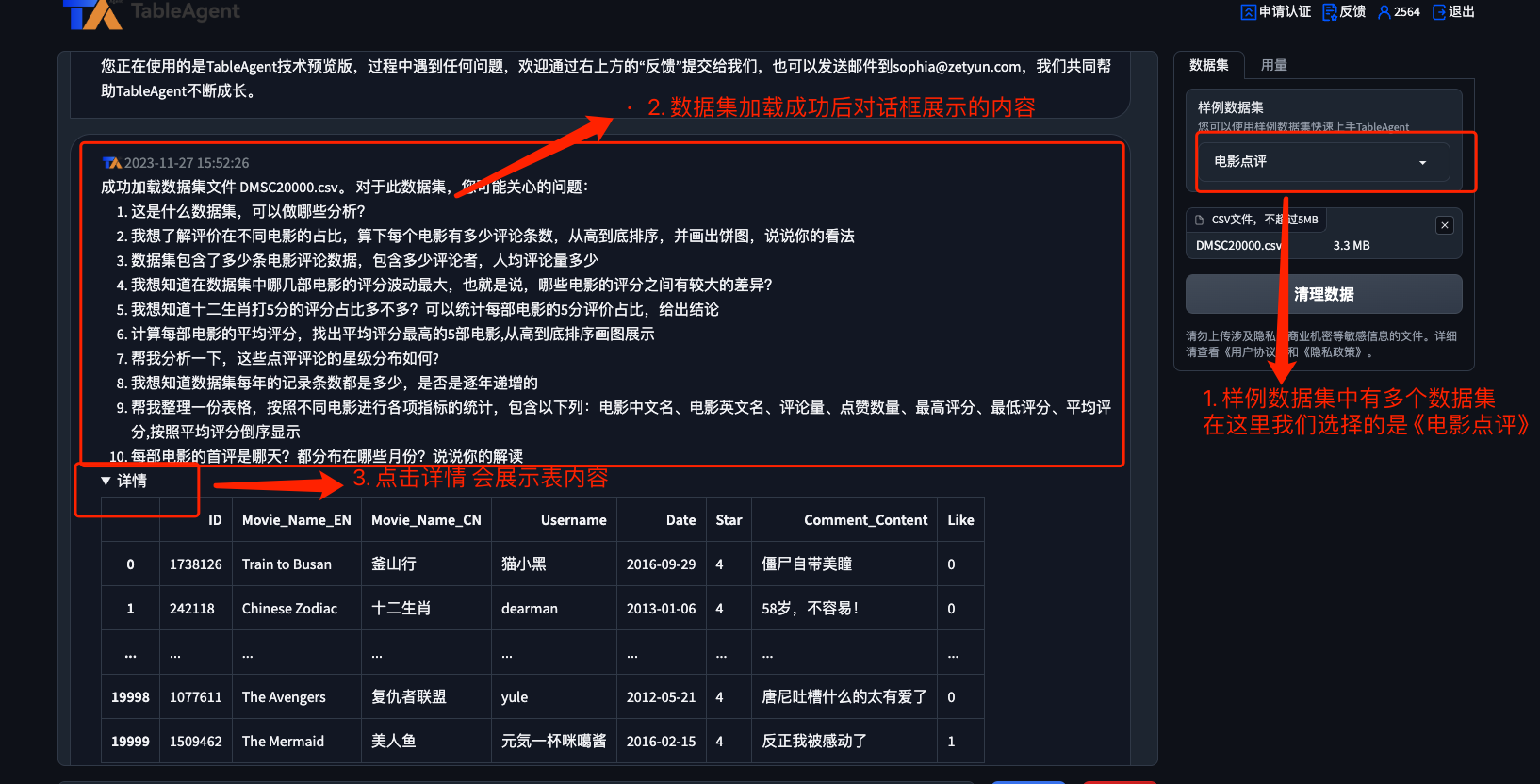
亮点:
- 选择数据集后, 对话框内自动给出可能关心的问题
- 在详情中有详细的csv 表格数据
- 输入框内,会有一个提问示例,极大的帮助了用户操作
2.2. 数据分析能力
提问内容如下 : 我想了解评价在不同电影的占比,算下每个电影有多少评论条数,从高到底排序,并画出饼图,说说你的看法
返回效果如下图所示:


亮点:
- 点击 详情 会展示关于csv 表格的详细的代码解析
- 饼状图绘制的方法及代码分析讲解
- 同时会还有思路的分析
三、实际场景数据分析
1. 准备数据
接下来我们使用部分人才库的数据 进行多方项的分析
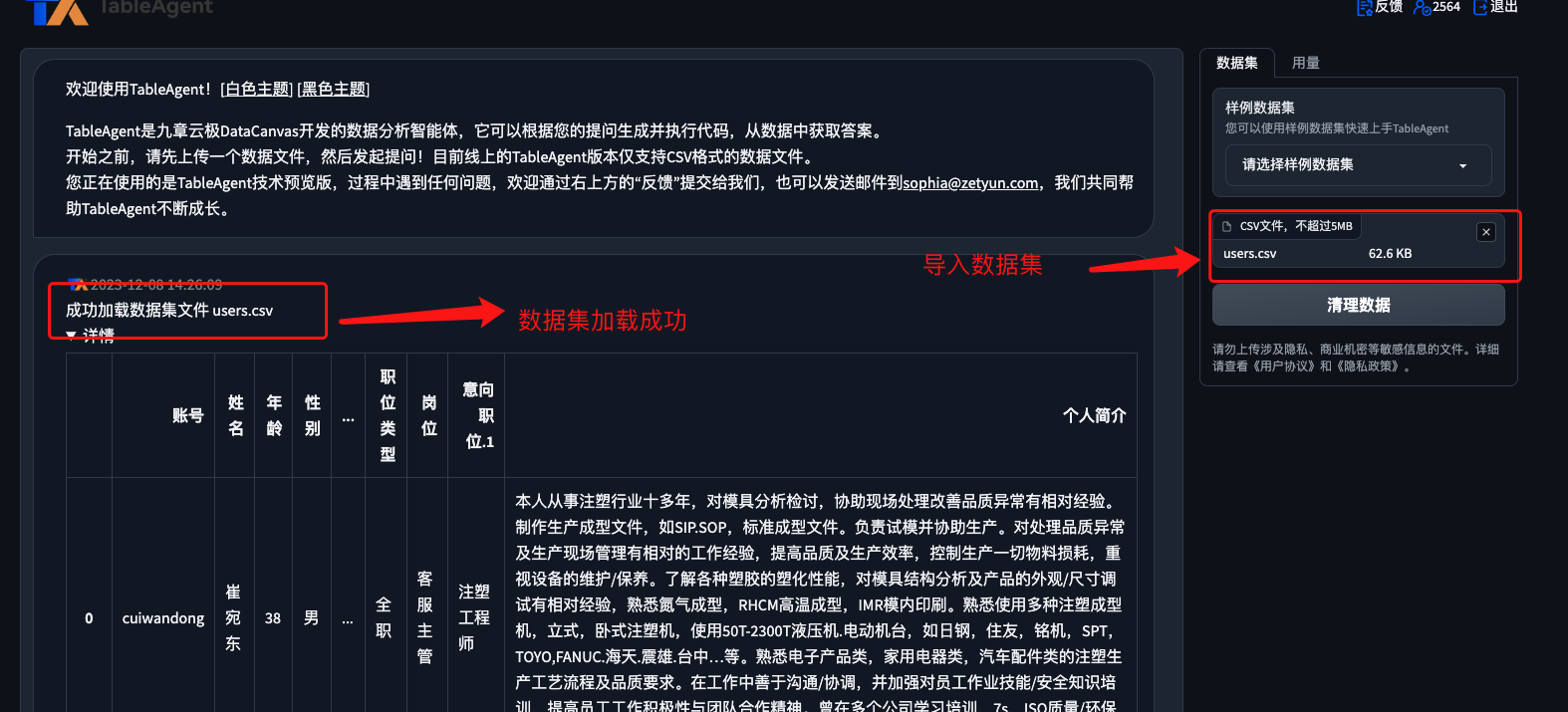
users.csv
2. 数据概览
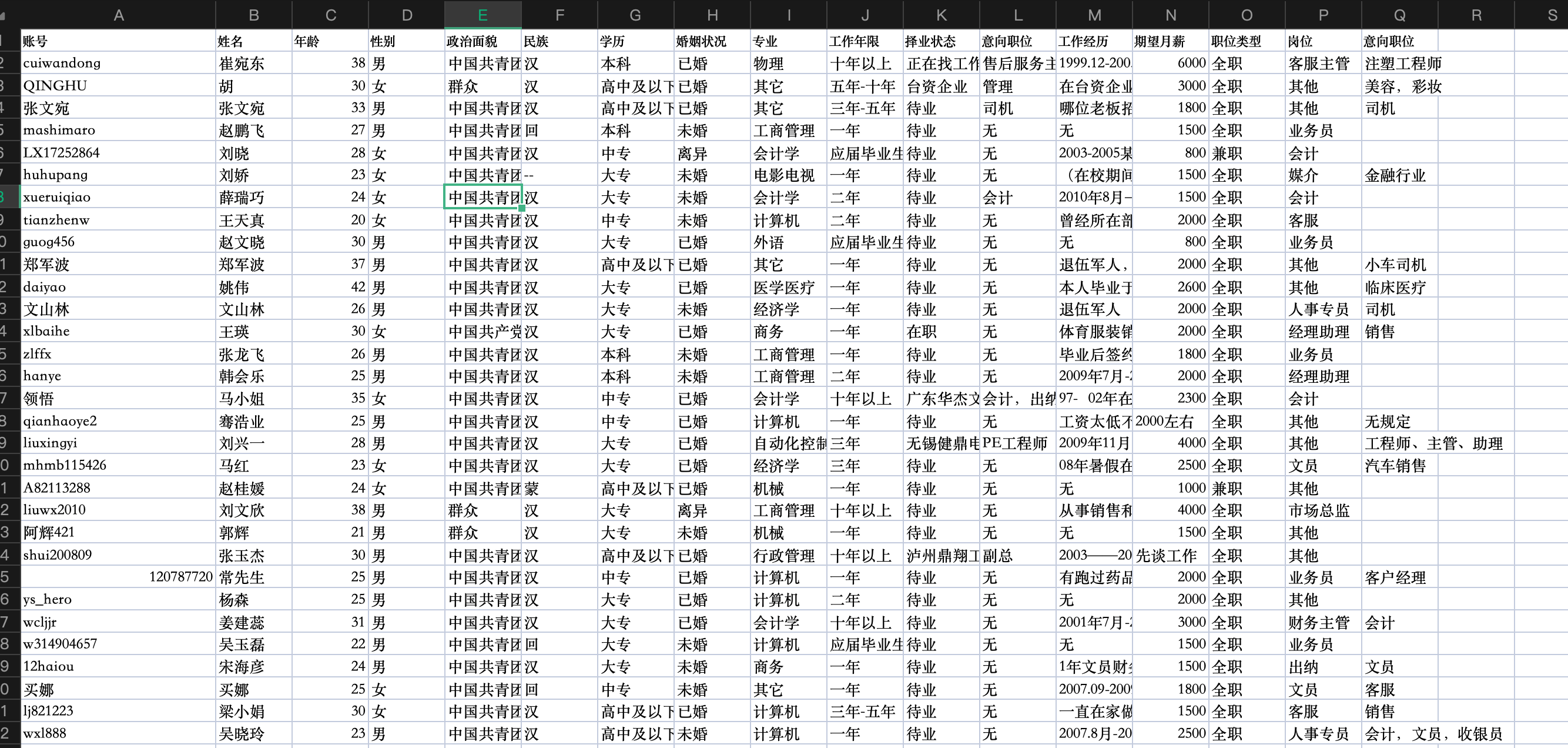
在数据集中包含以下信息:
账号 , 姓名,年龄,性别,政治面貌,民族,学历,婚姻状况,专业,工作年限,择业状态,意向职位, 工作经历, 期望月薪, 职位类型, 岗位,意向职位,个人简介
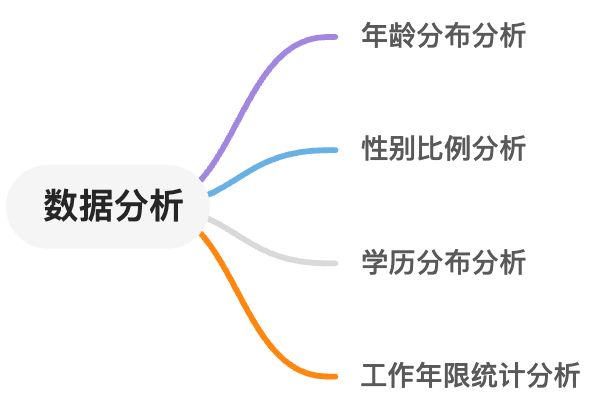
3. 数据分析方向
我们接下来将使用TableAgent 对下面的十个方向进行分析, 从而帮助我们更好的理解数据集中的人口特征、职业倾向和意向等信息
4. 导入数据
4.1. 年龄分布分析
提问:使用柱状图或饼图展示不同年龄段的人数占比。
4.1.1. 效果展示
| TableAgent分析结果 |
我自己分析结果 |
| 
|
|
4.1.2. 代码分析
| 维度 |
TableAgent分析结果 |
| 代码 |
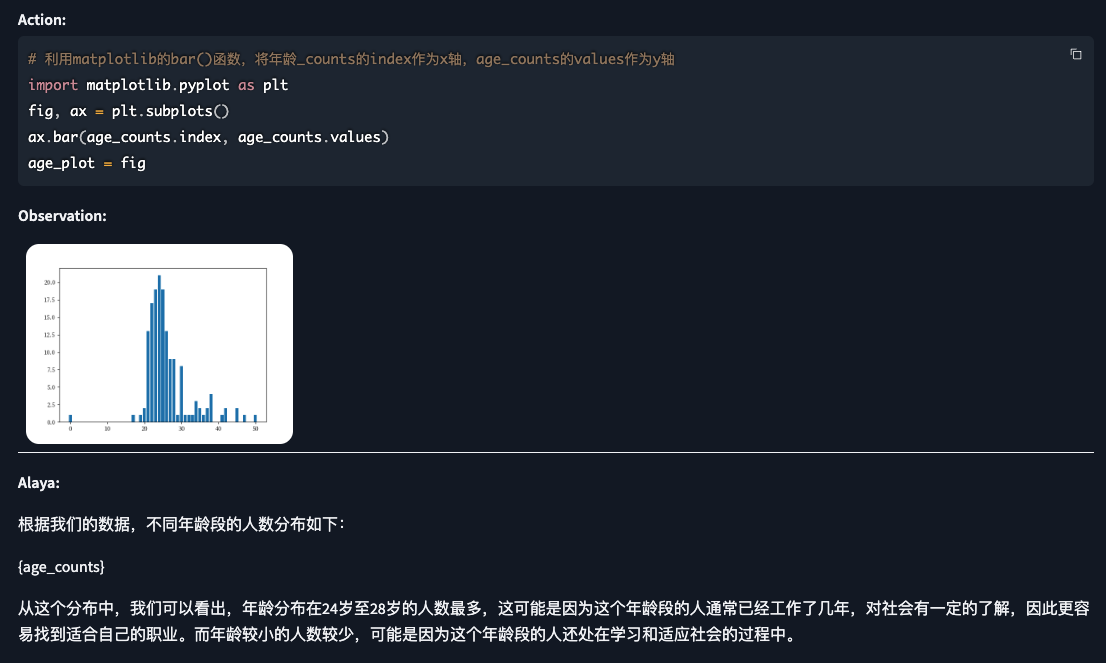
# 利用matplotlib的bar()函数,将年龄_counts的index作为x轴,age_counts的values作为y轴
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.bar(age_counts.index, age_counts.values)
age_plot = fig
|
| 分析 |

|
| 维度 |
我自己分析结果 |
| 代码 |
import random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
#指定字体文件路径
font_path = 'wendaoshouyuanti.ttf'
# 加载自定义字体文件
custom_font = FontProperties(fname=font_path)
# 设置默认字体为自定义字体
plt.rcParams['font.family'] = custom_font.get_name()
data = pd.read_csv("users.csv")
ages = data["年龄"]
plt.hist(ages, bins=20)
# 生成与数据长度相同的颜色列表
colors = ['red', 'green', 'blue', 'orange', 'purple'] # 可根据需要添加更多颜色
# 计算每个年龄段的人数
bins = np.arange(0, 50, 5)
counts, _ = np.histogram(ages, bins=bins)
# 绘制柱状图,并为每个柱子设置随机颜色
for i in range(len(counts)):
plt.bar(bins[i], counts[i], width=8, color=colors[random.randint(0, len(colors) - 1)])
plt.xlabel("年龄", fontproperties=custom_font)
plt.ylabel("数量", fontproperties=custom_font)
plt.title("年龄分布", fontproperties=custom_font)
plt.show()
|
| 解析 |
- 导入所需的库,包括随机数生成、数组操作、数据处理、绘图和自定义字体管理。
- 指定字体文件路径并加载自定义字体文件。然后,通过plt.rcParams['font.family']将默认字体设置为自定义字体。
- 从名为"users.csv"的CSV文件中读取数据,并将年龄数据存储在ages变量中。
- 使用plt.hist()函数绘制直方图,其中ages是要绘制的数据,bins=20指定了将数据分成20个区间。
- 定义一个颜色列表colors和一个年龄区间列表bins。使用np.histogram()计算每个年龄区间的人数,并将结果存储在counts变量中。
- 使用循环遍历每个年龄区间,调用plt.bar()函数绘制柱状图,并为每个柱子设置随机颜色。
- 设置x轴、y轴和标题的标签,并使用自定义字体进行显示。
|
4.1.3. 年龄分布对比分析结果
| TableAgent分析结果 |
我自己分析结果 |
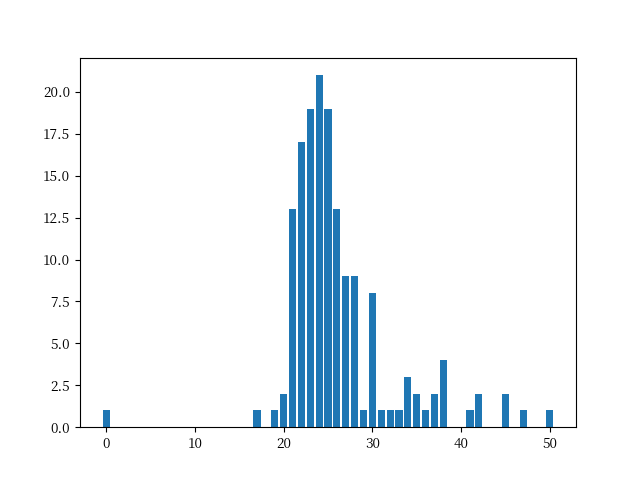
| 从这个分布中,我们可以看出,年龄分布在24岁至28岁的人数最多,这可能是因为这个年龄段的人通常已经工作了几年,对社会有一定的了解,因此更容易找到适合自己的职业。而年龄较小的人数较少,可能是因为这个年龄段的人还处在学习和适应社会的过程中。 |
- 从柱状图中可以发现大部分人的年龄都在19岁及以上
- 在40岁以上的人数开始逐渐降低
- 19岁以下人群较少,最大的可能性是在学习中
|
5. 性别比例分析
提问: 使用饼图展示男性和女性的比例
5.1.1. 效果展示
| TableAgent分析结果 |
我自己分析结果 |
| 
|
|
5.1.2. 代码分析
| 维度 |
TableAgent分析结果 |
| 代码 |
# 使用matplotlib的pie()函数,以gender_counts为输入,绘制饼图
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.pie(gender_counts, labels=['男', '女'], autopct='%1.1f%%')
ax.set_title('Gender Ratio')
gender_ratio_fig = fig
|
| 分析 |


|
| 维度 |
我自己分析结果 |
| 代码 |
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 读取CSV文件
data = pd.read_csv('users.csv')
# 获取“性别”列数据
gender_data = data['性别']
# 统计男女人数
male_count = (gender_data == '男').sum()
female_count = (gender_data == '女').sum()
# 自定义字体设置
custom_font = FontProperties(fname='wendaoshouyuanti.ttf')
# 创建饼图
labels = ['男', '女']
sizes = [male_count, female_count]
colors = ['lightblue', 'lightcoral']
explode = (0.1, 0) # 突出显示男性部分
# 将自定义字体应用于标签文本
plt.pie(sizes, explode=explode, labels=labels, colors=colors, autopct='%1.1f%%', startangle=140,
textprops={'fontproperties': custom_font})
plt.axis('equal') # 保持长宽比一致
plt.title('男女比例', fontproperties=custom_font) # 使用自定义字体
# 显示饼图
plt.show()
|
| 解析 |
- 导入了必要的模块和库,包括pandas,matplotlib.pyplot和FontProperties。
- 使用pd.read_csv()函数读取了一个名为users.csv的CSV文件,并将其保存到变量data中。这个CSV文件包含了一个名为“性别”的列,其中包含了一组用户的性别数据。
- 从data中获取了“性别”列的数据,保存到变量gender_data中。
- 使用sum()函数和布尔索引,分别统计了男性和女性的数量,并将其保存到变量male_count和female_count中。
- 使用FontProperties类加载了一个名为wendaoshouyuanti.ttf的自定义字体,并将其保存到变量custom_font中。
- 创建了一个饼图,其中男性和女性分别用labels列表表示,他们的数量分别用sizes列表表示。colors列表表示了男性和女性部分的颜色,explode元组用于突出显示男性部分。autopct参数指定了饼图中百分比的显示格式,startangle参数指定了饼图的起始角度。
- 将自定义字体应用于饼图的标签文本,使用textprops参数将自定义字体设置为饼图标签的字体。
- 使用plt.axis('equal')函数设置了饼图的长宽比一致。
- 设置了饼图的标题,并将自定义字体应用于标题,最后通过plt.show()函数显示了饼图。
|
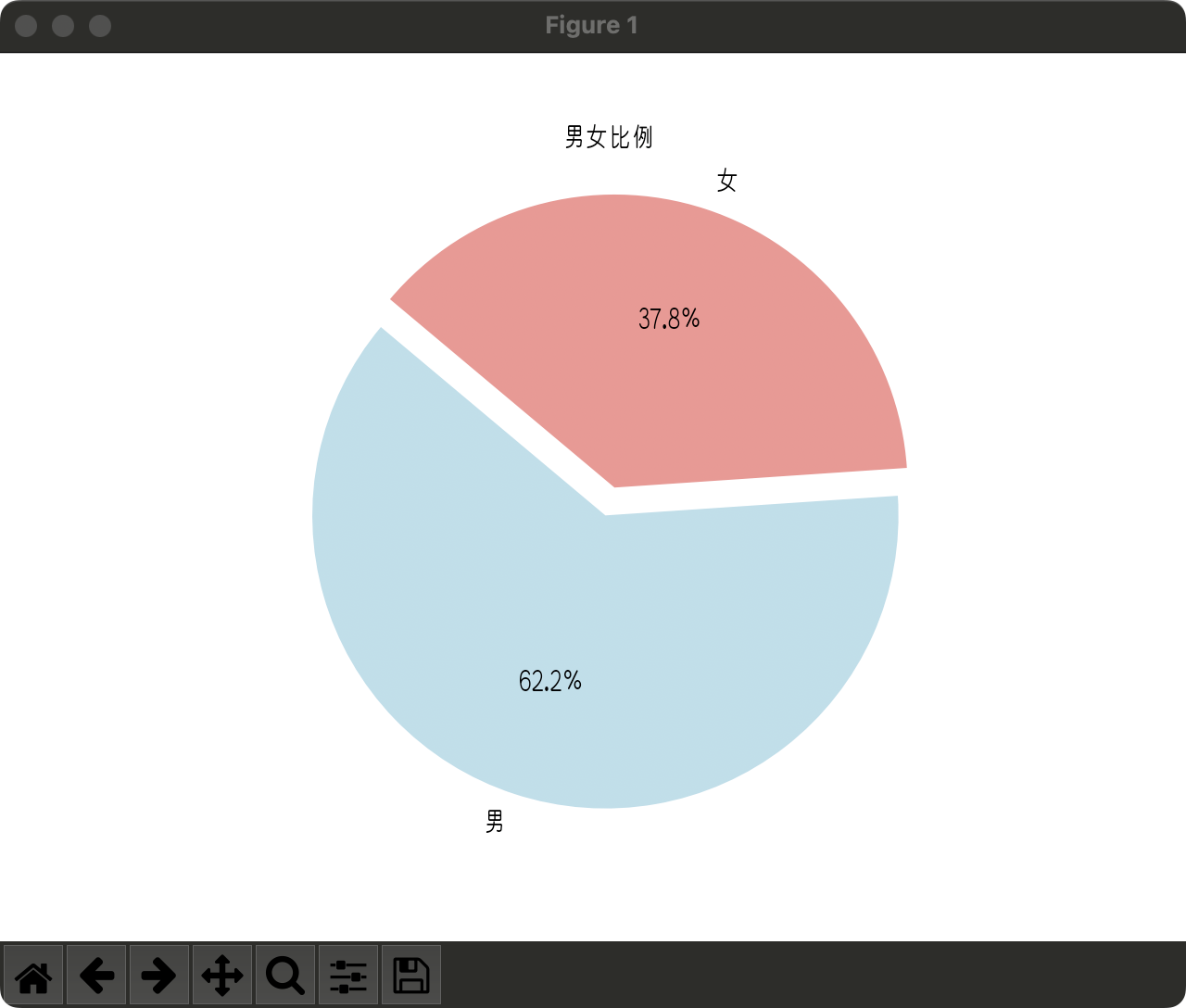
5.1.3. 性别比例对比分析结果
| TableAgent分析结果 |
我自己分析结果 |
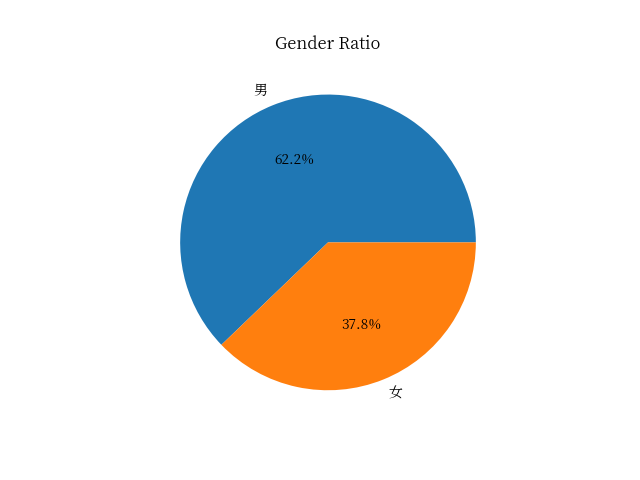
| 1. 从我们的数据中可以看出,男性用户的数量为97,女性用户的数量为59。这意味着在我们的用户群体中,男性占据了主导地位。
- 从图中可以看出,男性用户的比例远高于女性用户,这可能是因为我们的应用程序和网站主要是由男性用户使用的。然而,这并不意味着我们的内容或者服务应该只针对男性用户。对于女性用户,我们也可以提供适合他们的内容和服务。
总的来说,我们的目标是为尽可能多的用户提供良好的体验,无论他们的性别是什么。我们已经采取了一些措施,比如在界面设计上为女性用户考虑,以及提供内容和服务时考虑到各种用户的需求。 |
- 性别比例在人才招聘中的影响:根据男性用户数量明显多于女性用户数量的结果,可能反映了在某些人才领域中,男性占据人才市场的主导地位。这可能与特定行业或职位的性别偏好有关。
- 性别平等问题:通过比较不同性别用户在职位等级、薪酬水平、晋升机会等方面的数据,可以评估在人才工作中是否存在性别平等问题。如果发现男性和女性在这些方面存在差距,可能需要考虑采取措施促进性别平等。
- 人才招聘策略:根据不同性别用户的数量比例,可以对人才招聘策略进行优化。例如,如果某个行业或职位中女性用户数量较少,可以针对女性开展更有针对性的招聘活动或提供更具吸引力的福利待遇,以增加女性人才的吸引力。
|
6. 学历分布分析
提问:表头为"学历"列的指的是每个人的学历, 使用条形图展示不同学历层次的人数占比
效果展示
| TableAgent分析结果 |
我自己分析结果 |
| 
|
|
6.1.1. 代码分析
| 维度 |
TableAgent分析结果 |
| 代码 |
# 可以通过matplotlib的bar函数来实现,源码是education_ratios.plot(kind='bar')
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.bar(education_ratios.index, education_ratios.values)
plt.xlabel('Education Levels')
plt.ylabel('Ratios')
plt.title('Ratios of Different Education Levels')
plt.show()
education_ratios_plot = plt.gcf()
|
| 分析 |
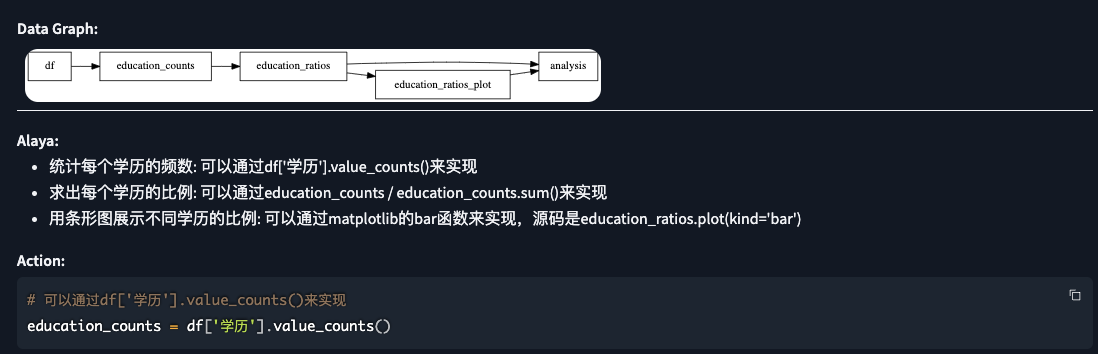
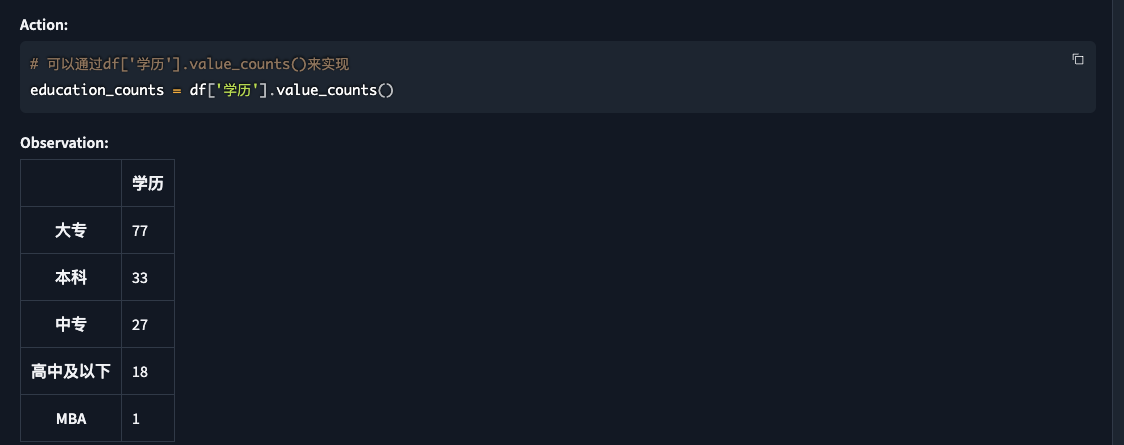
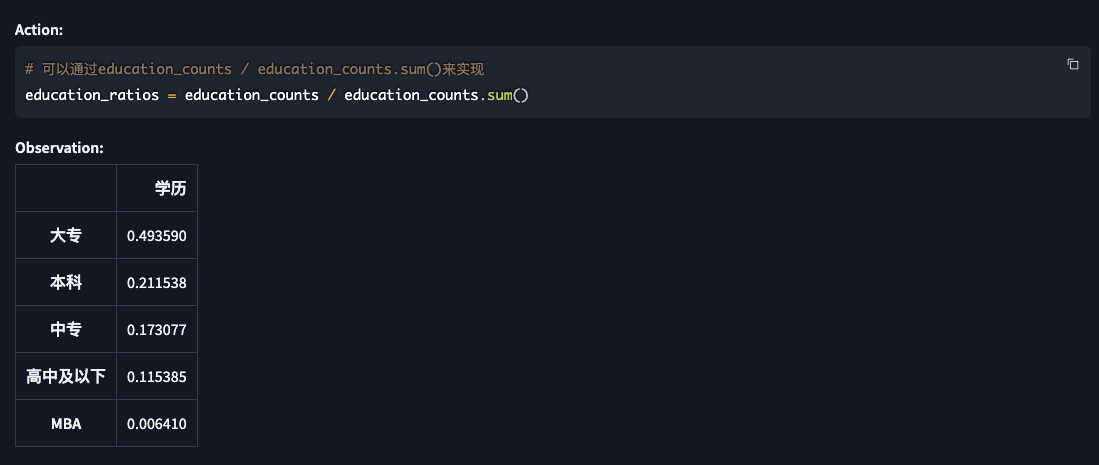
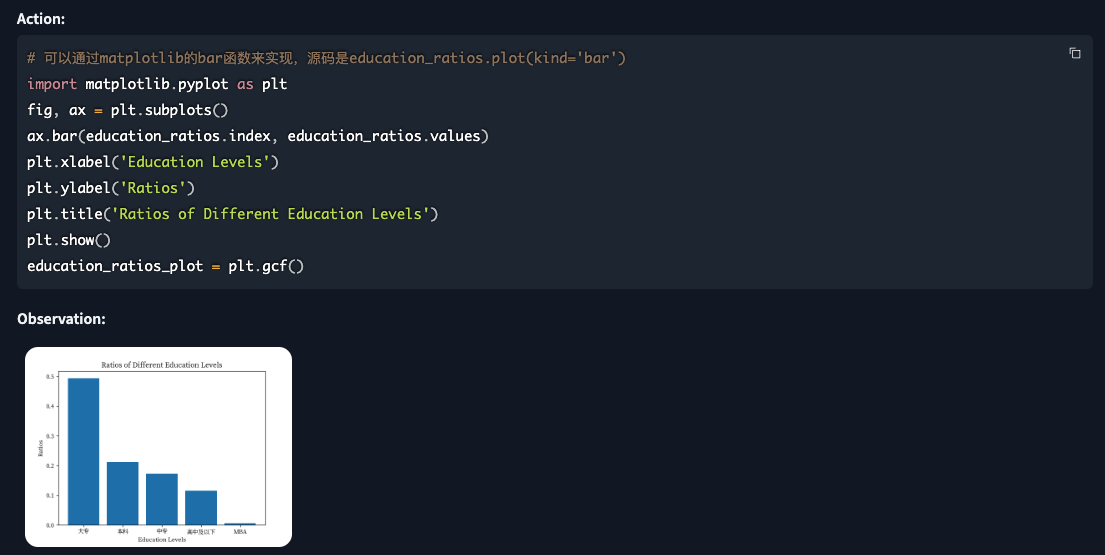

|
| 维度 |
我自己分析结果 |
| 代码 |
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 读取CSV文件并提取“学历”列数据
data = pd.read_csv('users.csv')
education_data = data['学历']
# 统计不同学历层次的人数
education_counts = education_data.value_counts()
# 计算不同学历层次的人数占比
education_percentages = education_counts / education_counts.sum() * 100
# 设置自定义字体(确保已安装相应字体文件)
font_path = 'wendaoshouyuanti.ttf'
custom_font = fm.FontProperties(fname=font_path)
# 绘制条形图
plt.bar(education_percentages.index, education_percentages.values)
plt.xlabel('学历', fontproperties=custom_font)
plt.ylabel('人数占比 (%)', fontproperties=custom_font)
plt.title('不同学历层次的人数占比', fontproperties=custom_font)
plt.xticks(rotation=45, fontproperties=custom_font)
plt.show()
|
| 解析 |
- 通过import语句导入了需要使用的三个库:pandas用于数据处理,matplotlib.pyplot用于绘图,matplotlib.font_manager用于管理字体。
- 使用pd.read_csv('users.csv')读取名为'users.csv'的CSV文件,并将数据存储在名为data的DataFrame中。
- 从DataFrame data 中提取名为“学历”的列数据,存储在名为education_data的Series中。
- 使用value_counts()方法统计不同学历层次的人数,结果存储在名为education_counts的Series中。
- 计算不同学历层次的人数占比,将结果存储在名为education_percentages的Series中。这里使用了/进行元素级别的除法,然后乘以100,得到百分比。
- 指定了一个自定义的字体文件'wendaoshouyuanti.ttf',并使用fm.FontProperties(fname=font_path)创建了一个自定义字体对象custom_font。
- 利用plt.bar()绘制条形图,横轴为不同学历层次,纵轴为人数占比,使用了自定义的字体设置。接着使用plt.xlabel()、plt.ylabel()和plt.title()设置了横轴标签、纵轴标签和图表标题,并使用plt.xticks(rotation=45)设置了横坐标标签的旋转角度。最后使用plt.show()进行图表展示。
|
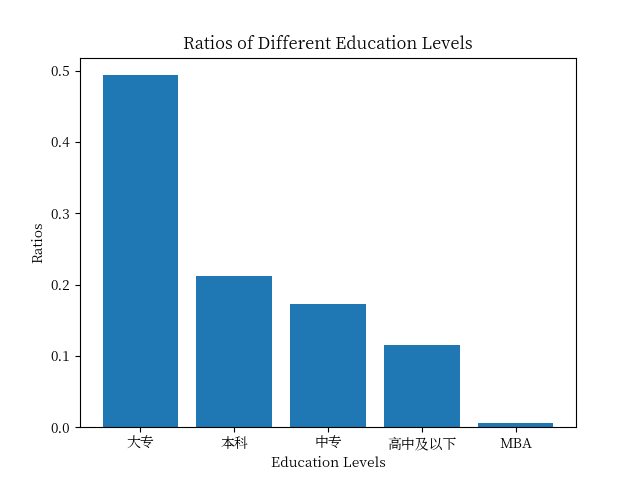
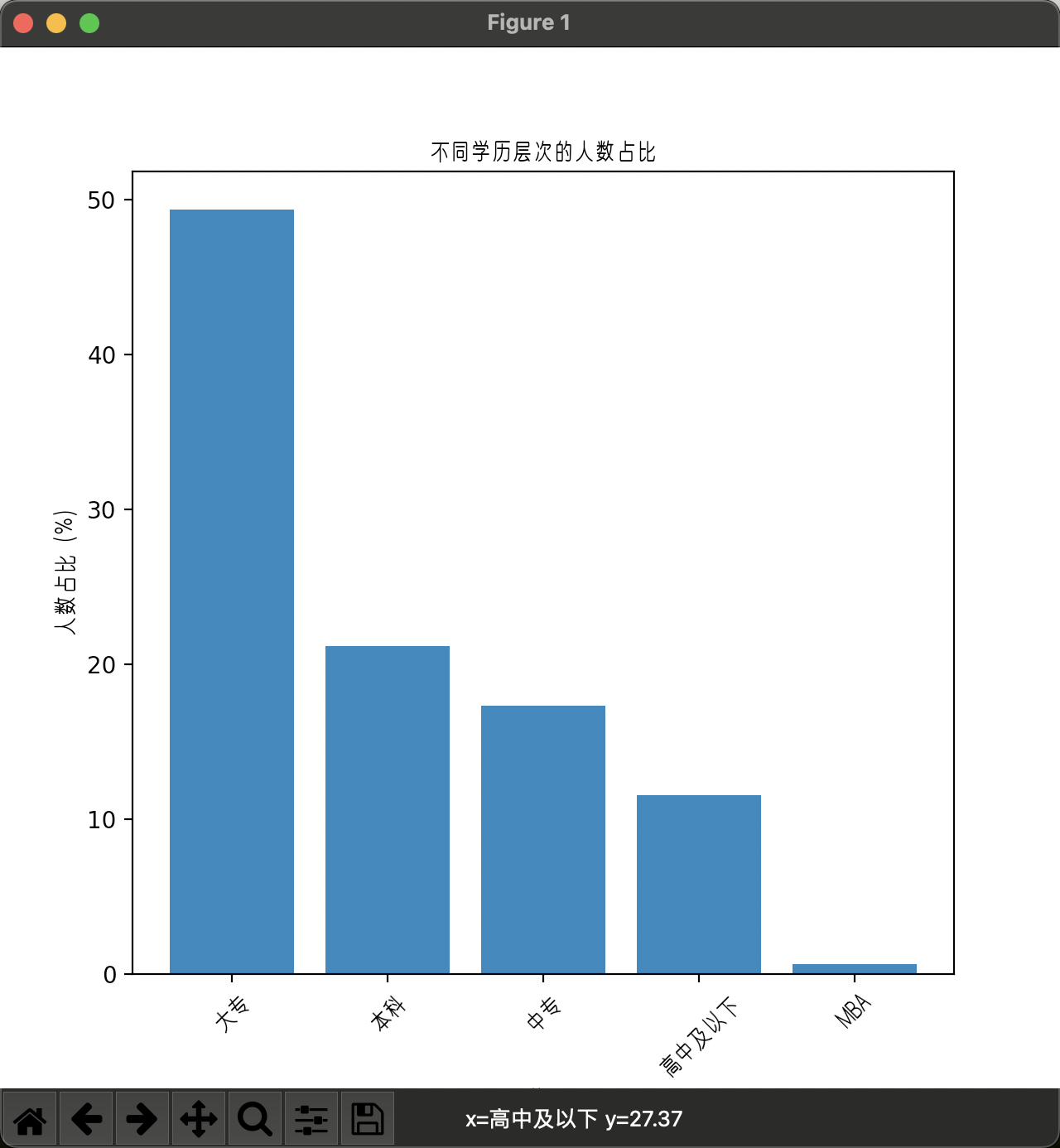
6.1.2. 学历分布对比分析结果
| TableAgent分析结果 |
我自己分析结果 |
| 从这个图中,我们可以看到,
- 大专学历的人数占比最高,达到了49.36%,
- 其次是本科学历,占比为21.15%。
- 中专学历和高中及以下学历的人数占比分别为17.31%和11.54%。
- MBA学历的人数占比最少,只有0.44%。
这些数据表明,在我们的数据集中,大专学历的人数最多,其次是本科学历,这两种学历的人数占比都超过了一半。这可能意味着我们的数据集中,大专学历和本科学历的人数最多,这两种学历的人数占比也最高。这可能是因为这两种学历的人员更容易获取工作,或者这两种学历的学生更容易找到工作。 |
- 不同学历层次的人数占比 : 大专的人数占比最高,约为49.04%,其次是本科(21.99%)、中专(18.06%)、高中及以下(12.04%)和MBA(0.67%)。
- 分析结果可以帮助我们了解给定学历数据的分布情况,以及不同学历层次的人数占比情况
|
7. 工作年限统计分析
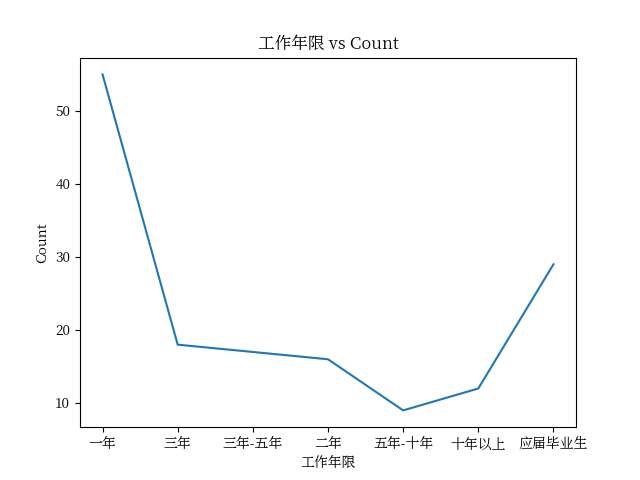
提问: 表头为"工作年限"列的指的是每个人的工作年限,使用折线图展示不同工作年限的人数分布情况
7.1.1. 效果展示
| TableAgent分析结果 |
我自己分析结果 |
| 
|
|
7.1.2. 代码分析
| 维度 |
TableAgent分析结果 |
| 代码 |
# 利用matplotlib的plot方法,将'工作年限'列作为x轴,'Count'列作为y轴,绘制折线图
import matplotlib.pyplot as plt
work_year_count_plot = plt.figure()
plt.plot(work_year_count['工作年限'], work_year_count['Count'])
plt.xlabel('工作年限')
plt.ylabel('Count')
plt.title('工作年限 vs Count')
plt.show()
|
| 分析 |

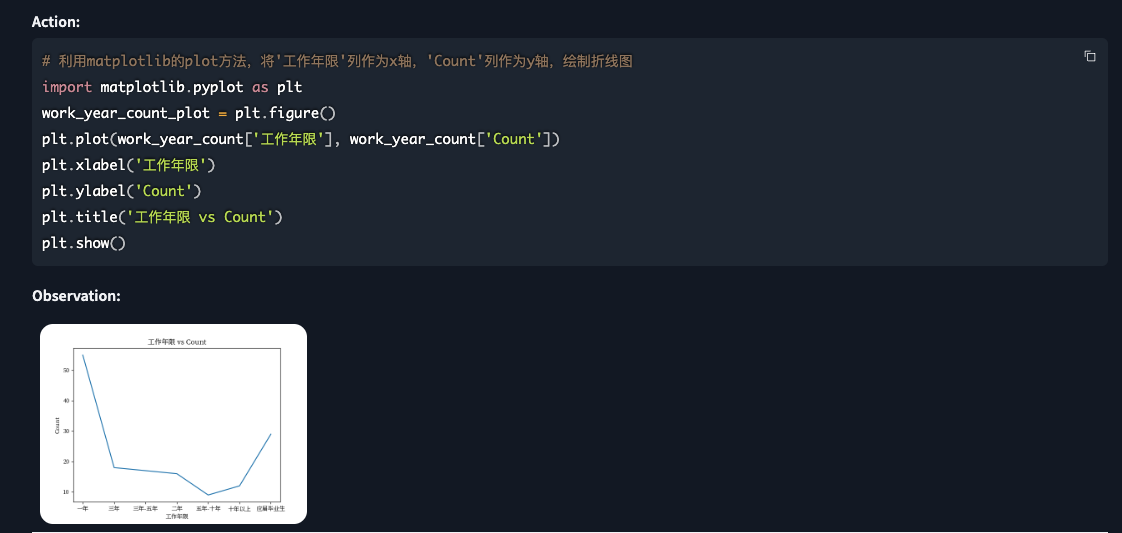
|
| 维度 |
我自己分析结果 |
| 代码 |
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 读取CSV文件
data = pd.read_csv('users.csv')
# 提取"工作年限"列数据
work_experience_data = data['工作年限']
# 统计不同工作年限的人数
work_experience_counts = work_experience_data.value_counts().sort_index()
# 自定义字体设置
font_path = 'tangxianbinsong.ttf'
custom_font = fm.FontProperties(fname=font_path)
# 绘制折线图
plt.plot(work_experience_counts.index, work_experience_counts.values)
print(work_experience_counts.index)
plt.xlabel('工作年限', fontproperties=custom_font)
plt.ylabel('人数', fontproperties=custom_font)
plt.title('不同工作年限的人数分布', fontproperties=custom_font)
plt.show()
|
| 解析 |
- 使用 pandas 读取了名为 'users.csv' 的 CSV 文件中的数据,并提取了其中的 "工作年限" 列数据。然后,通过 value_counts() 函数统计了不同工作年限的人数,并对结果进行了按索引排序。
- 创建了一个具有自定义字体属性的 FontProperties 对象 custom_font。
- 在绘制折线图时,使用 plt.plot() 函数绘制了不同工作年限的人数分布,然后通过 plt.xlabel()、plt.ylabel() 和 plt.title() 函数分别设置了 x 轴标签、y 轴标签和图标题的字体属性为自定义字体。
- 调用 plt.show() 函数显示了绘制好的折线图。
|
7.1.3. 工作年限对比分析结果
| TableAgent分析结果 |
我自己分析结果 |
| 1. 从图中可以看出,工作年限与用户数量的关系并不是线性的,也就是说,工作年限越短,用户数量越多。
- 这可能是因为刚毕业或者刚刚工作的年轻人更容易找到适合自己的工作,因此我们看到的工作年限与用户数量的关系是这样的。而工作年限越长的用户,他们的经验和技能已经相对较多,因此在寻找工作时,他们对行业的了解可能相对较少,因此找到合适的工作的可能性较小。
- 总的来说,我们的数据显示,工作年限较短的用户数量较多,而工作年限较长的用户数量较少。这可能是因为刚毕业或者刚刚工作的年轻人更容易找到适合自己的工作,而工作年限较长的用户在寻找工作时,对行业的了解可能相对较少,因此找到合适的工作的可能性较小。
|
- 数据概览:
- 数据中包含了不同工作年限的人数统计。
- 总共有7个不同的工作年限分类。
- 最少的人数是9人,对应于工作年限为"五年-十年"。
- 最多的人数是55人,对应于工作年限为"一年"。
- 工作年限与人数的分布:
- 数据中显示了不同工作年限下的人数分布。
- "一年"和"应届毕业生"是最高人数的工作年限分类,分别为55人和29人。
- "五年-十年"是最低人数的工作年限分类,只有9人。
- 工作年限与人数的趋势:
- 通过观察数据,我们无法直接得出工作年限与人数之间的趋势关系,因为数据没有提供具体的时间范围。
- 但我们可以看到,在工作年限较短的范围内(一年、三年等),人数相对较多,而在工作年限较长的范围内(五年-十年、十年以上),人数相对较少。
在这个数据集中,大部分人的工作年限较短,而工作年限较长的人数相对较少。这可能反映了该数据集中的职业发展情况,但由于缺乏具体时间范围的信息,我们无法进一步分析工作年限与人数之间的趋势关系。 |
8. 其他方向数据分析
对于数据的挖掘是多方向, 多个方向进行数据挖掘才可以获取到数据背后的一些信息,从而帮助我们进行决策, 下面我提供几个方向 大家可以尝试的TableAgent 上进行分析一下哦 !!
四、总结
ableAgent 可以免费体验,注册后可以免费使用5次,次数使用完了,可以认证申请增加次数(每天15次)
【TableAgent公测地址】 数据测试的方向提供给大家了, 有兴趣的话赶紧去体验一下吧 !!
通过上面的测试,我们很轻易的便发现了 , TableAgent 给出的可视化数据图 与我们自己生成的可以说是一个样的, 但是TableAgent更加的快速, 给出的数据分析的内容也是很有参考价值, 同时也给出了数据生成过程的思路分析, 很nice.
正如九章云极DataCanvas公司主任架构师杨健所说:
当前市场呈现出丰富多样的生成式AI形态,拨开一众表面浮夸的形态和场景,TableAgent团队发现,“数据分析”是大模型和具体业务融合的更深一步,是最能为用户产生直接商业价值的核心领域,也将是企业真正需要沉淀的、最有业务价值的领域。与九章云极DataCanvas公司 “一切为了应用”的AI基础软件研发目标一致,TableAgent聚焦数据分析,作为Data+AI的产物,将在未来大模型主导的AI时代为企业转换巨大的业务价值,迎来难以估量的蓝海机遇。