文章目录
前言
在数字化时代,数据分析的重要性已经变得无处不在,就像我们生活中必不可少的空气一样。它是数字化管理和智能决策的基础,但同时也是一项高度专业化的工作。对于那些只会使用Excel的人来说,面对描述性分析、诊断性分析和预测性分析可能会感到相当头疼。然而,九章云极DataCanvas公司自主研发的TableAgent数据分析智能体的出现,让大型模型对个人生产力的提升达到了新的高度。只需要知道如何提问,你就能成为一个顶级的数据分析师,深入洞察数据的奥秘。
2023年7月9日,OpenAI发布了一款震撼全球的Code Interpreter插件,让“人人都是数据分析师”的梦想成为现实。然而,早在6月28日,九章云极DataCanvas公司就已经提前发布了TableGPT。现在,Code Interpreter已经更名为Advanced Data Analysis,而TableGPT也进行了一系列的重大升级,以TableAgent的新名字重新上线,面向全社会开放公测。
一、TableAgent介绍
TableAgent 数据分析智能体
TableAgent是一款功能强大的企业级数据分析智能体,可以实现私有化部署。它具备出色的意图理解能力、分析建模能力和深刻的洞察力。通过充分理解用户的意图,TableAgent能够自主地运用统计科学、机器学习、因果推断等高级建模技术,从海量数据中挖掘出有价值的信息。这不仅为用户提供了精准的分析观点,还能为他们制定决策提供深刻的见解。此外,凭借自有的大型模型和自主研发的T+底层体系,TableAgent能够灵活适应各行各业以及不同专业领域的需求,实现在特定领域内个性化数据分析场景下的专业化微调。
TableAgent现已开放公测 : 点击即可访问

融合创新应用的新成果
九章云极DataCanvas公司自主研发的Alaya九章元识大模型,为TableAgent提供了关键性的技术支持。通过在Alaya基础大模型上进行微调,衍生出了Alaya-ZeroX模型组,这些模型各具特色,能够协同完成复杂的分析任务。不同规模的模型参数确保了生成质量和推理性能的同时满足。
此次TableAgent的发布还带来了一项重要功能,即专业化微调。由于不同行业和企业在数据分析领域有着各自独特的语言背景和分析模型需求,通用的分析工具往往难以满足这些专业化要求。而TableAgent则能为企业提供这种专业化的微调服务。
为了实现这一目标,TableAgent特别设计了一套名为T+(Table Family)的系统。该系统能够高效地进行定制化的微调工作,并且具备自我迭代的能力。这一系统性的支持使得数据分析各个环节的升级更加高效,用户在无需感知的情况下就能享受到不断升级的数据分析体验。
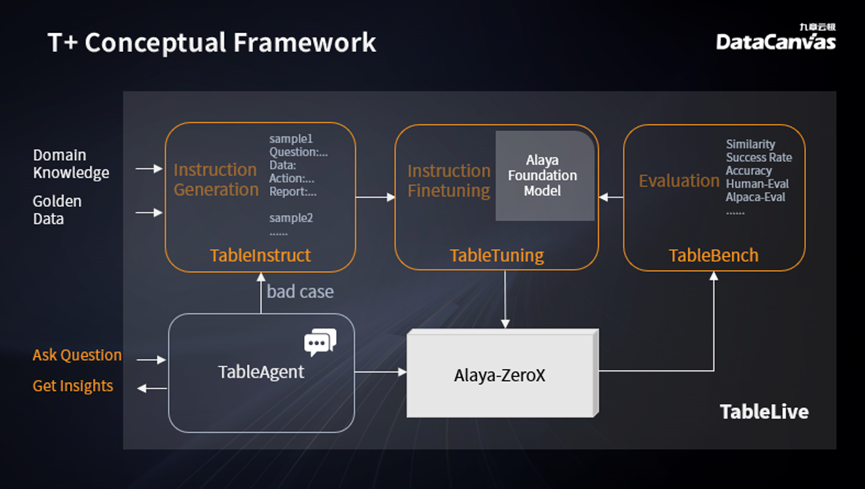
Table Family

二、注册TableAgent
访问TableAgent
点击链接 体验TableAgent, 如下图所示,点击立刻体验

注册
输入手机号``验证码 登录 TableAgent
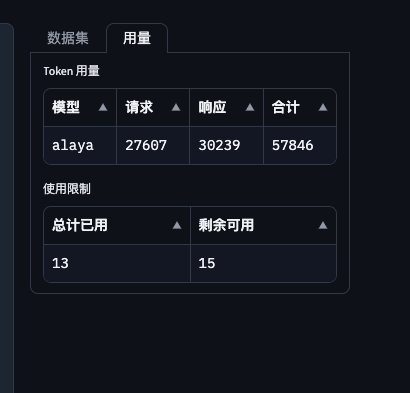
用量
注册后可以免费使用5次,次数使用完了,可以认证申请增加次数(每天15次)
三、 体验TableAgent
样例数据集体验
TableAgent 提供了
样例数据集可以使用样例数据集快速上手 TableAgent
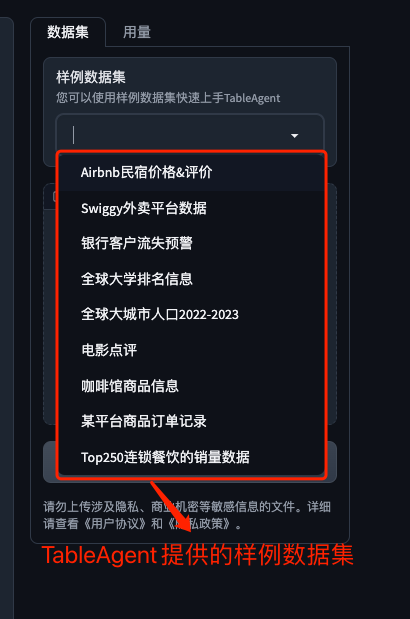
接下来我们使用TableAgent提供的样例数据集进行数据分析的体验
选择样例数据集
我们选择
全球大学排名信息的数据集
当数据集加载成功之后, 左侧的对话框内返回了关于该数据集的信息, 并且提供了问题的可选项以供用户参考, 同时在详情的折叠面板中有这关于数据集的csv 的数据展示 ,如下图所示
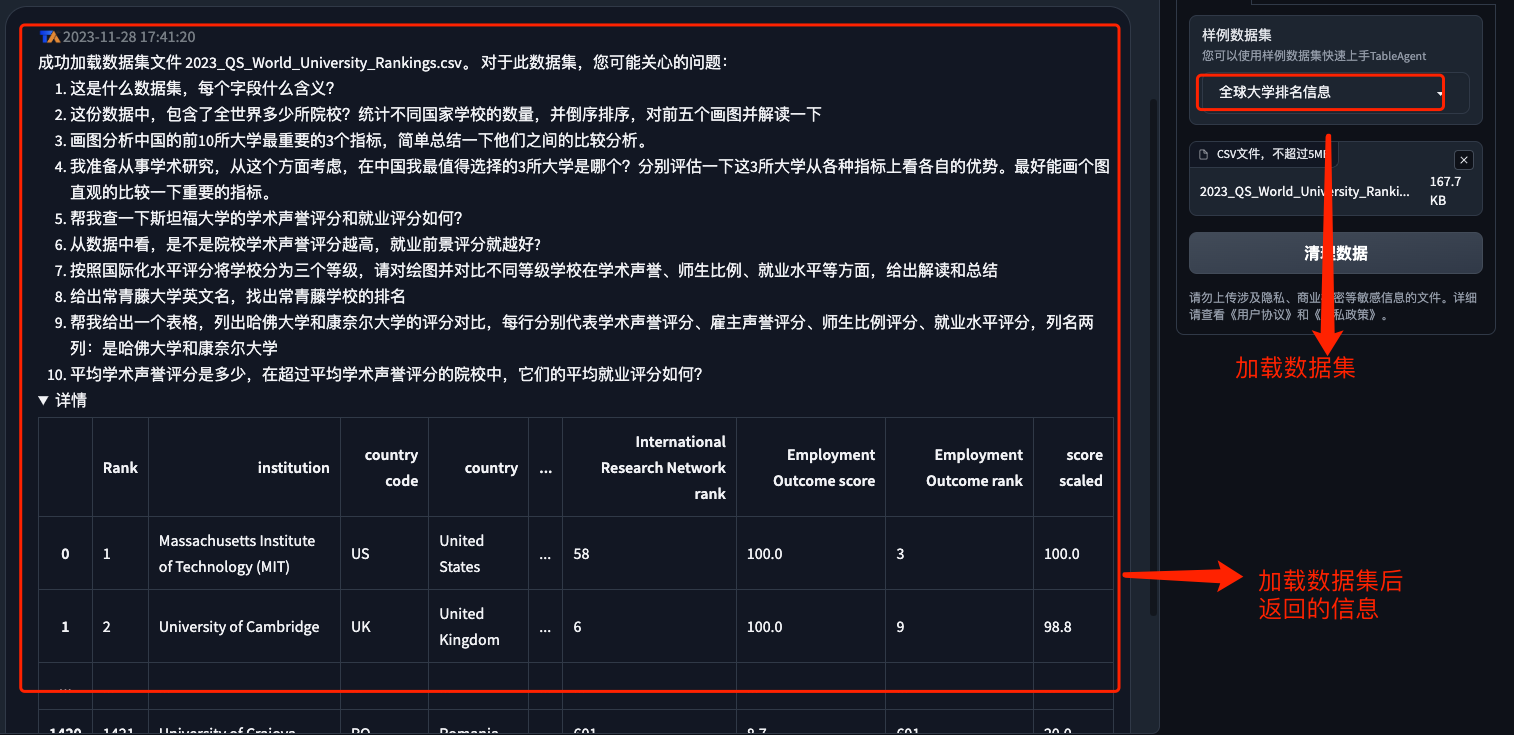
样例数据集进行数据分析
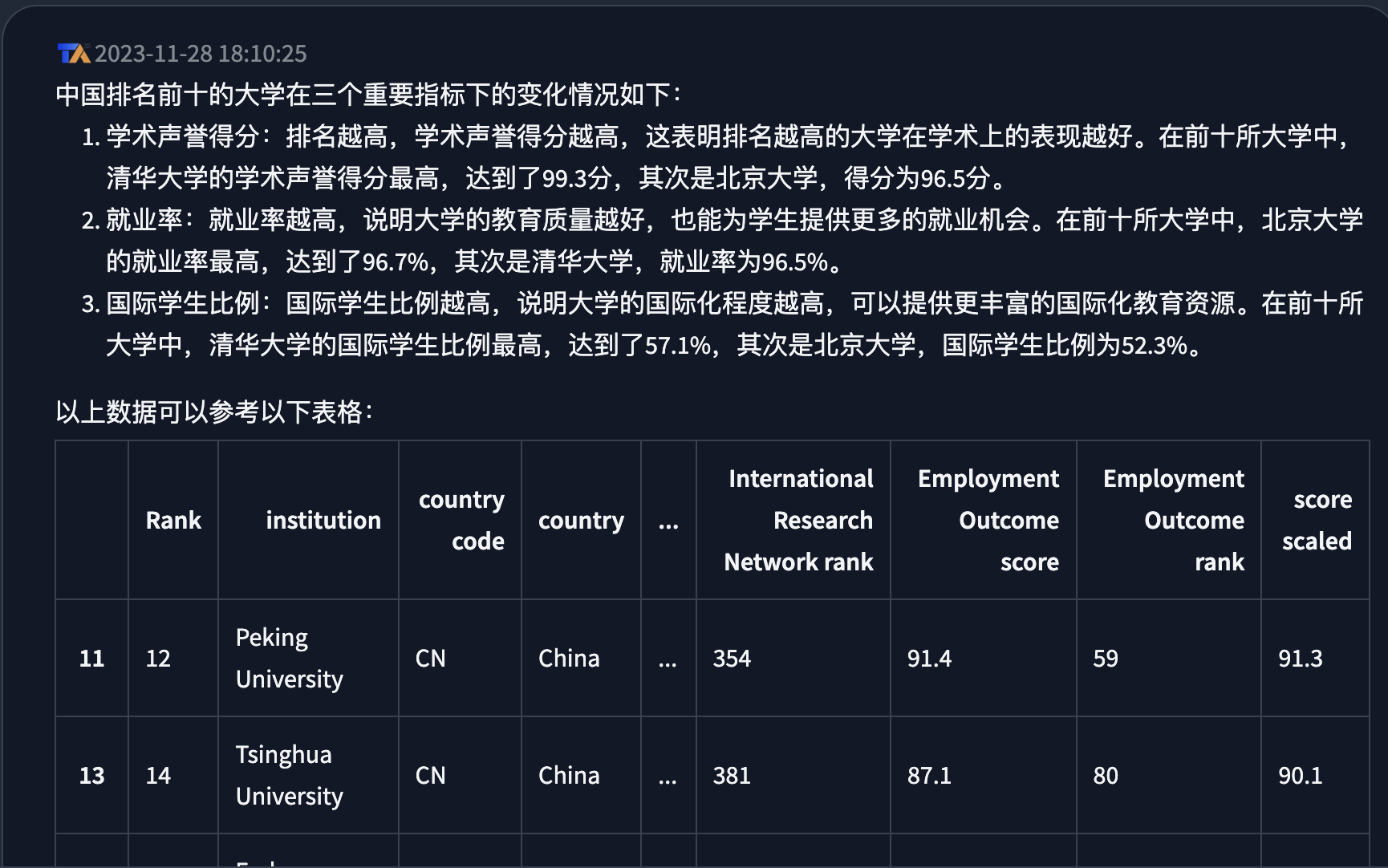
**提问:**画图分析中国的前10所大学最重要的3个指标,简单总结一下他们之间的比较分析。
数据图
效果图
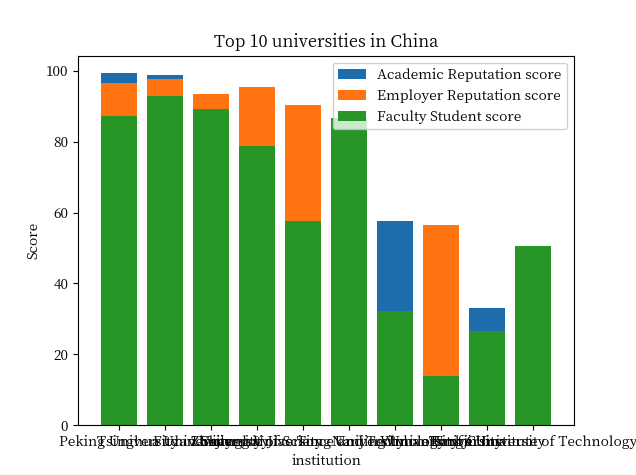

分析:
- 根据我给出的问题,并没有指定数据图的格式, 这里TableAgent 自动选择的是柱状图进行展示, 可以说是比较人性化的, 更加直观
- x轴数据明显重叠了, 这一点还是有待优化的。
- 再给出数据图表的同时,也给出了数据分析的内容,这一点简直绝了。
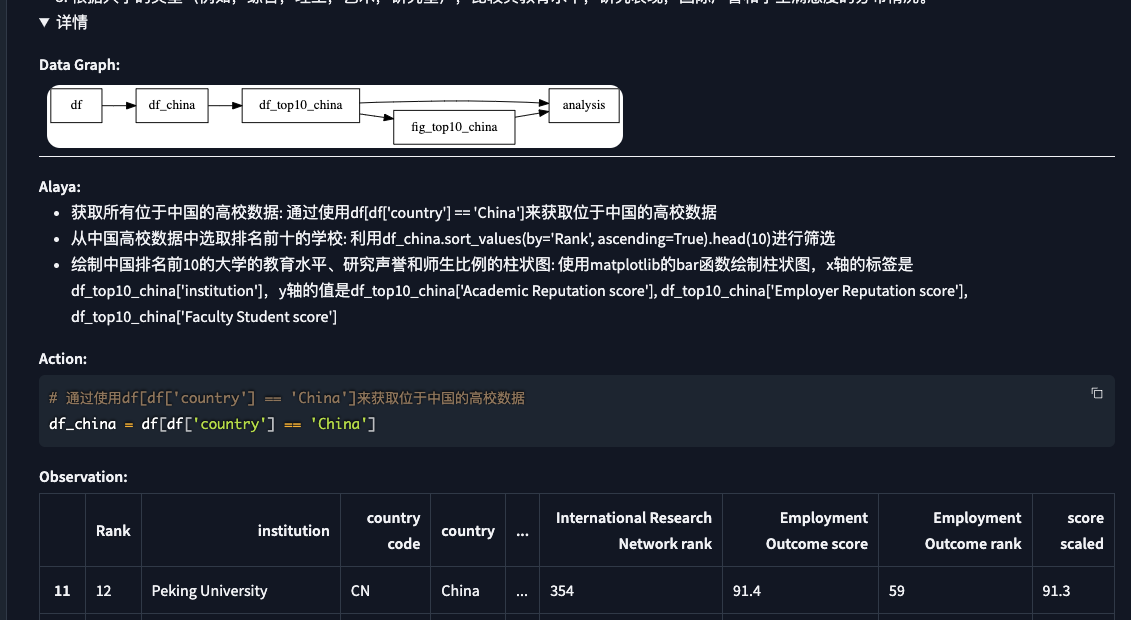
- 在详情的折叠内容中, 也会给出分析的步骤,以及代码思路, 这一点对于研发人员也是非常的友好
样例数据集进行数据分析规定图表格式
通过1.2 的问题我们可以看到, 我们并没有指定图表格式, TableAgent 给我们择优选择了柱状图, 接下来我们规定一下输出的图表格式, TableAgent 是否可以理解并执行呢?
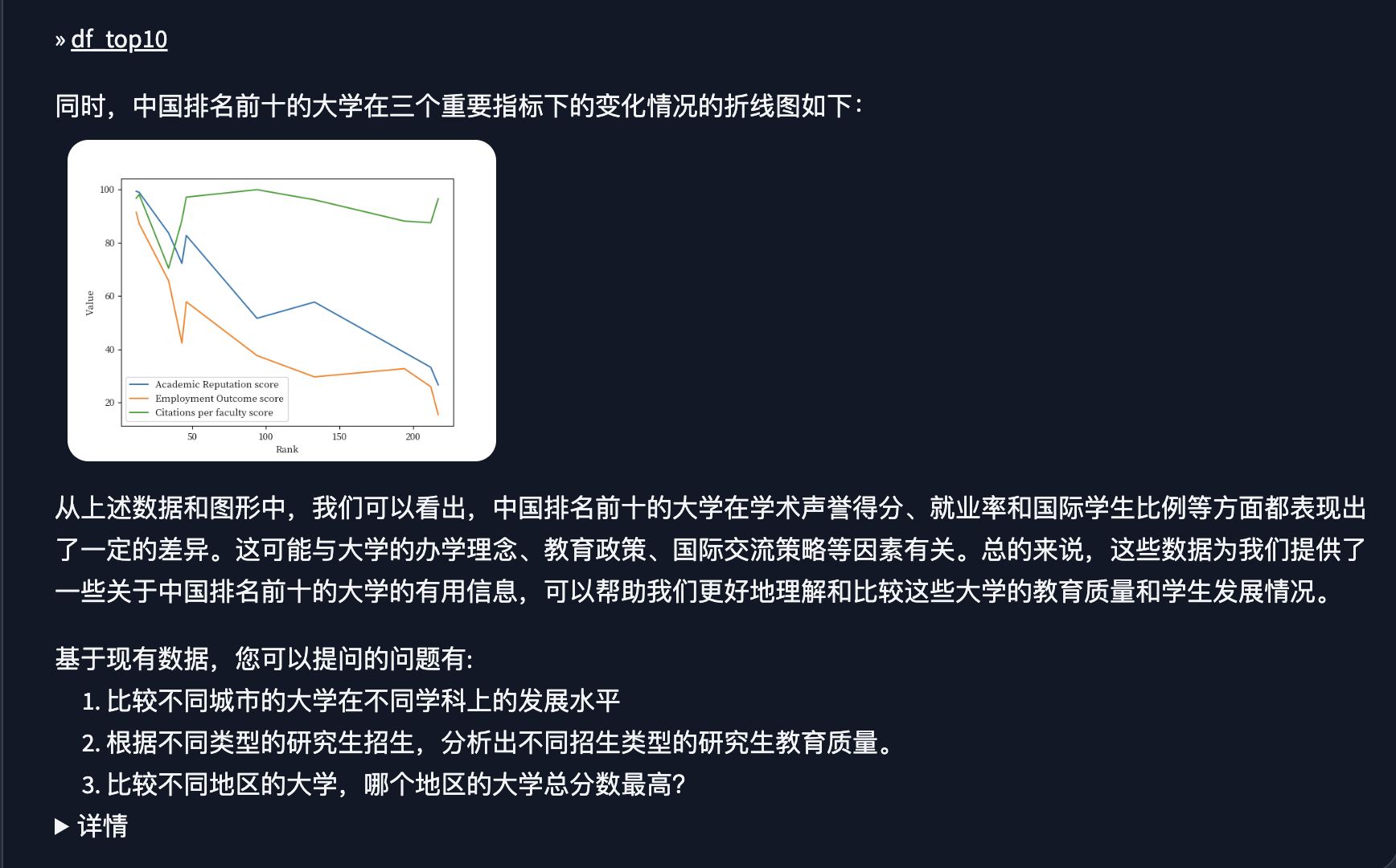
提问: 通过折线图分析中国的前10所大学最重要的3个指标,简单总结一下他们之间的比较分析。
数据图
效果图
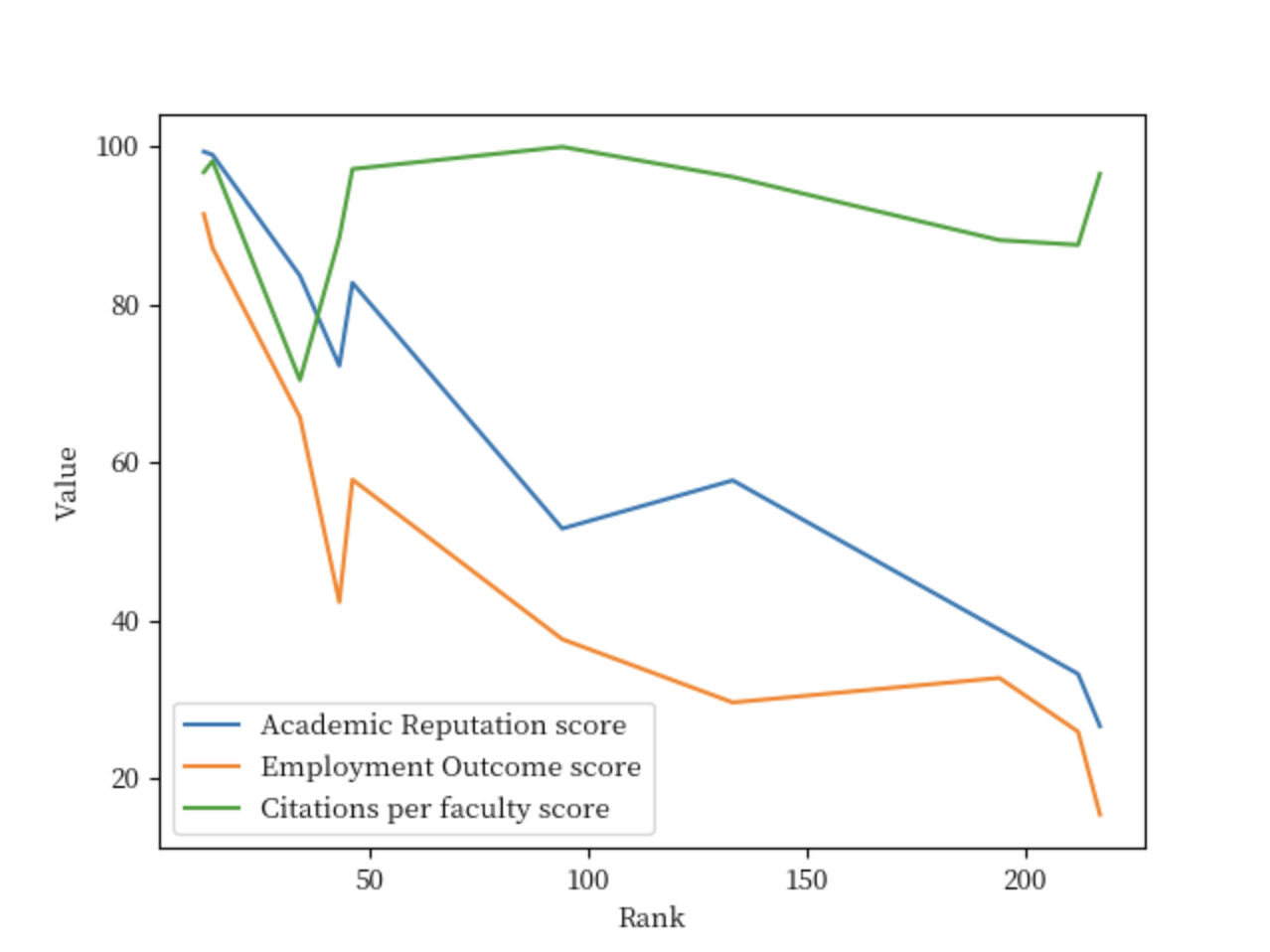
分析:
此时我让TableAgent 用折线图进行数据分析, 通过效果图我们发现, TableAgent 返回的数据分析图与我们的预期相符,同时TableAgent 也给了我们相应的分析过程及结果,同时也给出了接下数据分析的方向。
总结:
针对柱状图和折线图以及TableAgent 给出的分析结论我们可以得到综合的结论
- 教育水平、研究声誉和师生比例:
- 从柱状图中可以观察到,北京大学和清华大学在教育水平、研究声誉和师生比例等方面处于领先地位,而其他大学如中国科学技术大学、复旦大学和上海交通大学也表现出色。
- 数据表中显示了这些大学在不同指标下的具体得分和排名,进一步印证了柱状图的结果。
- 学术声誉得分、就业率和国际学生比例:
- 通过折线图和数据表,可以发现清华大学在学术声誉得分和国际学生比例方面表现较好,而北京大学在就业率上处于较高水平。
自定义数据集体验
准备数据
如下链接为我们准备的csv数据集
数据概览
10 个类别(书籍、平板、手机、水果、洗发水、热水器、蒙牛、衣服、计算机、酒店),共 6 万多条评论数据,正、负向评论各约 3 万条
数据分析方向
情感/观点/评论 倾向性分析
导入数据
如下图所示, 我们清楚原有数据集, 然后导入我们准备好的数据集,进行数据分析。
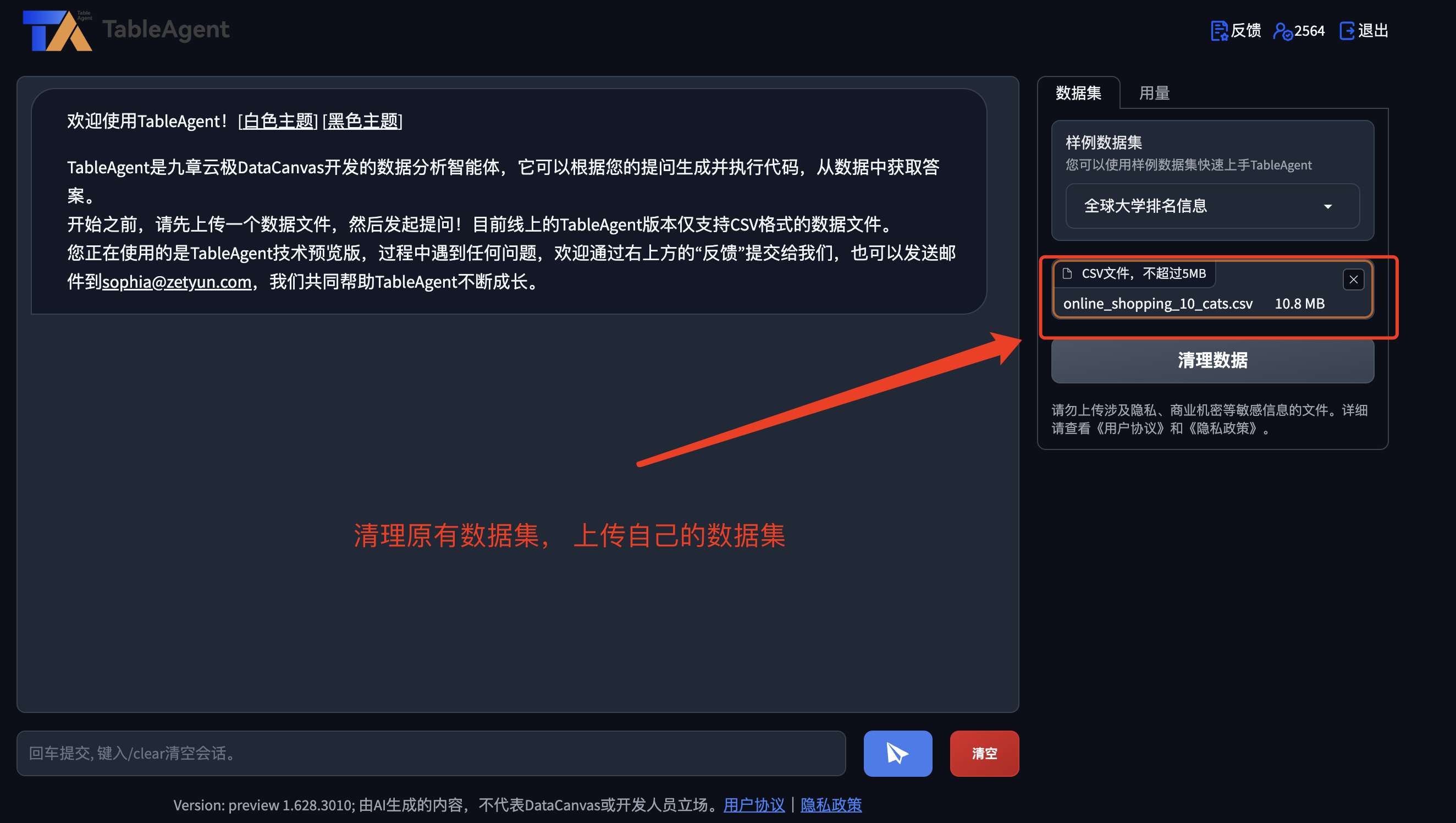
注意:由于我们准备的数据是10Mb , 但是TableAgent目前允许的最大的数据量是不可以超出5Mb的,因此我们需要对数据进行裁剪,使之在5Mb 以内。
删除"cat"列中包含"洗发水"、“热水器”、“蒙牛”、“衣服”、"计算机"和"酒店"的行
import pandas as pd
# 读入CSV文件到DataFrame中
df = pd.read_csv('online_shopping_10_cats.csv')
# 删除"cat"列中包含"衣服"、"计算机"和"酒店"的行
df = df[~df['cat'].isin(['洗发水', '热水器', '蒙牛', '衣服', '计算机', '酒店'])]
# 将结果保存到新的CSV文件中
df.to_csv('new_data.csv', index=False)
如图所示清理过后数据集大小正好符合要求, 直接导入即可
简单数据分析
首先我们进行简单的数据分析,
问题如下: 对书籍、平板、手机、水果、洗发水、热水器、蒙牛 这几个类别进行用户倾向性分析,数据集中cat代表类别,label为0代表负面评价为1为正向评价,review代表用户的评价
数据图:
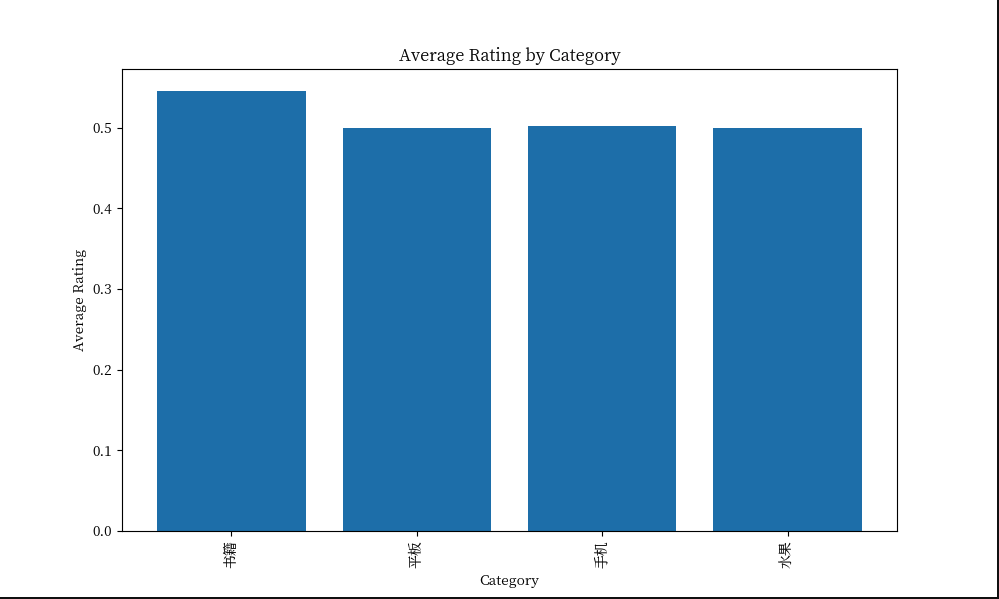

分析:对于我们自己的数据集TableAgent不仅给出了图表分析,同时也给出了详细的分析结果,返回结果符合我们的预期
复杂数据分析
接下来我们将问题复杂化,看下TableAgent 是否依旧可以给出完美的分析结果
问题如下: : 对书籍、平板、手机、水果、洗发水、热水器、蒙牛 这几个类别进行用户倾向性分析,数据集中cat代表类别,label为0代表负面评价为1为正向评价,review代表用户的评价,分析数据集中 review列用户的正向评论和负向评论, 并将绘制成旭日图和散点图
数据图:
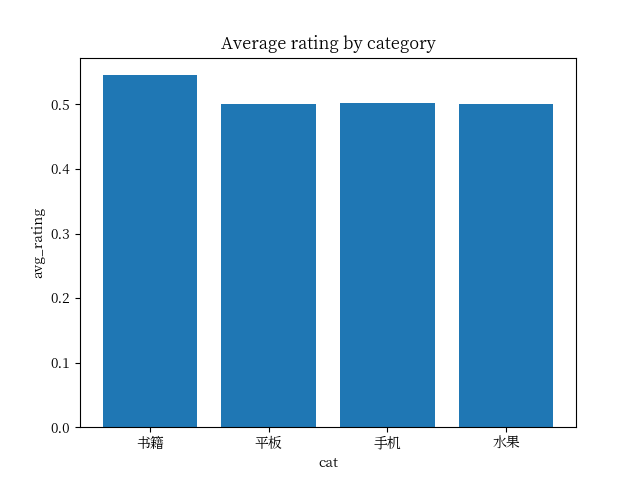
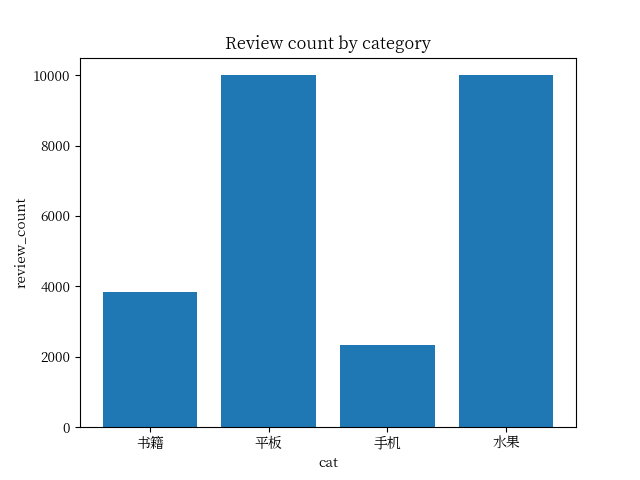

分析:从结果来看 并不符合我们的预期, 我们计划生成的是旭日图和散点图 , 但是实际上给出的结果却是柱状图, 当然这里不排除我们数据集本身的原因
四、常见问题
通过TableAgent提供的样例数据集和我么自己提供的数据集来看,存在以下问题:
- 用户如果导入的数据集低于5MB时, 需要自己对数据进行处理,删除多余的数据,这点显然不是很友好
- 过于复杂的图形(可能是数据集的原因), 理解的并不是很友好
- 给出的提问方向或者示例,有时并不符合数据集的内容
五、总结
TableAgent其实是九章云极之前发布的TableGPT升级后的产品形态,通过本次的体验能明显感觉到在性能方面有显著提升,以自然语言对话的方式实现结构化数据的分析工作,这对我这种数据建模的小白来说蛮友好的。它的另一个大亮点是支持企业私有化部署,做ToB企业的都知道现在企业对数据安全是多么地看重。不得不说给个大大的赞哦!!!