Deeplab是图像分割领域非常强大的模型,在前面的博文中我们也进行过很多相应项目的开发实践,感兴趣的话可以自行移步阅读即可:
《基于DeepLabV3Plus实现质检划痕图像分割识别系统》
《基于DeepLabV3Plus实现无人机航拍目标分割识别系统》
《python基于DeepLabv3+开发构建河道分割识别系统》
《python基于DeeplabV3Plus开发构建裂缝分割识别系统,并实现裂缝宽度计算测量》
《AI助力隧道等洞体类场景下水泥基建缺陷检测,基于DeeplabV3Plus开发构建洞体场景下壁体建筑缺陷分割系统》
本文的核心目的就是想要基于DeepLabV3Plus来开发构建手机屏幕表面缺陷图像智能分割识别系统,助力工业生产流程上的智能化,首先看下实例效果:

在图像分割领域中有不少优秀出色的网络,DeepLab系列就是其中非常经典的分支之一,在之前的很多项目中陆续都已经有接触到了,在处理图像分割中表现出色。
DeepLabV3Plus是一种用于语义分割任务的深度学习模型,它是DeepLab系列模型的一种改进版本。下面详细解释DeepLabV3Plus的原理:
引入空洞卷积(Dilated Convolution):DeepLabV3Plus利用空洞卷积来扩大感受野,以更好地捕捉图像中的上下文信息。传统的卷积操作只关注局部区域,而空洞卷积通过在卷积核中引入间隔(或称为膨胀率),使得卷积核能够跳过一些像素点,从而扩大感受野。
多尺度金字塔池化(Multi-scale Atrous Spatial Pyramid Pooling, ASPP):DeepLabV3Plus使用ASPP模块来处理不同尺度的信息。ASPP模块使用多个并行的空洞卷积分支,每个分支具有不同的膨胀率,以捕捉来自不同感受野的特征。最后,将这些特征进行汇总并进行融合,以生成更丰富的特征表示。
融合低级特征:为了结合低层次的细节特征,DeepLabV3Plus引入了一个编码器-解码器结构。在编码器部分,通过堆叠多个残差块和降采样操作,提取高层次的语义特征。然而,这会导致空间信息的丢失。因此,在解码器部分,使用反卷积(或上采样)操作来恢复特征图的分辨率,并与对应的低级特征进行融合。
融合注意力机制:为了进一步提升融合的效果,DeepLabV3Plus引入了注意力机制。该机制利用辅助监督信号和空间注意力模块,自适应地对不同的特征图进行加权融合。这样可以使网络更加关注重要的特征区域,提升语义分割的准确性。
DeepLabV3Plus通过引入空洞卷积、多尺度金字塔池化、融合低级特征和注意力机制等改进,提升了语义分割任务的性能。它能够准确地标记图像中每个像素的类别,从而在许多计算机视觉领域(如图像分割、自动驾驶等)中发挥着重要作用。
整体网络结构图如下所示:

接下来看下数据集:



共包含:油污、划痕和斑点这三种常见的手机屏幕缺损类型。
DeepLabV3Plus核心实现如下:
import tensorflow as tf
from keras import backend as K
from keras.layers import (
Activation,
BatchNormalization,
Concatenate,
Conv2D,
DepthwiseConv2D,
Dropout,
GlobalAveragePooling2D,
Input,
Lambda,
Softmax,
ZeroPadding2D,
)
from keras.models import Model
from modules.mobilenet import mobilenetV2
from modules.Xception import Xception
def SepConv_BN(
x,
filters,
prefix,
stride=1,
kernel_size=3,
rate=1,
depth_activation=False,
epsilon=1e-3,
):
if stride == 1:
depth_padding = "same"
else:
kernel_size_effective = kernel_size + (kernel_size - 1) * (rate - 1)
pad_total = kernel_size_effective - 1
pad_beg = pad_total // 2
pad_end = pad_total - pad_beg
x = ZeroPadding2D((pad_beg, pad_end))(x)
depth_padding = "valid"
if not depth_activation:
x = Activation("relu")(x)
x = DepthwiseConv2D(
(kernel_size, kernel_size),
strides=(stride, stride),
dilation_rate=(rate, rate),
padding=depth_padding,
use_bias=False,
)(x)
x = BatchNormalization(epsilon=epsilon)(x)
if depth_activation:
x = Activation("relu")(x)
x = Conv2D(
filters, (1, 1), padding="same", use_bias=False
)(x)
x = BatchNormalization(epsilon=epsilon)(x)
if depth_activation:
x = Activation("relu")(x)
return x
def Deeplabv3(
input_shape, num_classes, alpha=1.0, backbone="mobilenet", downsample_factor=16
):
img_input = Input(shape=input_shape)
x, atrous_rates, skip1 = MobileNet(
img_input, alpha, downsample_factor=downsample_factor
)
size_before = tf.keras.backend.int_shape(x)
b0 = Conv2D(256, (1, 1), padding="same", use_bias=False)(x)
b0 = BatchNormalization(epsilon=1e-5)(b0)
b0 = Activation("relu")(b0)
b1 = SepConv_BN(
x, 256, "A!", rate=atrous_rates[0], depth_activation=True, epsilon=1e-5
)
b2 = SepConv_BN(
x, 256, "A2", rate=atrous_rates[1], depth_activation=True, epsilon=1e-5
)
b3 = SepConv_BN(
x, 256, "A3", rate=atrous_rates[2], depth_activation=True, epsilon=1e-5
)
b4 = GlobalAveragePooling2D()(x)
b4 = Lambda(lambda x: K.expand_dims(x, 1))(b4)
b4 = Lambda(lambda x: K.expand_dims(x, 1))(b4)
b4 = Conv2D(256, (1, 1), padding="same", use_bias=False)(b4)
b4 = BatchNormalization(epsilon=1e-5)(b4)
b4 = Activation("relu")(b4)
b4 = Lambda(
lambda x: tf.image.resize_images(x, size_before[1:3], align_corners=True)
)(b4)
x = Concatenate()([b4, b0, b1, b2, b3])
x = Conv2D(256, (1, 1), padding="same", use_bias=False)(x)
x = BatchNormalization(epsilon=1e-5)(x)
x = Activation("relu")(x)
x = Dropout(0.1)(x)
skip_size = tf.keras.backend.int_shape(skip1)
x = Lambda(
lambda xx: tf.image.resize_images(xx, skip_size[1:3], align_corners=True)
)(x)
dec_skip1 = Conv2D(
48, (1, 1), padding="same", use_bias=False
)(skip1)
dec_skip1 = BatchNormalization(epsilon=1e-5)(
dec_skip1
)
dec_skip1 = Activation(tf.nn.relu)(dec_skip1)
x = Concatenate()([x, dec_skip1])
x = SepConv_BN(x, 256, "DC0", depth_activation=True, epsilon=1e-5)
x = SepConv_BN(x, 256, "DC1", depth_activation=True, epsilon=1e-5)
size_before3 = tf.keras.backend.int_shape(img_input)
x = Conv2D(num_classes, (1, 1), padding="same")(x)
x = Lambda(
lambda xx: tf.image.resize_images(xx, size_before3[1:3], align_corners=True)
)(x)
x = Softmax()(x)
model = Model(img_input, x)
return model
基于轻量级的MobileNet作为骨干网络来实现特征的提取,即使是在算力较弱的设备下也可以完成训练。在自己的项目中也可以直接整合集成使用。
训练完成后对整体进行可视化,核心实现如下:
from matplotlib import pyplot as plt
with open("train.txt") as f:
train_list = [float(one) for one in f.readlines() if one.strip()]
with open("val.txt") as f:
val_list = [float(one) for one in f.readlines() if one.strip()]
print("train_list_length: ", len(train_list))
print("val_list_length: ", len(val_list))
plt.clf()
plt.figure(figsize=(8, 6))
plt.plot(train_list, label="Train Loss Cruve", c="g")
plt.plot(val_list, label="Val Loss Cruve", c="b")
plt.title("Model Loss Cruve")
plt.savefig("loss.png")结果如下所示:
这里分为两个阶段进行训练,首先是冷冻训练,主要是基于预训练权重来进行训练,如下:
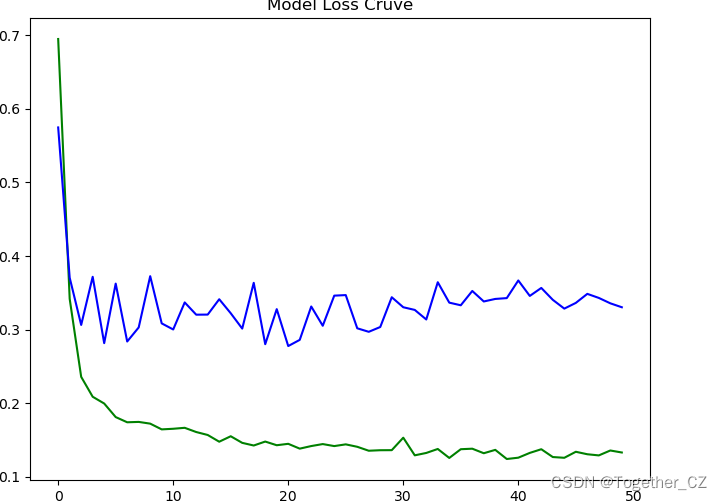
这一阶段大部分参数被冻结,模型的整体损失比较高,完成预热之后解冻模型参数开启全量训练,如下所示:

这里为了方便使用模型,开发了专用的可视化系统界面,实例推理计算效果如下所示:
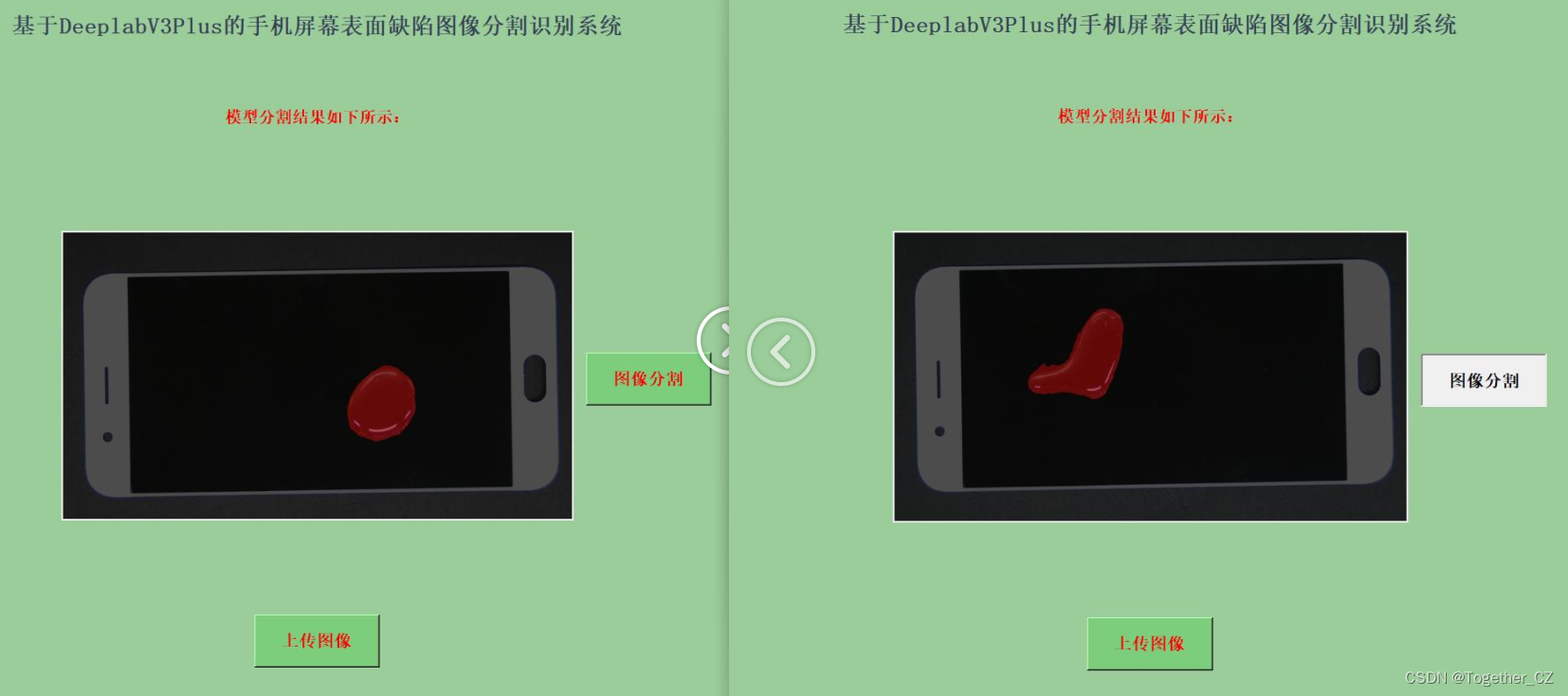
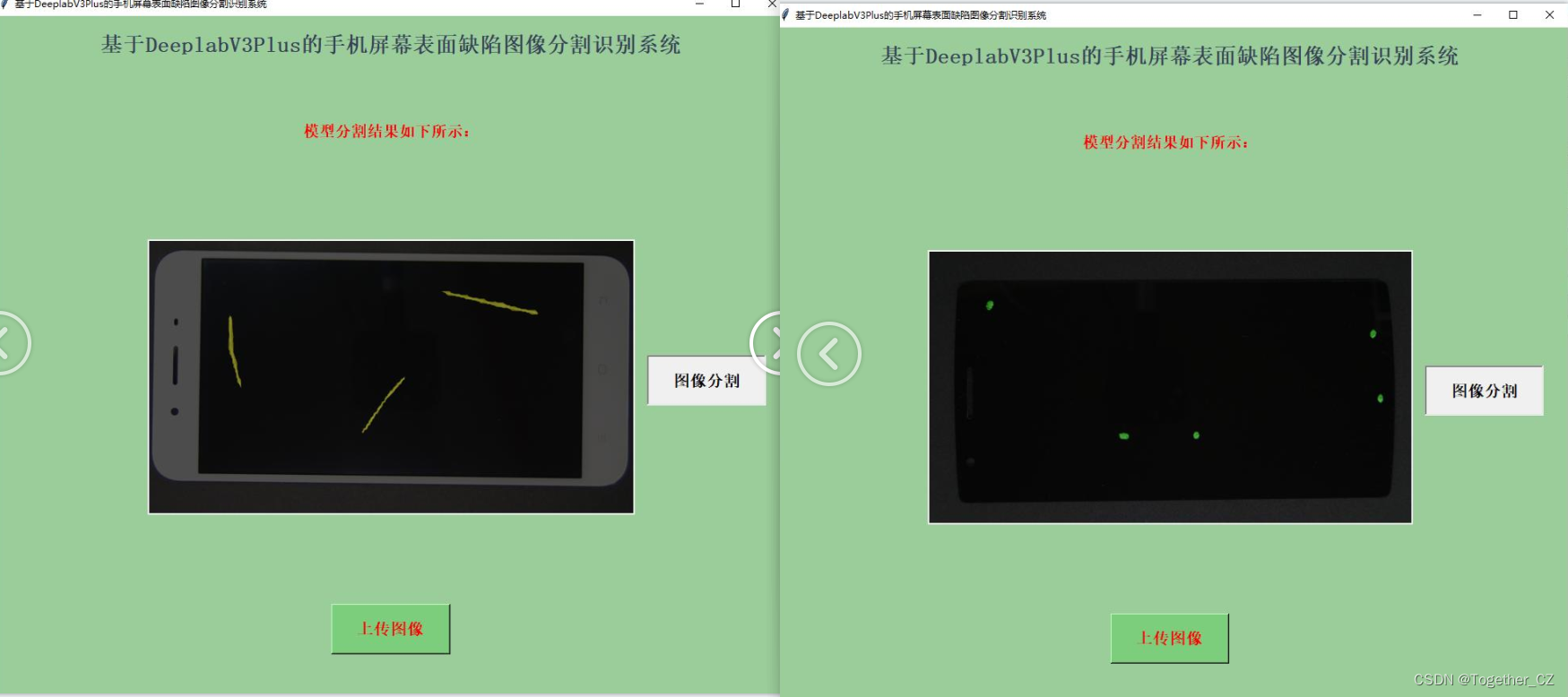
直观来看效果还是不错的,有兴趣的话都是可以自己动手实践一下的。