
摘要
We present Text2Room†, a method for generating roomscale textured 3D meshes from a given text prompt as input. To this end, we leverage pre-trained 2D text-to-image models to synthesize a sequence of images from different poses. In order to lift these outputs into a consistent 3D scene representation, we combine monocular depth estimation with a text-conditioned inpainting model. The core idea of our approach is a tailored viewpoint selection such that the content of each image can be fused into a seamless, textured 3D mesh. More specifically, we propose a continuous alignment strategy that iteratively fuses scene frames with the existing geometry to create a seamless mesh. Unlike existing works that focus on generating single objects [56, 41] or zoom-out trajectories [18] from text, our method generates complete 3D scenes with multiple objects and explicit 3D geometry. We evaluate our approach using qualitative and quantitative metrics, demonstrating it as the first method to generate room-scale 3D geometry with compelling textures from only text as input.
我们介绍了 Text2Room†,这是一种从给定文本提示作为输入生成房间尺度纹理 3D 网格的方法。为此,我们利用预训练的 2D 文本到图像模型来合成一系列来自不同姿势的图像。为了将这些输出提升为一致的 3D 场景表示,我们将单眼深度估计与文本条件修复模型相结合。我们方法的核心思想是定制视点选择,这样每张图像的内容都可以融合到一个无缝的、有纹理的 3D 网格中。更具体地说,我们提出了一种连续对齐策略,该策略将场景帧与现有几何体迭代融合以创建无缝网格。与专注于从文本生成单个对象 [56、41] 或缩小轨迹 [18] 的现有作品不同,我们的方法生成具有多个对象和显式 3D 几何的完整 3D 场景。我们使用定性和定量指标评估我们的方法,证明它是第一种仅从文本作为输入生成具有引人注目的纹理的房间尺度 3D 几何图形的方法。
方法
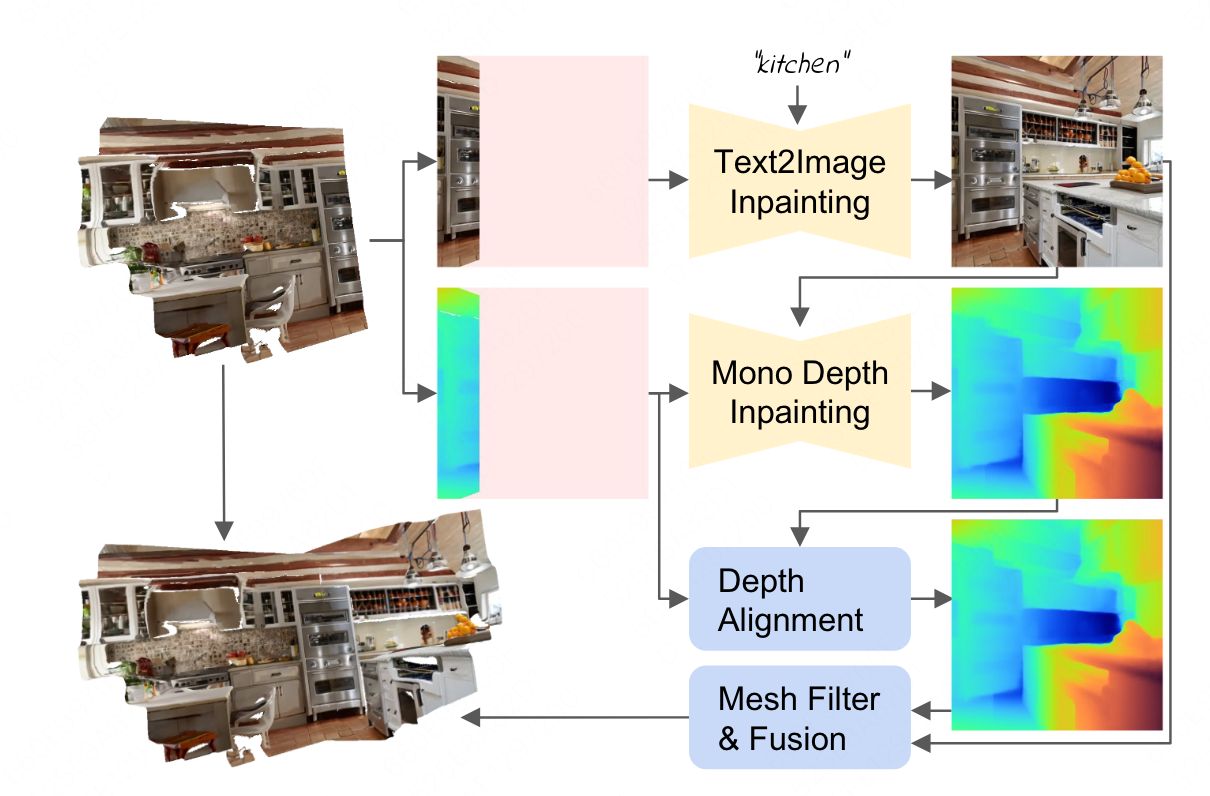
- 提出了两阶段的合适视角选择方案,首先生成场景的布局,然后将场景的空洞部分补全.采用迭代的场景生成更新mesh,每次在不同视角调用2D文本到图像的生成模型.为了保证新生成的图像的几何和已有的几何一致,采用了深度对齐.
迭代3D场景生成
- 使用mesh作为几何的表征
KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at position 16: \begin{array} \̲m̲a̲t̲h̲c̲a̲l̲{M}=(\mathcal{V… - 其中 M \mathcal{M} M 是mesh, V \mathcal{V} V是所有顶点, C \mathcal{C} C是所有顶点颜色, S \mathcal{S} S是所有的面元,整个mesh是迭代生成的
- 算法的输入是一些text prompts { P t } t = 1 T \left\{P_t\right\}_{t=1}^T {
Pt}t=1T以及这些prompts对应的pose
- 这个pose是一个预先设定的,不是一个像nerf里面精确的pose
- 在每个迭代中,首先会在指定pose根据已有的mesh光栅化生成RGB图片 I t I_t It深度图 d t d_t dt以及mask m t m_t mt,未生成的部分会被mask掉
I t , d t , m t = r ( M t , E t ) I_t, d_t, m_t=r\left(\mathcal{M}_t, E_t\right) It,dt,mt=r(Mt,Et) - 随后会使用图片加mask对RGB图片补全,注意这里会加入一个文本prompt
I ^ t = F t 2 i ( I t , m t , P t ) \hat{I}_t=\mathcal{F}_{t 2 i}\left(I_t, m_t, P_t\right) I^t=Ft2i(It,mt,Pt) - 随后对深度图也进行了补全,并且对其已有的深度
d ^ t = align ( F d , I t , d t , m t ) \hat{d}_t=\operatorname{align}\left(\mathcal{F}_d, I_t, d_t, m_t\right) d^t=align(Fd,It,dt,mt) - 有了新生成的RGBD就得到新的部分场景,将这部分场景和已有的场景进行融合得到增量更改的mesh
M t + 1 = fuse ( M t , I ^ t , d ^ t , m t , E t ) \mathcal{M}_{t+1}=\operatorname{fuse}\left(\mathcal{M}_t, \hat{I}_t, \hat{d}_t, m_t, E_t\right) Mt+1=fuse(Mt,I^t,d^t,mt,Et)
深度对齐
-
-
直接对一张新生成的图进行深度估计会导致新生成的深度旧部分的深度可能不对齐,导致3D几何产生不连续

-
为此,使用了两阶段的深度对齐.首先使用深度补全网络根据旧图已有的部分深度和生成的RGB进行深度的补全,然后使用最小二乘法估计缩放和平移
-
深度的平移和缩放的估计,使用最小二乘法最小化经过线性变化的预测视差和gt视差
min γ , β ∥ m ⊙ ( γ d ^ p + β − 1 d ) ∥ 2 \min _{\gamma, \beta}\left\|m \odot\left(\frac{\gamma}{\hat{d}_p}+\beta-\frac{1}{d}\right)\right\|^2 γ,βmin m⊙(d^pγ+β−d1) 2 -
最后使用的深度 d ^ \hat{d} d^是预测深度的线性变换
d ^ = γ ⋅ d ^ p + β \hat{d}=\gamma \cdot \hat{d}_p+\beta d^=γ⋅d^p+β -
最后在mask的边缘部分使用了 5 × 5 5\times 5 5×5的高斯滤波进行了平滑
mesh 融合
- 在迭代生成过程中会新生成RGB以及深度,要将新生成的部分与现有的场景进行融合
- 首先会通过反向投影将相机空间的点投到3D点云,这里只投影在mask中的区域(新生成的部分)
P t = { E t − 1 K − 1 ( u , v , d ^ t ( u , v ) ) T } u = 0 , v = 0 W , H \mathcal{P}_t=\left\{E_t^{-1} K^{-1}\left(u, v, \hat{d}_t(u, v)\right)^T\right\}_{u=0, v=0}^{W, H} Pt={ Et−1K−1(u,v,d^t(u,v))T}u=0,v=0W,H - E t E_t Et K K K分别是外参和内参
- 得到3D点后需要将3D点连成三角形面片,最朴素的方法是将像素平面最近的四个点(一个正方形的四个顶点)组成两个三角形
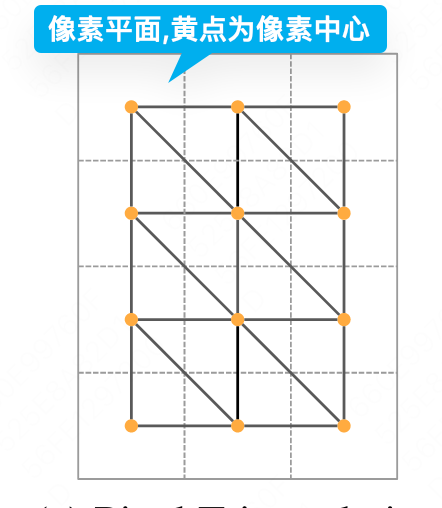
- 但是这样的做法会由于深度不准会导致部分三角形拉伸,超出几何范围,作者使用了两阶段的超出部分移除方法

- 首先会判断三角形的边是不是过长,如果任意一条边比阈值大就移除
- 然后会计算判断三角形面和相机射线的夹角,如果相机射线和表面越接近平行则投影面积越小,内积越小,则被筛去
S = { ( i 0 , i 1 , i 2 ) ∣ n T v > δ s n } \mathcal{S}=\left\{\left(i_0, i_1, i_2\right) \mid n^T v>\delta_{s n}\right\} S={ (i0,i1,i2)∣nTv>δsn}
两阶段视角选择
- 如果相机的pose选择过于随意会导致场景生成变差并且有拉伸和空洞,作者提出了两阶段视角选择方法,从最优的位置选取下一相机pose,逐步填充空的区域
- 在生成阶段,算法生成场景的主体,包括整体的布局以及家具.作者使用了预先设定轨迹,相当于一系列的关键帧,每个关键帧包括一个prompt和pose,通过不同方向的视角逐渐覆盖整个房间.
- 作者发现当每一个新pose和上一个pose只有部分小重叠的时候效果最好,在生成新场景的同时和现有场景还有一部分连接
- 作者选择以圆周运动生成下一个块的轨迹,大致以原点为中心
- 在天花板以及地板等不需要家具的地方生成只需要更改prompt,比如’floor’
- 在补全阶段需要处理生成过程中的空洞,解决方法是让相机看向空洞的地方进行生成
- 将场景离散化成三维体素,在每个体素里随机采样多个pose,丢弃和集合太近的pose,然后在每个场景里选择一个看到大块空洞区域的pose,在选择的pose里进行补全
- 最后进行泊松表面重建填补剩余的空洞,使便面更完整与平滑
实验
-
对比方法
- Pure ClipNeRF
- Outpainting
- Tex2Light
- Blockade
-
评价指标
- CLIP score(CS):计算图像和文本prompt的语义相似度,越高越好
- C L I P − S ( c , v ) = w ∗ max ( cos ( c , v ) , 0 ) \mathrm{CLIP}-\mathrm{S}(\mathbf{c}, \mathbf{v})=w * \max (\cos (\mathbf{c}, \mathbf{v}), 0) CLIP−S(c,v)=w∗max(cos(c,v),0)
- Inception score (IS):用于评价生成图像的真实性,包含多样性和区分性两个方面,越高越好
- Percentual quality (PQ): 用户实验评价的生成质量
- 3D Structure Completeness (3DS): 用户实验评价的结构完整性
-
定性结果

-
定量结果
- 在每个场景的任意的新视角渲染60张图片计算指标
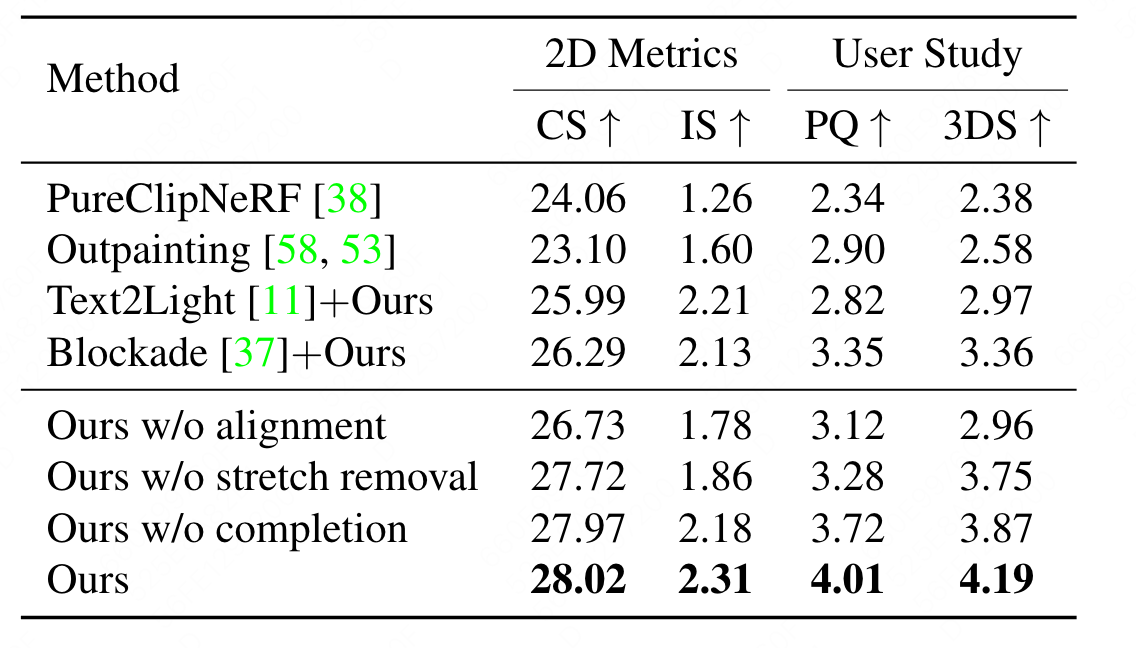
- 在每个场景的任意的新视角渲染60张图片计算指标
总结与局限性
- 本方法能够仅从文本中生成带纹理的3Dmesh.使用text2image生成图片,再通过对齐策略迭代地将图片转换到3D场景.核心在于合适的视角选择.
- 局限性
- 该方法在一些特定的场景下会失效.
- 基于阈值的筛去方法不能将所有的延伸区域去除.
- 一些空洞无法完全补全,导致泊松重建阶段过于平滑.
- 没有将材质和关照解耦