你可能对 torch 上的某些函数感到困惑,它们执行相同的操作但名称不同。 例如: reshape()、view()、permute()、transpose() 等。
这些函数的做法真的不同吗? 不! 但为了理解它,我们首先需要了解一下张量在 pytorch 中是如何实现的。
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎
张量(tensor)是抽象或逻辑结构,就像数组一样,无法按照其设想的方式实现。 显而易见的原因是内存单元是连续(contiguous)的,因此我们需要找到一种方法将它们保存在内存中。 例如,如果我们有一个如下所示的二维张量(或数组):
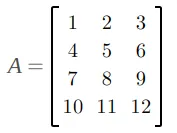
将其保存到内存中的正常(或连续)方式是逐行排列。 所以我们将有:

每个张量都有元数据来声明如何读取张量。 例如,在这个 2d 张量中,为了访问下一行,我们必须向前移动 3 步,而下一列我们应该向前移动 1 步。 我们称这两个数字为步幅(stride)。 所以我们可以像下面这样提取它们:

这为我们开辟了新的可能性,因为们可以通过改变步幅元数据来改变张量! 例如,如果我们将步长从(3, 1) 更改为(1, 3),我们实际上转置了矩阵,而无需对所有内存项进行任何操作:

正如你所注意到的,张量不再连续,因为我们更改了它!为了转到下一行,我们只需跳过 1 个值,而跳过3 个值则移动到下一列。
如果我们回想一下张量的内存布局,这是有道理的:
[0, 1, 2, 3, 4, …, 11]为了移动到下一列(例如从0到3,我们必须跳过 3 个值。因此张量不再是连续的!要使其连续,只需对其调用contigously()即可:

当你调用contigious()时,它实际上会创建张量的副本,因此元素的顺序将与从头开始创建相同形状的张量相同。
请注意,“连续”这个词有点误导,因为它并不是张量的内容分布在断开连接的内存块周围。 这里字节仍然分配在一块内存中,但元素的顺序不同!
同样,视图函数 view()只是原始变量的视图,这意味着如果更改原始内存,它也会发生变化:

这实际上非常有效,因为我们不必为转换创建新的内存槽。 但 reshape()可以复制原始数据。 来自原始文档:
连续输入和具有兼容步幅的输入可以在不复制的情况下进行重塑,但你不应依赖于复制与查看行为。
例如,如果我们有如下代码:

运行输出结果如下:
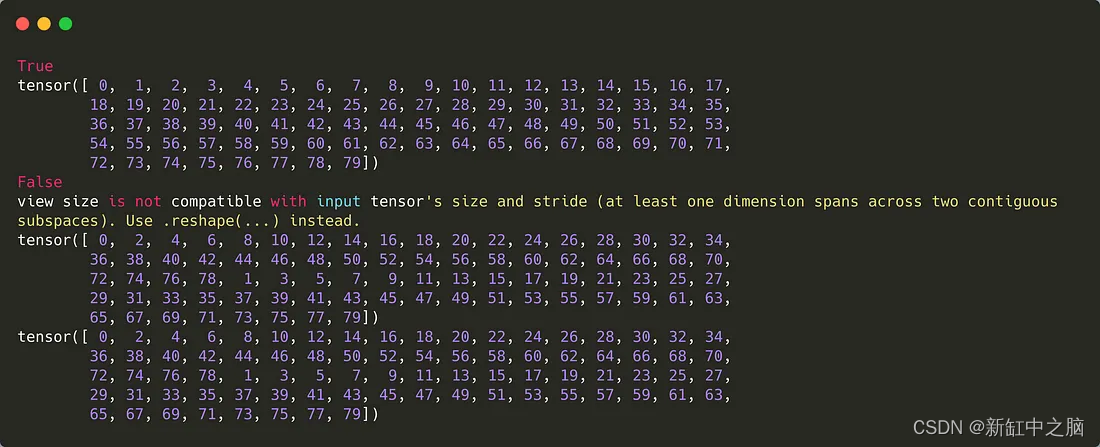
该视图不适用于非连续数据。
另外,考虑到 permute() 是另一个仅适用于元数据的函数,因此它也会创建不连续的数据。 permute() 改变轴的顺序,因此它与改变矩阵形状的 view() 或 reshape() 完全不同。