简介
这是可能一篇没有什么实际作用的文章,因为没有任何shader效果实现,整篇文章到最后,我只实现了一个旋转的立方体(o(╯□╰)o,好弱),和游戏引擎渲染的万紫千红的3D世界显得有很大落差,仿佛一切都回到了最初的起点(不知道有没有人能猜出来左侧的是哪部游戏大作的截图(*^▽^*))。

不过实时渲染繁华的背后,还是这看似简单的光栅化。今天,本人打算学习一下基本的光栅化渲染的过程,看一下怎样把一个模型从一些顶点数据,变成最终显示在屏幕上的图像,也就是所谓的渲染流水线。
所谓SoftRenderer(软渲染),就是用纯代码逻辑模拟OpenGL或者D3D渲染流水线,当然,只是实现了冰山一角,软渲染没有什么实际运用意义,但是对学习渲染原理来说应该是一个比较有效的手段了。之前开了个SoftRenderer的小坑,只是实现了基本的3D变换,三角形图元绘制,仿射纹理映射,最近本想写一篇深度相关的blog的,奈何写了一半发现好多内容需要推导计算,于是乎索性先把软渲染的坑补完,正好这几天把透视校正纹理映射加上了,顺便修了几个bug,基本可以运行起来了(然而我只画了个正方体,帧率还惨不忍睹)。一些高级的特性,比如法线贴图,复杂光照,双线性采样,RT之类的就等之后再慢慢填坑啦(恩,这很有可能是个弃坑-_-)。
简单介绍一下,项目使用的是C++,类似D3D的3D模式,左手坐标系,NDC中Z是(0,1)区间,向量为行向量,左乘矩阵,没有第三方库,只用到了Windows GDI相关,工程VS2015。基本实现了模型->世界->齐次裁剪空间->裁剪->透视除法->视口映射->ZBuffer深度测试->透视校正纹理映射等功能。实现过程中参考了知乎大佬们的各种回答。本人才疏学浅,尤其是渲染这里,很可能只是“看起来是对的“,再加上哥们600多的近视,所以如果有错误,还望各位高手批评指正。
渲染流水线
《Real Time Renderering》中把渲染流水线的功能简要描述如下:给定一个虚拟相机,一些三维物体,灯光,着色方程,贴图等资源,最终生成一张二维图片的过程。所谓流水线Pipline,也就是把原本线性执行的工作,改为并行执行,这样可以极大地提高效率。流水线的瓶颈也就是流水线中最弱的(耗时最长的)。渲染流水线在《RTR》中定义为三个基本阶段,而每一个阶段里面,又分为一些具体的操作步骤,下面分别看一下。
Application(应用程序阶段):字面意思即可,就是相对于渲染来说,其他的内容基本都可以定义在这个阶段。比如游戏逻辑,物理等等。个人理解为在调用DrawCall之前的阶段,该阶段主要在CPU上进行。
Geometry(几何阶段):主要是顶点着色器(MVP变换),裁剪,屏幕映射。处理上一阶段传递进来的图元和位置等信息,计算变换位置,最终决定物体在屏幕上的哪个位置,过程中还需进行裁剪,计算一些需要传递给下一阶段的数据。下图是《RTR3》中定义的Gemmetry阶段:

Rasterizer(光栅化阶段):光栅化阶段是将上一阶段变换投影映射后屏幕空间的顶点(包括顶点包含的各种数据),转化为屏幕上像素的一个过程。在该阶段主要进行的是三角形数据的设置,数据插值,像素着色(包括纹理采样),Alpha测试,深度测试,模板测试,混合。

为了更好地显示,一般会采用双缓冲技术,即在backbuffer渲染,完成后swap到前台。
上面的流水线,可能并不是很全面,新版本的有可能有Geometry Shader,Early-Z,Tiled Based等等,而且这个东西每个厂商可能都不太一样,但是上面的应该算是比较经典的一个流水线,并且都是必不可少的阶段(曾经以为裁剪可以不用,偷一点懒,大不了性能差点,后来发现自己真是太天真)。
下面本人就来大致实现基本的渲染流水线,本文的顺序是绘制直线,三角形,MVP矩阵变换,裁剪,视口映射,深度测试,透视校正纹理采样,是以复杂度作为顺序,并非真正的渲染顺序。
绘制直线
首先来研究一下怎么绘制直线,软渲染中每一个阶段其实都有多种方法进行实现,只不过有些是比较公认的通用方案。我这里只是找了一个适合我的方案。
我们显示在屏幕上的图像,其实就是一幅二维图片,而图片其实是离散的,换句话说,就是一个二维数组,屏幕的坐标就是数组的索引。所以,实际上我们在光栅化阶段绘制的时候,直接使用int型数据即可。俗话说得好,两点确定一条直线,那么,这一个步骤的输入就是两个二维坐标,输出就是一条直线。
实现画线有几种算法,DDA(最易理解,直接算斜率,有除法,不利于硬件实现,慢),Bresenham算法(没有除法和浮点数,快),吴小林算法(带抗锯齿,比Bresenham慢)。这里,我采用了Bresenham算法进行绘制:
//斜率k = dy / dx
//以斜率小于1为例,x轴方向每单位都应该绘制一个像素,x累加即可,而y需要判断。
//误差项errorValue = errorValue + k,一旦k > 1,errorValue = errorValue - 1,保证0 < errorValue < 1
//errorValue > 0.5时,距离y + 1点较近,因而y++,否则y不变。
int dx = x1 - x0;
int dy = y1 - y0;
float errorValue = 0;
for (int x = x0, y = y0; x <= x1; x++)
{
DrawPixel(x, y);
errorValue += (float)dy / dx;
if (errorValue > 0.5)
{
errorValue = errorValue - 1;
y++;
}
}上面算法的主要思想是,按照直线的一个方向,以斜率小于1为例的话,在x轴方向每次步进一个像素,y判断离哪个像素近。通过y方向增加一个累计误差值,当误差值超过1了,说明y方向应该上移一个像素,否则仍然是距离当前y值近。不过上面的算法还是没有避免掉除法的问题,我们可以通过修改一下判断的条件,去掉除法和浮点数,并完善各种情况:
void ApcDevice::DrawLine(int x0, int y0, int x1, int y1)
{
int dx = x1 - x0;
int dy = y1 - y0;
int stepx = 1;
int stepy = 1;
if (dx < 0)
{
stepx = -1;
dx = -dx;
}
if (dy < 0)
{
stepy = -1;
dy = -dy;
}
int dy2 = dy << 1;
int dx2 = dx << 1;
int x = x0;
int y = y0;
int errorValue;
//改为整数计算,去掉除法
if (dy < dx)
{
errorValue = dy2 - dx;
for (int i = 0; i <= dx; i++)
{
DrawPixel(x, y);
x += stepx;
errorValue += dy2;
if (errorValue >= 0)
{
errorValue -= dx2;
y += stepy;
}
}
}
else
{
errorValue = dx2 - dy;
for (int i = 0; i <= dy; i++)
{
DrawPixel(x, y);
y += stepy;
errorValue += dx2;
if (errorValue >= 0)
{
errorValue -= dy2;
x += stepx;
}
}
}
}那么,我们随机在屏幕上画两条线的效果如下,分辨率是600*450,仔细看锯齿还是挺严重的,也让我深刻地意识到了抗锯齿的重要性o(╯□╰)o:
绘制三角形
迈出了最难的第一步,接下来就会好很多了。点,线,面,三个点确定一个三角形,所以我们再加一个参数,绘制一个三角形看一下。但是此处并非直接给三个点,连在一起,而是要把三角形内部填充上颜色。最简单的填充就是扫描线填充,换句话说我们按照屏幕的y轴方向,从上向下,每一行进行绘制,直到把三角形全部填充上为止。首先要把三角形分一下类:
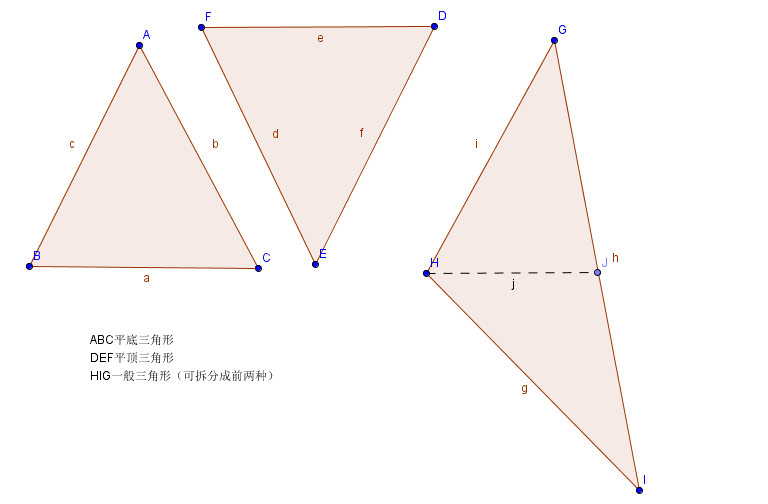
我们已知的是y的方向,那么就需要带入三角形边的直线方程求得x的坐标,然后在两个点之间画线。如果三角形是平顶的或者是平底的,那么我们只需要考虑两条边即可,但是如果是一般的三角形,我们就需要做一下拆分,把三角形划分成一个平顶三角形和一个平底三角形,以上图为例,三角形GHI,以H的y值带入GI直线方程求得J的x坐标,生成GHJ和HJI两个三角形,这两个三角形就可以按照平顶和平底的方式进行光栅化了。
以平底三角形ABC为例,假设A(x0,y0),B(x1,y1),C(x2,y2),AB直线上随机一点(x,y),那么直线方程如下:
(y - y1) / (x - x1) = (y0 - y1) / (x0 - x1),我们已知y(从y0到y1循环),则x值为: x = (y - y0) * (x0 - x1) / (y0 - y1) + x1。AC边类似得到x值,那么循环中我们就可以根据y值得到每条扫描线左右的x值。平底和平顶三角形的绘制代码如下:
void ApcDevice::DrawBottomFlatTrangle(int x0, int y0, int x1, int y1, int x2, int y2)
{
for (int y = y0; y <= y1; y++)
{
int xl = (y - y1) * (x0 - x1) / (y0 - y1) + x1;
int xr = (y - y2) * (x0 - x2) / (y0 - y2) + x2;
DrawLine(xl, y, xr, y);
}
}
void ApcDevice::DrawTopFlatTrangle(int x0, int y0, int x1, int y1, int x2, int y2)
{
for (int y = y0; y <= y2; y++)
{
int xl = (y - y0) * (x2 - x0) / (y2 - y0) + x0;
int xr = (y - y1) * (x2 - x1) / (y2 - y1) + x1;
DrawLine(xl, y, xr, y);
}
}知道了平顶和平底,我们只要根据拐点计算出拐点y轴对应另一边的x值,生成新的三角形即可。但是此处我们为了代码简单一些,先对传入的三个顶点进行一下排序:、
void ApcDevice::DrawTrangle(int x0, int y0, int x1, int y1, int x2, int y2)
{
//按照y进行排序,使y0 < y1 < y2
if (y1 < y0)
{
std::swap(x0, x1);
std::swap(y0, y1);
}
if (y2 < y0)
{
std::swap(x0, x2);
std::swap(y0, y2);
}
if (y2 < y1)
{
std::swap(x1, x2);
std::swap(y1, y2);
}
if (y0 == y1) //平顶三角形
{
DrawTopFlatTrangle(x0, y0, x1, y1, x2, y2);
}
else if (y1 == y2) //平底三角形
{
DrawBottomFlatTrangle(x0, y0, x1, y1, x2, y2);
}
else //拆分为一个平顶三角形和一个平底三角形
{
//中心点为直线(x0, y0),(x2, y2)上取y1的点
int x3 = (y1 - y0) * (x2 - x0) / (y2 - y0) + x0;
int y3 = y1;
//进行x排序,此处约定x2较小
if (x1 > x3)
{
std::swap(x1, x3);
std::swap(y1, y3);
}
DrawBottomFlatTrangle(x0, y0, x1, y1, x3, y3);
DrawTopFlatTrangle(x1, y1, x3, y3, x2, y2);
}
}通过上面的步骤,我们就可以在屏幕上绘制一个填充好的三角形啦,如下图:

ObjectToWorld矩阵构建
下面就是3D相关的操作了,这也是软渲染中最有意思的部分。首先就是MVP变换,具体来说就是将模型空间坐标通过ObjectToWorld矩阵(M)变换到世界空间,然后通过WorldToView矩阵(V)变换到相机空间,最后通过透视投影矩阵(P)变换到裁剪空间。上述的几个变换都是由矩阵完成的。关于矩阵,简单点来说就是一个二维数组,只是为了更加方便地表达变换的过程,并且这些计算通过矩阵更加容易用硬件进行实现。下面主要用到的是矩阵的乘法,向量与矩阵的乘法,矩阵的转置等特性。
如果把矩阵的行解释为坐标系的基向量,那么乘以该矩阵就相当于做了一次坐标变换,vM = w,称之为M将v变换到w。用基向量[1,0,0]与任意矩阵M相乘,得到[m11,m12,m13],得出的结论是矩阵的每一行都可以解释为转化后的基向量。根据该结论,就可以通过一个期望的变换,反向构造出一个矩阵来代表这个变换。首先来看一下MVP的M,也就是模型空间转世界空间的变换,这个变换也是分为三个子变换,分别是缩放,旋转,平移。下面分别推导一下几个变换的矩阵。
缩放矩阵
缩放是最简单的变换,假设顶点为(x, y, z),缩放系数为(sx, sy, sz),那么缩放希望的就是(sx *x, sy * y, sz * z),我们用一个矩阵来表示的话就是:
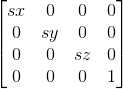
代码如下:
Matrix ApcDevice::GenScaleMatrix(const Vector3& v)
{
Matrix m;
m.Identity();
m.value[0][0] = v.x;
m.value[1][1] = v.y;
m.value[2][2] = v.z;
return m;
}旋转矩阵
接下来是旋转矩阵,看起来有点麻烦,而且x,y,z三个方向需要单独实现,其实又是三个矩阵相乘,这篇文章推导的比较明了,借用一张图:
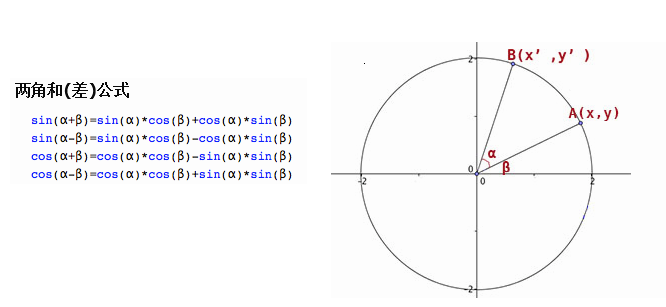
到这个时候,我才意识到,哇塞,原来三角函数展开的实际应用竟然这么重要。。。我们要表示一个旋转,比如绕Z轴旋转,那么这个时候,Z轴的坐标是不会变化的,所以只考虑X,Y轴坐标即可,比如上图,A为原始坐标(x,y),角度为β,旋转角度α变换到B点(x’,y'),半径为r。此时,左右手坐标系的差别就有了,我使用的是左手坐标系,所以用左手拇指指向Z轴正方向(指向屏幕内),另外四指环绕的方向就是旋转的正方向了。如果用右手坐标系,那么就得换成右手了。
那么x’= r * cos(α + β) = cos(α) * cos(β) * r - sin(α) * sin(β) * r = cos(α) * x - sin(α) * y
同理y’= r * sin(α + β) = sin(α) * cos(β) * r + cos(α) * sin(β) * r = sin(α) * x + cos(α) * y
根据上面的两个等式,我们就可以构建出一个矩阵,Z方向不变,置为1即可,矩阵如下:
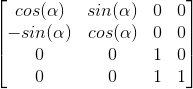
绕X轴旋转的矩阵:

绕Y轴旋转的矩阵:
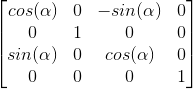
最终,这样,每个轴上我们给定一个角度即可得到旋转的矩阵,最终矩阵为三者相乘,绕三个轴旋转值按一个Vector传递进来:
Matrix ApcDevice::GenRotationMatrix(const Vector3& rotAngle)
{
Matrix rotX = GenRotationXMatrix(rotAngle.x);
Matrix rotY = GenRotationYMatrix(rotAngle.y);
Matrix rotZ = GenRotationZMatrix(rotAngle.z);
return rotX * rotY * rotZ;
}
Matrix ApcDevice::GenRotationXMatrix(float angle)
{
Matrix m;
m.Identity();
float cosValue = cos(angle);
float sinValue = sin(angle);
m.value[1][1] = cosValue;
m.value[1][2] = sinValue;
m.value[2][1] = -sinValue;
m.value[2][2] = cosValue;
return m;
}
Matrix ApcDevice::GenRotationYMatrix(float angle)
{
Matrix m;
m.Identity();
float cosValue = cos(angle);
float sinValue = sin(angle);
m.value[0][0] = cosValue;
m.value[0][2] = -sinValue;
m.value[2][0] = sinValue;
m.value[2][2] = cosValue;
return m;
}
Matrix ApcDevice::GenRotationZMatrix(float angle)
{
Matrix m;
m.Identity();
float cosValue = cos(angle);
float sinValue = sin(angle);
m.value[0][0] = cosValue;
m.value[0][1] = sinValue;
m.value[1][0] = -sinValue;
m.value[1][1] = cosValue;
return m;
}上面,我们只考虑物体绕自身轴旋转,如果需要绕任意一点旋转的话,我们就可以先进行平移,平移到该点,然后再旋转,旋转后再平移回去。即v = vTRT^-1
平移矩阵
原本而言,我们用3x3的矩阵即可表示上面两种变换,然而平移不行,所以就需要引入一个4x4的矩阵来表达平移变换,比如一个顶点(x,y,z)我们希望它平移(tx,ty,tz)距离,那么实际上就是(x + tx,y + ty,z + tz)。使用矩阵来表示的话就是:
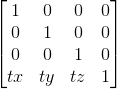
而如果用4x4矩阵,Vector3显然也不够用了,为了能达到上述的变换,我们就需要给Vector增加一个w维度,w = 1时,Vector表示点,与上述矩阵相乘后得到变换的结果,而w = 0时,Vector表示向量,上述变换的结果仍然是Vector自身,平移变换对方向变换不生效。
平移矩阵的代码如下:
Matrix ApcDevice::GenTranslateMatrix(const Vector3& v)
{
Matrix m;
m.Identity();
m.value[3][0] = v.x;
m.value[3][1] = v.y;
m.value[3][2] = v.z;
return m;
}ObjectToWorld矩阵整合
经过上面的步骤,我们得到了缩放矩阵,旋转矩阵,平移矩阵,最终将三者使用矩阵乘法相乘即可得到完整的ObjectToWorld矩阵,由于我们采用了行向量表示坐标,所以相当于左乘,即我们用vSRT的顺序进行变换。
我们可以根据矩阵连乘结合律把几个变换通过矩阵相乘的方法,先计算出一个结果矩阵再用该矩阵去变换顶点,这有一个很大的好处,就是我们可以逐对象计算一次变换整体的变换矩阵,然后这个对象的所有的顶点都应用这个变换。这样就把变换的时间从n次MVP计算+n次矩阵与顶点相乘变成了1次矩阵MVP计算+n次矩阵与顶点相乘,而且可以避免浮点计算误差(尝试了一下逐图元计算变换矩阵,最后正方形边界对不上,改为统一计算后效果正常)。我们不需要一些特殊的效果(固定管线),所以我们直接把这个SRT矩阵与后续的VP矩阵相乘,结果再来进行坐标的变换。
WorldToCamera矩阵构建
上一阶段,我们把顶点从模型空间转换到了世界空间,但是有一个很重要的问题,相机才是我们观察世界的窗口,后续的投影,裁剪,深度等如果都在世界空间做的话就太复杂了,如果我们把这些操作的坐标原点改为相机,就会大大降低后续操作的复杂性。所以,下一步就是如何将一个世界空间的对象转化到相机空间。要定义一个相机,首先要有相机位置,还要有相机看的方向,一种方法是给出相机的旋转角度,也就是Raw,Pitch,Roll这三个值,如下图:
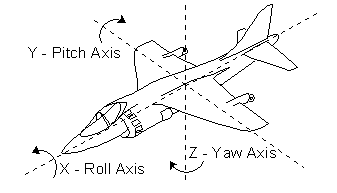
另一种方案就是给一个相机注视点以及一个控制相机Y轴方向的向量,也就是UVN相机模型,UVN比较容易定义相机的朝向,类似LookAt的功能,所以这里我们采用这种方式定义我们的相机位置和朝向。给定了相机位置和注视点位置,我们就能求得视方向向量N,然后我们根据给定的上向量V(只是输入临时用的,不是最终的V,输入的V在VN平面没有权重,因为N已经确定了视方向,只有UV平面上可能有权重,所以需要重新计算一个仅影响Roll的角),通过向量叉乘得到一个Cross(N,V)得到右向量U,最终我们再用Cross(N,U)得到真正的V,三者都需要Normalize。这样,我们就构建出了相机所在的空间基准坐标系。
我们要的是WorldToCamera的变换,不过,对一个点做一个变换,相当于对其所在坐标系做逆变换,所以我们只要求出整体变换的逆矩阵即可。比如上面的变换称之为WTC,上面的变换包括一个旋转R和平移T,那么我们要求的WTC^-1 (表示逆)=(RT)^-1 = (T^-1)( R^-1)。我们拆开来看:
先是旋转矩阵的逆,其实上面的计算,我们构建的UVN就是R矩阵了(把相机转换到世界空间,但是在第四行没有分量,换句话说就是3X3的矩阵,没有位移,也没有缩放,那么就只有旋转),下面一步就是求R的逆。矩阵正常求逆的运算是很费的,所以一般来说要避免直接求逆,因为3X3的旋转矩阵其实是一个正交矩阵(各行各列都是单位向量,并且两两正交,可以把上一节的旋转矩阵每个看一遍,抽出左上角3X3部分)。正交矩阵的重要性质就是MM^T (转置)= E(单位矩阵),进一步推导就是M ^ T = M ^ -1,所以上面的旋转矩阵的逆实际上就是它的转置。转置的话,我们只需要沿着对角线把数据互换一下,计算量比起求逆要小得多。
接下来是平移矩阵的逆,这个其实不需要去推导,比如向量按照(tx,ty,tz)进行了平移变换,那么对它的逆变换其实就是取反(-tx,-ty,-tz)。
最终两个矩阵以及相乘结果如下,其中T = (tx,ty,tz),UVN同理:
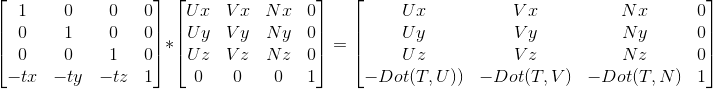
我们直接结果构建最终的矩阵,避免多一次矩阵运算,代码如下:
Matrix ApcDevice::GenCameraMatrix(const Vector3& eyePos, const Vector3& lookPos, const Vector3& upAxis)
{
Vector3 lookDir = lookPos - eyePos;
lookDir.Normalize();
Vector3 rightDir = Vector3::Cross(upAxis, lookDir);
rightDir.Normalize();
Vector3 upDir = Vector3::Cross(lookDir, rightDir);
upDir.Normalize();
//构建一个坐标系,将vector转化到该坐标系,相当于对坐标系进行逆变换
//C = RT,C^-1 = (RT)^-1 = (T^-1) * (R^-1),Translate矩阵逆矩阵直接对x,y,z取反即可;R矩阵为正交矩阵,故T^-1 = Transpose(T)
//最终Camera矩阵为(T^-1) * Transpose(T),此处可以直接给出矩阵乘法后的结果,减少运行时计算
float transX = -Vector3::Dot(rightDir, eyePos);
float transY = -Vector3::Dot(upDir, eyePos);
float transZ = -Vector3::Dot(lookDir, eyePos);
Matrix m;
m.value[0][0] = rightDir.x; m.value[0][1] = upDir.x; m.value[0][2] = lookDir.x; m.value[0][3] = 0;
m.value[1][0] = rightDir.y; m.value[1][1] = upDir.y; m.value[1][2] = lookDir.y; m.value[1][3] = 0;
m.value[2][0] = rightDir.z; m.value[2][1] = upDir.z; m.value[2][2] = lookDir.z; m.value[2][3] = 0;
m.value[3][0] = transX; m.value[3][1] = transY; m.value[3][2] = transZ; m.value[3][3] = 1;
return m;
}透视投影矩阵构建
接下来的投影阶段是3D向2D转换的一个重要的步骤(并不是这一步就转),同时也是后续CVV裁剪,ZBuffer,透视纹理校正的基础,这里我们暂且不考虑正交投影,直接来看透视投影。上文我们提到,为了更好地变换,用4X4矩阵,进而引入齐次坐标的概念,但是实际上,齐次坐标系真正的作用在于透视投影变换。
透视投影的主要知识点在于三角形相似以及小孔呈像,透视投影实现的就是一种“近大远小”的效果,其实投影后的大小(x,y坐标)也刚好就和1/Z呈线性关系。首先看下面一张图:
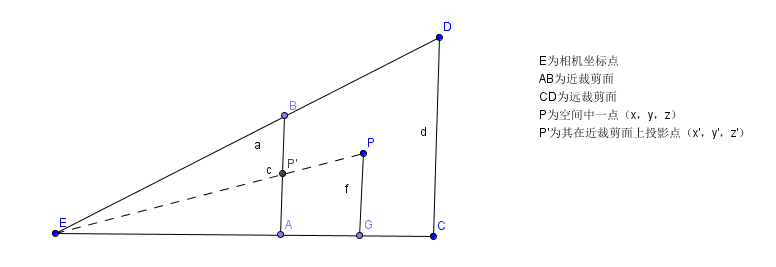
上图是一个视锥体的截面图(只看x,z方向),P为空间中一点(x,y,z),那么它在近裁剪面处的投影坐标假设为P’(x',y',z’),理论上来说,呈像的面应该在眼睛后方才更符合真正的小孔呈像原理,但是那样会增加复杂度,没必要额外引入一个负号(此处有一个裁剪的注意要点,下文再说),只考虑三角形相似即可。即三角形EAP’相似于三角形EGP,我们可以得到两个等式:
x’/ x = z’/ z => x’= xz’/ z
y’/ y = z’/ z => y’= yz’/ z
由于投影面就是近裁剪面,那么近裁剪面是我们可以定义的,我们设其为N,远裁剪面为F,那么实际上最终的投影坐标就是:
(Nx/z,Ny/z,N)。
投影后的Z坐标,实际上已经失去作用了,只用N表示就可以了,但是这个每个顶点都一样,每个顶点带一个的话简直是暴殄天物,浪费了一个珍贵的维度,所以这个Z值会被存储一个用于后续深度测试,透视校正纹理映射的变换后的Z值。
这个Z值,还是比较有说道的。在透视投影变换之前,我们的Z实际上是相机空间的Z值,直接把这个Z存下来也无可厚非,但是后续计算会比较麻烦,毕竟没有一个统一的标准。既然我们有了远近裁剪面,有了Z值的上下限,我们就可以把这个Z值映射到[0,1]区间,即当在近裁剪面时,Z值为0,远裁剪面时,Z值为1(暂时不考虑reverse-z的情况)。首先,能想到的最简单的映射方法就是depth = (Z(eye) - N)/ F - N。but,这种方案是不正确的(需要参考下文关于光栅化数据插值的内容,此处先给出结论,我认为这个1/z在光栅化阶段解释更为合适):透视投影变换之后,在屏幕空间进行插值的数据,与Z值不成正比,而是与1/Z成正比。所以,我们需要一个表达式,可以使Z = N时,depth = 0,Z = F时,depth = 1,并且需要有一个z作为分母,可以写成(az + b)/z,带入上述两个条件:
(N * a + b) / N = 0 => b = -an
(F * a + b) / F = 0 => aF + b = F => aF - aN = F
进而得到: a = F / (F - N) b = NF / (N - F)
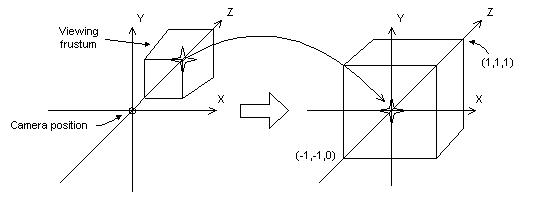
最终其实视锥体被变换为NDC,但是实际上我们一般是先不进行透视除法,那么就称之为CVV(此处不要过度纠结这两个概念,下文再去解释)过程如下图(DX文档附图)所示(下图是DX模式,左手系,NDC中Z区间是0到1,也是本文使用的模式;GL的话NDC中Z是-1到1,而且是右手系,二者最终推导出的透视投影矩阵是有差异的),主要思想就都是映射,把一个区间映射到另一个区间:
我们已经把Z值,进行了映射,秉承着映射大法好的观点,我们再把X和Y进行一下映射,上面我们已经计算出投影后的坐标值是(Nx/z,Ny/z,N)。假设近裁剪面上下分别为U,B,左右分别为L,R,我们要把原始的区间映射到[-1,1]区间。我们以X轴为例进行推导,最终X投影点映射到NDC的坐标假设为Xndc,那么映射公式如下:
Xndc - (-1) / (1 - (-1)) = (XN / Z - L) / (R - L)
计算该公式得到Xndc = 2XN / Z(R - L) - (R + L)/ (R - L)
同理Yndc = 2YN / Z(T - B) - (T + B) / (T - B)
这样,我们就可以得到了XYZ三个方向在NDC空间的坐标。
下面在来解释一下NDC和CVV,所谓NDC,全称为Normalized Device Coordinates,也就是标准设备空间,为何要引入这样一个空间呢,主要在于我们使用不同的设备,分辨率可能都不一样,实际在写shader的时候,没办法根据分辨率进行调整,而通过这样一个空间,把x,y映射到(-1,1)区间,z映射到(0,1)区间(OpenGL是(-1,1)),在下一步屏幕坐标映射时再根据屏幕分辨率生成像素真正应该在的位置,这样可以省掉很多设备适配的问题,让我们在写shader的时候一般不需要考虑屏幕分辨率的问题(有时候有,主要是全屏后处理时屏幕宽高的比例,我之前在屏幕水波纹效果中实现就遇到了这样的问题)。
再来看一下CVV,CVV全称为Canonical View Volume,即规则观察体。其实上面的变换最终的坐标应该是NDC的,但是为了更方便地做一些其他的操作,主要是CVV裁剪,引入了一个新的空间,这个空间主要是没有NDC空间的坐标没进行除以w计算,也就是说CVV空间的顶点还是齐次空间下的,除了w之后才会变为NDC空间,两者的差距主要是是否除以了w。个人理解:CVV只是用齐次坐标系表示了的NDC(如果我的理解不正确,还希望您及时指出我的错误)。
关于CVV裁剪,下文再讲,我们还是回到透视投影矩阵:
我们既然要CVV空间,也就是齐次裁剪空间下的顶点,所以我们刚好可以把上文得到的投影点坐标的每个元素的除以Z变换成W分量的Z,然后XYZ分量下的除以Z就可以去掉了,也就是说用齐次空间表示一下最终的投影点坐标:
P’(NX,NY,aZ + b,Z)带入上面的推导结果得到透视投影矩阵:
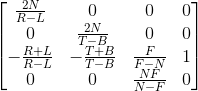
上面的矩阵是一个通用的矩阵,但是实际上我们绝大多数情况用的矩阵都是一个特殊情况的矩阵,也就是我们的相机刚好在视锥体中间,上下左右对称,那么R和L对称,T和B对称,两者相加都等于0,而R-L和T-B我们就可以用一个宽度和高度来表示,简化后的矩阵如下:
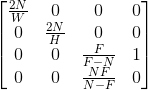
下面我们再考虑一下怎样更加优雅地表示这个矩阵(换句话说就是参考一下DX和GL真正的接口)。我们一般来说,给定一个
FOV角度,N近裁剪面,F远裁剪面,Aspect屏幕宽高比即可,如下图:
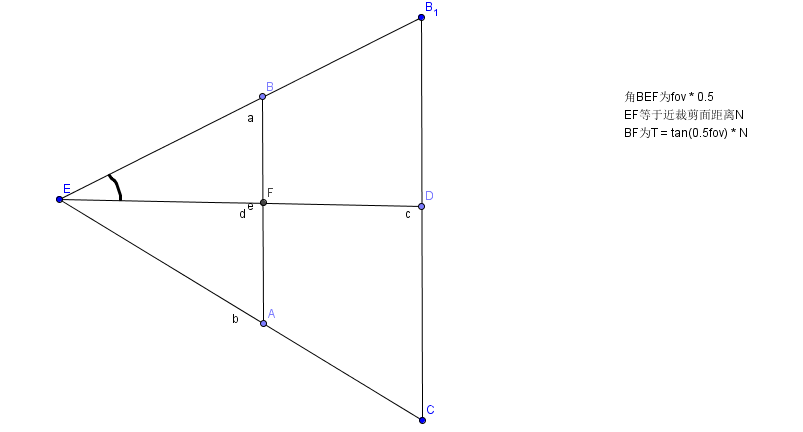
那么BF也就是的高度就是tan(0.5*fov)* N 最终的H = 2 tan(0.5fov)*N,最终的W = Aspect * H。带入上述矩阵:
2N/H = 2N/2tan(0.5fov)N = 1/tan(0.5fov) = cot(0.5fov)
2N/W = 1/(Aspect * tan(0.5fov)) = cot(0.5fov)/Aspect
最终矩阵结果如下,暂且还是以tan表示:
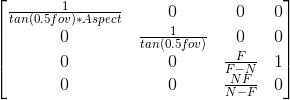
代码如下:
Matrix ApcDevice::GenProjectionMatrix(float fov, float aspect, float nearPanel, float farPanel)
{
float tanValue = tan(0.5f * fov * 3.1415 / 180);
Matrix proj;
proj.value[0][0] = 1.0f / (tanValue * aspect);
proj.value[1][1] = 1.0f / (tanValue);
proj.value[2][2] = farPanel / (farPanel - nearPanel);
proj.value[3][2] = -nearPanel * farPanel / (farPanel - nearPanel);
proj.value[2][3] = 1;
return proj;
}这里,我们只是进行了透视投影变换的第一步,将顶点转化到齐次裁剪空间,因为并没有进行透视除法,所以还没有所谓的投影。第二步是透视除法,但是中间一般还会穿插一步,CVV裁剪。
啊,终于写完了透视投影矩阵的变换,实际上这个矩阵结果只有几个数,然而背后的数学推导还是比较复杂的。有了P矩阵,我们最终用来变换的矩阵就都完成了。
CVV裁剪
经过了透视变换,坐标被变换到CVV空间,此时仍然是齐次坐标,我们正常应该是判断在裁剪的立方体内,不过齐次坐标我们也就是直接比较xyz值和w的值即可,DX模式的话,z需要比较0和w。这个是非常重要的,因为我们默认为了方便是把投影平面放到了眼睛前面,但是真的有在投影平面后面的东西,如果不剔除z<0的内容,就会导致这一部分按照不对的透视公式进行计算导致结果错误。而且更重要的一点在于,相机空间z = 0的时候(也就是齐次空间的w = 0)的这种情况,在我们透视除法的时候会有除0的问题。所以要把这个剔除掉。
比如一个齐次空间的顶点,我们可以按照上述方式判断其是否在CVV内:
inline bool ApcDevice::SimpleCVVCullCheck(const Vertex& vertex)
{
float w = vertex.pos.w;
if (vertex.pos.x < -w || vertex.pos.x > w)
return true;
if (vertex.pos.y < -w || vertex.pos.y > w)
return true;
if (vertex.pos.z < 0.0f || vertex.pos.z > w)
return true;
return false;
}CVV裁剪个人感觉是一个比较有争议的地方,现代的GPU到底如何去做裁剪,我不敢妄加推测,看了知乎上大佬们的讨论,也是分为几个派别。有认为裁剪的,有人为只剔除不裁剪的。不过个人倒比较赞同,重新构建一个三角形对于GPU来说还不如把整个三角形都画了好,毕竟实际运用时,三角形的密度很大,面积很小,都绘制了也要比裁剪可能还省。对于CVV中比较好处理的主要在于我们可以在透视除法前就把完全不可见的三角形直接剔除掉。所以我只实现了最简单的三顶点均不在CVV内剔除的方案(好吧,为偷懒找了个理由o(╯□╰)o)。
实现了CVV裁剪,其实还是蛮爽的,尤其是本身没有场景管理,视锥体裁剪的话,提交上来的所有内容都要绘制,如果本身不可见的话,那直接就咔掉了。测试的话,直接渲染立方体,帧率25左右,立方体在CVV外不开裁剪,帧率100多些(有视口范围判断),立方体在CVV外开裁剪,帧率999+直接爆表 。
透视除法与屏幕坐标映射
经过了透视投影变换,CVV裁剪,现在我们的顶点坐标都在齐次裁剪空间,下一步就是真正地进行透视除法了,经过了这一步才真正算是完成了透视投影变换。其实这个操作比较简单,因为计算在透视投影矩阵的构建中我们都推导过了,乘过Project矩阵的顶点,w坐标就不会是默认的1了。因为我们把Z值存了进去,此时我们将三个分量都除以Z,就得到了透视变换后的NDC坐标了。
马上就可以和我们之前进行的在屏幕上绘制三角形联系起来了,中间只差了一步,那就是屏幕坐标映射。上文介绍过,NDC的作用就是为了让我们计算时不需要考虑屏幕分辨率相关的问题,因为DX或者GL替我们做了,软渲染的话,我们就需要自己做这一步。
我们创建窗口的时候,会给一个窗口的宽度和高度(RT类似),既然我们得到了NDC空间的坐标值了,并且知道了屏幕的长和宽(分辨率),那么,是时候进行一波映射了。映射大法好啊!
NDC是(-1,1)区间(现在暂时只考虑X,Y),我们要把它映射到屏幕的(0,width)和(0,height)区间即可。先看X方向:首先,我们从(-1,1)区间映射到(0,1)区间,也就是(v.x / v.w + 1)* 0.5 * deviceWidth。Y方向,屏幕实际的坐标是左上角为(0,0)点,与我们的NDC是反过来的,所以映射到(0,1)区间后,还需要反向一下,改为(1-screendCoord)* deviceHeight。代码如下,进行了透视除法&屏幕空间映射:
float reciprocalW = 1.0f / v.w;
float x = (v.x * reciprocalW + 1.0f) * 0.5f * deviceWidth;
float y = (1.0f - v.y * reciprocalW) * 0.5f * deviceHeight;这里的x,y就是经过了上述所有变换后,最终在屏幕上的坐标点。下面我们整合一下整个3D变换的过程,最终屏幕坐标v' = vFinalMatrix => vMVP => vSRTVP => vSRxRyRzTVP,代码如下:
Matrix ApcDevice::GenMVPMatrix()
{
Matrix scaleM = GenScaleMatrix(Vector3(1.0f, 1.0f, 1.0f));
Matrix rotM = GenRotationMatrix(Vector3(0, 0, 0));
Matrix transM = GenTranslateMatrix(Vector3(0, 0, 0));
Matrix worldM = scaleM * rotM * transM;
Matrix cameraM = GenCameraMatrix(Vector3(0, 0, -5), Vector3(0, 0, 0), Vector3(0, 1, 0));
Matrix projM = GenProjectionMatrix(60.0f, (float)deviceWidth / deviceHeight, 0.1f, 30.0f);
return worldM * cameraM * projM;
}
void ApcDevice::DrawTrangle3D(const Vector3& v1, const Vector3& v2, const Vector3& v3, const Matrix& mvp)
{
Vector3 vt1 = mvp.MultiplyVector3(v1);
Vector3 vt2 = mvp.MultiplyVector3(v2);
Vector3 vt3 = mvp.MultiplyVector3(v3);
Vector3 vs1 = GetScreenCoord(vt1);
Vector3 vs2 = GetScreenCoord(vt2);
Vector3 vs3 = GetScreenCoord(vt3);
DrawTrangle(vs1.x, vs1.y, vs2.x, vs2.y, vs3.x, vs3.y);
}我们把MVP的计算整个抽取出来,每个对象计算一次即可,对象所有的三角形运用同一个MVP变换,即每个三角形逐顶点与MVP矩阵相乘,然后进行视口映射即可。这样,我们就得到了一个可以变换的三角形(虽然看起来和上面一样,然而这的确是一个有故事的三角形,因为他不是直接显示在屏幕上的,而是历经了无数次计算,才显示到了屏幕上):
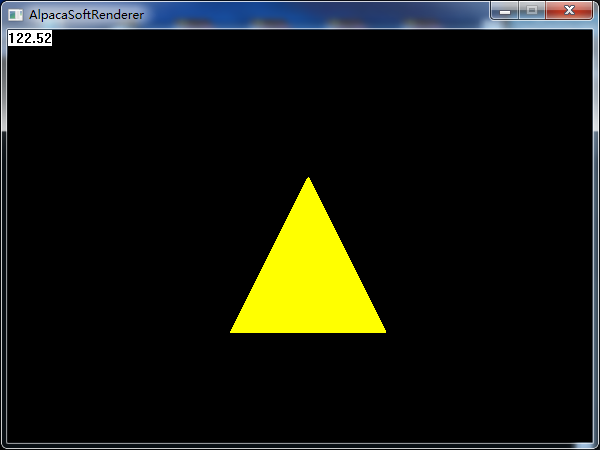
来一张动图,应用了旋转和平移变换(有故事的三角形自然多了一些能力,比如移动,旋转,缩放,随着相机位置移动的近大远小效应):

光栅化数据插值与仿射纹理映射
直到目前为止,我们虽然可以在屏幕上看到三角形了,并且可以运用各种变换,但是我们的三角形没有任何其他数据,仅有一个位置信息,这是十分令人不爽的,尤其是我这个视觉动物,憋了半天终于画出了个三角形,然而还木有颜色,简直是不能忍了!我们要给它加点料!要有更好的表现,我们就要给顶点加一些属性,最常见的,也是最容易的,就是颜色啦。我们给每个顶点增加一个顶点色,存储在顶点中。but,我们这时候应该意识到一个问题,我们的三角形只有三个点,而最终显示在屏幕上的可是无数个像素啊,其中的数据要怎么样得到呢?
比如我们正常写shader的时候,经常会定义一个v2f之类的结构体,用来从vertex阶段传递到fragment阶段,vertex阶段我们只考虑逐顶点计算的值就可以了,传递v2f,到fragment阶段,自动就可以在输入时取到每个v2f在fragment阶段的值,这个数据实际上是渲染管线帮我们自动处理了。所运用到的知识点其实也是非常简单的,就是插值(Lerp)。
来看一维的插值代码,也就是我们经常用的Lerp函数:
float LerpFloat(float v1, float v2, float t){ return v1 + (v2 - v1) * t;}其实非常简单,我们给一个(0,1)的插值控制函数,就可以完成从v1,v2之间的插值了,当t=0时,为v1,当t=1时为v2。
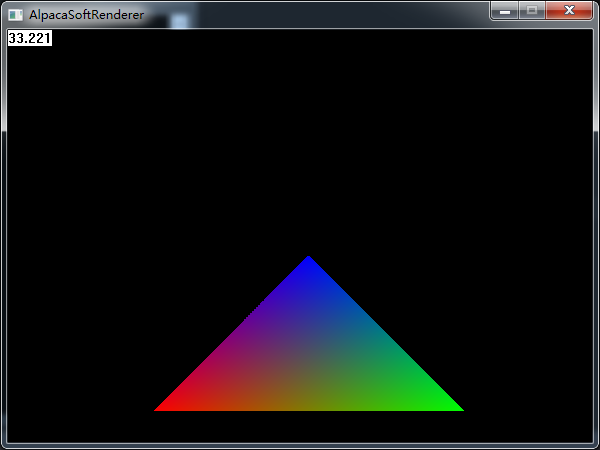
那么,在三角形设置好之后,三个顶点的数据是一定的,接下来要从上到下绘制扫描线,我们每次要绘制扫描线的时候,首先要获得扫描线两侧端点的数据值,扫描线的两侧端点的值在我们求解方程的时候可以得到,也就能求出该点在端点所在的边所处的值,此处是从上到下,那么我们就用y作为插值系数,以即每一点的t = (y - y0)/ (y2 - y0),然后我们就可以用这个系数去在顶点和底点两个点之间插值得到当前线上扫描线起始点和结束点的颜色值。扫描线本身也是同理,已知左右两点的颜色值,每次前进一个像素,都可以求出当前t = (x - x0) / (x1 - x0)作为插值系数。比如我们给上面的三角形增加一个顶点色,通过插值就可以得到如下的效果:
有了颜色,我们的三角形就好看了不少。需求总是有的,能不能再好看一点呢?既然代码写不出来,那就贴张图上去吧!(我想这应该也是前辈们发明纹理映射的初衷吧)。还是同一个问题,我们只有顶点数据,也就是美术同学展uv得到的坐标值,存在顶点中。像素上全靠插值,那么要想贴上一张图,我们应该有的其实是这一个像素点应该采样的纹理坐标也就是uv值,还是一样的思路,我们补全插值的计算和顶点上的uv数据。然后用windows自带的功能读入一张bmp贴图,然后构建一个二维数组,把这个贴图的每个像素逐步拷入数组就可以了。采样时,我们计算出uv值,然后依然是映射大法好,因为uv是(0,1)区间,我们把这个区间映射到像素数组的大小,然后就可以用这个index去纹理数组中采样该点的颜色了。其实在这一步也可以做一点小文章,比如传过来的uv是非(0,1)区间的,那么边界的颜色怎么给,如果我们直接截断,那么就是clamp,也可以取余数那就是repeat,还可以实现mirror等模式。这里我就直接Clamp了。下面是Texture类中两个主要的函数:
void Texture::LoadTexture(const char* path)
{
HBITMAP bitmap = (HBITMAP)LoadImage(NULL, path, IMAGE_BITMAP, width, height, LR_LOADFROMFILE);
HDC hdc = CreateCompatibleDC(NULL);
SelectObject(hdc, bitmap);
for (int i = 0; i < width; i++)
{
for (int j = 0; j < height; j++)
{
COLORREF color = GetPixel(hdc, i, j);
int r = color % 256;
int g = (color >> 8) % 256;
int b = (color >> 16) % 256;
Color c((float)r / 256, (float)g / 256, (float)b / 256, 1);
textureData[i][j] = c;
}
}
}
Color Texture::Sample(float u, float v)
{
u = Clamp(0, 1.0f, u);
v = Clamp(0, 1.0f, v);
//暂时直接采用clamp01的方式采样
int intu = width * u;
int intv = height * v;
return textureData[intu][intv];
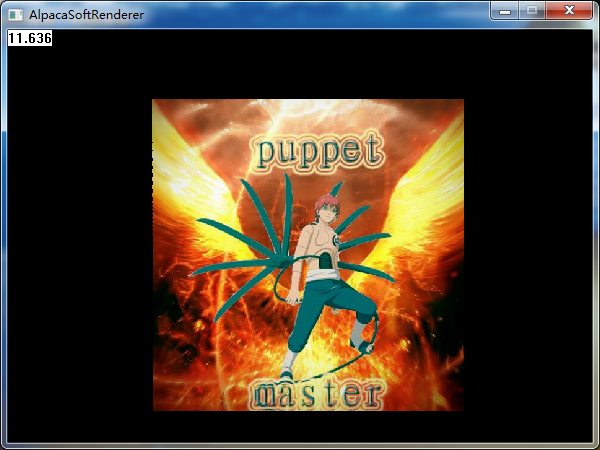
}搞一个自己的头像试一下纹理映射:
看起来好多了,是不是大功告成了呢?其实并不是,因为这一节忽略了一个重要的问题,导致我们所有的插值其实都是错误的,上面看起来没有问题,是因为仅仅看起来可能是对的。
1/Z的问题与透视校正纹理映射
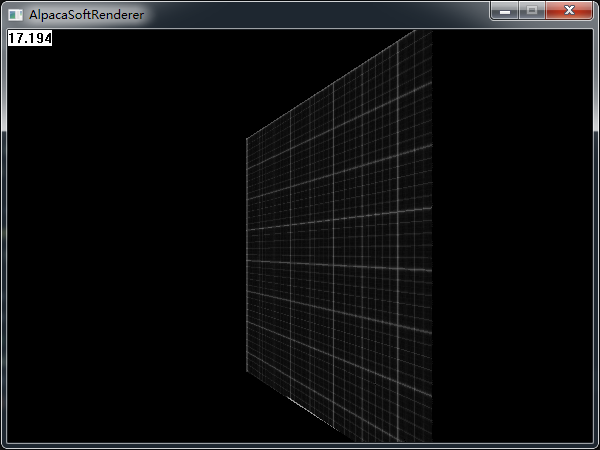
我们把上面的面片,沿着Y轴旋转45度,再看一下效果:
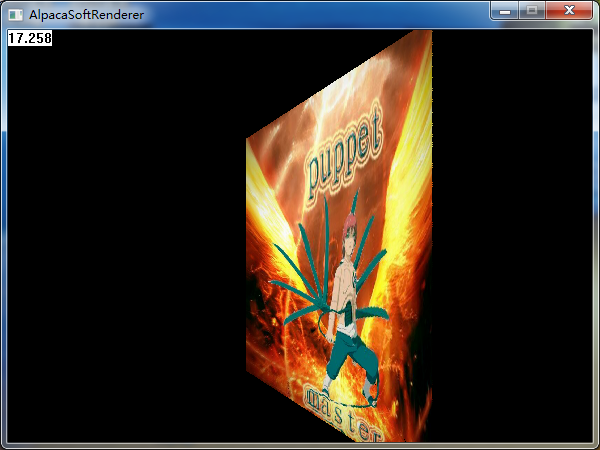
哦,伟大的蝎同志肿么变成了小短腿。。。简直玷污了我的偶像(我得赶快改好)。如果我们换一个贴图,那么这个问题将暴露得更加明显:
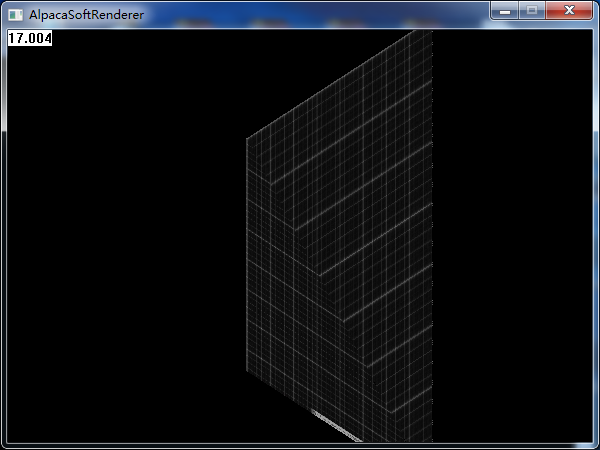
这是个什么鬼。。。我贴上去的可是一个方方正正的网格贴图:

那么,问题应该比较明确了,就出在透视上。来看一张图解释一下上面的现象:
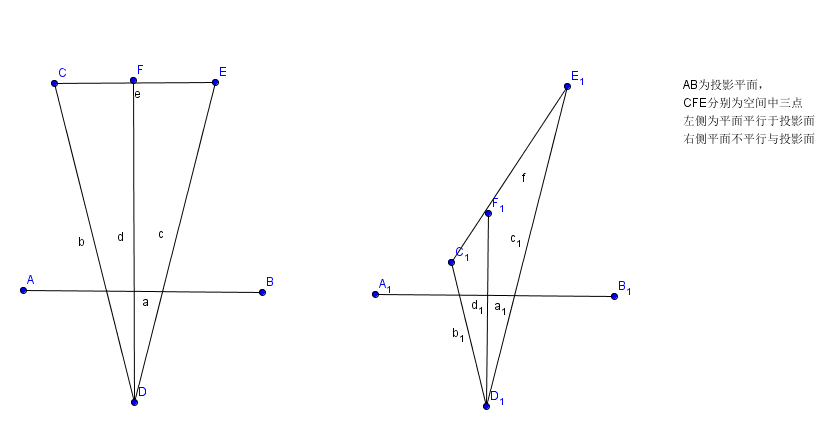
右侧的三角形是我直接复制过去的,唯一的区别就在于左侧CFE平面平行于近裁剪面,而右侧把CFE整个一条线拉歪,使C接近近裁剪面。二者在最终投影在近裁剪面的位置完全相同,但是实际上在三维空间位置是相差甚远的。
先祭出两篇大佬的推导:一篇几何证明,一篇代数证明。我数学不好,只能膜拜这些大佬了。主要证明的就是在投影空间的值与1/z成正比。
我们存在顶点中的数据,顶点颜色,顶点上uv的坐标等内容,其实都是在模型空间下制作的,换句话说,这些值实际上应该在模型空间下进行插值计算,但是投影是一个损失维度的变换,我们单纯地用最终二维屏幕上的位置距离去插值,如果Z全都一致,那没有影响,在投影平面均匀变换的值,对应相机空间(推回模型空间也一样)也是均匀变换的。但是像右图,在投影平面两段相同距离对应相机空间的距离就不同了。
我们在推导投影矩阵的时候,得到过投影点的坐标(Nx/z,Ny/z,N),换句话说,投影后的X’本身就是与1/Z呈线性关系的,然后我们还知道uv坐标与x呈线性关系,实际上就是uv坐标与1/z呈线性关系,那么通过这样一个方式,我们在三角形进行设置时,强行把uv除以一个z,那么此时uv就变成了uv/z,这个值是与投影后的nx/z呈线性关系的,也就是说我们可以在屏幕空间根据距离进行线性插值得到一点上的确切的uv/z值。不过还有一个问题,我们得到了uv/z,还需要把uv还原,也就是得到uv,我们还需要再求出当前点的1/z值,这个值被我们存在了z坐标上,我们在每个点采样的时候,再把z乘回去,就得到了这一点真正的uv坐标值(最后除以z和w其实效果差不多,两者其实也是线性关系)。
inline void ApcDevice::PrepareRasterization(Vertex& vertex)
{
//透视除法&视口映射
//齐次坐标转化,除以w,然后从-1,1区间转化到0,1区间,+ 1然后/2 再乘以屏幕长宽
float reciprocalW = 1.0f / vertex.pos.w;
vertex.pos.x = (vertex.pos.x * reciprocalW + 1.0f) * 0.5f * deviceWidth;
vertex.pos.y = (1.0f - vertex.pos.y * reciprocalW) * 0.5f * deviceHeight;
//将其他数据转化为1/z
vertex.pos.z *= reciprocalW;
vertex.u *= vertex.pos.z;
vertex.v *= vertex.pos.z;
}在采样时,使用了:
int errorValue = dy2 - dx;
for (int i = 0; i <= dx; i++)
{
float t = (x - x0) / (x1 - x0);
float z = Vertex::LerpFloat(v0.pos.z, v1.pos.z, t);
float realz = 1.0f / z;
float u = Vertex::LerpFloat(v0.u, v1.u, t);
float v = Vertex::LerpFloat(v0.v, v1.v, t);
Color c = tex->Sample(u * realz, v * realz);
DrawPixel(x, y, c);
x += stepx;
errorValue += dy2;
if (errorValue >= 0)
{
errorValue -= dx2;
y += stepy;
}
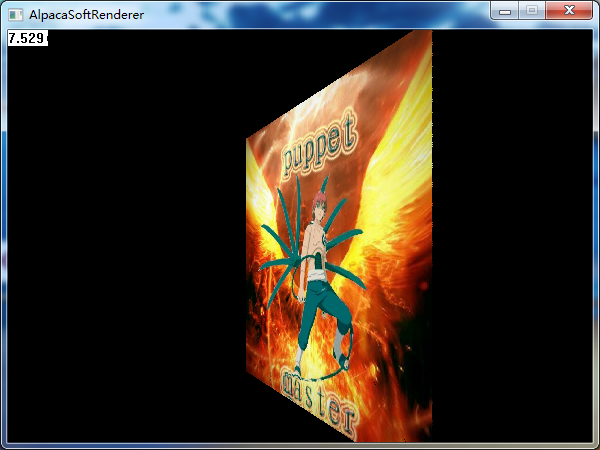
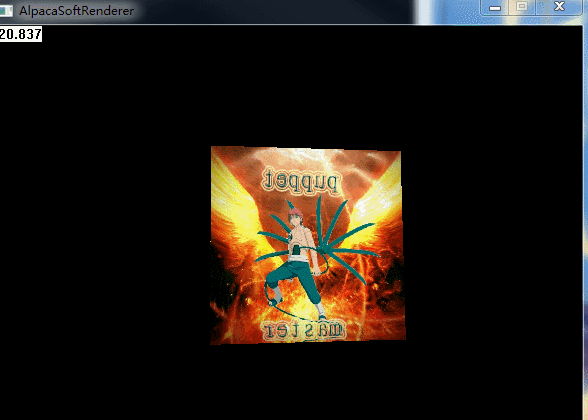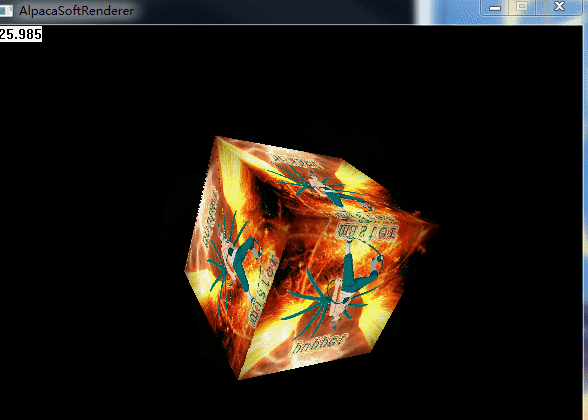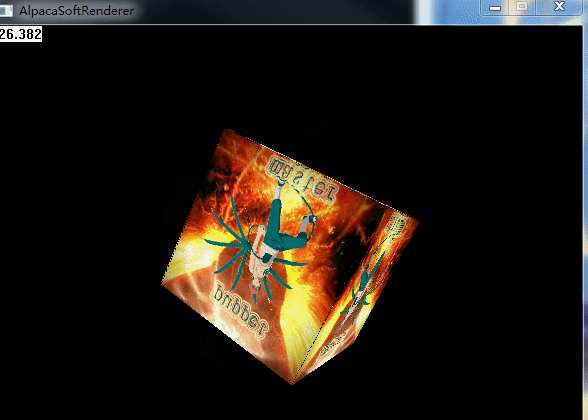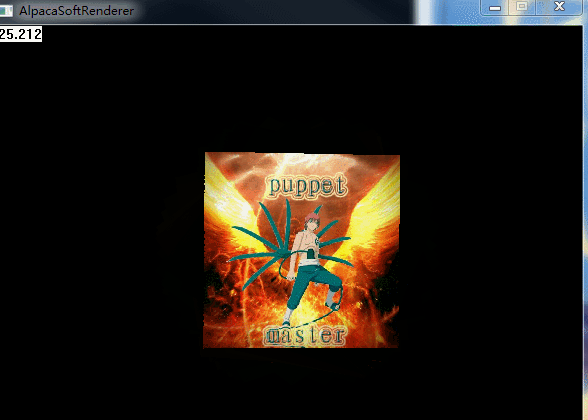
}经过透视校正纹理采样后的效果:
logo的效果也正常啦:
ZBuffer算法
人的需求总是无限的,贴上了图,还是感觉不够爽,毕竟不是一个立体的东西,只是个面片,下面我决定搞个模型进来。不过我不打算引入第三方库,导入fbx那不是软渲染干的事儿了,这个东西在opengl玩更好。所以我手撸了个立方体数据,直接写个顶点缓存,每个点加个uv数据。然后坐等我的立方体出现:
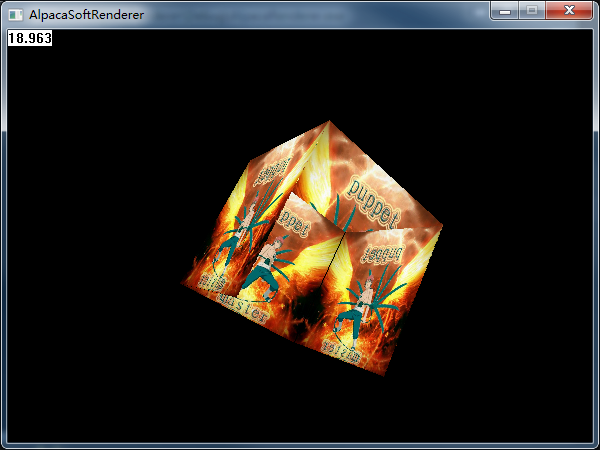
额,好像。。。哪里不太对。。。立方体面之间的遮挡关系错乱了。换句话说,我们没有深度测试,没有办法保证立方体面渲染的顺序,我们需要的是像素精度的深度保证。下面来加一个ZBuffer。
其实ZBuffer的思想比较简单,就是在逐像素增加一个缓存,每次绘制的时候,把当前深度也存储进这个buffer,下次再绘制该像素的时候,先判断一下当前像素的z值,如果比该值小或相等的话,说明离得更近(仅考虑ZTest LEqual)。这种情况下就可以更新当前像素点的颜色值,并且可以选择更新深度缓存。
我们先申请一块屏幕大小的float类型内存:
zBuffer = new float*[deviceHeight];
for (int i = 0; i < deviceHeight; i++)
{
zBuffer[i] = new float[deviceWidth];
}然后每次渲染之前,除掉ClearColorBuffer外,还要把DepthBuffer也Clear掉:
void ApcDevice::Clear()
{
BitBlt(screenHDC, 0, 0, deviceWidth, deviceHeight, NULL, NULL, NULL, BLACKNESS);
//ClearZ
for (int i = 0; i < deviceHeight; i++)
{
for (int j = 0; j < deviceWidth; j++)
{
zBuffer[i][j] = 0.0f;
}
}
}每次绘制时进行深度判断,深度检测失败不进行绘制,深度检测成功此处默认开启ZWrite:
bool ApcDevice::ZTestAndWrite(int x, int y, float depth)
{
//上面只进行了简单CVV剔除,所以还是有可能有超限制的点,此处增加判断
if (x >= 0 && x < deviceWidth && y >= 0 && y < deviceHeight)
{
if (zBuffer[y][x] <= depth)
{
zBuffer[y][x] = depth;
return true;
}
}
return false;
}有了深度缓存,我们的立方体就完整啦:
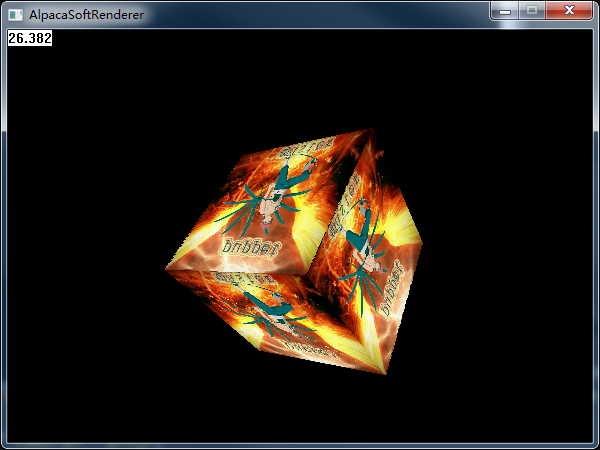
深度缓存,我采用的是1/Z,所以上面的深度默认为0表示无限远。为了更好的效率,我的ZTest实际上放在了计算扫描线时每次插值计算出Z之后立刻就进行深度检测,其实类似于Early-Z,而不是实际上真正渲染时的ZCheck,因为我没有考虑Alpha Test的情况,也不需要考虑分支的问题,直接Cull掉是性能最好的。
int errorValue = dy2 - dx;
for (int i = 0; i <= dx; i++)
{
float t = (x - x0) / (x1 - x0);
float z = Vertex::LerpFloat(v0.pos.z, v1.pos.z, t);
float realz = 1.0f / z;
if (ZTestAndWrite(x, y, realz))
{
float u = Vertex::LerpFloat(v0.u, v1.u, t);
float v = Vertex::LerpFloat(v0.v, v1.v, t);
//Color c = Color::Lerp(v0.color, v1.color, t);
Color c = tex->Sample(u * realz, v * realz);
DrawPixel(x, y, c);
}
x += stepx;
errorValue += dy2;
if (errorValue >= 0)
{
errorValue -= dx2;
y += stepy;
}
}关于深度,其实还有很多可以玩的,不过这么好玩的东西,还是另起一篇blog吧。
最后,再来一张动图:
总结
本文主要实现了基本的光栅化渲染器的一些常见的特性,MVP矩阵变换,简单CVV剔除,视口映射,光栅化,透视校正纹理采样等等。目前还有基本的光照,背面剔除,线框渲染,相机控制等几个是我打算加的。有些算法肯定很古老,而且GPU的具体实现我不敢妄加揣测,填软渲染的坑主要是为了学习的目的,加深一下对渲染知识的理解。其实实现的过程还是蛮有意思的(有点找到了几年前写了第一个命令行版本的2048的那种乐趣,当时自己玩了半宿,一边玩一边手舞足蹈,室友以为我疯了呢),很久不写的C++又温习了一下,再一个方面就是需要考虑优化了,让我清晰地意识到逐像素计算是真的很费很费,面片贴脸的时候基本就跑不动啦!!!项目从开始写的时候,只有一个三角形没经过变换,没有采样,FPS上百,逐渐增加特性之后帧率一度掉到了个位数,后来稍微优化了一下,稳定在了20-25帧,还是有很大的优化的空间的。
代码的话直接开源吧,第一次用Git,如果能您赏个星星什么的就更好啦。本人才疏学浅,如果您发现了什么问题,还望批评指正。