引言
神经网络中的注意力机制(Attention Mechanism)是在计算能力有限的情况下,将计算资源分配给更重要的任务,同时解决信息超载问题的一种资源分配方案。在神经网络学习中,一般而言模型的参数越多则模型的表达能力越强,模型所存储的信息量也越大,但这会带来信息过载的问题。那么通过引入注意力机制,在众多的输入信息中聚焦于对当前任务更为关键的信息,降低对其他信息的关注度,甚至过滤掉无关信息,就可以解决信息过载问题,并提高任务处理的效率和准确性。
这就类似于人类的视觉注意力机制,通过扫描全局图像,获取需要重点关注的目标区域,而后对这一区域投入更多的注意力资源,获取更多与目标有关的细节信息,而忽视其他无关信息。通过这种机制可以利用有限的注意力资源从大量信息中快速筛选出高价值的信息。
注意力机制的核心:使网络关注到更为重要的信息
注意力机制能使卷积神经网络自适应的注意更为重要的信息,因此注意力机制是实现网络自适应注意的重要方式。
一般而言,注意力机制可以分为:通道注意力机制、空间注意力机制、二者的结合
空间注意力机制(关注每个通道的比重):
通道注意力机制(关注每个像素点的比重):SENet
二者的结合:CBAM
SENet(通道注意力机制)
Squeeze-and-Excitation Networks,论文地址
SENet实现示意图如下所示
SENet的核心:获得输入进来的特征层其每个通道的权值,利用其权值大小使网络关注到更为重要的信息。
Progress
1.为卷积算子,用以实现对任意给定的变换。
,其中
∈
,
∈
2.Squeeze:Global Information Embedding
将全局空间信息Squeeze到通道描述符。
Squeeze:对输入进来的特征层U进行Squeeze,采用的方法是全局平均池化(global average pooling)。
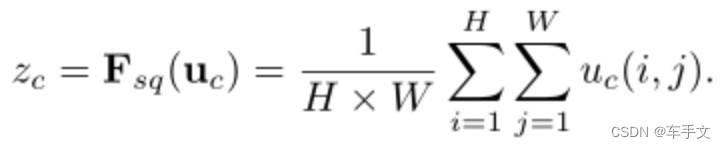
将空间维度 H × W 的特征映射进行融合,生成通道描述符。
3.Excitation:Adaptive Recalibration
自适应调整
(1)Excitation:每个通道都通过一个基于通道依赖的自选门机制来学习特定样本的激活,使其学会使用全局信息并有选择地强调信息特征,抑制不重要的信息特征,采用的激活函数是sigmoid并在其中嵌入ReLU函数用于帮助网络训练并限制模型的复杂性。
通过两个全连接层(FC),第一个全连接层W1神经元个数较少用于降维,第二个全连接层W2神经元个数与输入特征层相同用于升维。通过Sigmoid将权重固定到0~1之间,即获得了输入特征层每个通道的权值(0~1之间)。
(2)Reweight:将Excitation输出的权重通过乘法逐通道加权到输入特征层上。
代码实现
import torch
import torch.nn as nn
import math
class se_block(nn.Module):
def __init__(self, channel, ratio=16):
"""
第一层全连接层神经元个数较少,因此需要一个比例系数ratio进行缩放
"""
super(se_block, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // ratio, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // ratio, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
# b, c, h, w -> b, c, 1, 1 -> b, c
avg = self.avg_pool(x).view(b, c)
# b, c -> b, c // ratio -> b, c -> b, c, 1, 1
fc = self.fc(avg).view(b, c, 1, 1)
return x * fc
SENet就是在卷积层的输入和输出之间添加:global average pooling → FC1 → ReLU → FC2 → sigmoid
SENet缺点是所采用的降维操作会对通道注意力的预测产生负面影响,且获取依赖关系效率低且不必要