论文:Learning Transferable Visual Models From Natural Language Supervision
代码:https://github.com/OpenAI/CLIP
官网:https://openai.com/research/clip
出处:OpenAI
时间:2021.02
贡献:
- 提出了一个基于图文匹配的多模态模型
- 通过对图像和文本的模型联合训练,最大化两者编码特征的 cosine 相似度,来实现图和文的匹配
- 基于图文匹配的模型比直接学习文本内容的模型效率高很多
简介:
- CLIP 是由 OpenAI 开源的基于对比学习的大规模(4 亿个图文 pairs)图文预训练模型
- 图像和文本的编码器都使用 Transformer,使用余弦相似度来衡量两者编码特征的距离
- 文本描述使用的英文
一、背景
从原始文本中直接学习的 pre-training 的方法在过去几年中让 NLP 产生了很大的变革
开发 text-to-text 来实现一个标准的输入输出能够使得 task-agnostic 结构零样本迁移到下游的数据集上,而不需要特定的输出头或特定的数据集。
这也表明,在超大文本数据集上使用预训练方法的效果超过了使用带标注的 NLP 数据集训练的效果。
那么在计算机视觉领域是否也能使用超大规模的预训练数据来达到类似的效果呢
一般的计算机视觉任务都是基于设定好的类别来做的,这会限制模型的泛化性,比如无法识别没有定义过的类别。
NLP 和 CV 的一个巨大的 gap 在于尺度!
本文作者是如何做的:
- 研究了使用大规模的自然语言处理的数据集来训练图像分类器能达到什么效果
- 即在互联网上搜集了大概 4 亿的 image-text pairs 数据集,然后从头开始训练 ConvVIRT,本文称为 CLIP(Contrastive Language-Image Pre-training),能够高效的从自然语言中获得监督信号
- 作者通过训练 8 个模型来研究 CLIP 的可伸缩性
- 作者发现,CLIP 和 GPT 家族很类似,会在 pre-training 阶段学习很多任务,如 OCR、定位、动作识别等
- 作者在 30 多个数据集上进行了 zero-shot 迁移能力的测试,发现其能够达到使用监督学习的效果
二、方法
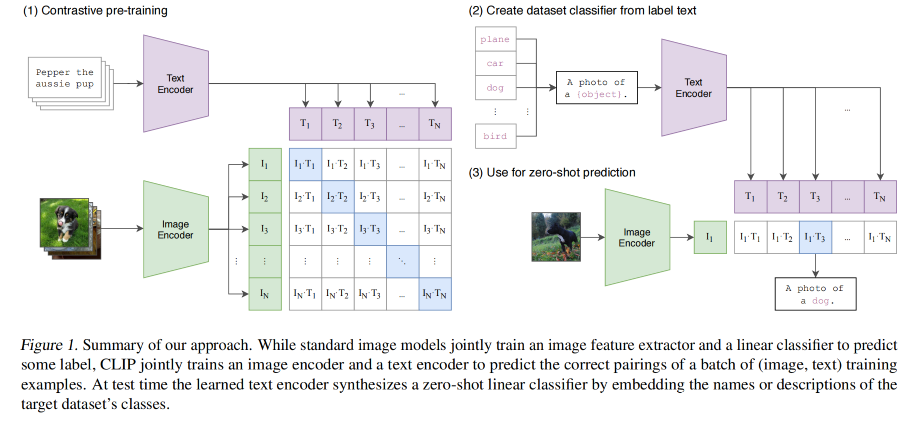
2.1 使用自然语言来监督训练
本文方法的一个核心点在于从自然语言的监督信息中学习感知能力
从自然语言中学习的好处:
- 对图像分类来说,和标准的 label 相比,自然语言能够提供更多信息
- 因为不需要将模型构建成一个 1-of-N 的投票选择模式,而是能够从大量互联网文本中包括的更丰富的监督中学习
- 从自然语言中学习不仅仅学习一种特征表示,而是还能将特征表示和语言联合起来,从而实现更灵活的零样本迁移
2.2 建立一个超大数据集
作者构建了一个新的数据集 WIT(WebImageText),其中包括 4 亿对(图像,文本)在互联网上公开可获得的来源。
2.3 选择预训练模型
现有的很多计算机视觉模型非常耗费计算资源,所以训练的效率很重要,更何况要使用自然语言作为监督信号,这样会比 ImageNet 中使用 1000 个 label 来训练的难度更大。
作者首先尝试了类似于 VirTex 的方法,从头联合训练图像的 CNN 和文本的 transformer 模型,预测每个图像的准确描述。
但如图 2 所示,文本 transformer 模型需要 6300 万参数,是 ResNet-50 这个 image encoder 计算量的 2 倍,学习识别 Imagenet 的类别比其他基于 bag-of-words 的方法低 3 倍。

由于每个图像的描述是不同的,同一个图像的描述也可能是多种多样的,所以要完全按照自然语言作为学习的 label (即学习其描述中的每个单词)的话难度非常大
所以就出现了使用对比学习的方法
现有的很多生成模型也能实现高质量的图像描述,但在相同描述水平的前提下,生成模型比对比模型计算量更高
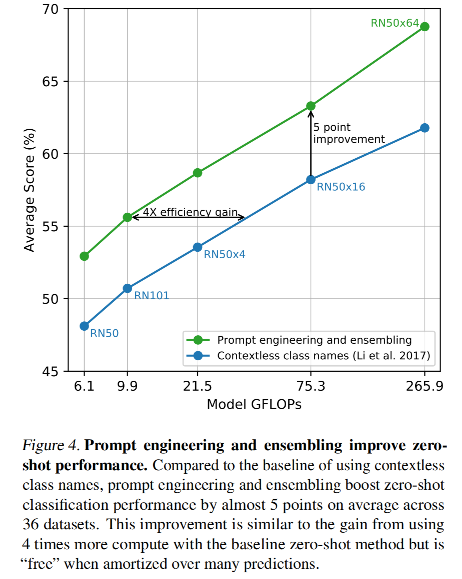
所以,本文提出的训练系统将 image-to-text 构建成了一个更简单的任务,将自然语言描述的 text 看成一个整体,去学习和哪个 image 来匹配,而非学习 text 中的每个 word。这样的思路将在 Imagenet 上的零样本迁移学习速度提升了 4x
CLIP 的思路:
- 给定一个 batch,包含 N 对儿(image,text)
- CLIP 的训练目标是预测一个 NxN 的可能配对的矩阵
- 所以 CLIP 是要学习多模态的 embedding,同时训练 image encoder 和 text encoder,来最大化一个 batch 内真实的 N N N 个(image,text)pairs 的 cosine 相似度,最小化一个 batch 内其他 N 2 − N N^2-N N2−N 个非真实匹配的(image,text)pairs 的 cosine 相似度
- 以对称性的 cross entropy loss 来优化这些相似性得分
如图 3 展示了 CLIP 的伪代码:

2.4 模型缩放和选择
在 image encoder 模型的选择上,作者考虑了两个结构:
- ResNet-50
- ViT
text encoder 使用的就是 transformer 结构,base size 是 63M-parameter,12 层,8 个 attention head
之前的 CV 研究中通常使用缩放模型的 width 和 depth 来实现对模型大小的缩放,本文也类似。
对 text encoder,作者只缩放模型的 width
三、效果
零样本迁移的能力
表 1 对比了 Visual N-Grams 和 CLIP 在 3 个不同数据集上的效果
Visual N-Grams 在 ImageNet 上的效果为 11.5% ,而 CLIP 达到了 76.2%,和经过监督训练的 ResNet50 都差不多了
CLIP 的 top-5 acc 达到了 95%,和 Inception-v4 差不多
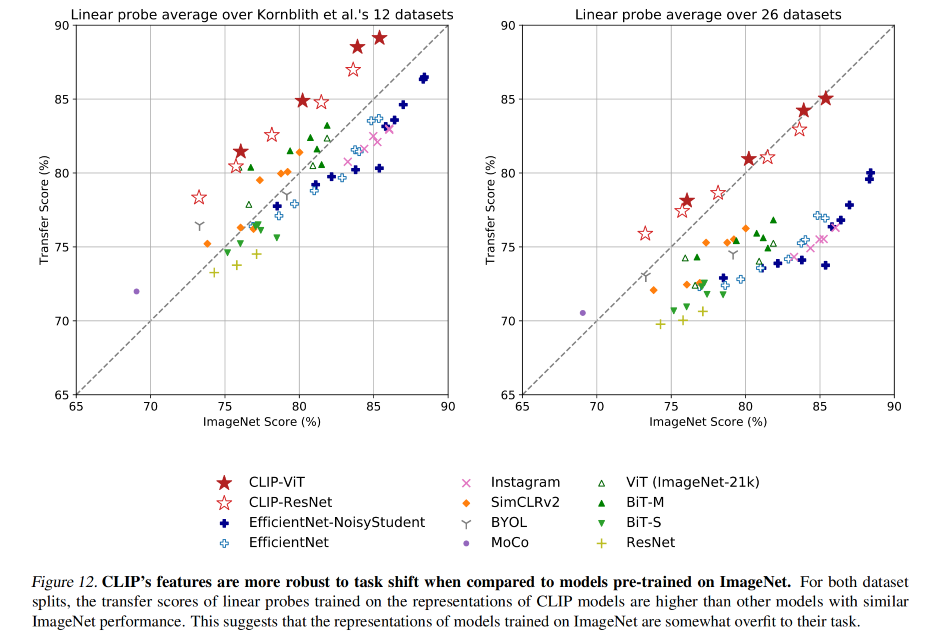
这表明了 CLIP 在分类任务上有很好的零样本迁移能力

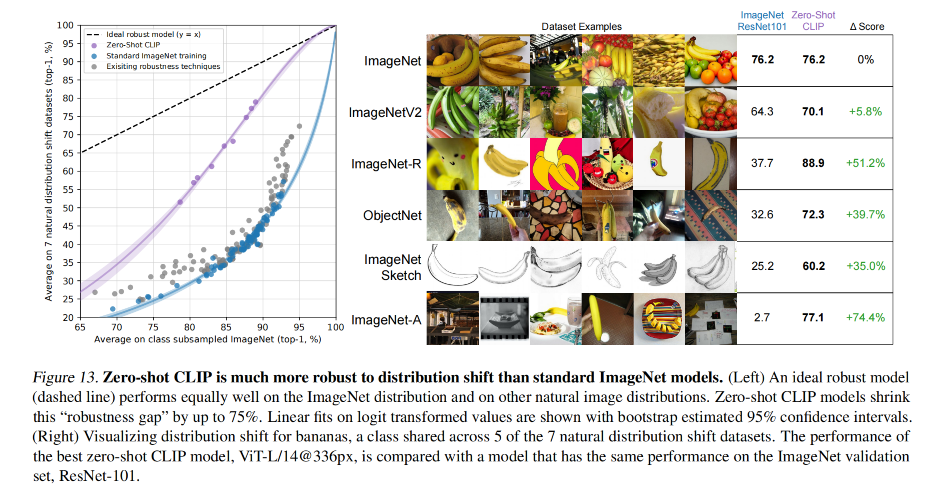
下图是官网上展示的在 ImageNet 数据集上使用 ResNet101 和 CLIP ViT-L 的对比效果:
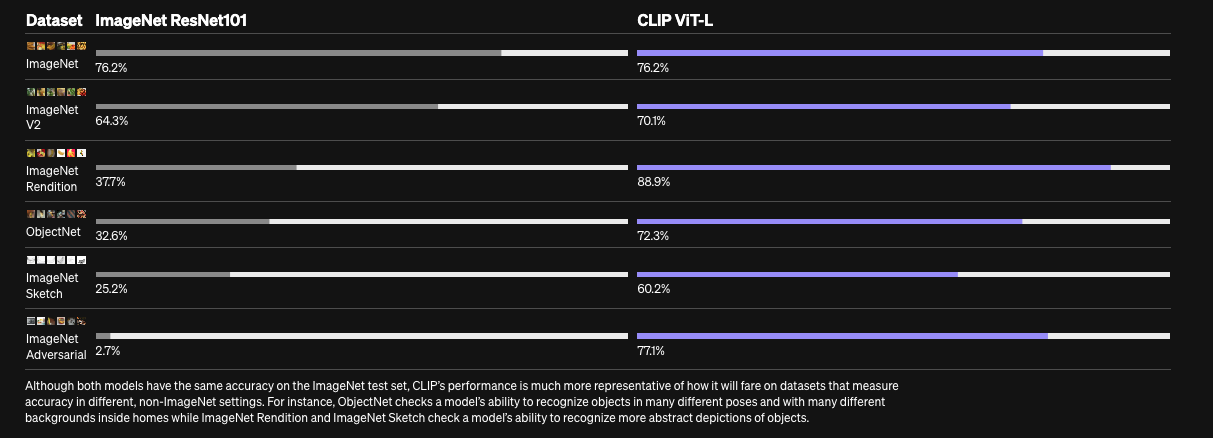
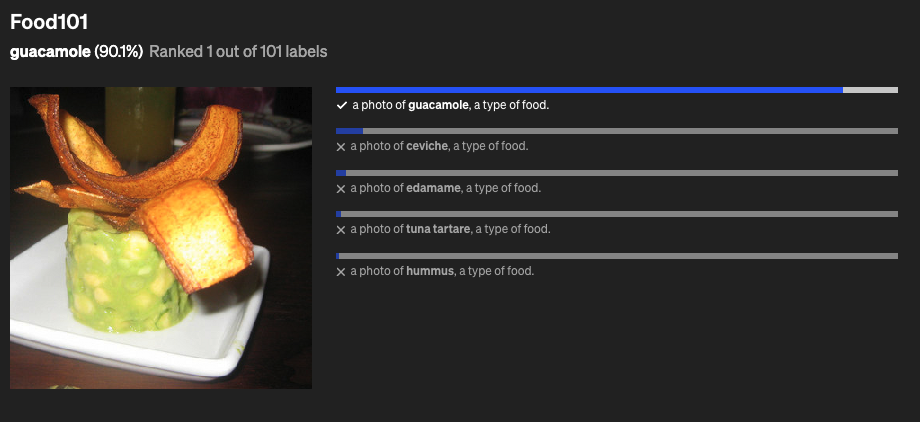
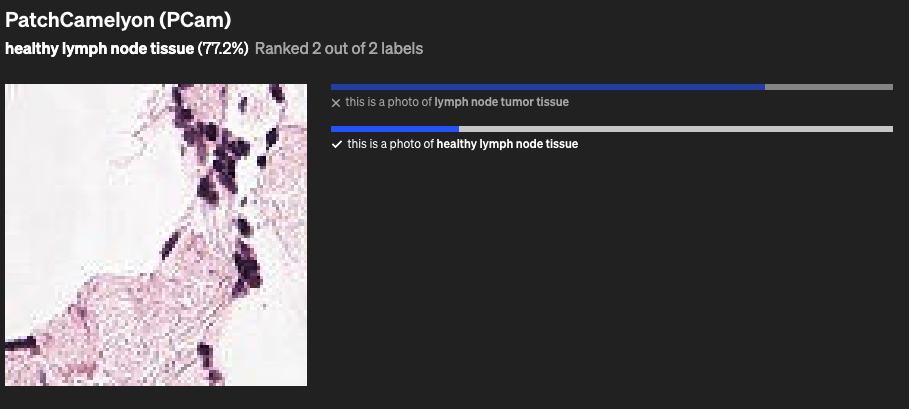
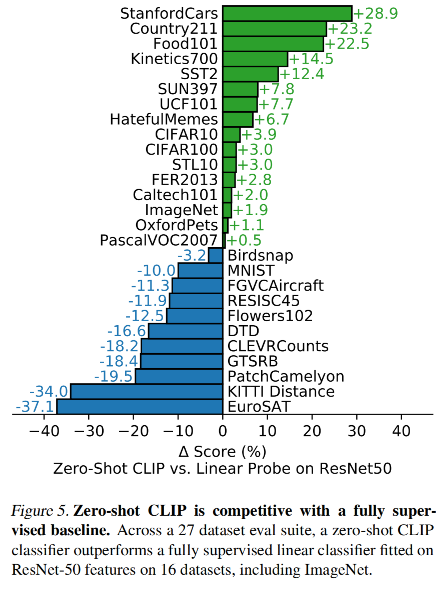
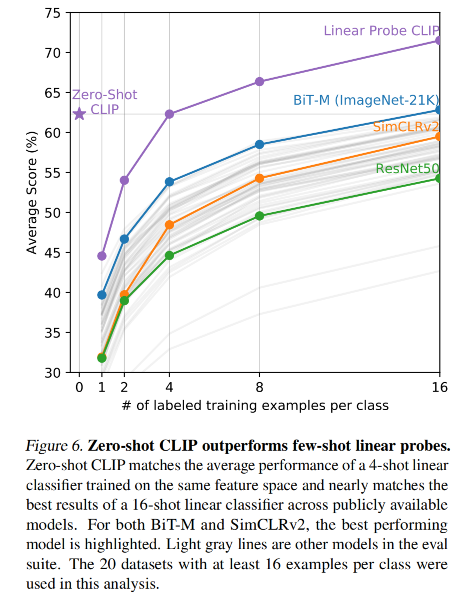
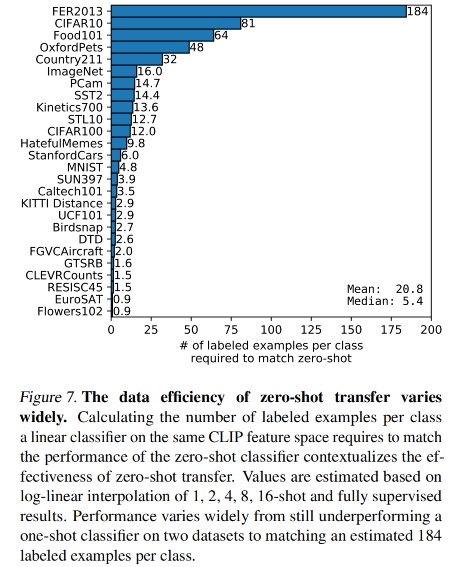
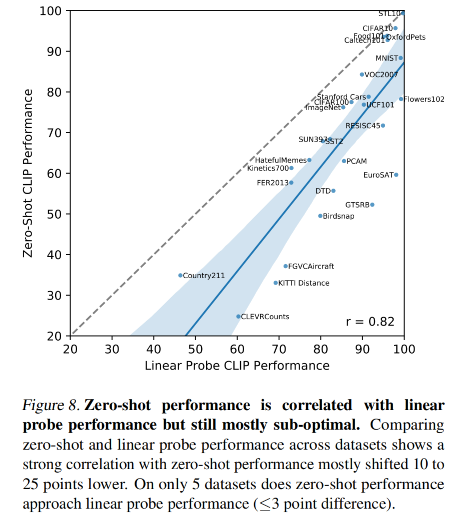
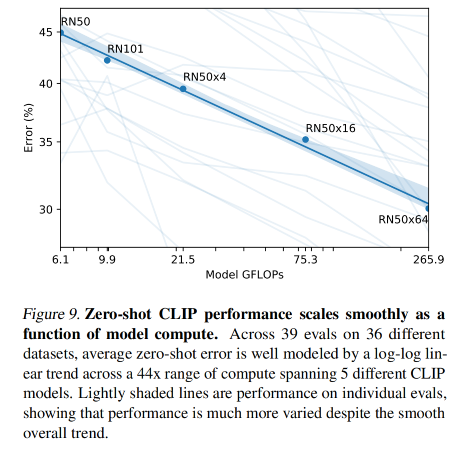
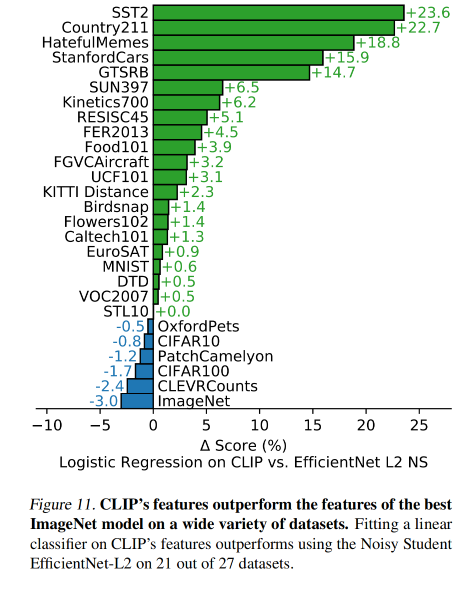
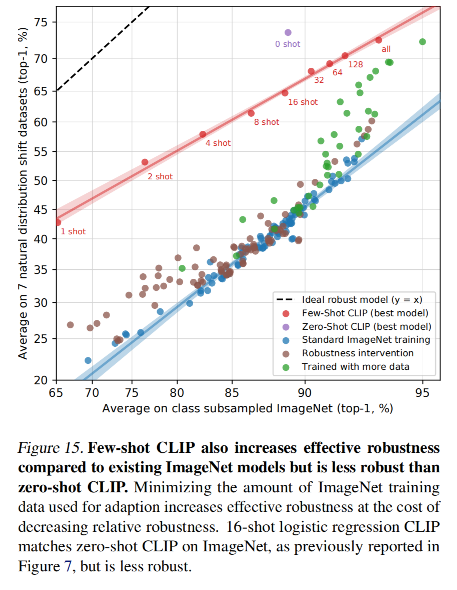
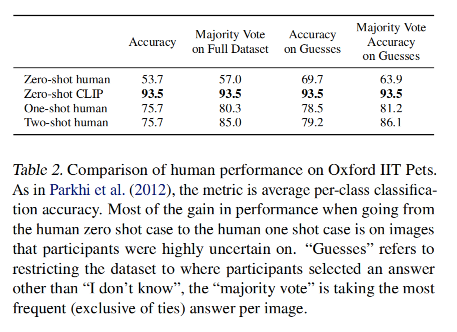
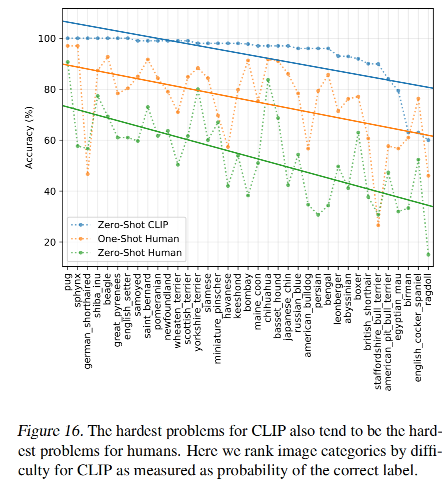
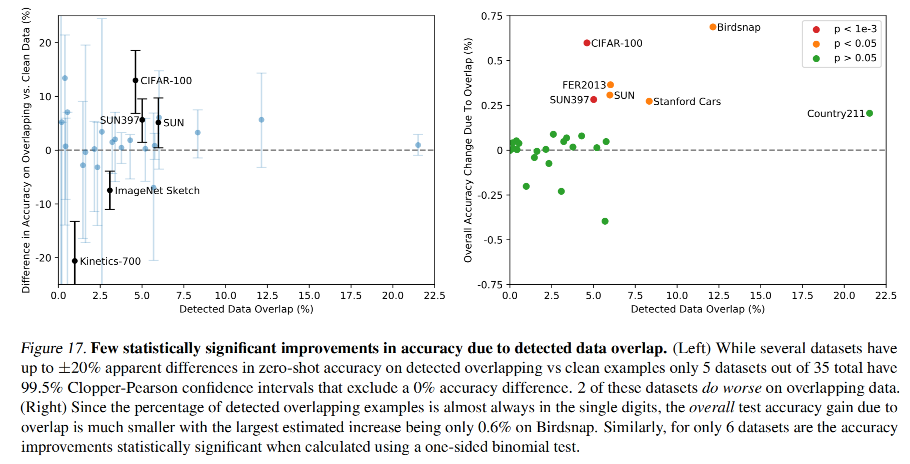
CLIP 在一些数据集上的效果: