代码的第一部分是导入所需要的库,包括 pytesseract 和 PIL 中的 Image。pytesseract 是一个开源的 OCR(光学字符识别)库,可以用来识别图像中的文字。PIL(Python Imaging Library)是一个用于图像处理的库。
接下来是定义了一个函数 demo(),该函数用来执行图像识别操作。
在 demo() 函数中,首先使用 Image.open() 方法打开了名为 “3.png” 的图片,将其赋值给变量 image。
然后,使用 pytesseract.image_to_string() 方法对 image 进行识别。其中,通过 lang=‘chi_sim’ 指定识别语言为中文。
最后,使用 print() 函数将识别出的文本打印输出。
在代码的主程序部分,通过 if name == ‘main’: 判断是否是直接运行该脚本,如果是,则调用 demo() 函数进行图像识别。
需要注意的是,运行这段代码前需要确保已经安装了 pytesseract 库和其它相关的依赖库,同时需要下载并安装中文语言包和其它必要的训练数据。
这两个代码都可以
# -*- coding: utf-8 -*-
"""
Created on Tue Oct 24 11:03:32 2023
@author: Lenovo
"""
import pytesseract
from PIL import Image
def demo():
# 打开要识别的图片
image = Image.open('3.png')
# 使用pytesseract调用image_to_string方法进行识别,传入要识别的图片,lang='chi_sim'是设置为中文识别,
text = pytesseract.image_to_string(image, lang='chi_sim')
# 输入所识别的文字
print(text)
if __name__ == '__main__':
demo()
from PIL import Image
import pytesseract
# 添加tesseract的路径
pytesseract.pytesseract.tesseract_cmd = r'E:\Tesseract-OCR\tesseract.exe'
"""
image_to_string():如果识别英文或数字可以不必额外参数,如果识别其他语言则需要加上lang参数
lang='chi_sim'表示要识别的是中文简体
没有识别出来时,返回空白
"""
text = pytesseract.image_to_string(Image.open('3.png'), lang='chi_sim')
# 将识别到的文本写入到文件中
with open('output2.txt', 'w', encoding='utf-8') as file:
file.write(text)
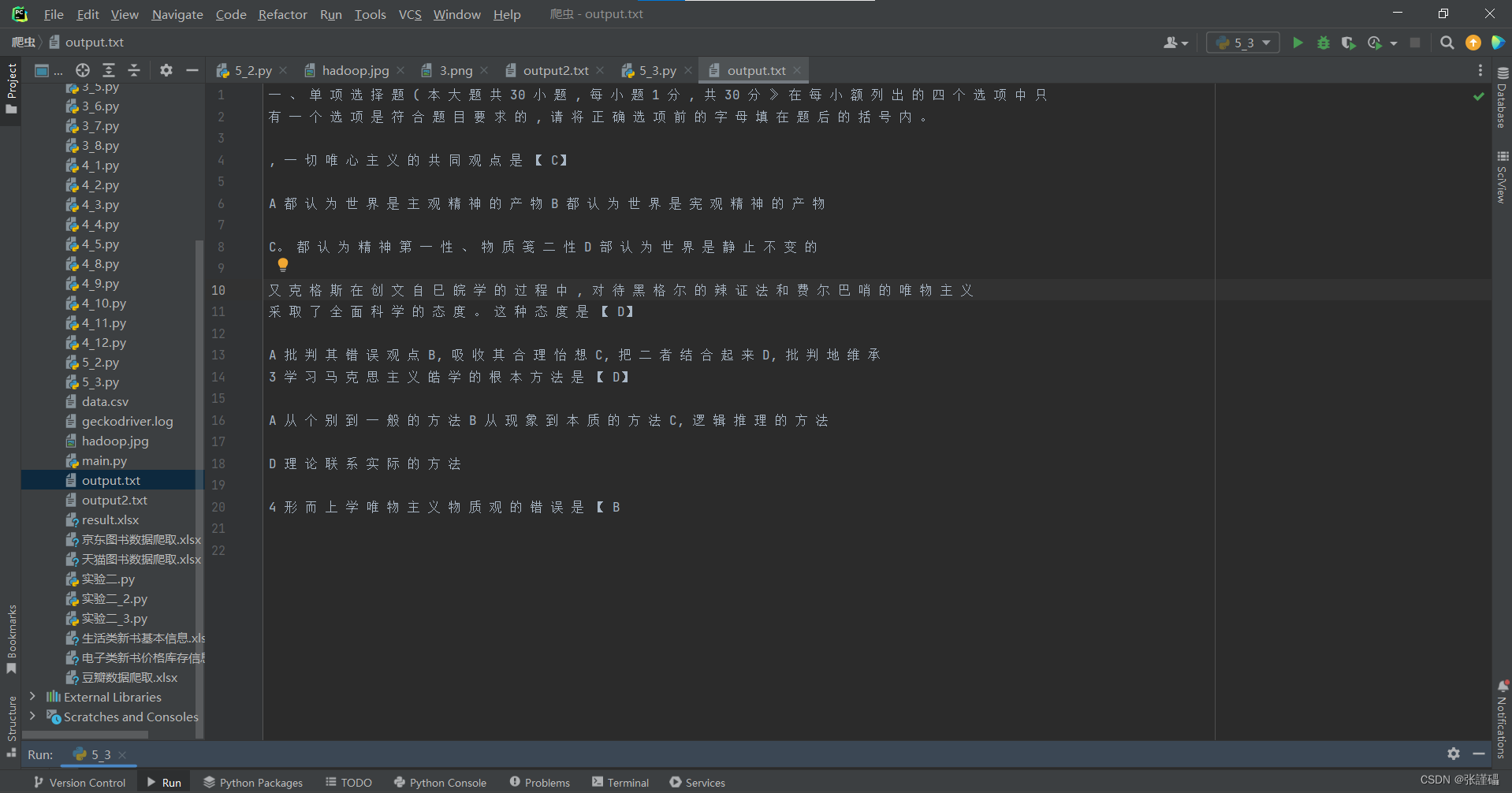
print("文本已生成为output.txt文件。")图片

第一个代码会直接输出

第二个代码会生成一共文件

打开