环境软件包
1:创建一个CenOS6.8虚拟系统
1.1:选择自定义

1.2:选择默认

1.3:操作系统选择稍后安装

1.4:系统选择CentOS 6 64位

1.5:根据自己电脑性能选择
(下面全部选择默认)


1.6:改主机名为master








2:安装操作系统
2.1:选择“编辑虚拟机设置”

2.2:选择系统ios映像

2.3:左下角“完成”别忘了

2.4:开机

2.5:选择第一个

2.6:选择skip(鼠标不能用请使用键盘)

2.7:选择右下角next(下一步)

2.8:选择语言,然后选择右下角next

2.9:选择键盘布局,然后选择右下角next

2.10:选择本地硬盘,然后选择右下角next

2.11:选择yes

2.12:设置主机名为master.centos.com,然后选择右下角next

2.13:选择时区,选择Asia/Shanghai,然后选择右下角next

2.14:设置管理员密码,然后选择右下角next

密码过于简单提醒,可以跳过

2.15:选择分区(选择自动分区)


2.16:选择组件

2.17:选择右下角reboot(重启)就安装好了

3:设置固定IP地址
3.1:修改VM软件网络环境


3.2:编辑网卡配置文件
位置:/etc/sysconfig/network-scripts/ifcfg-eth0
1改
BOOTPROTO=static
4.添加
IPADDR=192.168.128.130
NETMASK=255.255.255.0
GATEWAY=192.168.128.2
DNS1=192.168.128.2
3.3:修改完成后重启网卡
service network restart
4:挂载系统映像
mount /dev/sr0 /mnt
5:修改本地yum源
进入yum目录
cd /etc/yum.repos.d/
清空默认yum源
rm -f *
vi yum.repo
在里面写入
[yum]
name=yum
baseurl=file:///mnt
gpgcheck=0
enable=1
6:处理yum源缓存
清理缓存
yum clean all
建立缓存
yum makecache
7:远程连接虚拟机(如果配置正常但连接不了,可以通过下载)
yum install openssh-server
8:安装yum软件
yum install -y vim zip openssh-server openssh-clients lrzsz
我这里比课本多一个lrzsz,这个是远程文件传输工具
9:安装java环境(windows和Linux都要安装)
9.1:Windows的java环境安装

9.1.1:java的jdk安装(jdk=软件开发工具包)
 :9.1.2:java的jre的安装(jre=运行环境)
:9.1.2:java的jre的安装(jre=运行环境)

9.1.3::配置环境变量
1:此电脑右键点击,选择管理

2:进入环境变量配置

3:配置变量
JAVA_HOME
D:\java\jdk

CLASSPATH
,:%JAVA_HOME%\jre\lib\re.jar:,:


4:验证java是否安装完成
进入cmd窗口

输入命令
java -version

5:Windows的java安装教程结束
------------------------------------------------------------------------这是一个华丽的分割线----------------------------------------------------------
9.2:Linux的java安装
我这里用的是xshell远程连接工具
[root@localhost ~]# cd /opt
[root@localhost ~]# rz #上传Linux版java软件包(jdk-7u80-linux-x64.rpm)
[root@localhost opt]# rpm -ivh jdk-7u80-linux-x64.rpm
准备中... ################################# [100%]
正在升级/安装...
1:jdk-2000:1.7.0_80-fcs ################################# [100%]
Unpacking JAR files...
rt.jar...
jsse.jar...
charsets.jar...
tools.jar...
localedata.jar...
jfxrt.jar...
10:修改配置文件
安装软件包
把hadoop-2.6.4.tar.gz上传到master的/opt目录下
并执行
tar -zxf hadoop-2.6.4.tar.gz -C /usr/local
操作过程
cd /usr/local/hadoop-2.6.4/etc/hadoop
vi /etc/hosts #末尾添加以下内容
192.168.128.130 master master.centos.com
192.168.128.131 slave1 slave1.centos.com
192.168.128.132 slave2 slave2.centos.com
192.168.128.133 slave3 slave3.centos.com
10.1备注:一共需要修改8个文件内容详解
cp mapred-site.xml.template mapred-site.xml
1:core-site.xml
核心配置文件,修改主机名和临时文件位置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/log/hadoop/tmp</value>
</property>
</configuration>
2:hadoop-env.sh
配置hadoop运行基本环境,修改jdk的位置
export JAVA_HOME=/usr/java/jdk1.7.0_80
3:yarn-env.sh
配置yarn框架运行环境配置,修改jdk位置
export JAVA_HOME=/usr/java/jdk1.7.0_80
4:mapred-site.xml
修改MapReduce相关配置,修改master机器名
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
5:yarn-site.xml
这个是yarn框架的配置,设置变量
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/hadoop/yarn/local</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/data/tmp/logs</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http//master:19888/jobhistory/logs/</value>
<descripion>URL for job history server</descripion>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
</configuration>
6:slaves
该文件保存了slave节点信息
localhost
slave1
slave2
slave3
7:hdfs-site.xml
hdfs相关配置文件制定NameNode云数据和DataNode数据存储位置和文件块副本个数
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
8:/etc/hosts
主机名及ip地址映射
192.168.128.130 master master.centos.com
192.168.128.131 slave1 slave1.centos.com
192.168.128.132 slave2 slave2.centos.com
192.168.128.133 slave3 slave3.centos.com
11:克隆虚拟机
这一步重复3次命名为slave1,slave2,slave3




给克隆的虚拟机命名

12:配置slave1,slave2,slave3(下面的命令在3个虚拟机都要执行)
12.1:删除文件
rm -rf /etc/udev/rules.d/70-persistent-net.rules
12.2:网络配置
ifconfig -a

红色内容写入网卡配置文件里(两者要对应)
vi /etc/sysconfig/network-scripts/ifcfg-eth0
service network restart

IP地址改为
slave1:192.168.128.131
slave2:192.168.128.132
slave3:192.168.128.133
12.3:修改机器名
vim /etc/sysconfig/network
修改成
slave1机器
NETWORKING=yes
HOSTNAME=slave1.centos.com
slave2机器
NETWORKING=yes
HOSTNAME=slave2.centos.com
slave3机器
NETWORKING=yes
HOSTNAME=slave3.centos.com
修改完成后重启虚拟机
reboot
注意下面的操作需要虚拟机全部开机!!!!
13:配置SSH免密码登录
master机器配置
下面的命令执行后需要按3次enter(回车)键
ssh-keygen -t rsa
下面的是配置免密登录命令
依次输入yes ,root用户密码
ssh-copy-id -i /root/.ssh/id_rsa.pub master
ssh-copy-id -i /root/.ssh/id_rsa.pub slave1
ssh-copy-id -i /root/.ssh/id_rsa.pub slave2
ssh-copy-id -i /root/.ssh/id_rsa.pub slave3
14:配置时间同步
master机器的配置
yum install -y ntp
编辑/etc/ntp.conf取消server开头行,文件末尾添加
restrict 192.168.0.0 mask 255.255.255.0 nomodify notrap
server 127.127.1.0
fudge 127.127.1.0 stratum 10
slave1,slave2,slave3机器
yum install -y ntp
编辑/etc/ntp.conf取消server开头行,文件末尾添加
server master
15:ntp环境配置
15.1:4台机器全部关闭防火墙
关闭防火墙
service iptables stop
永久关闭防火墙
chkconfig iptables off
开启服务
service ntpd start
设置服务开机自动启动
chkconfig ntpd on
slave1,slave2,slave3机器
开启服务
service ntpd start
设置服务开机自动启动
chkconfig ntpd on
同步时间
ntpdate master
16:启动关闭集群
16.1:配置环境变量
master,slave1,slave2,slave3机器的配置
修改/etc/profile文件,追加下面的内容
export HADOOP_HOME=/usr/local/hadoop-2.6.4
export PATH=$HADOOP_HOME/bin:$PATH:/usr/java/jdk1.7.0_80/bin
使配置文件生效
source /etc/profile
下面的命令只需要在master上面执行
格式化NameNode,初始化hadoop的相关配置
hdfs namenode -format
出现以下内容表示格式化成功没有则表示格式化失败
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master.centos.com/192.168.128.130
************************************************************/
16.2:集群启动
进入hadoop安装目录
cd $HADOOP_HOME
sbin/start-dfs.sh #启动hdfs相关服务
第一次启动时会询问yes/no
选择yes

启动yarn相关服务
sbin/start-yarn.sh
启动日志相关文件
sbin/mr-jobhistory-daemon.sh start historyserver
16.3:集群关闭
进入hadoop安装目录
cd $HADOOP_HOME
关闭hdfs相关服务
sbin/stop-dfs.sh
关闭yarn相关服务
sbin/stop-yarn.sh
关闭日志相关文件
sbin/mr-jobhistory-daemon.sh stop historyserver
在启动dfs时报错(使用后可能出现环境变量全部消失)这个报错不影响使用
安装前要关闭服务
master节点安装
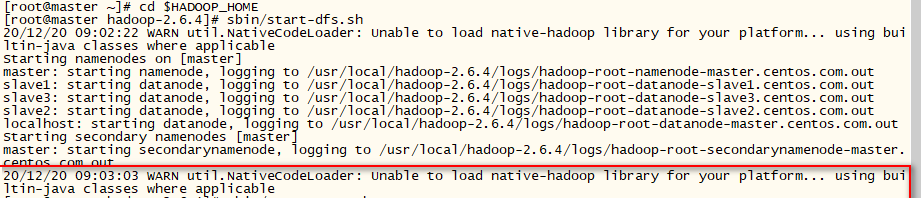
报错原因是:不能加载本地库的WARN
linux默认安装版本是2.12
hadoop需要2.14
查看glibc版本命令
strings /lib64/libc.so.6 | grep GLIBC_

解决过程::
安装glibc-2.14
环境配置
yum install -y gcc wget
安装glibc-2.14
1:使用wget下载glibc安装包
进入·root目录·下进行操作
cd /root
wget http://ftp.gnu.org/gnu/glibc/glibc-2.14.tar.gz
2:解压安装包
tar -xzvf glibc-2.14.tar.gz
3:进入文件夹进行操作
cd glibc-2.14
mkdir build /opt/glibc-2.14
cd build
编译定义目录
../configure --prefix=/opt/glibc-2.14
安装(时间较长请耐心等待)
make
make install
删除原来的原有库链接
rm -rf /lib64/libc.so.6
指定新库链接
LD_PRELOAD=/opt/glibc-2.14/lib/libc-2.14.so ln -s /opt/glibc-2.14/lib/libc-2.14.so /lib64/libc.so.6
如果出现启动节点不见了下面是解决办法
删除格式化产生的配置文件,并重新格式化
rm -rf /data//hadoop/*
重新格式化并启动集群
17:集群的监控
修改本地host文件
文件位置:C:\Windows\System32\drivers\etc

添加以下内容
192.168.128.130 master master.centos.com
192.168.128.131 slave1 slave1.centos.com
192.168.128.132 slave2 slave2.centos.com
192.168.128.133 slave3 slave3.centos.com
17.1监控HDFS
浏览器地址栏输入:http://master:50070/

注释:
(1):Overview
记录了NameNode启动时间,版本号,编译版本等基本信息
(2):Summary
记录集群信息,提供了集群环境的一些信息,从图中可以看见所有DataNode节点的基本存储信息,例如硬盘大小以及有多少被HDFS使用等一些数据信息,同时标注了当前集群环境中DataNode的信息,对活动状态的DataNode也专门做了记录
(3):NameNode Storage
提供了NameNode的信息,最后的State标示此节点为活动节点,可正常提供服务
----------------------------------------------------这是一个华丽的分割线--------------------------------------------------------------
以下菜单可以查看HDFS上面的文件信息

17.2:NameNode节点信息
浏览器地址栏输入:http://master:50070/dfshealth.jsp

注释:
点击Browse the filesystem可以进入文件存储目录

17.3:YARN监控
浏览器地址栏输入:http://master:8088

17.4:日志监控
浏览器地址栏输入:http://master:19888
