MobileVIT学习笔记
MOBILEVIT: LIGHT-WEIGHT, GENERAL-PURPOSE,AND MOBILE-FRIENDLY VISION TRANSFORMER
ABSTRACT
轻型卷积神经网络(CNN)实际上是用于移动视觉任务的。他们的空间归纳偏差允许他们在不同的视觉任务中以较少的参数学习表征。然而,这些网络在空间上是局部的。为了学习全局表示,采用了基于自注意力的视觉变换器(VIT)。与CNN不同,VIT是重量级的。在本文中,我们提出了以下问题:是否有可能结合CNN和ViTs的优势,为移动视觉任务构建一个重量轻、延迟低的网络?为此,我们介绍了MobileViT,一种用于移动设备的轻型通用视觉transformers。**MobileViT从另一个角度介绍了使用Transformer进行全球信息处理的方法。**我们的结果表明,MobileViT在不同的任务和数据集上显著优于基于CNNand和ViT的网络。在ImageNet-1k数据集上,MobileViT以大约600万个参数达到了78.4%的最高精度,对于类似数量的参数,其精度分别比MobileNetv3(基于CNN)和DeIT(基于ViT)高3.2%和6.2%。在MS-COCO目标检测任务中,对于相同数量的参数,MobileViT比MobileNetv3的准确率高5.7%。我们的源代码是开源的,可从以下网址获得:https://github.com/apple/ml-cvnets.
1 INTRODUCTION
基于自注意力的模型,特别是视觉变换器(VIT;图1a;Dosovitskiy等人,2021),是卷积神经网络(CNN)学习视觉表示的替代方法。简而言之,ViT将图像划分为一系列不重叠的面片,然后使用transformers中的多头自注意力学习面片间表示(V aswani等人,2017)。总的趋势是增加ViT网络中的参数数量以提高性能(例如,Touvron等人,2021a;Graham等人,2021;Wu等人,2021)。然而,这些性能改进是以模型大小(网络参数)和延迟为代价的。许多真实世界的应用程序(例如增强现实和自主轮椅)需要视觉识别任务(例如,对象检测和语义分割)在资源受限的移动设备上及时运行**。为了有效,此类任务的ViT模型应该重量轻、速度快。即使ViT模型的模型尺寸减小以匹配移动设备的资源约束,其性能也明显低于轻型CNN**。例如,对于约500-600万的参数预算,DeIT(Touvron等人,2021a)的精度比MobileNet V3(Howard等人,2019)低3%。因此,需要设计轻型ViT模型。
轻型CNN为许多移动视觉任务提供了动力。然而,基于ViT的网络仍远未在此类设备上使用。与易于优化和与任务特定网络集成的轻量CNN不同,ViT重量重(例如,ViT-B/16与MobileNetv3:86与750万个参数),更难优化(肖等人,2021),需要大量的数据扩充和L2正则化以防止过拟合(Touvron等人,2021a;王等人,2021),并且需要昂贵的解码器用于下游任务,特别是对于密集预测任务。例如,基于ViT的分割网络(Ranftl等人,2021)学习了约3.45亿个参数,并实现了与基于CNN的网络DeepLabv3(Chen等人,2017)类似的性能,具有5900万个参数。在基于ViT的模型中需要更多的参数,可能是因为它们缺乏特定于图像的归纳偏差,这是CNN固有的(Xiao等人,2021)。为了建立稳健和高性能的ViT模型,结合卷积和变压器的混合方法正在获得兴趣(肖等人,2021;d’Ascoli等人,2021;陈等人,2021b)。 然而,这些混合模型仍然很重,并且对数据增加很敏感。例如,删除CutMix(Zhong等人,2020)和DeIT样式(Touvron等人,2021a)数据增强会导致Heo等人(2021)的ImageNet精度显著下降(78.1%至72.4%)。
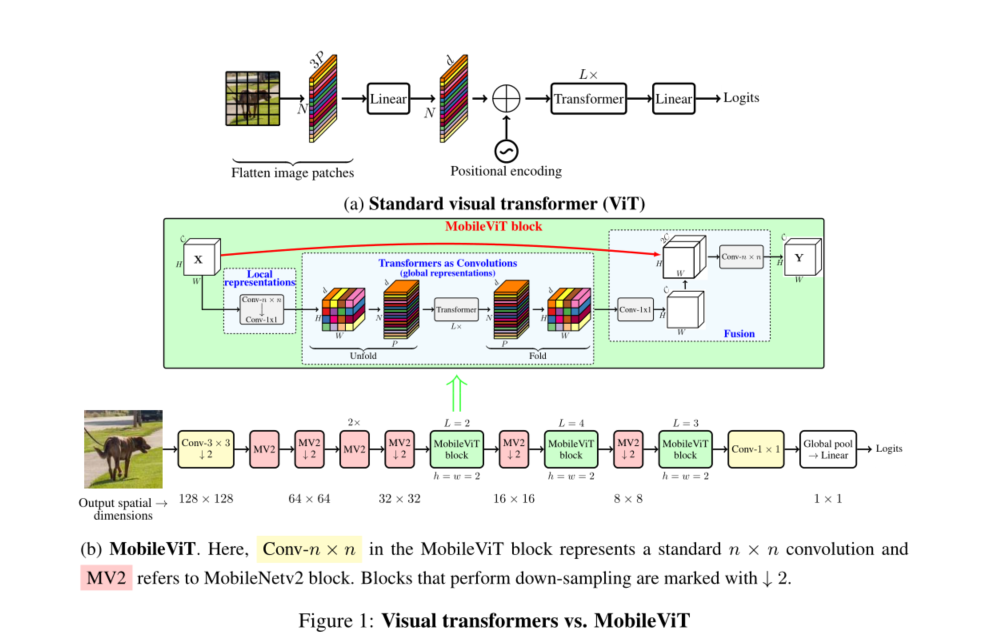
如何结合CNN和transformers的优势来构建用于移动视觉任务的ViT模型仍然是一个悬而未决的问题。移动视觉任务需要轻量、低延迟和精确的模型,以满足设备的资源约束,并且是通用的,因此可以应用于不同的任务(例如分割和检测)。请注意,浮点运算(FLOP)不足以在移动设备上实现低延迟,因为FLOP忽略了几个重要的推断相关因素,例如内存访问、并行度和平台特性(Ma等人,2018)。例如,Heo等人(2021)基于ViT的方法PiT比DeIT(Touvron等人,2021a)具有3×更少的浮点运算,但在移动设备上具有类似的推理速度(iPhone-12上的DeIT与PiT:10.99 ms与10.56 ms)。因此,**本文的重点不是优化FLOPs1,而是为移动视觉任务设计一个重量轻(§3)、通用(§4.1和§4.2)和低延迟(§4.3)的网络。**我们使用MobileViT实现了这一目标,它结合了CNN(例如,空间归纳偏差和对数据增强的敏感性较低)和VIT(例如,输入自适应加权和全局处理)的优点。具体来说,我们引入了MobileViT块,该块在张量中有效地编码局部和全局信息(图1b)。与ViT及其变体(有卷积和无卷积)不同,MobileViT从不同的角度学习全局表示。**标准卷积涉及三种操作:展开、局部处理和折叠。**MobileViT块用使用transformers的全局处理替换卷积中的局部处理。这使得MobileViT块具有类似CNN和ViT的属性,这有助于它用更少的参数和简单的训练方法(例如基本增强)学习更好的表示。据我们所知,这是第一项表明轻量级VIT可以通过简单的训练方法在不同的移动视觉任务中实现轻量级CNN级性能的工作。对于大约500-600万的参数预算,MobileViT在ImageNet-1k数据集上达到了78.4%的最高精度(Russakovsky等人,2015),比MobileNetv3更精确3.2%,并且有一个简单的训练配方(MobileViT与MobileNetv3:300与600个时代;1024与4096个批量)。我们还观察到,当MobileViT用作高度优化的移动视觉任务特定架构中的功能主干时,性能显著提高。将MNASNet(Tan等人,2019)替换为MobileViT作为SSDLite的特征主干(Sandler等人,2018),产生了更好的(+1.8%mAP)和更小的(1.8×)检测网络(图2)。

2 RELATED WORK
Light-weight CNNs.
CNN中的基本构建层是标准卷积层。由于该层的计算成本很高,因此提出了几种基于因子分解的方法,使其重量轻且便于移动(例如,Jin等人,2014;Chollet,2017;Mehta等人,2020)。其中,Chollet(2017)的可分离卷积引起了人们的兴趣,并在最先进的轻型CNN中广泛用于移动视觉任务,包括MobileNet(Howard等人,2017;Sandler等人,2018;Howard等人,2019)、ShuffleNet V2(Ma等人,2018)、ESPNetv2(Mehta等人,2019)、MixNet(Tan&Le,2019b)和MNASNet(Tan等人,2019)。这些重量轻的CNN功能齐全,易于训练。例如,这些网络可以轻松替换现有任务特定模型(例如,DeepLabv3)中的重量级主干(例如,ResNet(He等人,2016))以减少网络大小并改善延迟。尽管有这些优点,但这些方法的一个主要缺点是它们在空间上是局部的。本文将变压器视为卷积;允许利用卷积(如多功能和简单训练)和变换器(如全局处理)的优点来构建轻型(§3)和通用(§4.1和§4.2)VIT。
Vision transformers.
Dosovitskiy等人(2021)将Vaswani等人(2017)的transformers应用于大规模图像识别,并表明通过超大规模数据集(例如JFT-300M),ViTs可以在没有图像特定感应偏差的情况下实现CNN级精度。通过广泛的数据扩充、重L2正则化和蒸馏,可以在ImageNet数据集上训练VIT,以实现CNN级性能(Touvron等人,2021a;b;Zhou等人,2021)。然而,与CNN不同,VIT的优化能力不达标,难以训练。随后的工作(例如,Graham等人,2021;Dai等人,2021;Liu等人,2021;Wang等人,2021;Yuan等人,2021b;Chen等人,2021b)表明,这种不合标准的优化是由于VIT中缺乏空间感应偏差。在VIT中使用卷积结合这种偏差可以提高它们的稳定性和性能。已经探索了不同的设计,以获得卷积和变压器的好处。例如,肖等人(2021)的ViT-C为ViT添加了一个早期卷积干。CvT(Wu等人,2021)修改了变压器中的多头注意,并使用深度可分离卷积代替线性投影。BoTNet(Srinivas等人,2021)用多头注意力取代了ResNet瓶颈单元中的标准3×3卷积。ConViT(d’Ascoli等人,2021)使用选通位置自注意力结合了软卷积感应偏差。PiT(Heo等人,2021)使用基于深度卷积的池层扩展了ViT。虽然这些模型可以通过广泛的扩展实现与CNN的竞争性能,但大多数模型都很重。例如,PiT和CvT比EfficientNet(Tan&Le,2019a)学习的参数多6.1倍和1.7倍,并在ImageNet1k数据集上分别达到类似的性能(top-1精度约81.6%)。此外,当这些模型被缩小以构建轻型ViT模型时,其性能明显低于轻型CNN。对于大约600万的参数预算,PiT的ImageNet-1k精度比MobileNetv3低2.2%。
Discussion
与普通VIT相比,卷积和变压器的结合产生了稳健和高性能的VIT。然而,一个悬而未决的问题是:如何结合卷积和变换器的优势,为移动视觉任务构建轻量级网络?本文的重点是设计轻量级ViT模型,该模型优于具有简单训练配方的最先进模型。为此,我们引入了MobileViT,它结合了CNN和ViTs的优势,构建了一个轻量级、通用和移动友好的网络。MobileViT带来了一些新的观察结果。(i) 更好的性能:对于给定的参数预算,MobileViT 模型与现有的轻型CNN相比,在不同的移动视觉任务(§4.1和§4.2)中实现更好的性能。(ii)泛化能力:泛化能力是指训练和评估指标之间的差距。对于具有相似训练指标的两个模型,具有更好评估指标的模型更具普遍性,因为它可以在看不见的数据集上进行更好的预测。与之前的ViT变体(有卷积和无卷积)不同,与CNN相比,即使在大量数据增加的情况下,其泛化能力也较差(Dai等人,2021),MobileViT表现出更好的泛化能力(图3)。(iii)鲁棒性:一个好的模型应该对超参数(例如数据增强和L2正则化)具有鲁棒性,因为调整这些超参数需要耗费时间和资源。与大多数基于ViT的模型不同,MobileViT模型使用基本增广进行训练,并且对L2正则化不太敏感(§C)。
3 MOBILEVIT: A LIGHT-WEIGHT TRANSFORMER
图1a所示的标准ViT模型重塑了输入 X ∈ R H × W × C X∈ R^{H×W×C} X∈RH×W×C为一系列扁平面片 X f ∈ R N × P C X_f∈ R^{N×PC} Xf∈RN×PC,将其投影到固定的d维空间 X p ∈ R N × d X_p∈R^{N×d} Xp∈RN×d,然后使用L变换块堆栈学习 inter-patch表示。视觉变换器中自注意力的计算成本为 O ( N 2 d ) O(N^2d) O(N2d)。这里,C、H和W分别表示张量的通道、高度和宽度,P=wh是高度为H、宽度为W的面片中的像素数,N是面片数。由于这些模型忽略了CNN固有的空间归纳偏差,因此需要更多参数来学习视觉表示。例如,基于ViT的网络DPT(Dosovitskiy等人,2021)比基于CNN的网络DeepLabv3(Chen等人,2017)多学习6倍的参数,以提供类似的分割性能(DPT与DeepLabv3:345 M与59 M)。此外,与CNN相比,这些模型表现出不合标准的优化能力。这些模型对L2正则化很敏感,需要大量的数据增强以防止过度拟合(Touvron等人,2021a;Xiao等人,2021)。
本文介绍了一种轻型ViT模型MobileViT。**其核心思想是学习将transformers作为卷积的全局表示。**这使我们能够隐式地将卷积特性(例如,空间偏差)纳入网络,使用简单的训练方法(例如,基本增强)学习表示,并轻松地将MobileViT与下游架构(例如,用于分割的DeepLabv3)集成。
3.1 MOBILEVIT ARCHITECTURE
MobileViT block
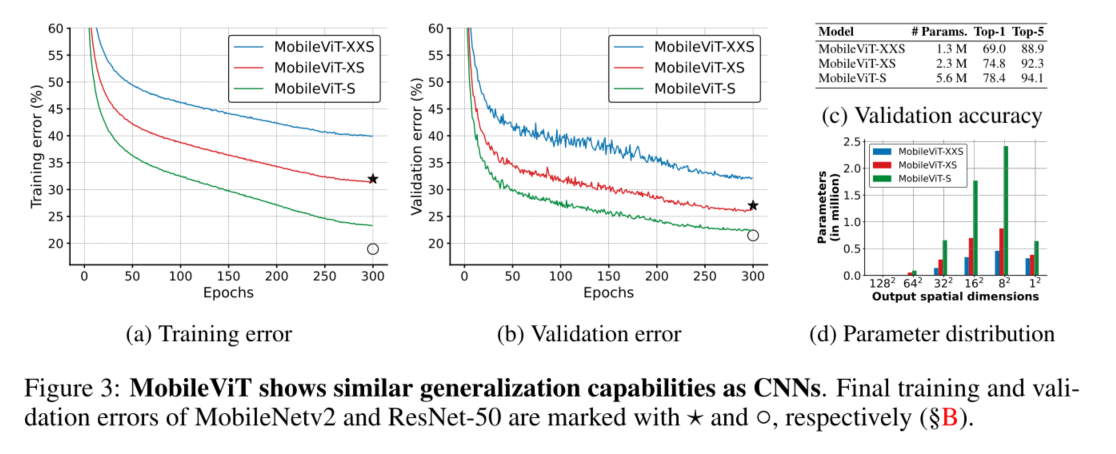
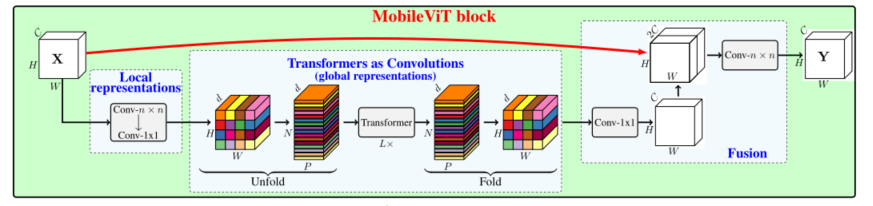
MobileViT块如图1b所示,旨在用较少的参数在输入张量中建模局部和全局信息。形式上,对于给定的输入张量 X ∈ R H × W × C X∈R^{H×W×C} X∈RH×W×C,MobileViT应用n×n标准卷积层,然后是逐点(或1×1)卷积层来生成 X L ∈ R H × W × d X_L∈ R^{H×W×d} XL∈RH×W×d。n×n卷积层编码局部空间信息,而逐点卷积通过学习输入通道的线性组合将张量投影到高维空间(或d维,其中d>C)。
使用MobileViT,我们希望在具有H×W有效感受野的同时对长范围非局部依赖进行建模。广泛研究的长范围依赖建模方法之一是(dilated convolutions)膨胀卷积。然而,这种方法需要仔细选择扩张率。否则,权重应用于填充零,而不是有效的空间区域(Y u&Koltun,2016;Chen等人,2017;Mehta等人,2018)。另一个有希望的解决方案是自我注意力(Wang等人,2018;Ramachandran等人,2019;Bello等人,2019;Dosovitskiy等人,2021)。在自注意力方法中,具有多头自注意力的视觉变换器(VIT)对于视觉识别任务是有效的。然而,VIT重量很重,并表现出低于标准的优化能力。这是因为VIT缺乏空间归纳偏差(Xiao等人,2021;Graham等人,2021)。
为了使MobileViT能够学习具有空间归纳偏差的全局表示,我们 X L X_L XL展开为N个不重叠的平坦面片 X U ∈ R P × N × d X_U∈ R^{P×N×d} XU∈RP×N×d。这里,P=wh,N=HW/P是面片数,h≤ n和w≤ n分别是面片的高度和宽度。对于每个p∈ {1,··,P},通过应用transformers来获得对片间关系进行编码 X G ∈ R P × N × d X_G∈ R^{P×N×d} XG∈RP×N×d为:
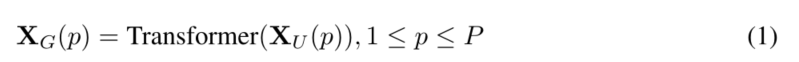
与丢失像素空间顺序的VIT不同,MobileViT既不会丢失面片顺序,也不会丢失每个面片内像素的空间顺序(图1b)。因此,我们可以折叠 X G ∈ R P × N × d X_G∈ R^{P×N×d} XG∈RP×N×d以获得 X F ∈ R H × W × d X_F∈R^{H×W×d} XF∈RH×W×d。然后,使用逐点卷积将 X F X_F XF投影到低C维空间,并通过级联操作与X组合。然后使用另一个n×n卷积层来融合这些级联特征。注意,由于 X U ( p ) X_U(p) XU(p)使用卷积对n×n区域的局部信息进行编码,而 X G ( p ) X_G(p) XG(p)对p位置的p个面片上的全局信息进行编码,所以 X G X_G XG中的每个像素可以对 X X X中所有像素的信息进行编码,如图4所示。因此,MobileViT的整体有效感受野为H×W。

**Relationship to convolutions. **
**标准卷积可以看作是三个连续操作的堆栈:(1)展开,(2)矩阵乘法(学习局部表示)和(3)折叠。**MobileViT块与卷积相似,因为它也利用了相同的构建块。MobileViT块用更深的全局处理(变压器层堆栈)取代卷积中的局部处理(矩阵乘法)。因此,MobileViT具有卷积性质(例如,空间偏差)。因此,MobileViT块可以被视为卷积变压器。我们有意设计的简单设计的一个优点是,卷积和变压器的低级别高效实现可以开箱即用;允许我们在不同的设备上使用MobileViT,而无需任何额外的努力。
Light-weight.
MobileViT块使用标准卷积和变换器分别学习局部和全局表示。由于之前的工作(如Howard et al.,2017;Mehta et al.,2021a)表明,使用这些层设计的网络重量很重,因此自然会产生一个问题:为什么MobileViT重量很轻?我们认为,问题主要在于使用transformers学习全局表示。对于给定的面片,以前的工作(例如,Touvron等人,2021a;Graham等人,2021)通过学习像素的线性组合将空间信息转换为潜在信息(图1a)。然后使用transformers学习补丁间信息,对全局信息进行编码。因此,这些模型失去了CNN固有的图像特定感应偏差。因此,他们需要更多的能力来学习视觉表征。因此,它们既深又宽。与这些模型不同,MobileViT使用卷积和变换器的方式是,生成的MobileViT块具有卷积性质,同时允许全局处理。这种建模能力使我们能够设计浅层和窄层MobileViT模型,这些模型反过来又很轻。与使用L=12和d=192的基于ViT的模型DeIT相比, MobileViT模型在空间水平32×32、16×16和8×8分别使用L={2、4、3}和d={96、120、144}。由此产生的MobileViT网络比DeIT网络更快(1.85×),更小(2×),更好(+1.8%)(表3;§4.3)。

Computational cost.
MobileViT和ViTs(图1a)中多头自注意力的计算成本分别为 O ( N 2 P d ) O(N^2Pd) O(N2Pd)和 O ( N 2 d ) O(N^2d) O(N2d)。理论上,与ViTs相比,MobileViT效率较低。然而,在实践中,MobileViT比ViTs更有效。MobileViT在ImageNet-1K数据集上的浮点运算量减少了2倍,精度比DeIT高1.8%(表3;§4.3)。我们认为,这是由于与轻型设计类似的原因(如上所述)。
MobileViT architecture
我们的网络受到轻量级CNN理念的启发。我们在通常用于移动视觉任务的三种不同网络大小(S:small、XS:extra small和XXS:extra-extra small)下训练MobileViT模型(图3c)。MobileViT中的初始层是步幅为3×3标准卷积,然后是MobileNet V2(或MV2)块和MobileViT块(图1b和§a)。我们使用Swish(Elfwing等人,2018)作为激活函数。根据CNN模型,我们在MobileViT块中使用n=3。特征地图的空间维度通常是2和h、w的倍数≤ n、 因此,我们在所有空间级别上设置h=w=2(更多结果见§C)。MobileViT网络中的MV2块主要负责下采样。因此,这些块在MobileViT网络中是浅而窄的。图3d中MobileViT的空间层次参数分布进一步表明,MV2块对不同网络配置的总网络参数的贡献非常小。

3.2 MULTI-SCALE SAMPLER FOR TRAINING EFFICIENCY
在基于ViT的模型中,学习多尺度表示的标准方法是微调。例如,Touvron等人(2021a)以224×224的空间分辨率对不同大小的DeIT模型进行了独立微调。这种学习多尺度表示的方法更适合VIT,因为位置嵌入需要根据输入大小进行插值,并且网络的性能取决于插值方法。与CNN类似,MobileViT不需要任何位置嵌入,并且在训练期间可以受益于多尺度输入
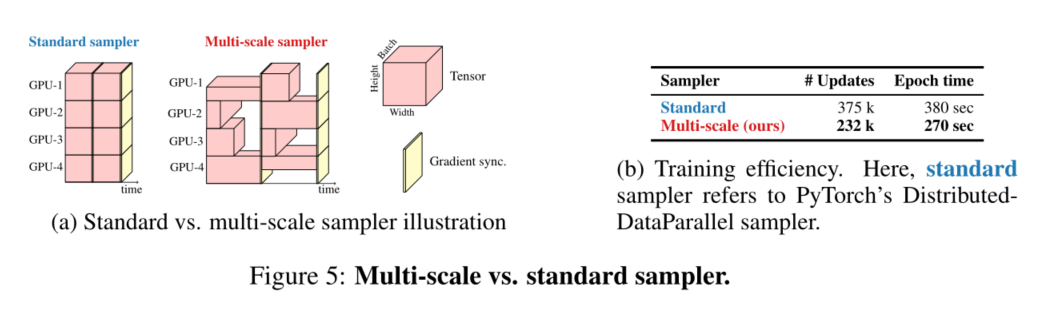
之前基于CNN的研究(例如,Redmon&Farhadi,2017;Mehta等人,2021b)表明,多尺度训练是有效的。然而,这些工作大多在经过固定次数的迭代后采样新的空间分辨率。例如,YOLOv2(Redmon&Farhadi,2017)在每10次迭代时从预定义集采样一个新的空间分辨率,并在训练期间跨不同GPU使用相同的分辨率。这导致GPU利用率不足,训练速度较慢,因为在所有分辨率中使用相同的批量大小(使用预定义集中的最大空间分辨率确定)。为了便于MobileViT在不进行微调的情况下学习多尺度表示,并进一步提高训练效率(即更少的优化更新),我们将多尺度训练方法扩展到可变大小的批量。给定一组排序的空间分辨率 S = ( H 1 , W 1 ), ⋅ ⋅ ,( H n , W n ) S={(H_1,W_1),··,(H_n,W_n)} S=(H1,W1),⋅⋅,(Hn,Wn)和最大空间分辨率 ( H n , W n ) (H_n,W_n) (Hn,Wn)的batch size b,我们随机采样一个空间分辨率 ( H t , W t ) ∈ S (H_t,W_t)∈ S (Ht,Wt)∈S在每个GPU上的第t次训练迭代中,计算第t次迭代的批大小为: b t = H n W n b H t W t b_{t}=\frac{H_{n} W_{n} b}{H_{t} W_{t}} bt=HtWtHnWnb。因此,较大的批大小用于较小的空间分辨率。这减少了每个epoch的优化器更新,并有助于更快的训练。
图5比较了标准和多尺度取样器。在这里,我们将Pytorch中的DistributedDataParallel称为标准取样器。总的来说,多尺度采样器(i)减少了训练时间,因为它需要更少的优化器更新,具有可变大小的批次(图5b),(ii)将性能提高约0.5%(图10;§B),以及(iii)迫使网络学习更好的多尺度表示(§B),即在不同的空间分辨率下评估时,相同的网络会产生更好的性能与使用标准采样器训练的采样器相比。在§B中,我们还表明多尺度采样器是通用的,并提高了CNN(例如MobileNet V2)的性能。
4 EXPERIMENTAL RESULTS

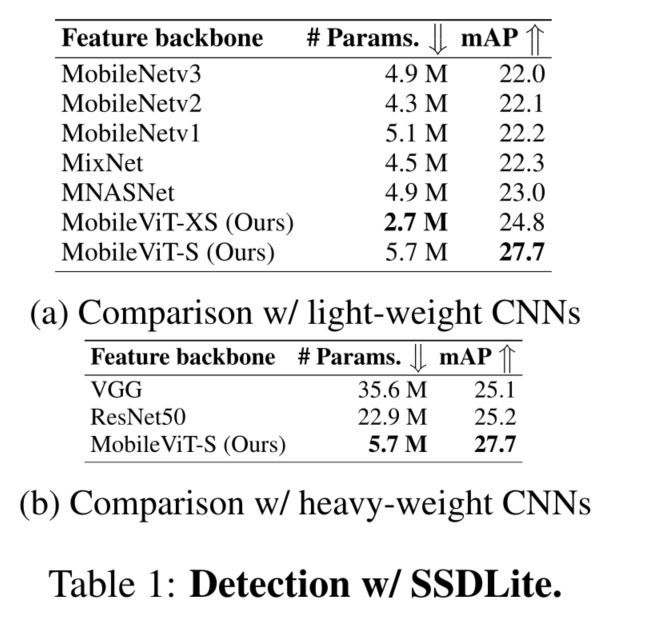
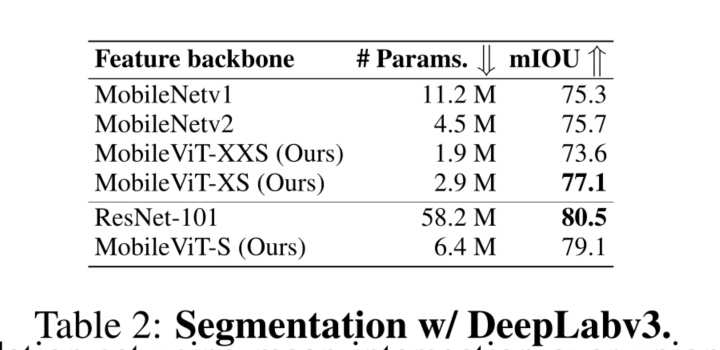
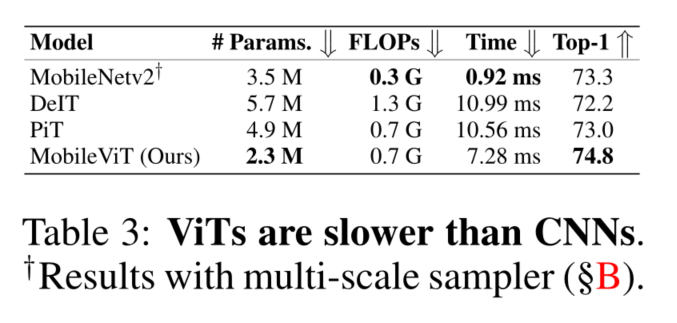
4.3 PERFORMANCE ON MOBILE DEVICES
轻量级和低延迟网络对于实现移动视觉应用非常重要。为了证明MobileViT在此类应用中的有效性,使用公开的CoreMLTools(2021)将预先训练的全精度MobileViT模型转换为CoreML。然后在移动设备上,即iPhone 12上测量其推理时间(平均超过100次迭代)。
Mobile-friendly.
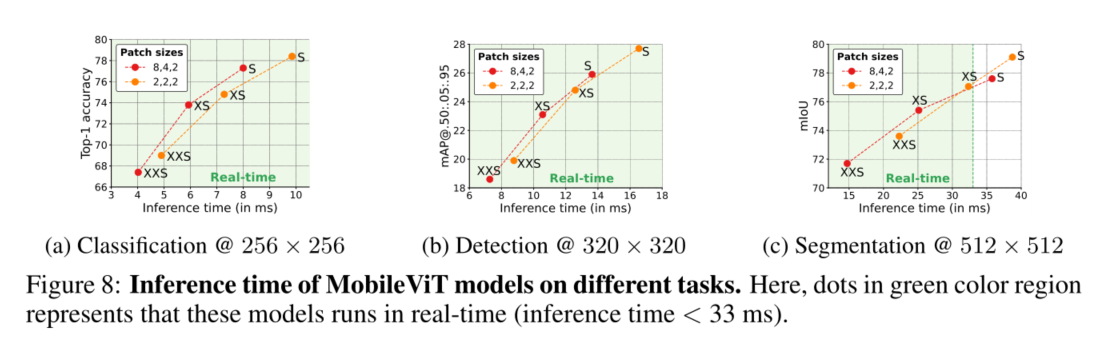
图8显示了具有两个补丁大小设置(配置A:2、2、2和配置B:8、4、2)的MobileViT网络在三个不同任务上的推断时间。这里,ConfigX中的p1、p2、p3分别表示8、16和32的输出步长2处的面片高度h(宽度w=h)。与较大的面片(配置B)相比,面片尺寸较小的模型(配置A)更精确。这是因为,与配置A模型不同,配置B模型无法对所有像素的信息进行编码(图13和§C)。另一方面,对于给定的参数预算,配置B模型比配置a更快,即使两种配置中的自注意力的理论复杂性相同,即 O ( N 2 P d ) O(N ^2P d) O(N2Pd)。对于较大的斑块大小(例如,P=82=64),与较小的斑块大小(例如,P=22=4)相比,我们的斑块数量N更少。因此,自注意力的计算成本相对较小。此外,与配置a相比,配置B模型具有更高的并行度,因为与较小的面片(P=4)相比,在较大的面片(P=64)中可以同时计算更多像素的自注意力。因此,Config-B模型比Config-A更快。为了进一步改善MobileViT的延迟,可以使用线性自注意力(Wang等人,2020)。无论如何,两种配置中的所有模型都实时运行(推理速度≥ 30 FPS),但用于分割任务的MobileViT-S模型除外。这是预期的,因为与分类(256×256)和检测(320×320)网络相比,这些模型处理更大的输入(512×512)
Discussion.
我们观察到,与移动设备上的MobileNet v2相比,MobileNet和其他基于VIT的网络(如DeIT和PiT)速度较慢(表3)。这一观察结果与之前的研究相矛盾,之前的研究表明,与CNN相比,VIT更具可扩展性(Dosovitskiy等人,2021)。这种差异主要是因为两个原因。首先,GPU上的变压器有专用的CUDA内核,VIT中开箱即用,以提高其在GPU上的可扩展性和效率(例如,Shoeybi等人,2019年;Lepikhin等人,2021)。其次,CNN受益于多种设备级优化,包括卷积层的批量归一化融合(Jacob等人,2018)。这些优化改善了延迟和内存访问**。然而,目前移动设备上还没有针对变压器的此类专用和优化操作**。因此,用于移动设备的MobileViT和基于ViT的网络的推理图是次优的。我们相信,与CNN类似,MobileViT和ViTs的推理速度将在未来随着专用设备级操作而进一步提高。