论文原文:https://arxiv.org/abs/2110.02178
源码地址(pytorch实现):https://github.com/apple/ml-cvnets
前言
MobileVit是由CNN和Transformer混合架构组成的,它利用了CNN的空间归纳偏置[1]和加速网络收敛的优势,而且还利用了transformer的自注意力机制和全局视野。在模型参数上,它比主流的transformer架构的网络参数量更低,但是精度却更高,而在与主流轻量级CNN架构相比其参数量也更低,精度也更高。当然了,速度上仍然比主流轻量级CNN架构模型慢很多,不过对比纯transformer架构却快很多
网络结构

图1
组成部分(从左至右):
-
普通卷积层:用于对输入图像进行预处理和特征提取。
-
MV2(MobileNetV2中的Inverted Residual block):一种轻量级的卷积块结构,用于在网络中进行下采样操作。
-
MobileViT block:MobileViT的核心组件,由多个Transformer block组成,用于对图像特征进行全局上下文的建模和特征融合。
-
全局池化层:用于将特征图进行降维,得到全局特征。
-
全连接层:用于将全局特征映射到最终的预测输出。
MV2:
是mobile-Net V2中的结构,由2个1×1的卷积和1个3×3的卷积组成

图2
relu6
原relu激活函数未对输出大于0的数值进行限制,relu6将输出值最大限制为6,其公式如下:
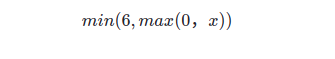
MobileViT block:
核心组件,由多个Transformer block和卷积层(卷积核大小为1×1和3×3)组成

图3
具体过程:
首先将特征图通过一个卷积核大小为nxn(源码为3x3)的卷积层进行局部的特征建模,然后通过一个卷积核大小为1x1的卷积层调整通道数。接着通过Unfold -> Transformer -> Fold结构进行全局的特征建模,然后再通过一个卷积核大小为1x1的卷积层将通道数调整回原始大小。接着通过shortcut捷径分支与原始输入特征图进行Concat拼接(沿通道channel方向拼接),最后再通过一个卷积核大小为nxn(源码3x3)的卷积层做特征融合得到输出
Unfold -> Transformer -> Fold 过程:
首先对特征图进行patch划分,图4中的patch为2×2,即每个patch由4个token组成。在进行自注意(self-attention)计算时,每个token(图4中的每个token,即每个小颜色块)只和自己颜色相同的token进行attention(减少计算量的目的,只需要原始1/4的计算量,原始self-attention每个token都需要与其余token进行attention计算)。
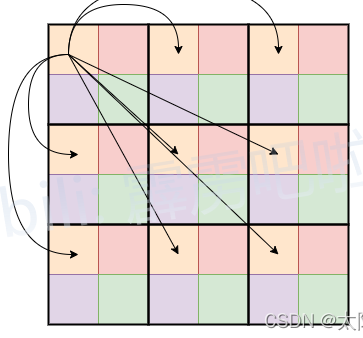
图4

图5
参考解释
[1]:CNN的空间归纳偏置是指CNN在处理图像数据时,利用卷积操作的特性对空间信息进行建模和学习的一种偏置机制。在图像数据中,相邻像素之间的空间关系通常是有意义的,而CNN可以通过卷积操作在局部感受野内获取并学习到这种空间关系。具体来说,CNN通过共享权重的卷积核在不同的位置上提取特征,这种权重共享机制使得CNN具有对平移不变性的特点,即不同位置上提取的特征是具有相似性的。通过这种特性,CNN能够对图像的空间结构进行建模,从而捕捉到图像中不同位置之间的相关性和约束关系。在图像分类任务中,通过卷积操作和池化操作,CNN可以逐渐降低特征图的尺寸,对全局和局部特征进行提取和组合,最后输出分类结果。这种空间归纳偏置使得CNN能够对图像中的空间结构进行建模和理解,提高了图像分类的性能。
相比之下,纯Transformer架构在处理图像数据时缺乏这种空间归纳偏置,而是主要依赖于自注意力机制对不同位置的特征进行关联和整合。因此,在处理图像数据时,引入CNN的空间归纳偏置可以弥补纯Transformer架构的不足,提升模型在图像相关任务中的性能。