Topic
少见的来自Apple的一篇Paper,通过将Mobilenet和VIT进行结合,得到了很好的结果

Abstract
轻量级卷积神经网络(cnn)是移动视觉任务的事实(能实现的)。他们的空间归纳偏差使他们能够在不同的视觉任务中学习参数更少的表征。然而,这些网络工作在空间上是局部的。为了学习全局表示,采用了基于自我注意的视觉变形器(ViTs)。与cnn不同的是,vit是heavyweight。在本文中,我们提出了以下问题:是否有可能将cnn和vit的优势结合起来,为移动视觉任务构建一个轻量级、低延迟的网络?为此,我们介绍了MobileViT,一种用于移动设备的轻量级通用视觉转换器。移动式ViT为变压器的全球信息处理提供了不同的视角。我们的结果表明,在不同的任务和数据集上,MobileViT显著优于CNN和vit的网络。在ImageNet-1k数据集上,MobileViT在约600万pa参数下实现了78.4%的top-1精度,在类似数量的参数下,比MobileNetv3(基于cnn)和DeIT(基于vi)的精度分别高出3.2%和6.2%。在MS-COCO对象检测任务中,在相同数量的参数下,MobileViT比MobileNetv3的准确率高5.7%
Introduction
基于自我注意力的模型,尤其是ViT,是卷积神经网络(cnn)学习视觉表示的替代方案。简单地说,ViT将图像划分为一系列不重叠的补丁,然后使用变压器中的多头自注意学习互不重叠的补丁表示。总体趋势是增加ViT网络中的参数数量以提高性能。然而,这些性能改进是以模型大小(网络参数)和延迟为代价的。许多现实世界的应用程序(例如,增强现实和自动轮椅)需要视觉识别任务(例如,对象检测和语义分割)以及时的方式在资源受限的移动设备上运行。为了有效,用于此类任务的ViT模型应该是轻量级和快速的。即使减少了ViT模型的模型尺寸以匹配移动设备的资源约束,其性能也明显不如轻量级cnn。例如,对于约500 - 600万的参数预算,DeIT (Touvron等人,2021a)的准确度比MobileNetv3 (Howard等人,2019)低3%。因此,设计轻量化的ViT模型势在必行。
轻量级cnn已经为许多移动视觉任务提供了动力。然而,基于vit的网络还远远没有在这些设备上使用。与易于优化并与特定任务网络集成的轻量级cnn不同,vit是重载的(例如,ViT-B/16 vs. MobileNetv3: 86 vs. 750万个参数),更难优化(Xiao et al., 2021),需要大量的数据增强(data augmen)和L2正则化来防止过拟合(Touvron et al., 2021a;Wang等人,2021),并且需要昂贵的解码器来完成下游任务,特别是密集的预测任务。对于在vv的情况下,基于vit的分割网络(Ranftl等人,2021年)学习了大约3.45亿个参数,并实现了与基于cnn的网络DeepLabv3 (Chen等人,2017年)类似的性能,具有5900万个参数。在基于vit的模型中需要更多参数可能是因为它们缺乏特定于图像的归纳偏差,这是cnn固有的(Xiao et al., 2021)。为了建立健壮和高性能的ViT模型,将卷积和变压器结合起来的混合方法
Related Work
[Light-weight CNNs]
[Vision transformers]
与普通vit相比,将卷积和变压器相结合可以得到更健壮和高性能的vit。然而,这里有一个悬而未决的问题:如何结合卷积和变压器的优势,为移动视觉任务构建轻量级网络?本文的重点是设计轻量级ViT模型,这些模型通过简单的训练方法胜过最先进的模型。为此,我们引入了MobileViT,它结合了cnn和vit的优势,构建了一个轻量级、通用、移动友好的网络。MobileViT带来了一些新颖的观察结果:
- Better performance
- Generalization capability
- Robust
结构
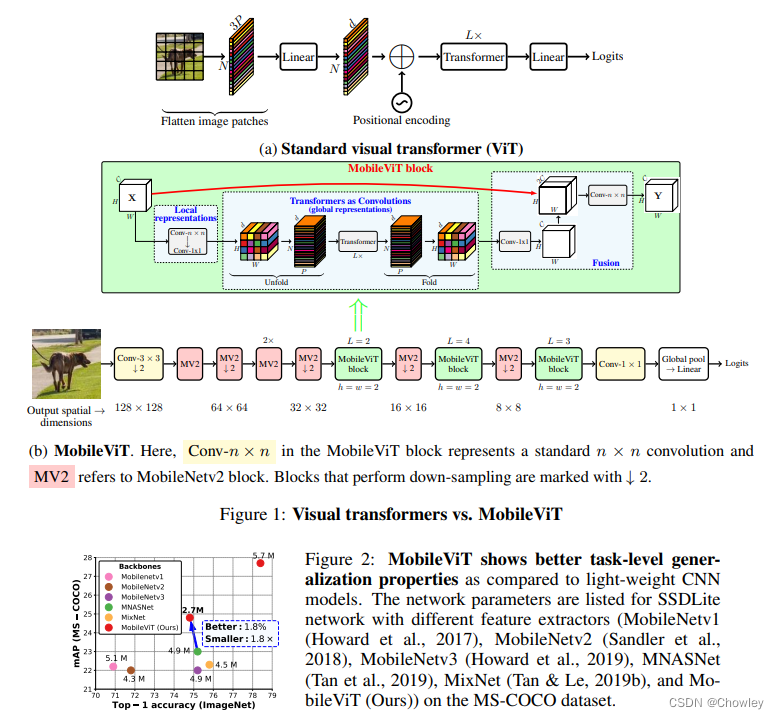
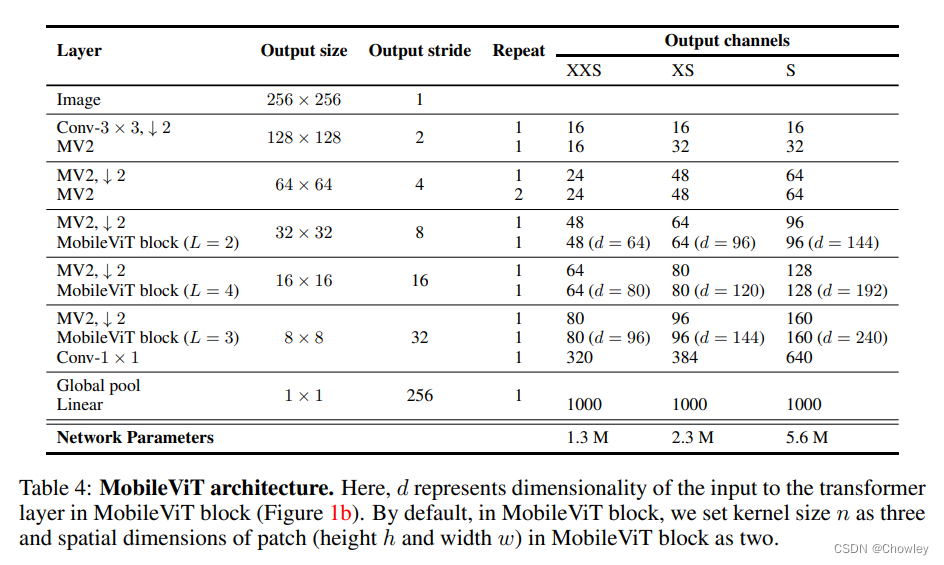
- MobileViT块。如图1b所示,MobileViT块旨在对具有较少参数的输入张量中的局部和全局信息进行建模。形式上,对于给定的输入张量X∈R H×W×C, MobileViT应用一个n × n的标准卷积层,然后是一个按点(或1×1)的卷积层,以产生XL∈R H×W×d。n×n卷积层编码局部空间信息,而点卷积通过学习输入通道的线性组合将张量投影到高维空间(或d维,其中d > C)
- 使用MobileViT,我们希望在拥有有效的H × w接受域的情况下对远程非局部依赖进行建模,其中一个被广泛研究的远程依赖建模方法是扩张卷积。然而,这种方法需要仔细选择扩张率。Oth方面,权重应用于填充的零,而不是有效的空间区域(Yu & Koltun, 2016;Chen等人,2017;梅塔等人,2018)。另一个有希望的解决方案是自我关注(Wang et al., 2018;Ramachandran等人,2019;贝罗等人,2019年;Dosovitskiy等人,2021)。在自注意方法中,具有多头自注意的视觉变形器(ViTs)在视觉识别任务中表现出较好的效果。然而,vit是重量级的,并表现出低于标准的可优化性。这是因为vit缺乏空间归纳偏差(Xiao et al., 2021;格雷厄姆等人,2021)

- 标准卷积可以被看作是三个连续操作的堆栈:(1)展开,(2)矩阵乘法(学习局部表示),(3)折叠(fold)。MobileViT块类似于卷积,因为它也利用了相同的构建块。MobileViT块用更深层次的全局处理(转换器层的堆栈)取代卷积中的局部处理(矩阵乘法)。因此,MobileViT具有类似卷积的属性(例如,空间偏差)。因此,MobileViT块可以被视为卷积式的转换。我们有意简化设计的一个优势是,可以开箱即用地使用低层次的卷积和转换器实现;允许我们在不同的设备上使用MobileViT,而不需要任何额外的工作。
- 图5比较了标准采样器和多尺度采样器。这里,我们将PyTorch中的distributeddataparlena作为标准采样器。总的来说,多尺度采样器(i)减少了训练时间,因为它需要更少的优化器更新可变大小的批次(图5b), (ii)提高了约0.5%的性能(图10;§B)和(iii)迫使网络学习更好的多尺度表示(§B),即,与使用标准采样器训练的网络相比,同一网络在不同空间分辨率下评估时产生更好的性能。在§B中,我们还展示了多尺度采样器是通用的,并提高了cnn的性能(例如,MobileNetv2)。

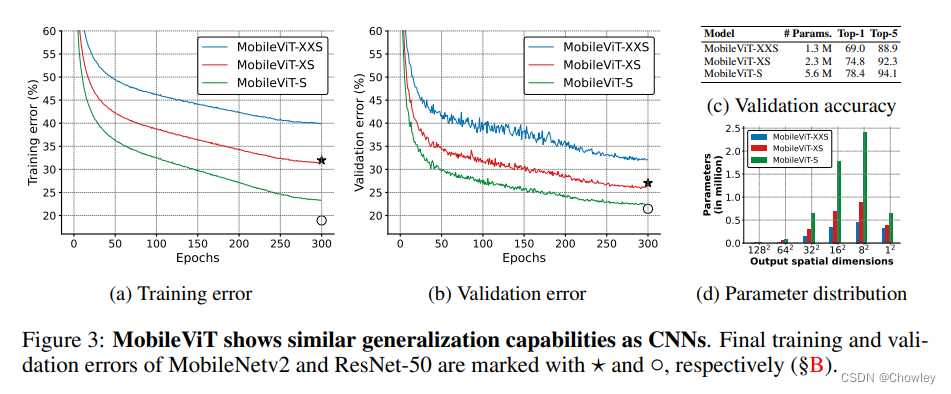
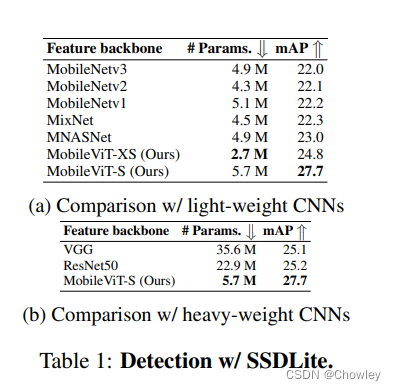
Experiments


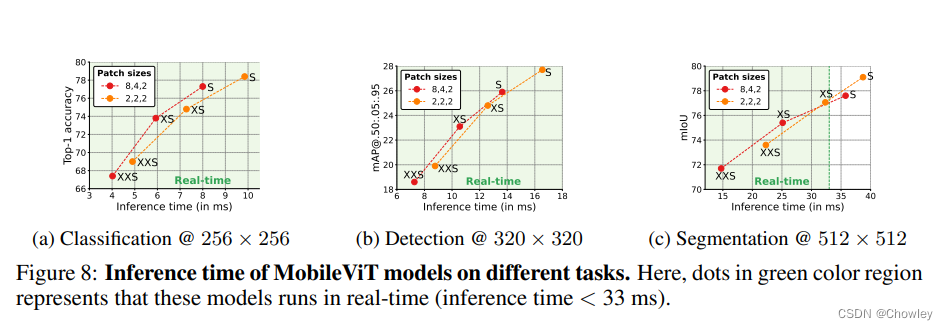
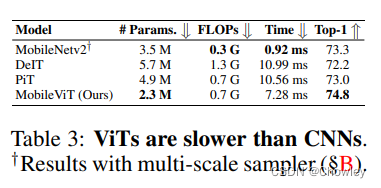
Conclusion and Discussion
我们观察到,与移动设备上的MobileNetv2相比,MobileViT和其他基于ViT的网络(例如,DeIT和PiT)更慢(表3)。这一观察结果与之前的工作相矛盾,这些工作表明,与cnn相比,ViT更具有可扩展性(Dosovit (skiy)等人,2021年)。这种差异主要是由于两个原因。首先,专门的CUDA内核用于gpu上的变压器,在vit中开箱即用,以提高其在gpu上的可伸缩性和效率(例如,Shoeybi等人,2019;Lepikhin等人,2021)。其次,cnn受益于几种设备级优化,包括与卷积层的批量归一化融合(Jacob et al., 2018)。这些优化改善了延迟和内存访问。然而,这种专门的、优化的变压器操作目前还不能用于移动设备。因此,由此产生的MobileViT和基于vitc的移动设备网络的推断图是次优的。我们相信,与cnn类似,MobileViT和ViTs的推断速度将在未来通过专用的设备级操作进一步提高。
Self-Evaluation
简单说就是将CNN和Transformer,两个系列结合起来,产生了不错的效果,原文的附录内容更加详细,感兴趣的可以去仔细读读
MobileVIT